Consulta & comparar experimentos e execuções com MLflow
Experimentos e trabalhos (ou execuções) no Aprendizado de Máquina do Azure podem ser consultados usando MLflow. Você não precisa instalar nenhum SDK específico para gerenciar o que acontece dentro de um trabalho de treinamento, criando uma transição mais perfeita entre execuções locais e a nuvem removendo dependências específicas da nuvem. Neste artigo, você aprenderá a consultar e comparar experimentos e execuções em seu espaço de trabalho usando o Azure Machine Learning e o SDK do MLflow em Python.
O MLflow permite:
- Crie, consulte, exclua e pesquise experimentos em um espaço de trabalho.
- Consultar, excluir e procurar execuções em um espaço de trabalho.
- Rastreie e recupere métricas, parâmetros, artefatos e modelos de execuções.
Para obter uma comparação detalhada entre o MLflow de código aberto e o MLflow quando conectado ao Azure Machine Learning, consulte Matriz de suporte para consultar execuções e experimentos no Azure Machine Learning.
Nota
O SDK do Python do Azure Machine Learning v2 não fornece recursos nativos de log ou rastreamento. Isso se aplica não apenas para o registro, mas também para consultar as métricas registradas. Em vez disso, use MLflow para gerenciar experimentos e execuções. Este artigo explica como usar o MLflow para gerenciar experimentos e execuções no Azure Machine Learning.
Você também pode consultar e pesquisar experimentos e execuções usando a API REST MLflow. Consulte Usando o MLflow REST com o Azure Machine Learning para obter um exemplo sobre como consumi-lo.
Pré-requisitos
Instale o pacote MLflow SDK
mlflowe o plug-in do Azure Machine Learningazureml-mlflowpara MLflow da seguinte maneira:pip install mlflow azureml-mlflowGorjeta
Você pode usar o
mlflow-skinnypacote, que é um pacote MLflow leve sem dependências de armazenamento SQL, servidor, interface do usuário ou ciência de dados. Este pacote é recomendado para usuários que precisam principalmente dos recursos de rastreamento e registro em log do MLflow sem importar o conjunto completo de recursos, incluindo implantações.Crie um espaço de trabalho do Azure Machine Learning. Para criar um espaço de trabalho, consulte Criar recursos necessários para começar. Revise as permissões de acesso necessárias para executar suas operações MLflow em seu espaço de trabalho.
Para fazer o acompanhamento remoto ou acompanhar experiências em execução fora do Azure Machine Learning, configure o MLflow para apontar para o URI de acompanhamento da sua área de trabalho do Azure Machine Learning. Para obter mais informações sobre como conectar o MLflow ao seu espaço de trabalho, consulte Configurar o MLflow para o Azure Machine Learning.
Experiências de consulta e pesquisa
Use o MLflow para procurar experimentos dentro do seu espaço de trabalho. Veja os exemplos seguintes:
Obtenha todos os experimentos ativos:
mlflow.search_experiments()Nota
Em versões herdadas do MLflow (<2.0), use o método
mlflow.list_experiments()em vez disso.Obtenha todos os experimentos, incluindo arquivados:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)Obtenha uma experiência específica pelo nome:
mlflow.get_experiment_by_name(experiment_name)Obtenha uma experiência específica por ID:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
Experiências de pesquisa
O search_experiments() método, disponível desde o Mlflow 2.0, permite pesquisar experimentos que correspondam aos critérios usando filter_stringo .
Recupere vários experimentos com base em seus IDs:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )Recupere todos os experimentos criados após um determinado tempo:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")Recupere todos os experimentos com uma determinada tag:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
A consulta e a pesquisa são executadas
O MLflow permite pesquisar execuções dentro de qualquer experimento, incluindo vários experimentos ao mesmo tempo. O método mlflow.search_runs() aceita o argumento experiment_ids e experiment_name para indicar quais experimentos você deseja pesquisar. Você também pode indicar search_all_experiments=True se deseja pesquisar em todos os experimentos no espaço de trabalho:
Por nome da experiência:
mlflow.search_runs(experiment_names=[ "my_experiment" ])Pelo ID do experimento:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])Pesquise em todos os experimentos no espaço de trabalho:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
Observe que oferece suporte ao fornecimento de uma matriz de experimentos, para que experiment_ids você possa pesquisar execuções em vários experimentos, se necessário. Isso pode ser útil caso você queira comparar execuções do mesmo modelo quando ele está sendo registrado em experimentos diferentes (por exemplo, por pessoas diferentes ou iterações de projeto diferentes).
