Tutorial: Indexar dados grandes do Apache Spark usando SynapseML e Azure AI Search
Neste tutorial do Azure AI Search, saiba como indexar e consultar dados grandes carregados de um cluster do Spark. Configure um Jupyter Notebook que execute as seguintes ações:
- Carregue vários formulários (faturas) em um quadro de dados em uma sessão do Apache Spark
- Analisá-los para determinar suas características
- Monte a saída resultante em uma estrutura de dados tabular
- Gravar a saída em um índice de pesquisa hospedado no Azure AI Search
- Explore e consulte o conteúdo que criou
Este tutorial depende do SynapseML, uma biblioteca de código aberto que suporta aprendizado de máquina paralelo em massa sobre big data. No SynapseML, a indexação de pesquisa e o aprendizado de máquina são expostos por meio de transformadores que executam tarefas especializadas. Os transformadores exploram uma ampla gama de recursos de IA. Neste exercício, use as APIs do AzureSearchWriter para análise e enriquecimento de IA.
Embora o Azure AI Search tenha enriquecimento de IA nativo, este tutorial mostra como acessar recursos de IA fora do Azure AI Search. Ao usar SynapseML em vez de indexadores ou habilidades, você não está sujeito a limites de dados ou outras restrições associadas a esses objetos.
Gorjeta
Assista a um pequeno vídeo desta demonstração em https://www.youtube.com/watch?v=iXnBLwp7f88. O vídeo expande este tutorial com mais etapas e visuais.
Pré-requisitos
Você precisa da biblioteca e de vários recursos do synapseml Azure. Se possível, use a mesma assinatura e região para seus recursos do Azure e coloque tudo em um grupo de recursos para limpeza simples mais tarde. Os links a seguir são para instalações do portal. Os dados de exemplo são importados de um site público.
- Pacote SynapseML 1
- Azure AI Search (qualquer camada) 2
- Serviços de IA do Azure (qualquer camada) 3
- Azure Databricks (qualquer camada) 4
1 Este link resolve um tutorial para carregar o pacote.
2 Você pode usar a camada de pesquisa gratuita para indexar os dados de exemplo, mas escolha uma camada mais alta se os volumes de dados forem grandes. Para camadas faturáveis, forneça a chave da API de pesquisa na etapa Configurar dependências mais adiante.
3 Este tutorial usa o Azure AI Document Intelligence e o Azure AI Translator. Nas instruções a seguir, forneça uma chave multisserviço e a região. A mesma chave funciona para ambos os serviços.
4 Neste tutorial, o Azure Databricks fornece a plataforma de computação Spark. Usamos as instruções do portal para configurar o espaço de trabalho.
Nota
Todos os recursos do Azure acima oferecem suporte a recursos de segurança na plataforma Microsoft Identity. Para simplificar, este tutorial pressupõe a autenticação baseada em chaves, usando pontos de extremidade e chaves copiadas das páginas do portal do Azure de cada serviço. Se você implementar esse fluxo de trabalho em um ambiente de produção ou compartilhar a solução com outras pessoas, lembre-se de substituir chaves codificadas por chaves de segurança integradas ou criptografadas.
Etapa 1: Criar um cluster e um bloco de anotações do Spark
Nesta seção, crie um cluster, instale a synapseml biblioteca e crie um bloco de anotações para executar o código.
No portal do Azure, localize seu espaço de trabalho do Azure Databricks e selecione Iniciar espaço de trabalho.
No menu à esquerda, selecione Computar.
Selecione Criar computação.
Aceite a configuração padrão. Leva vários minutos para criar o cluster.
Instale a
synapsemlbiblioteca após a criação do cluster:Selecione Bibliotecas nas guias na parte superior da página do cluster.
Selecione Instalar novo.
