Documentação de orientação de resolução de problemas
Este artigo aborda perguntas frequentes sobre o uso do fluxo de prompt.
Problemas relacionados à criação de fluxo
O erro "A ferramenta do pacote não foi encontrada" ocorre quando atualiza o fluxo para uma experiência orientada para o código
Quando você atualiza fluxos para uma experiência code-first, se o fluxo utilizou as ferramentas Faiss Index Lookup, Vetor Index Lookup, Vetor DB Lookup ou Content Safety (Text), você pode encontrar a seguinte mensagem de erro:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
Para resolver o problema, você tem duas opções:
Opção 1
Atualize sua sessão de computação para a versão de imagem base mais recente.
Selecione Modo de arquivo raw para alternar para a visualização de código bruto. Em seguida, abra o arquivo flow.dag.yaml .

Atualize os nomes das ferramentas.
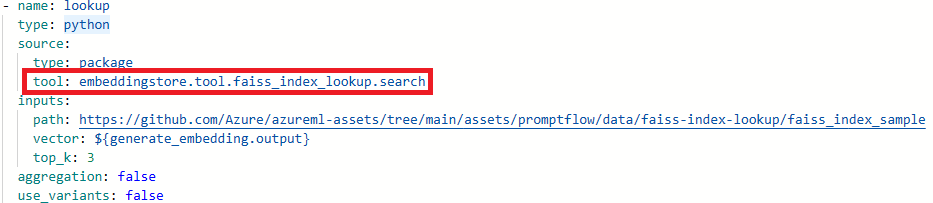
Ferramenta Novo nome da ferramenta Pesquisa de índice Faiss promptflow_vectordb.tool.faiss_index_lookup. FaissIndexLookup.search Pesquisa de índice vetorial promptflow_vectordb.tool.vetor_index_lookup. VectorIndexLookup.search Pesquisa de banco de dados vetorial promptflow_vectordb.tool.vetor_db_lookup. VectorDBLookup.search Segurança de conteúdo (texto) content_safety_text.tools.content_safety_text_tool.analyze_text Salve o arquivo flow.dag.yaml .
Opção 2
- Atualize sua sessão de computação para a versão de imagem base mais recente
- Remova a ferramenta antiga e recrie uma nova.
Erro "Ficheiro ou diretório inexistente"
O fluxo de prompt depende de um armazenamento de compartilhamento de arquivos para armazenar um instantâneo do fluxo. Se o armazenamento de compartilhamento de arquivos tiver um problema, você pode encontrar o seguinte problema. Aqui estão algumas soluções alternativas que você pode tentar:
Se você estiver usando uma conta de armazenamento privada, consulte Isolamento de rede no fluxo de prompt para garantir que seu espaço de trabalho possa acessar sua conta de armazenamento.
Se a conta de armazenamento estiver habilitada para acesso público, verifique se há um armazenamento de dados nomeado
workspaceworkingdirectoryem seu espaço de trabalho. Deve ser um tipo de compartilhamento de arquivos.
- Se você não obteve esse armazenamento de dados, precisará adicioná-lo ao seu espaço de trabalho.
- Crie um compartilhamento de arquivos com o nome
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Crie um armazenamento de dados com o nome
workspaceworkingdirectory. Consulte Criar armazenamentos de dados.
- Crie um compartilhamento de arquivos com o nome
- Se você tiver um
workspaceworkingdirectoryarmazenamento de dados, mas seu tipo forblobem vez de , crie um novo espaço defilesharetrabalho. Use o armazenamento que não habilita namespaces hierárquicos para o Azure Data Lake Storage Gen2 como uma conta de armazenamento padrão do espaço de trabalho. Para obter mais informações, consulte Criar espaço de trabalho.
- Se você não obteve esse armazenamento de dados, precisará adicioná-lo ao seu espaço de trabalho.