Importante
Se experiment_ids, experiment_namesou search_all_experiments não forem especificados, o MLflow pesquisará por padrão no experimento ativo atual. Você pode definir o experimento ativo usando mlflow.set_experiment().
Por padrão, o MLflow retorna os dados no formato Pandas Dataframe , o que o torna útil ao processar ainda mais nossa análise das execuções. Os dados retornados incluem colunas com:
- Informações básicas sobre a execução.
- Parâmetros com o nome
params.<parameter-name>da coluna . - Métricas (último valor registrado de cada um) com o nome
metrics.<metric-name>da coluna.
Todas as métricas e parâmetros também são retornados quando a consulta é executada. No entanto, para métricas que contêm vários valores (por exemplo, uma curva de perda ou uma curva PR), apenas o último valor da métrica é retornado. Se você quiser recuperar todos os valores de uma determinada métrica, usa mlflow.get_metric_history o método. Consulte Obtendo parâmetros e métricas de uma execução para obter um exemplo.
Execução de encomendas
Por padrão, os experimentos estão em ordem decrescente por start_time, que é o tempo em que o experimento foi enfileirado no Aprendizado de Máquina do Azure. No entanto, você pode alterar esse padrão usando o parâmetro order_by.
A ordem é executada por atributos, como
start_time:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])A ordem é executada e limita os resultados. O exemplo a seguir retorna a última execução única no experimento:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])A ordem é executada pelo atributo
duration:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])Gorjeta
attributes.durationnão está presente no MLflow OSS, mas é fornecido no Azure Machine Learning por conveniência.A ordem é executada pelos valores da métrica:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)Aviso
Atualmente, não há suporte para o uso
order_bycom expressões contendometrics.*,params.*outags.*no parâmetroorder_by. Em vez disso, use osort_valuesmétodo de Pandas como mostrado no exemplo.
Execuções de filtro
Você também pode procurar uma execução com uma combinação específica nos hiperparâmetros usando o parâmetro filter_string. Use params para acessar os parâmetros da execução, metrics para acessar as métricas registradas na execução e attributes para acessar os detalhes das informações da execução. MLflow suporta expressões unidas pela palavra-chave AND (a sintaxe não suporta OR):
A pesquisa é executada com base no valor de um parâmetro:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")Aviso
Apenas operadores
=,likee!=são suportados para filtragemparameters.A pesquisa é executada com base no valor de uma métrica:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")A pesquisa é executada com uma determinada tag:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")Execuções de pesquisa criadas por um determinado usuário:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")A pesquisa é executada com falha. Consulte Filtrar execuções por status para obter os valores possíveis:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")A pesquisa é executada após um determinado tempo:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")Gorjeta
Para a chave
attributes, os valores devem ser sempre strings e, portanto, codificados entre aspas.A pesquisa é executada e demora mais de uma hora:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")Gorjeta
attributes.durationnão está presente no MLflow OSS, mas é fornecido no Azure Machine Learning por conveniência.A pesquisa é executada com o ID em um determinado conjunto:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
O filtro é executado por status
Quando você filtra execuções por status, o MLflow usa uma convenção diferente para nomear o status possível diferente de uma execução em comparação com o Aprendizado de Máquina do Azure. A tabela a seguir mostra os valores possíveis:
| Status do trabalho do Azure Machine Learning | MLFlow's attributes.status |
Significado |
|---|---|---|
| Não iniciada | Scheduled |
O trabalho/execução foi recebido pelo Azure Machine Learning. |
| Queue | Scheduled |
O trabalho/execução está programado para ser executado, mas ainda não começou. |
| Preparação | Scheduled |