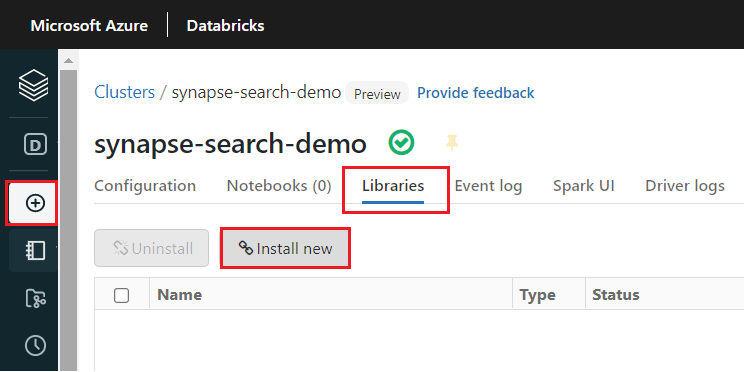
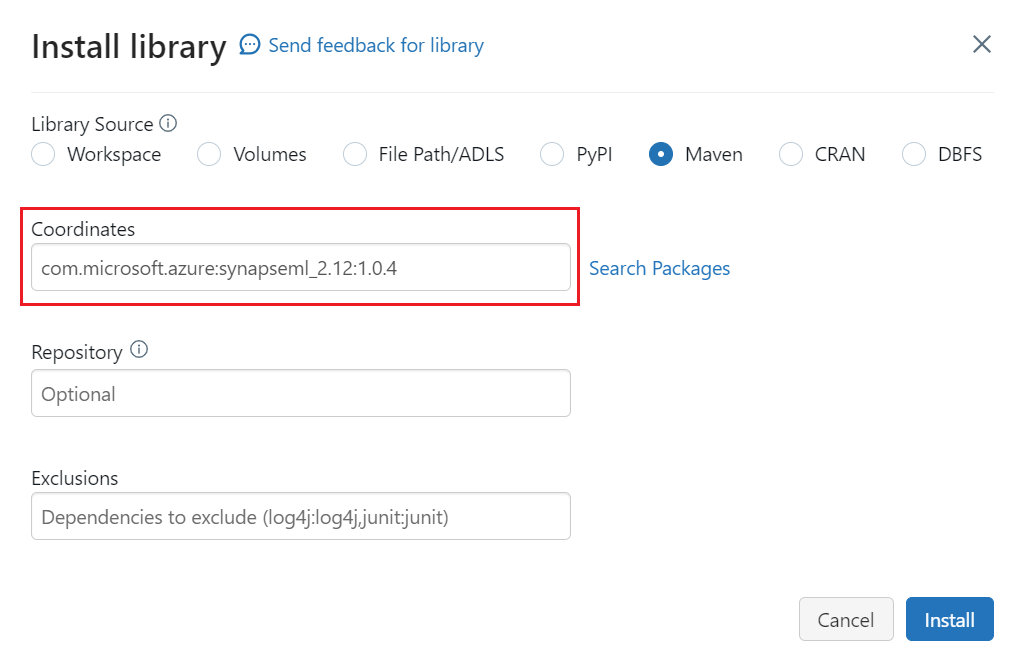
Selecione Maven.
Em Coordenadas, insira
com.microsoft.azure:synapseml_2.12:1.0.4Selecione Instalar.
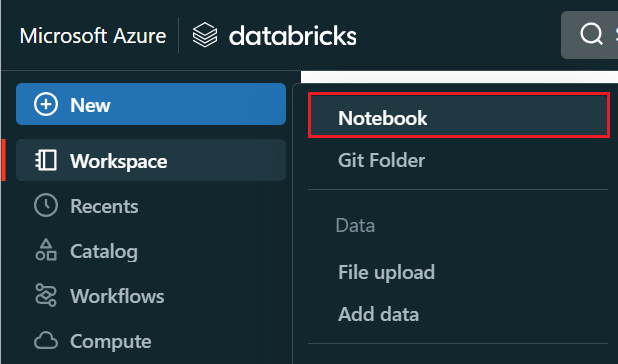
No menu à esquerda, selecione Criar>bloco de anotações.