O fluxo está em falta

Existem possíveis razões para este problema:
Se o acesso público à sua conta de armazenamento estiver desativado, você deverá garantir o acesso adicionando seu IP ao firewall de armazenamento ou habilitando o acesso por meio de uma rede virtual que tenha um ponto de extremidade privado conectado à conta de armazenamento.
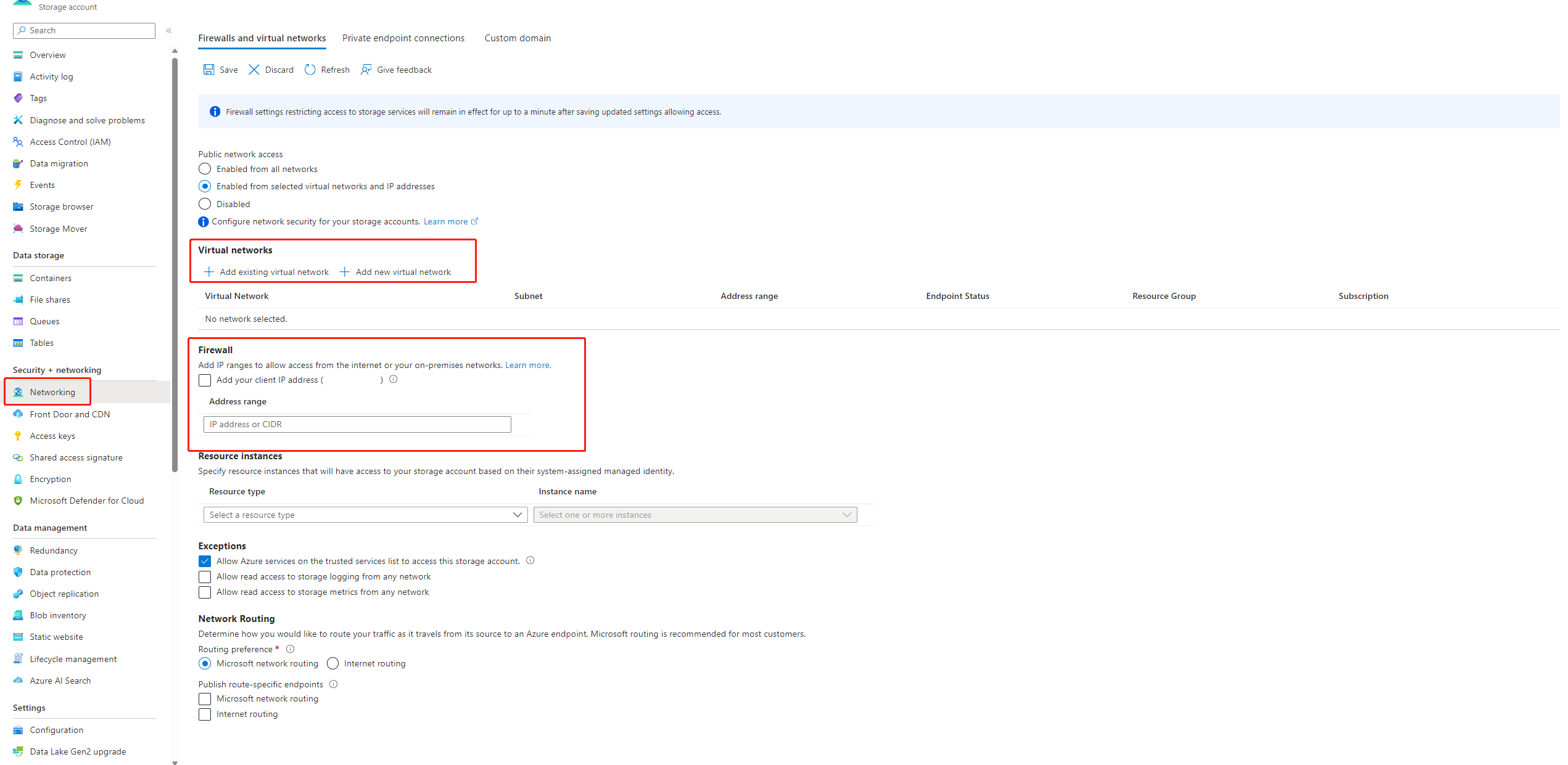
Há alguns casos, a chave de conta no armazenamento de dados está fora de sincronia com a conta de armazenamento, você pode tentar atualizar a chave de conta na página de detalhes do armazenamento de dados para corrigir isso.

