Executar pontos de extremidade em lote do Azure Data Factory
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
O Big Data requer um serviço que possa orquestrar e operacionalizar processos para refinar esses enormes armazenamentos de dados brutos em insights de negócios acionáveis. O serviço de nuvem gerenciado do Azure Data Factory lida com esses complexos projetos híbridos de extração-transformação-carga (ETL), extração-carga-transformação (ELT) e integração de dados.
O Azure Data Factory permite criar pipelines que podem orquestrar várias transformações de dados e gerenciá-las como uma única unidade. Os pontos de extremidade em lote são um excelente candidato para se tornar uma etapa nesse fluxo de trabalho de processamento.
Neste artigo, saiba como usar pontos de extremidade em lote nas atividades do Azure Data Factory confiando na atividade de Invocação da Web e na API REST.
Gorjeta
Ao usar pipelines de dados na Malha, você pode invocar o ponto de extremidade em lote diretamente usando a atividade do Aprendizado de Máquina do Azure. Recomendamos o uso do Fabric para orquestração de dados sempre que possível para aproveitar os recursos mais recentes. A atividade do Azure Machine Learning no Azure Data Factory só pode funcionar com ativos do Azure Machine Learning V1. Para obter mais informações, consulte Executar modelos do Azure Machine Learning a partir da malha, usando pontos de extremidade em lote (visualização).
Pré-requisitos
Um modelo implantado como um ponto de extremidade em lote. Use o classificador de condição cardíaca criado em Usando modelos MLflow em implantações em lote.
Um recurso do Azure Data Factory. Para criar um data factory, siga as etapas em Guia de início rápido: criar uma fábrica de dados usando o portal do Azure.
Depois de criar seu data factory, navegue até ele no portal do Azure e selecione Iniciar estúdio:


Autenticar em pontos de extremidade de lote
O Azure Data Factory pode invocar as APIs REST de pontos de extremidade em lote usando a atividade de Invocação da Web. Os pontos de extremidade em lote suportam o Microsoft Entra ID para autorização e a solicitação feita às APIs requer um tratamento de autenticação adequado. Para obter mais informações, consulte Atividade da Web no Azure Data Factory e Azure Synapse Analytics.
Você pode usar uma entidade de serviço ou uma identidade gerenciada para autenticar em pontos de extremidade em lote. Recomendamos o uso de uma identidade gerenciada porque simplifica o uso de segredos.
Você pode usar a identidade gerenciada do Azure Data Factory para se comunicar com pontos de extremidade em lote. Nesse caso, você só precisa se certificar de que seu recurso do Azure Data Factory foi implantado com uma identidade gerenciada.
Se você não tiver um recurso do Azure Data Factory ou se ele já tiver sido implantado sem uma identidade gerenciada, siga este procedimento para criá-lo: Identidade gerenciada atribuída pelo sistema.
Atenção
Não é possível alterar a identidade do recurso no Azure Data Factory após a implantação. Se você precisar alterar a identidade de um recurso depois de criá-lo, precisará recriar o recurso.
Após a implantação, conceda acesso para a identidade gerenciada do recurso que você criou ao seu espaço de trabalho do Azure Machine Learning. Consulte Conceder acesso. Neste exemplo, a entidade de serviço requer:
- Permissão no espaço de trabalho para ler implantações em lote e executar ações sobre elas.
- Permissões para leitura/gravação em armazenamentos de dados.
- Permissões para ler em qualquer local na nuvem (conta de armazenamento) indicada como entrada de dados.
Sobre o gasoduto
Neste exemplo, você cria um pipeline no Azure Data Factory que pode invocar um determinado ponto de extremidade em lote sobre alguns dados. O pipeline se comunica com os pontos de extremidade em lote do Azure Machine Learning usando REST. Para obter mais informações sobre como usar a API REST de pontos de extremidade em lote, consulte Criar trabalhos e dados de entrada para pontos de extremidade em lote.
O pipeline tem a seguinte aparência:

O pipeline contém as seguintes atividades:
Run Batch-Endpoint: uma atividade da Web que usa o URI do ponto de extremidade em lote para invocá-lo. Ele passa o URI de dados de entrada onde os dados estão localizados e o arquivo de saída esperado.
Esperar pelo trabalho: é uma atividade de loop que verifica o status do trabalho criado e aguarda sua conclusão, como Concluído ou Reprovado. Esta atividade, por sua vez, utiliza as seguintes atividades:
- Verificar status: uma atividade da Web que consulta o status do recurso de trabalho que foi retornado como uma resposta da atividade Run Batch-Endpoint .
- Esperar: uma atividade de espera que controla a frequência de sondagem do status do trabalho. Definimos um padrão de 120 (2 minutos).
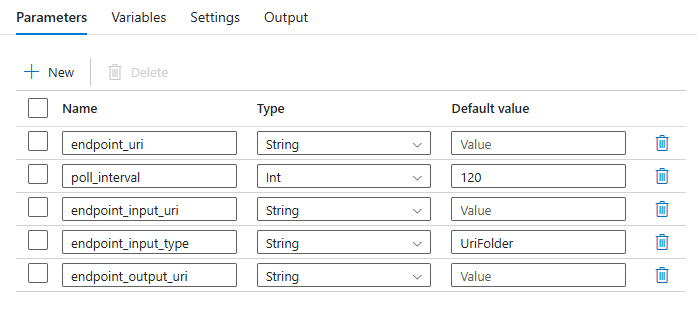
O pipeline requer que você configure os seguintes parâmetros:
| Parâmetro | Description | Valores de exemplo |
|---|---|---|
endpoint_uri |
O URI de pontuação do ponto de extremidade | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
O número de segundos a aguardar antes de verificar o status do trabalho para conclusão. O padrão é 120. |
120 |
endpoint_input_uri |
Os dados de entrada do ponto de extremidade. Vários tipos de entrada de dados são suportados. Certifique-se de que a identidade gerenciada que você usa para executar o trabalho tenha acesso ao local subjacente. Como alternativa, se você usar Armazenamentos de Dados, verifique se as credenciais estão indicadas lá. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
O tipo de dados de entrada que você está fornecendo. Atualmente, os pontos de extremidade em lote suportam pastas (UriFolder) e Arquivo (UriFile). O padrão é UriFolder. |
UriFolder |
endpoint_output_uri |
O arquivo de dados de saída do ponto de extremidade. Ele deve ser um caminho para um arquivo de saída em um Repositório de Dados anexado ao espaço de trabalho do Aprendizado de Máquina. Nenhum outro tipo de URIs é suportado. Você pode usar o armazenamento de dados padrão do Azure Machine Learning, chamado workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

Aviso
Lembre-se de que endpoint_output_uri esse deve ser o caminho para um arquivo que ainda não existe. Caso contrário, o trabalho falhará com o erro o caminho já existe.
Criar o pipeline
Para criar esse pipeline em seu Azure Data Factory existente e invocar pontos de extremidade em lote, siga estas etapas:
Verifique se a computação onde o ponto de extremidade em lote é executado tem permissões para montar os dados que o Azure Data Factory fornece como entrada. A entidade que invoca o ponto de extremidade ainda concede acesso.
Neste caso, é o Azure Data Factory. No entanto, a computação em que o ponto de extremidade em lote é executado precisa ter permissão para montar a conta de armazenamento fornecida pelo Azure Data Factory. Consulte Acesso a serviços de armazenamento para obter detalhes.
Abra o Azure Data Factory Studio. Selecione o ícone de lápis para abrir o painel Autor e, em Recursos de fábrica, selecione o sinal de adição.
Selecione Importação de pipeline>do modelo de pipeline.
Selecione um arquivo .zip .
- Para usar identidades gerenciadas, selecione este arquivo.
- Para usar um princípio de serviço, selecione este arquivo.
Uma visualização do pipeline aparece no portal. Selecione Utilizar este modelo.
O pipeline é criado para você com o nome Run-BatchEndpoint.
Configure os parâmetros da implantação em lote:
Aviso
Certifique-se de que seu ponto de extremidade em lote tenha uma implantação padrão configurada antes de enviar um trabalho para ele. O pipeline criado invoca o ponto de extremidade. Uma implantação padrão precisa ser criada e configurada.