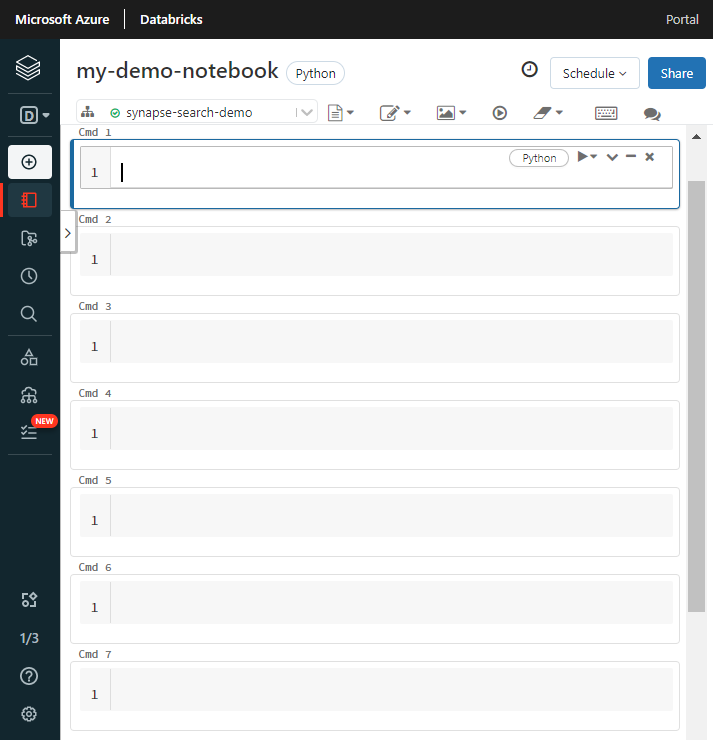
Dê um nome ao bloco de anotações, selecione Python como a linguagem padrão e selecione o cluster que tem a
synapsemlbiblioteca.Crie sete células consecutivas. Cole o código em cada um.
Etapa 2: Configurar dependências
Cole o código a seguir na primeira célula do seu bloco de anotações.
Substitua os espaços reservados por pontos de extremidade e chaves de acesso para cada recurso. Forneça um nome para um novo índice de pesquisa. Nenhuma outra modificação é necessária, então execute o código quando estiver pronto.
Esse código importa vários pacotes e configura o acesso aos recursos do Azure usados neste fluxo de trabalho.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Etapa 3: Carregar dados no Spark
Cole o código a seguir na segunda célula. Nenhuma modificação é necessária, então execute o código quando estiver pronto.
Esse código carrega alguns arquivos externos de uma conta de armazenamento do Azure. Os arquivos são várias faturas e são lidos em um quadro de dados.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Etapa 4: adicionar inteligência de documentos
Cole o código a seguir na terceira célula. Nenhuma modificação é necessária, então execute o código quando estiver pronto.
Esse código carrega o transformador AnalyzeInvoices e passa uma referência ao quadro de dados que contém as faturas. Ele chama o modelo de fatura pré-criado do Azure AI Document Intelligence para extrair informações das faturas.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
A saída desta etapa deve ser semelhante à próxima captura de tela. Observe como a análise de formulários é compactada em uma coluna densamente estruturada, que é difícil de trabalhar. A próxima transformação resolve esse problema analisando a coluna em linhas e colunas.
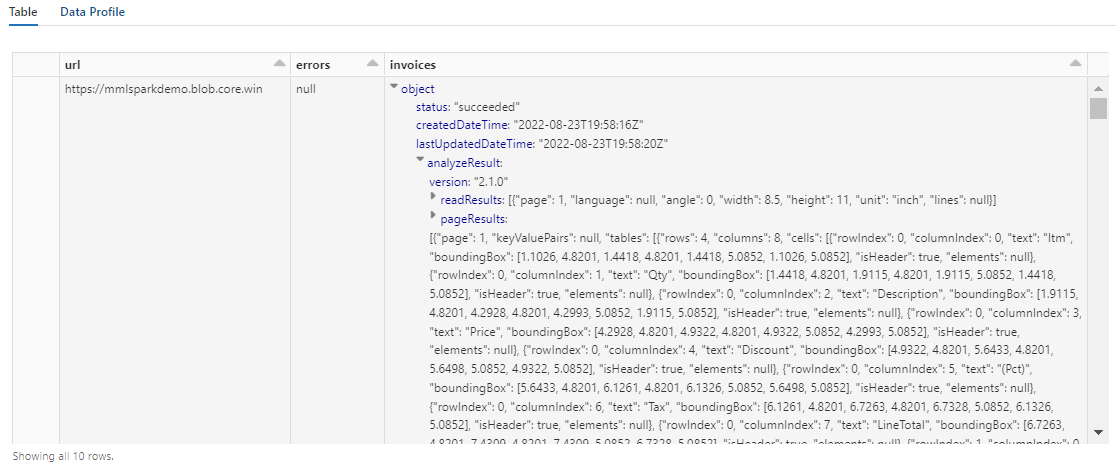
Etapa 5: Reestruturar a saída de inteligência de documentos
Cole o código a seguir na quarta célula e execute-o. Não são necessárias modificações.