Se você estiver usando o Azure AI Foundry, a conta de armazenamento precisará definir o CORS para permitir que o Azure AI Foundry acesse a conta de armazenamento, caso contrário, você verá o problema de fluxo ausente. Você pode adicionar as seguintes configurações de CORS à conta de armazenamento para corrigir esse problema.
- Vá para a página da conta de armazenamento, selecione
Resource sharing (CORS)emsettingse selecione paraFile service. - Origens permitidas:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Métodos permitidos:
DELETE, GET, HEAD, POST, OPTIONS, PUT

- Vá para a página da conta de armazenamento, selecione



Problemas relacionados à sessão de computação
A execução falhou devido a "Nenhum módulo com o nome XXX"
Esse tipo de erro relacionado à sessão de computação não possui os pacotes necessários. Se estiver a utilizar um ambiente predefinido, certifique-se de que a imagem da sua sessão de computação está a utilizar a versão mais recente. Se você estiver usando uma imagem base personalizada, certifique-se de instalar todos os pacotes necessários no contexto do docker. Para obter mais informações, consulte Personalizar imagem base para sessão de computação.
Onde encontrar a instância sem servidor usada pela sessão de computação?
Você pode exibir a instância sem servidor usada pela sessão de computação na guia da lista de sessões de computação na página de computação. Saiba mais sobre como gerenciar instância sem servidor.
Falhas de sessão de computação usando imagem base personalizada
Falha no início da sessão de computação com requirements.txt ou imagem base personalizada
Suporte de sessão de computação para usar requirements.txt ou imagem base personalizada para flow.dag.yaml personalizar a imagem. Recomendamos que você use requirements.txt para casos comuns, que serão usados pip install -r requirements.txt para instalar os pacotes. Se você tiver dependência mais do que pacotes python, precisará seguir a imagem base Personalizar para criar uma nova base de imagem sobre a imagem base de fluxo de prompt. Em seguida, use-o em flow.dag.yaml. Saiba mais como especificar a imagem base na sessão de computação.
- Você não pode usar a imagem base arbitrária para criar uma sessão de computação, você precisa usar a imagem base fornecida pelo fluxo de prompt.
- Não fixe a versão de
promptflowepromptflow-toolsnorequirements.txt, porque já os incluímos na imagem base. Usar a versão antiga depromptflowepromptflow-toolspode causar um comportamento inesperado.
Problemas relacionados à execução do fluxo
Como encontrar as entradas e saídas brutas da ferramenta LLM para investigação adicional?
No fluxo de prompt, na página de fluxo com execução bem-sucedida e página de detalhes de execução, você pode encontrar as entradas e saídas brutas da ferramenta LLM na seção de saída. Selecione o botão para visualizar a view full output saída completa.

Trace inclui cada solicitação e resposta à ferramenta LLM. Você pode verificar a mensagem bruta enviada para o modelo LLM e a resposta bruta do modelo LLM.

Como corrigir o erro 409 do Azure OpenAI?
Você pode encontrar erro 409 do Azure OpenAI, isso significa que você atingiu o limite de taxa do Azure OpenAI. Você pode verificar a mensagem de erro na seção de saída do nó LLM. Saiba mais sobre o limite de taxa do Azure OpenAI.

Identificar o nó que consome mais tempo
Verifique os logs de sessão de computação.
Tente encontrar o seguinte formato de log de aviso:
{node_name} está em execução há {duration} segundos.
Por exemplo:
Caso 1: O nó de script Python é executado por um longo tempo.

Neste caso, você pode descobrir que
PythonScriptNodeestava funcionando por um longo tempo (quase 300 segundos). Em seguida, você pode verificar os detalhes do nó para ver qual é o problema.Caso 2: O nó LLM é executado por um longo tempo.

Nesse caso, se você encontrar a mensagem
request cancelednos logs, pode ser porque a chamada da API OpenAI está demorando muito e excedendo o limite de tempo limite.Um tempo limite da API OpenAI pode ser causado por um problema de rede ou uma solicitação complexa que requer mais tempo de processamento. Para obter mais informações, consulte Tempo limite da API OpenAI.
Aguarde alguns segundos e tente efetuar novamente o seu pedido. Esta ação geralmente resolve quaisquer problemas de rede.
Se tentar novamente não funcionar, verifique se você está usando um modelo de contexto longo, como
gpt-4-32k, e definiu um valor grande paramax_tokens. Nesse caso, o comportamento é esperado porque o prompt pode gerar uma resposta longa que leva mais tempo do que o limite superior do modo interativo. Nessa situação, recomendamos tentarBulk testporque esse modo não tem uma configuração de tempo limite.
Se você não conseguir encontrar nada nos logs para indicar que é um problema de nó específico:
- Entre em contato com a equipe de fluxo de prompt (promptflow-eng) com os logs. Tentamos identificar a causa raiz.