O trabalho/execução ainda não começou, mas um cálculo foi alocado para sua execução e está preparando o ambiente e suas entradas. |
| Em Execução | Running |
O trabalho/execução está atualmente em execução ativa. |
| Concluído | Finished |
O trabalho/execução foi concluído sem erros. |
| Com falhas | Failed |
O trabalho/execução foi concluído com erros. |
| Cancelada | Killed |
O trabalho/execução foi cancelado pelo usuário ou encerrado pelo sistema. |
Exemplo:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
Obtenha métricas, parâmetros, artefatos e modelos
O método search_runs retorna um Pandas Dataframe que contém uma quantidade limitada de informações por padrão. Você pode obter objetos Python se necessário, o que pode ser útil para obter detalhes sobre eles. Use o parâmetro para controlar como a output_format saída é retornada:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
Os detalhes podem ser acessados a partir do info membro. O exemplo a seguir mostra como obter o run_id:
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
Obtenha parâmetros e métricas de uma corrida
Quando as execuções são retornadas usando output_format="list", você pode acessar facilmente os parâmetros usando a chave data:
last_run.data.params
Da mesma forma, você pode consultar métricas:
last_run.data.metrics
Para métricas que contêm vários valores (por exemplo, uma curva de perda ou uma curva PR), somente o último valor registrado da métrica é retornado. Se você quiser recuperar todos os valores de uma determinada métrica, usa mlflow.get_metric_history o método. Este método requer que você use o MlflowClient:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
Obter artefatos de uma corrida
O MLflow pode consultar qualquer artefato registrado por uma execução. Os artefatos não podem ser acessados usando o próprio objeto run e o cliente MLflow deve ser usado:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
O método anterior lista todos os artefatos registrados na execução, mas eles permanecem armazenados no repositório de artefatos (armazenamento do Azure Machine Learning). Para baixar qualquer um deles, use o método download_artifact:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
Nota
Em versões herdadas do MLflow (<2.0), use o método MlflowClient.download_artifacts() em vez disso.
Obter modelos a partir de uma corrida
Os modelos também podem ser registrados na execução e, em seguida, recuperados diretamente dele. Para recuperar um modelo, você precisa saber o caminho para o artefato onde ele está armazenado. O método list_artifacts pode ser usado para localizar artefatos que representam um modelo, uma vez que os modelos MLflow são sempre pastas. Você pode baixar um modelo especificando o caminho onde o modelo está armazenado, usando o download_artifact método:
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
Em seguida, você pode carregar o modelo de volta dos artefatos baixados usando a função load_model típica no namespace específico do sabor. O exemplo a seguir usa xgboost:
model = mlflow.xgboost.load_model(model_local_path)
O MLflow também permite executar ambas as operações de uma só vez e baixar e carregar o modelo em uma única instrução. O MLflow transfere o modelo para uma pasta temporária e carrega-o a partir daí. O método load_model usa um formato URI para indicar de onde o modelo deve ser recuperado. No caso de carregar um modelo a partir de uma execução, a estrutura URI é a seguinte:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
Gorjeta
Para consultar e carregar modelos registrados no registro do modelo, consulte Gerenciar registros de modelos no Azure Machine Learning com MLflow.
Obter execuções de filho (aninhadas)
O MLflow suporta o conceito de execuções filho (aninhadas). Essas corridas são úteis quando você precisa desmembrar rotinas de treinamento que devem ser rastreadas independentemente do processo de treinamento principal. Processos de otimização de ajuste de hiperparâmetros ou pipelines do Azure Machine Learning são exemplos típicos de trabalhos que geram várias execuções filhas. Você pode consultar todas as execuções filho de uma execução específica usando a marca mlflow.parentRunIdde propriedade , que contém a ID de execução da execução pai.