Este código carrega o FormOntologyLearner, um transformador que analisa a saída de transformadores de Document Intelligence e infere uma estrutura de dados tabular. A saída de AnalyzeInvoices é dinâmica e varia de acordo com os recursos detetados em seu conteúdo. Além disso, o transformador consolida a saída em uma única coluna. Como a saída é dinâmica e consolidada, é difícil usá-la em transformações a jusante que exigem mais estrutura.
FormOntologyLearner estende a utilidade do transformador AnalyzeInvoices procurando padrões que podem ser usados para criar uma estrutura de dados tabular. Organizar a saída em várias colunas e linhas torna o conteúdo consumível em outros transformadores, como AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Observe como essa transformação reformula os campos aninhados em uma tabela, o que permite as próximas duas transformações. Esta captura de tela é cortada para maior brevidade. Se estiver a acompanhar no seu próprio bloco de notas, tem 19 colunas e 26 linhas.
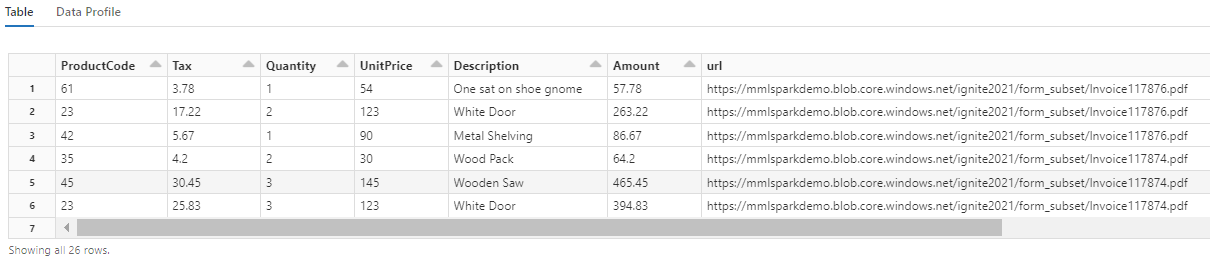
Etapa 6: adicionar traduções
Cole o código a seguir na quinta célula. Nenhuma modificação é necessária, então execute o código quando estiver pronto.
Esse código carrega Translate, um transformador que chama o serviço Azure AI Translator nos serviços de IA do Azure. O texto original, que está em inglês na coluna "Descrição", é traduzido automaticamente para vários idiomas. Toda a saída é consolidada na matriz "output.translations".
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Gorjeta
Para verificar se há cadeias de caracteres traduzidas, role até o final das linhas.
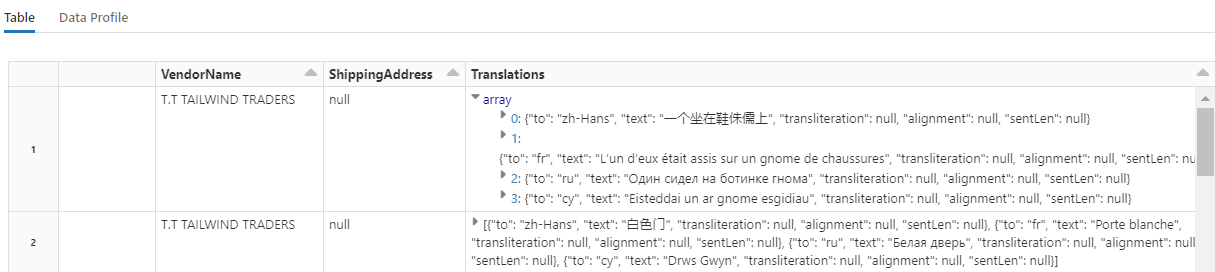
Etapa 7: Adicionar um índice de pesquisa com o AzureSearchWriter
Cole o código a seguir na sexta célula e execute-o. Não são necessárias modificações.
Esse código carrega AzureSearchWriter. Ele consome um conjunto de dados tabular e infere um esquema de índice de pesquisa que define um campo para cada coluna. Como a estrutura de traduções é uma matriz, ela é articulada no índice como uma coleção complexa com subcampos para cada tradução de idioma. O índice gerado tem uma chave de documento e usa os valores padrão para campos criados usando a API REST de criação de índice.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Você pode verificar as páginas de serviço de pesquisa no portal do Azure para explorar a definição de índice criada pelo AzureSearchWriter.