Problemas relacionados à implantação do fluxo
Falta autorização para executar a ação "Microsoft.MachineLearningService/workspaces/datastores/read"
Se o fluxo contiver a ferramenta Pesquisa de Índice, depois de implantar o fluxo, o ponto de extremidade precisará acessar o armazenamento de dados do espaço de trabalho para ler o arquivo yaml MLIndex ou a pasta FAISS contendo partes e incorporações. Portanto, você precisa conceder manualmente a permissão de identidade do ponto de extremidade para fazer isso.
Você pode conceder a identidade de ponto de extremidade AzureML Data Scientist no escopo do espaço de trabalho ou uma função personalizada que contenha a ação "MachineLearningService/workspace/datastore/reader".
Problema de tempo limite de solicitação upstream ao consumir o ponto de extremidade
Se você usar CLI ou SDK para implantar o fluxo, poderá encontrar erro de tempo limite. Por padrão, o request_timeout_ms é 5000. Você pode especificar no máximo até 5 minutos, o que é 300.000 ms. A seguir está um exemplo mostrando como especificar o tempo limite da solicitação no arquivo yaml de implantação. Para saber mais, consulte Esquema de implantação.
request_settings:
request_timeout_ms: 300000
OpenAI API atinge erro de autenticação
Se você regenerar sua chave do Azure OpenAI e atualizar manualmente a conexão usada no fluxo de prompt, poderá encontrar erros como "Não autorizado. O token de acesso está ausente, é inválido, o público está incorreto ou expirou." ao invocar um ponto de extremidade existente criado antes da regeneração da chave.
Isso ocorre porque as conexões usadas nos pontos de extremidade/implantações não serão atualizadas automaticamente. Qualquer alteração de chave ou segredos em implantações deve ser feita por atualização manual, que visa evitar afetar a implantação de produção on-line devido à operação offline não intencional.