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
Comparar trabalhos e modelos no estúdio do Azure Machine Learning (visualização)
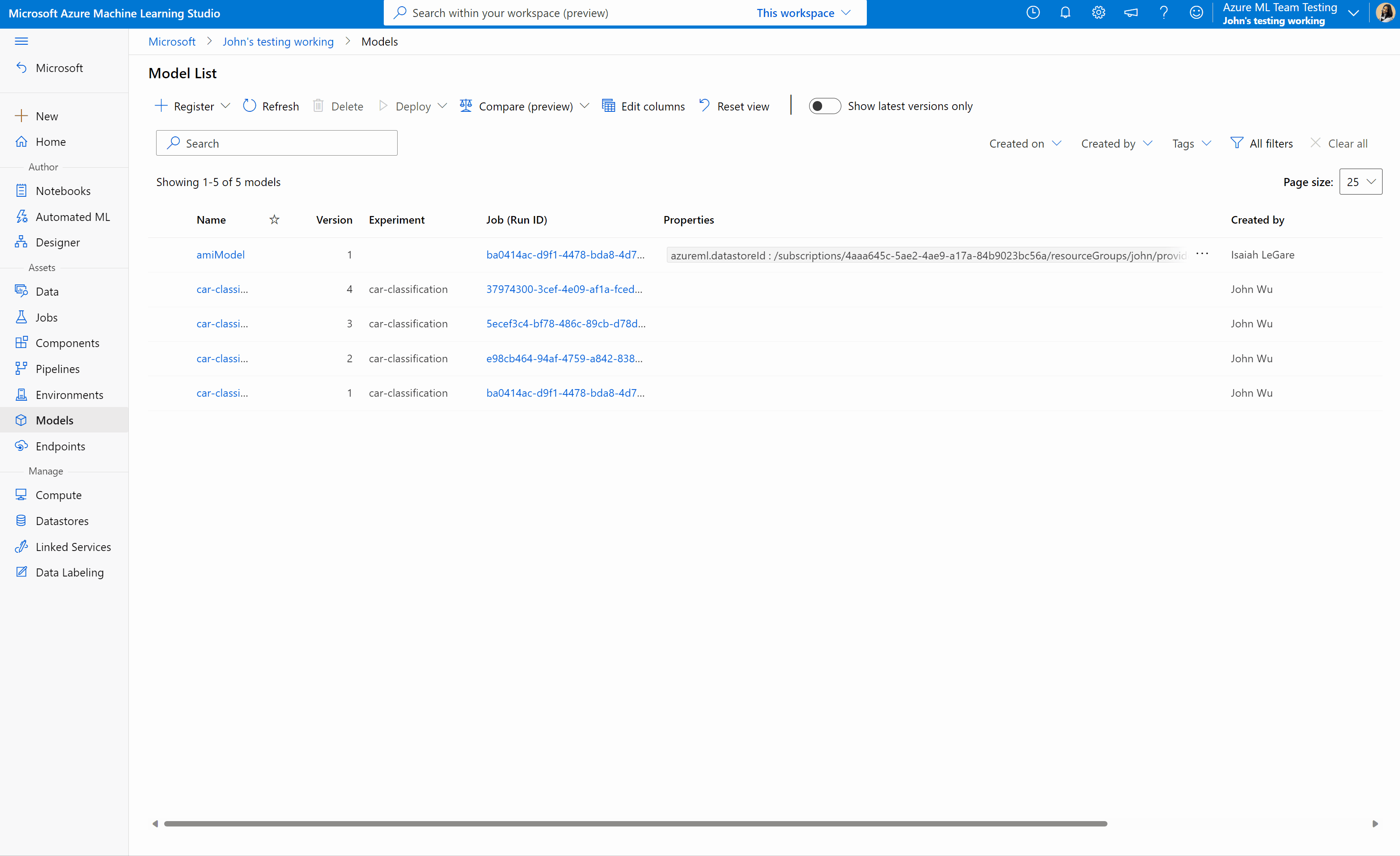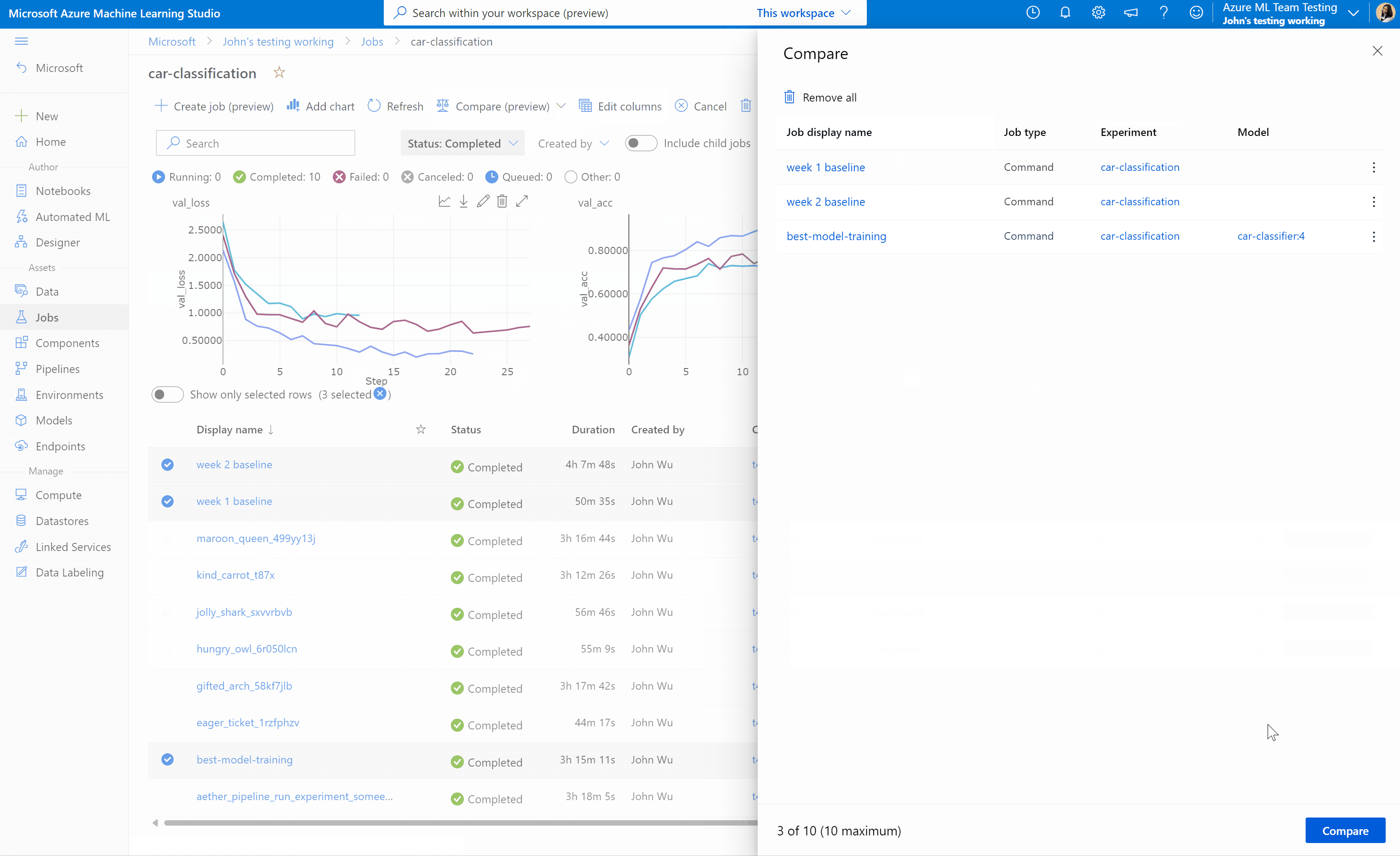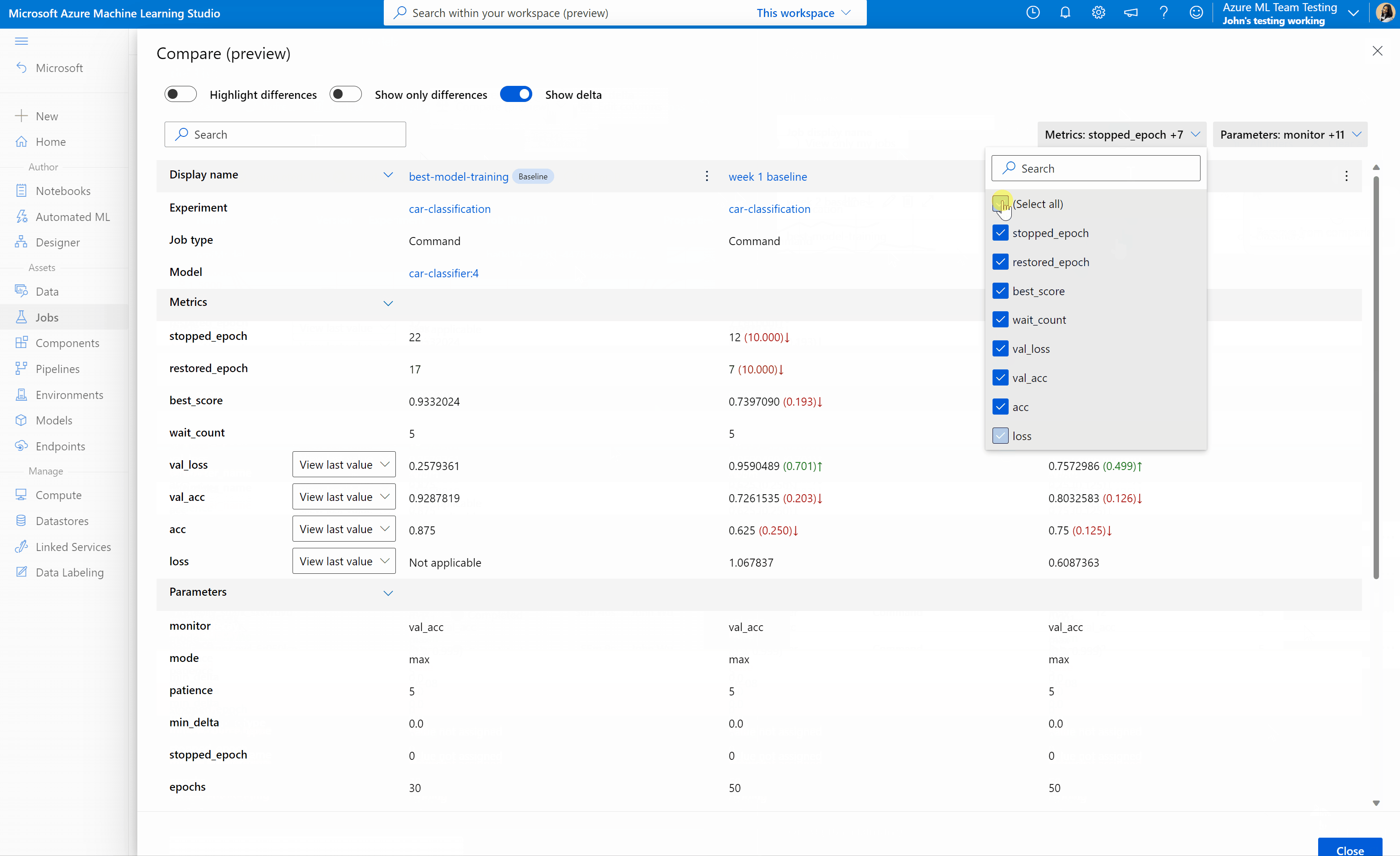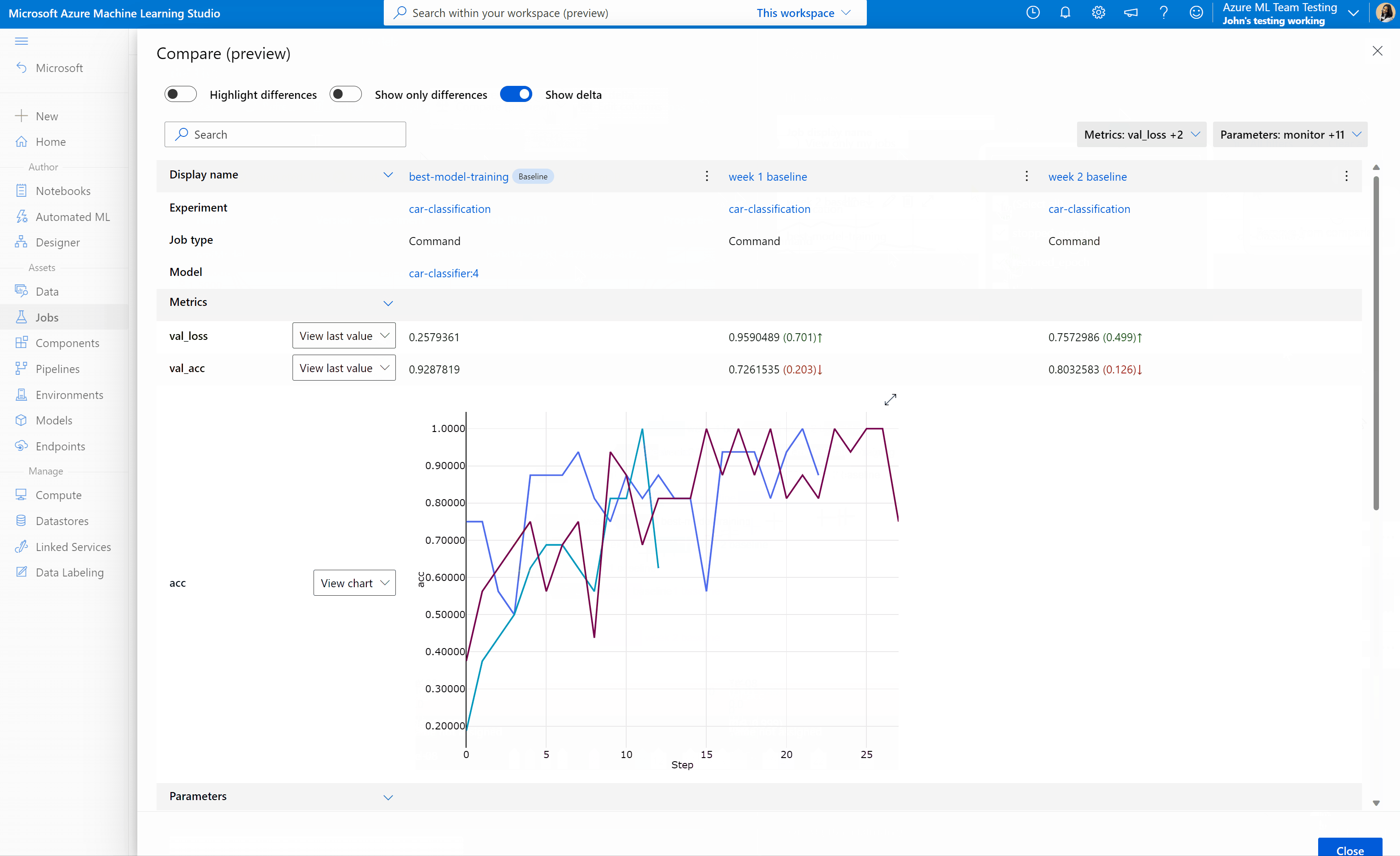
Para comparar e avaliar a qualidade de seus trabalhos e modelos no estúdio do Azure Machine Learning, use o painel de visualização para habilitar o recurso. Uma vez ativado, você pode comparar os parâmetros, métricas e tags entre os trabalhos e/ou modelos selecionados.
Importante
Os itens marcados (visualização) neste artigo estão atualmente em visualização pública. A versão de visualização é fornecida sem um contrato de nível de serviço e não é recomendada para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas. Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
O MLflow com blocos de anotações do Azure Machine Learning demonstra e expande os conceitos apresentados neste artigo.
- Treinar e rastrear um classificador com MLflow: demonstra como rastrear experimentos usando MLflow, modelos de log e combinar vários sabores em pipelines.
- Gerenciar experimentos e execuções com MLflow: demonstra como consultar experimentos, execuções, métricas, parâmetros e artefatos do Aprendizado de Máquina do Azure usando MLflow.
Matriz de suporte para consultas a execuções e experimentos
O SDK MLflow expõe vários métodos para recuperar execuções, incluindo opções para controlar o que é retornado e como. Use a tabela a seguir para saber quais desses métodos são atualmente suportados no MLflow quando conectados ao Azure Machine Learning:
| Caraterística | Suportado pelo MLflow | Suportado pelo Azure Machine Learning |
|---|---|---|
| A ordenação é executada por atributos | ✓ | ✓ |
| A ordenação é executada por métricas | ✓ | 1 |
| A ordenação é executada por parâmetros | ✓ | 1 |
| A encomenda é executada por etiquetas | ✓ | 1 |
| A filtragem é executada por atributos | ✓ | ✓ |
| A filtragem é executada por métricas | ✓ | ✓ |
| A filtragem é executada por métricas com caracteres especiais (com escape) | ✓ | |
| A filtragem é executada por parâmetros | ✓ | ✓ |
| A filtragem é executada por tags | ✓ | ✓ |
A filtragem é executada com comparadores numéricos (métricas), incluindo =, !=, >, >=<, e<= |
✓ | ✓ |
A filtragem é executada com comparadores de cadeia de caracteres (parâmetros, tags e atributos): = e != |
✓ | ✓2 |
A filtragem é executada com comparadores de cadeia de caracteres (parâmetros, tags e atributos): LIKE/ILIKE |
✓ | ✓ |
A filtragem é executada com comparadores AND |
✓ | ✓ |
A filtragem é executada com comparadores OR |
||
| Renomeando experimentos | ✓ |
Nota
- 1 Consulte a secção Ordenação é executada para obter instruções e exemplos sobre como obter a mesma funcionalidade no Azure Machine Learning.
-
!=2 para tags não suportadas.