Gorjeta
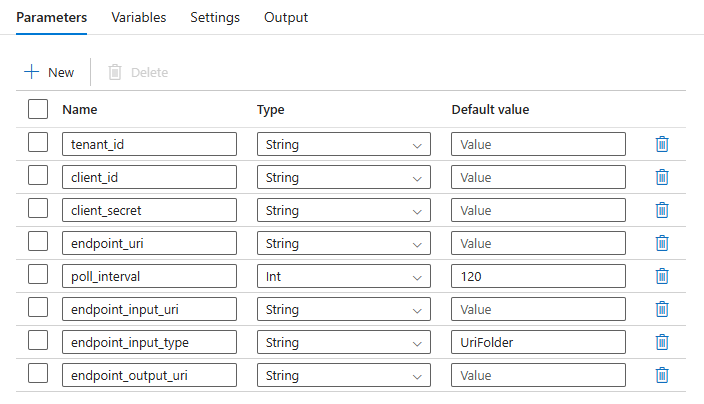
Para melhor reutilização, use o pipeline criado como um modelo e chame-o de dentro de outros pipelines do Azure Data Factory usando a atividade Executar pipeline. Nesse caso, não configure os parâmetros no pipeline interno, mas passe-os como parâmetros do pipeline externo, conforme mostrado na imagem a seguir:
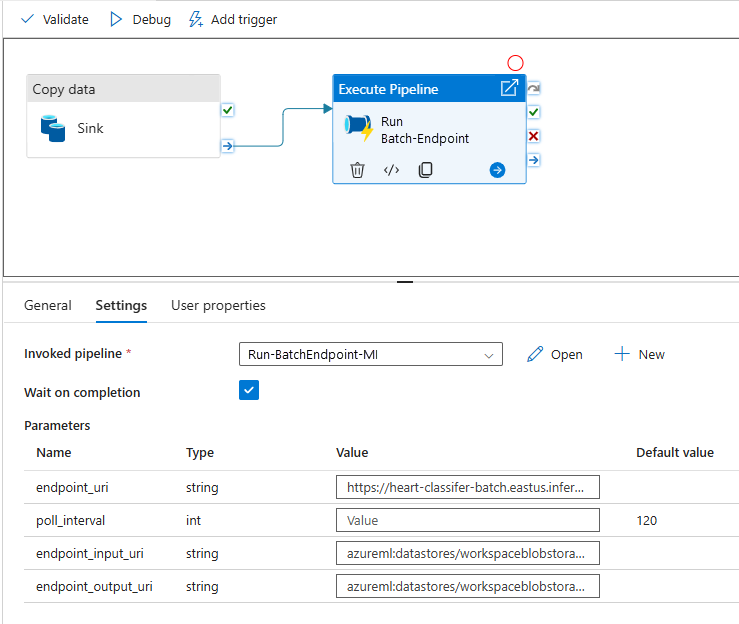
Seu pipeline está pronto para uso.
Limitações
Ao usar implantações em lote do Azure Machine Learning, considere as seguintes limitações:
Introdução de dados
- Apenas armazenamentos de dados do Azure Machine Learning ou Contas de Armazenamento do Azure (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2) são suportados como entradas. Se os dados de entrada estiverem em outra fonte, use a atividade Cópia do Azure Data Factory antes da execução do trabalho em lote para coletar os dados em um repositório compatível.
- Os trabalhos de ponto de extremidade em lote não exploram pastas aninhadas. Eles não podem trabalhar com estruturas de pastas aninhadas. Se seus dados são distribuídos em várias pastas, você tem que achatar a estrutura.
- Certifique-se de que seu script de pontuação fornecido na implantação possa lidar com os dados conforme se espera que sejam alimentados no trabalho. Se o modelo for MLflow, para obter as limitações dos tipos de arquivo suportados, consulte Implantar modelos MLflow em implantações em lote.
Saídas de dados
- Apenas armazenamentos de dados registrados do Azure Machine Learning são suportados. Recomendamos que você registre a conta de armazenamento que seu Azure Data Factory está usando como um Repositório de Dados no Azure Machine Learning. Dessa forma, você pode gravar de volta na mesma conta de armazenamento onde está lendo.
- Apenas as Contas de Armazenamento de Blob do Azure têm suporte para saídas. Por exemplo, o Azure Data Lake Storage Gen2 não é suportado como saída em trabalhos de implantação em lote. Se você precisar enviar os dados para um local ou coletor diferente, use a atividade Cópia do Azure Data Factory depois de executar o trabalho em lote.