- Se o ponto de extremidade foi implantado na interface do usuário do estúdio, você pode simplesmente reimplantar o fluxo para o ponto de extremidade existente usando o mesmo nome de implantação.
- Se o ponto de extremidade foi implantado usando SDK ou CLI, você precisa fazer alguma modificação na definição de implantação, como adicionar uma variável de ambiente fictício e, em seguida, usar
az ml online-deployment updatepara atualizar sua implantação.
Problemas de vulnerabilidade em implantações de fluxo de prompt
Para vulnerabilidades relacionadas ao tempo de execução do fluxo de prompt, a seguir estão as abordagens, que podem ajudar a mitigar:
- Atualize os pacotes de dependência no requirements.txt na pasta de fluxo.
- Se você estiver usando a imagem base personalizada para seu fluxo, precisará atualizar o tempo de execução do fluxo de prompt para a versão mais recente e reconstruir a imagem base e, em seguida, reimplantar o fluxo.
Para quaisquer outras vulnerabilidades de implantações online gerenciadas, o Azure Machine Learning corrige os problemas mensalmente.
"Erro MissingDriverProgram" ou "Não foi possível encontrar o programa de driver na solicitação"
Se você implantar seu fluxo e encontrar o seguinte erro, ele pode estar relacionado ao ambiente de implantação.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
Há duas maneiras de corrigir esse erro.
(Recomendado) Você pode encontrar o uri da imagem do contêiner na página de detalhes do ambiente personalizado e defini-lo como a imagem base do fluxo no arquivo flow.dag.yaml. Ao implantar o fluxo na interface do usuário, basta selecionar Usar ambiente de definição de fluxo atual e o serviço de back-end criará o ambiente personalizado com base nessa imagem base e
requirement.txtpara sua implantação. Saiba mais sobre o ambiente especificado na definição de fluxo.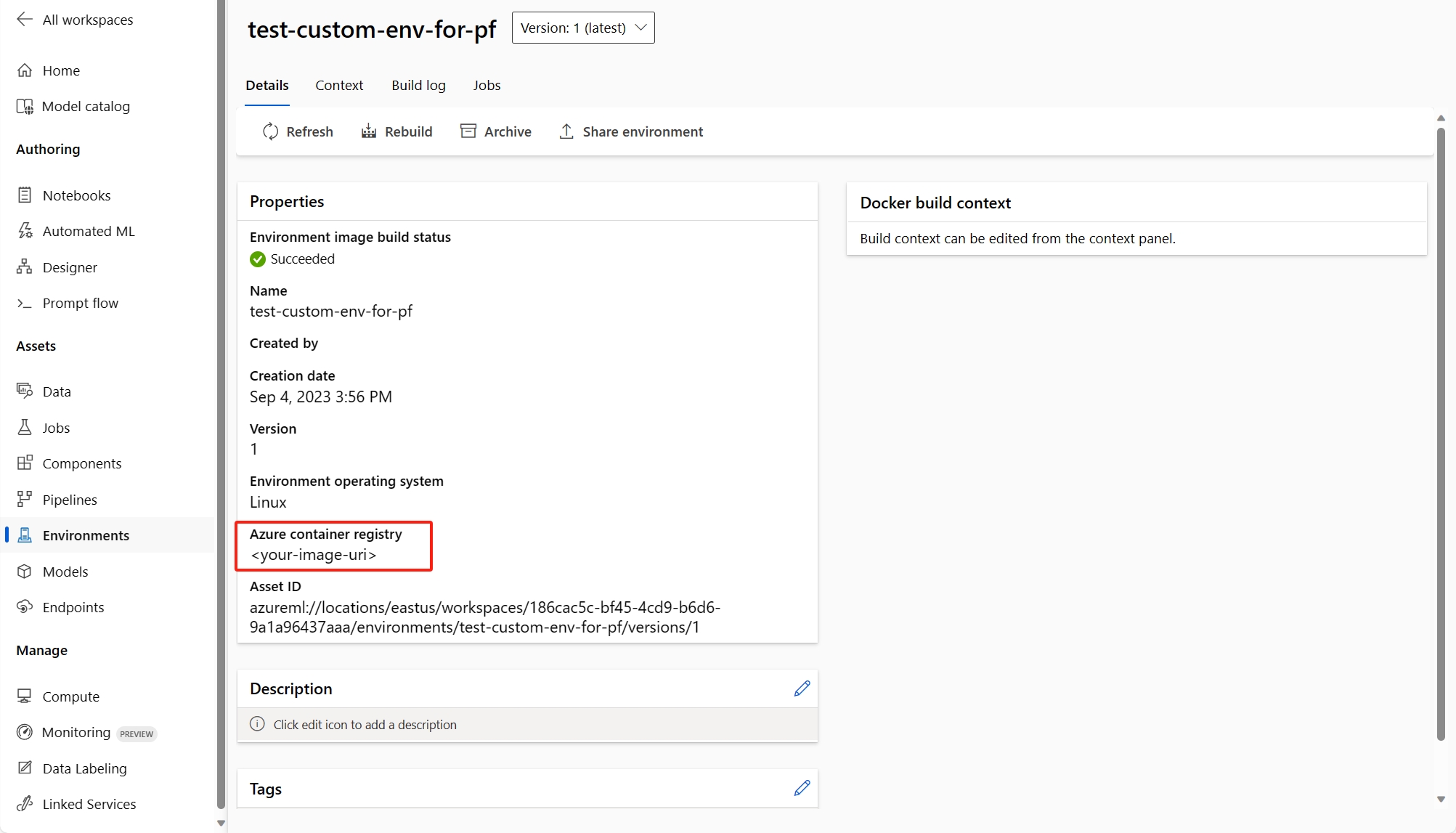

Você pode corrigir esse erro adicionando
inference_configsua definição de ambiente personalizado.Segue-se um exemplo de definição de ambiente personalizado.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
A resposta ao modelo demora muito tempo
Às vezes, você pode notar que a implantação está demorando muito para responder. Existem vários fatores potenciais para que isso ocorra.
- O modelo usado no fluxo não é poderoso o suficiente (exemplo: use GPT 3.5 em vez de text-ada)
- A consulta de índice não está otimizada e demora muito tempo
- O fluxo tem muitas etapas para processar
Considere otimizar o endpoint com as considerações acima para melhorar o desempenho do modelo.
Não é possível obter o esquema de implementação
Depois de implantar o ponto de extremidade e desejar testá-lo na guia Teste na página de detalhes do ponto de extremidade, se a guia Teste mostrar Não é possível buscar o esquema de implantação, você poderá tentar os dois métodos a seguir para atenuar esse problema:

- Certifique-se de ter concedido a permissão correta para a identidade do ponto de extremidade. Saiba mais sobre como conceder permissão à identidade do ponto final.
- Pode ser porque você executou seu fluxo em um tempo de execução de versão antiga e, em seguida, implantou o fluxo, a implantação usou o ambiente do tempo de execução que estava na versão antiga também. Para atualizar o tempo de execução, siga Atualizar um tempo de execução na interface do usuário e execute novamente o fluxo no tempo de execução mais recente e, em seguida, implante o fluxo novamente.
Acesso negado a listar segredos da área de trabalho
Se você encontrar um erro como "Acesso negado à lista de segredos do espaço de trabalho", verifique se concedeu a permissão correta para a identidade do ponto de extremidade. Saiba mais sobre como conceder permissão à identidade do ponto final.
Problemas relacionados com autenticação e identidade
Como é que utilizo o arquivo de dados sem credenciais no fluxo imediato?
Para usar o armazenamento sem credenciais no portal do Azure AI Foundry, você precisa basicamente fazer as seguintes coisas:
- Altere o tipo de autenticação do armazenamento de dados para Nenhum.
- Conceda permissão de MSI do projeto e contribuidor de dados de blob/arquivo do usuário no armazenamento.
Alterar o tipo de autenticação do arquivo de dados para Nenhum
Você pode seguir a autenticação de dados baseada em identidade nesta parte para tornar seu armazenamento de dados sem credenciais.
Você precisa alterar o tipo de autenticação de armazenamento de dados para Nenhum, que significa meid_token baseado em auth. Você pode fazer alterações na página de detalhes do armazenamento de dados ou na CLI/SDK: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

Para armazenamento de dados baseado em blob, você pode alterar o tipo de autenticação e também habilitar o MSI do espaço de trabalho para acessar a conta de armazenamento.

Para armazenamento de dados baseado em compartilhamento de arquivos, você pode alterar apenas o tipo de autenticação.

Conceder permissão à identidade de utilizador ou à identidade gerida
Para usar o armazenamento de dados sem credenciais no fluxo de prompt, você precisa conceder permissões suficientes à identidade do usuário ou à identidade gerenciada para acessar o armazenamento de dados.
- Certifique-se de que o sistema de espaço de trabalho atribuído à identidade gerenciada tenha
Storage Blob Data ContributoreStorage File Data Privileged Contributor, na conta de armazenamento, pelo menos precise de permissão de leitura/gravação (melhor também incluir exclusão). - Se você estiver usando a identidade do usuário essa opção padrão no fluxo de prompt, precisará certificar-se de que a identidade do usuário tenha a seguinte função na conta de armazenamento:
Storage Blob Data ContributorNa conta de armazenamento, pelo menos precisa de permissão de leitura/gravação (melhor também incluir excluir).Storage File Data Privileged ContributorNa conta de armazenamento, pelo menos precisa de permissão de leitura/gravação (melhor também incluir excluir).
- Se estiver a utilizar a identidade gerida atribuída pelo utilizador, tem de se certificar de que a identidade gerida tem a seguinte função na conta de armazenamento:
Storage Blob Data ContributorNa conta de armazenamento, pelo menos precisa de permissão de leitura/gravação (melhor também incluir excluir).Storage File Data Privileged ContributorNa conta de armazenamento, pelo menos precisa de permissão de leitura/gravação (melhor também incluir excluir).- Enquanto isso, você precisa atribuir a função de identidade
Storage Blob Data Readdo usuário à conta de armazenamento, pelo menos, se quiser usar o fluxo de prompt para criar e testar o fluxo.
- Se você ainda não conseguir visualizar a página de detalhes do fluxo e a primeira vez que usar o fluxo de prompt for anterior a 2024-01-01, será necessário conceder MSI do espaço de trabalho quanto
Storage Table Data Contributorà conta de armazenamento vinculada ao espaço de trabalho.