Guia de início rápido: analisar com o Data Explorer (visualização)
Neste artigo, você aprenderá as etapas básicas para carregar e analisar dados com o Data Explorer for Azure Synapse.
Criar um pool do Data Explorer
No Synapse Studio, no painel esquerdo, selecione Gerenciar>pools do Data Explorer.
Selecione Novo e insira os seguintes detalhes na guia Noções básicas :
Definição Valor sugerido Description Nome do pool do Data Explorer contosodataexplorer Este é o nome que o pool do Data Explorer terá. Carga de trabalho Com otimização de computação Essa carga de trabalho fornece uma maior relação de armazenamento CPU/SSD. Tamanho do nó Pequeno (4 núcleos) Defina isso para o menor tamanho para reduzir os custos deste início rápido Importante
Observe que há limitações específicas para os nomes que os pools do Data Explorer podem usar. Os nomes devem conter apenas letras minúsculas e números, devem ter entre 4 e 15 caracteres e devem começar com uma letra.
Selecione Rever + criar>Criar. O pool do Data Explorer iniciará o processo de provisionamento.
Criar um banco de dados do Data Explorer
No Synapse Studio, no painel do lado esquerdo, selecione Dados.
Selecione + (Adicionar novo recurso) >banco de dados do Data Explorer e cole as seguintes informações:
Definição Valor sugerido Description Nome do conjunto contosodataexplorer O nome do pool do Data Explorer a ser usado Nome TestDatabase O nome da base de dados tem de ser exclusivo dentro do cluster. Período de retenção predefinido 365 O período de tempo (em dias) durante o qual é garantido que os dados são mantidos disponíveis para consulta. O intervalo de tempo é medido desde o momento em que os dados são ingeridos. Período de cache padrão 31 O período de tempo (em dias) durante o qual manter os dados frequentemente consultados disponíveis no armazenamento SSD ou RAM, em vez de no armazenamento a longo prazo. Selecione Criar para criar o banco de dados. Normalmente, a criação demora menos de um minuto.
Ingerir dados de amostra e analisar com uma consulta simples
Depois que o pool for implantado, no Synapse Studio, no painel esquerdo, selecione Desenvolver.
Selecione + (Adicionar novo recurso) >script KQL. No painel do lado direito, você pode nomear seu script.
No menu Conectar a, selecione contosodataexplorer.
No menu Usar banco de dados, selecione TestDatabase.
Cole o comando a seguir e selecione Executar para criar uma tabela StormEvents.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Gorjeta
Verifique se a tabela foi criada com êxito. No painel esquerdo, selecione Dados, selecione o menu contosodataexplorer mais e selecione Atualizar. Em contosodataexplorer, expanda Tabelas e verifique se a tabela StormEvents aparece na lista.
Cole o comando a seguir e selecione Executar para ingerir dados na tabela StormEvents.
.ingest into table StormEvents 'https://kustosamples.blob.core.windows.net/samplefiles/StormEvents.csv' with (ignoreFirstRecord=true)Após a conclusão da ingestão, cole na consulta a seguir, selecione a consulta na janela e selecione Executar.
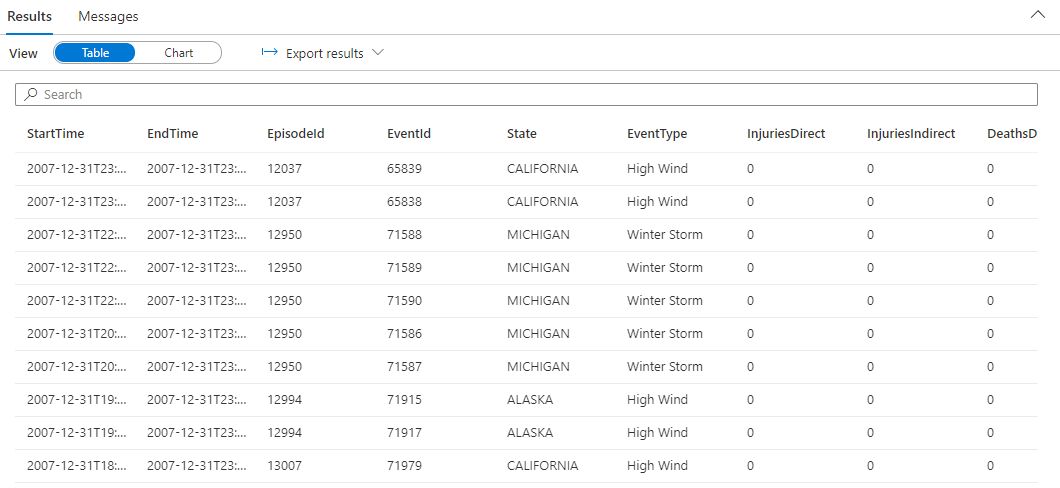
StormEvents | sort by StartTime desc | take 10A consulta retorna os seguintes resultados dos dados de exemplo ingeridos.