Nota
Se não for possível usar o índice de pesquisa padrão, você poderá fornecer uma definição personalizada externa em JSON, passando seu URI como uma cadeia de caracteres na propriedade "indexJson". Gere primeiro o índice padrão para saber quais campos especificar e, em seguida, siga com propriedades personalizadas se precisar de analisadores específicos, por exemplo.
Etapa 8: Consultar o índice
Cole o código a seguir na sétima célula e execute-o. Nenhuma modificação é necessária, exceto que você pode querer variar a sintaxe ou tentar mais exemplos para explorar ainda mais seu conteúdo:
- Sintaxe de consulta
- Query examples (Exemplos de consultas)
Não há transformador ou módulo que emita consultas. Esta célula é uma chamada simples para a API REST de Documentos de Pesquisa.
Este exemplo em particular está procurando pela palavra "porta" ("search": "door"). Ele também retorna uma "contagem" do número de documentos correspondentes e seleciona apenas o conteúdo dos campos "Descrição" e "Traduções" para os resultados. Se quiser ver a lista completa de campos, remova o parâmetro "select".
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
A captura de tela a seguir mostra a saída da célula para o script de exemplo.
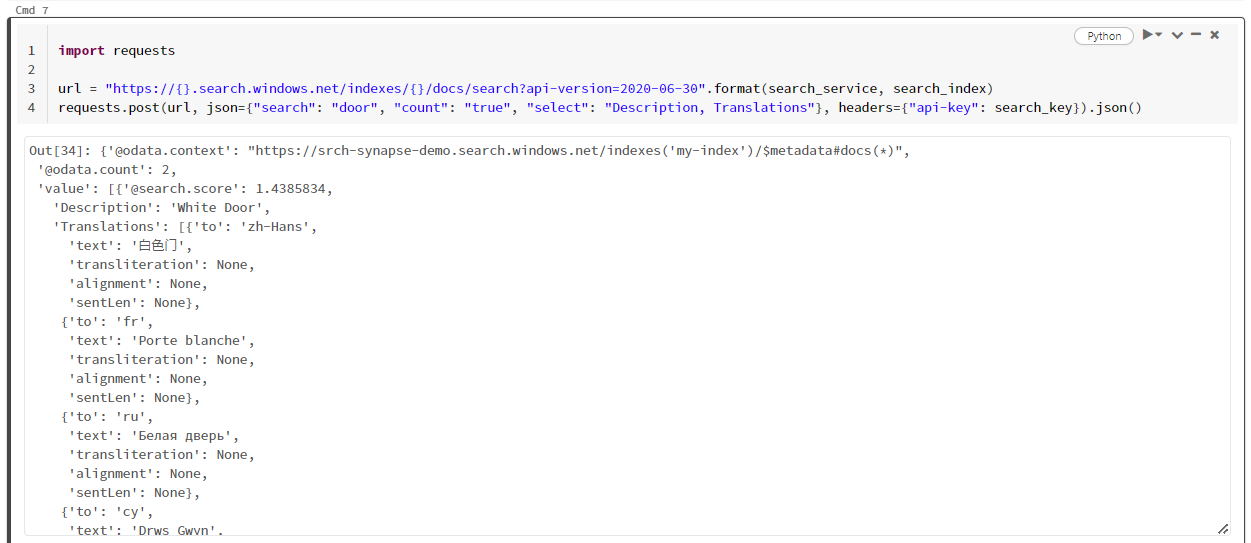
Clean up resources (Limpar recursos)
Quando estiver a trabalhar na sua própria subscrição, no final de um projeto, é uma boa ideia remover os recursos de que já não necessita. Os recursos que deixar em execução podem custar dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal do Azure, usando o link Todos os recursos ou Grupos de recursos no painel de navegação esquerdo.
Próximos passos
Neste tutorial, você aprendeu sobre o transformador AzureSearchWriter no SynapseML, que é uma nova maneira de criar e carregar índices de pesquisa no Azure AI Search. O transformador toma JSON estruturado como entrada. O FormOntologyLearner pode fornecer a estrutura necessária para a saída produzida pelos transformadores de Inteligência Documental no SynapseML.
Como próxima etapa, revise os outros tutoriais do SynapseML que produzem conteúdo transformado que você pode querer explorar por meio da Pesquisa de IA do Azure: