Migração de dados, ETL e carregamento para migrações netezza
Este artigo é a segunda parte de uma série de sete partes que fornece orientações sobre como migrar do Netezza para o Azure Synapse Analytics. O foco deste artigo são as melhores práticas para ETL e migração de carga.
Considerações sobre a migração de dados
Decisões iniciais para a migração de dados do Netezza
Ao migrar um armazém de dados netezza, tem de fazer algumas perguntas básicas relacionadas com dados. Por exemplo:
As estruturas de tabela não utilizadas devem ser migradas?
Qual é a melhor abordagem de migração para minimizar o risco e o impacto do utilizador?
Ao migrar data marts: mantenha-se físico ou virtual?
As secções seguintes abordam estes pontos no contexto da migração do Netezza.
Migrar tabelas não utilizadas?
Dica
Nos sistemas legados, não é incomum que as tabelas se tornem redundantes ao longo do tempo. Estes não precisam de ser migrados na maioria dos casos.
Faz sentido migrar apenas tabelas que estão a ser utilizadas no sistema existente. As tabelas que não estão ativas podem ser arquivadas em vez de migradas, para que os dados estejam disponíveis, se necessário no futuro. É melhor utilizar metadados do sistema e ficheiros de registo em vez de documentação para determinar que tabelas estão a ser utilizadas, uma vez que a documentação pode estar desatualizada.
Se estiver ativada, as tabelas do histórico de consultas do Netezza contêm informações que podem determinar quando uma determinada tabela foi acedida pela última vez, o que pode, por sua vez, ser utilizado para decidir se uma tabela é candidata à migração.
Eis uma consulta de exemplo que procura a utilização de uma tabela específica dentro de uma determinada janela de tempo:
SELECT FORMAT_TABLE_ACCESS (usage),
hq.submittime
FROM "$v_hist_queries" hq
INNER JOIN "$hist_table_access_3" hta USING
(NPSID, NPSINSTANCEID, OPID, SESSIONID)
WHERE hq.dbname = 'PROD'
AND hta.schemaname = 'ADMIN'
AND hta.tablename = 'TEST_1'
AND hq.SUBMITTIME > '01-01-2015'
AND hq.SUBMITTIME <= '08-06-2015'
AND
(
instr(FORMAT_TABLE_ACCESS(usage),'ins') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'upd') > 0
OR instr(FORMAT_TABLE_ACCESS(usage),'del') > 0
)
AND status=0;
| FORMAT_TABLE_ACCESS | SUBMITTIME
----------------------+---------------------------
ins | 2015-06-16 18:32:25.728042
ins | 2015-06-16 17:46:14.337105
ins | 2015-06-16 17:47:14.430995
(3 rows)
Esta consulta utiliza a função FORMAT_TABLE_ACCESS auxiliar e o dígito no final da $v_hist_table_access_3 vista para corresponder à versão do histórico de consultas instalada.
Qual é a melhor abordagem de migração para minimizar o risco e o impacto nos utilizadores?
Esta questão surge frequentemente porque as empresas podem querer reduzir o impacto das alterações no modelo de dados do armazém de dados para melhorar a agilidade. Muitas vezes, as empresas veem uma oportunidade de modernizar ou transformar ainda mais os seus dados durante uma migração ETL. Esta abordagem tem um risco mais elevado porque altera vários fatores em simultâneo, dificultando a comparação dos resultados do sistema antigo com o novo. Fazer alterações ao modelo de dados aqui também pode afetar as tarefas ETL a montante ou a jusante para outros sistemas. Devido a esse risco, é melhor redesenhar nesta escala após a migração do armazém de dados.
Mesmo que um modelo de dados seja alterado intencionalmente como parte da migração geral, é uma boa prática migrar o modelo existente tal como está para Azure Synapse, em vez de fazer qualquer reengenharia na nova plataforma. Esta abordagem minimiza o efeito nos sistemas de produção existentes, ao mesmo tempo que beneficia do desempenho e da escalabilidade elástica da plataforma do Azure para tarefas de reengenharia únicas.
Ao migrar do Netezza, muitas vezes o modelo de dados existente já é adequado para a migração tal como está para Azure Synapse.
Dica
Migrar o modelo existente tal como está inicialmente, mesmo que seja planeada uma alteração ao modelo de dados no futuro.
Migrar data marts: manter-se físico ou virtual?
Dica
A virtualização dos data marts pode ser guardada nos recursos de armazenamento e processamento.
Em ambientes legados do armazém de dados netezza, é prática comum criar vários data marts estruturados para proporcionar um bom desempenho para consultas e relatórios self-service ad hoc para um determinado departamento ou função empresarial numa organização. Como tal, um data mart consiste normalmente num subconjunto do armazém de dados e contém versões agregadas dos dados num formulário que permite aos utilizadores consultar facilmente esses dados com tempos de resposta rápidos através de ferramentas de consulta fáceis de utilizar, como o Microsoft Power BI, Tableau ou MicroStrategy. Normalmente, este formulário é um modelo de dados dimensional. Uma utilização dos data marts é expor os dados numa forma utilizável, mesmo que o modelo de dados do armazém subjacente seja algo diferente, como um cofre de dados.
Pode utilizar data marts separados para unidades de negócio individuais numa organização para implementar regimes de segurança de dados robustos, ao permitir que os utilizadores acedam a data marts específicos que lhes sejam relevantes e eliminando, obstinando ou anonimizando dados confidenciais.
Se estes data marts forem implementados como tabelas físicas, precisarão de recursos de armazenamento adicionais para armazená-los e processamento adicional para compilá-los e atualizá-los regularmente. Além disso, os dados no mercado só estarão tão atualizados como a última operação de atualização, pelo que podem não ser adequados para dashboards de dados altamente voláteis.
Dica
O desempenho e escalabilidade do Azure Synapse permite a virtualização sem sacrificar o desempenho.
Com o advento de arquiteturas MPP dimensionáveis relativamente de baixo custo, como Azure Synapse, e as características de desempenho inerentes dessas arquiteturas, pode ser que possa fornecer funcionalidades de data mart sem ter de instanciar o mercado como um conjunto de tabelas físicas. Isto é conseguido ao virtualizar eficazmente os data marts através de vistas SQL para o armazém de dados principal ou através de uma camada de virtualização com funcionalidades como vistas no Azure ou os produtos de visualização de parceiros da Microsoft. Esta abordagem simplifica ou elimina a necessidade de processamento adicional de armazenamento e agregação e reduz o número total de objetos de base de dados a migrar.
Há outro potencial benefício nesta abordagem. Ao implementar a lógica de agregação e associação numa camada de virtualização e ao apresentar ferramentas de relatórios externos através de uma vista virtualizada, o processamento necessário para criar estas vistas é "empurrado para baixo" para o armazém de dados, que é geralmente o melhor local para executar associações, agregações e outras operações relacionadas em grandes volumes de dados.
Os principais fatores para escolher uma implementação de data mart virtual em vez de um data mart físico são:
Mais agilidade: um data mart virtual é mais fácil de alterar do que as tabelas físicas e os processos ETL associados.
Menor custo total de propriedade: uma implementação virtualizada requer menos arquivos de dados e cópias de dados.
Eliminação de tarefas ETL para migrar e simplificar a arquitetura do armazém de dados num ambiente virtualizado.
Desempenho: embora os data marts físicos tenham sido historicamente mais eficazes, os produtos de virtualização implementam agora técnicas de colocação em cache inteligentes para mitigar.
Migração de dados do Netezza
Compreender os seus dados
Parte do planeamento da migração é compreender detalhadamente o volume de dados que precisa de ser migrado, uma vez que isso pode afetar as decisões sobre a abordagem de migração. Utilize metadados do sistema para determinar o espaço físico ocupado pelos "dados não processados" nas tabelas a migrar. Neste contexto, "dados não processados" significa a quantidade de espaço utilizado pelas linhas de dados numa tabela, excluindo sobrecargas como índices e compressão. Isto aplica-se especialmente às maiores tabelas de factos, uma vez que, normalmente, serão compostas por mais de 95% dos dados.
Pode obter um número preciso para que o volume de dados seja migrado para uma determinada tabela ao extrair uma amostra representativa dos dados (por exemplo, um milhão de linhas) para um ficheiro de dados ASCII simples delimitado não comprimido. Em seguida, utilize o tamanho desse ficheiro para obter um tamanho médio de dados não processados por linha dessa tabela. Por fim, multiplique esse tamanho médio pelo número total de linhas na tabela completa para dar um tamanho de dados não processado para a tabela. Utilize esse tamanho de dados não processado no seu planeamento.
Mapeamento do tipo de dados netezza
Dica
Avalie o impacto dos tipos de dados não suportados como parte da fase de preparação.
A maioria dos tipos de dados netezza tem um equivalente direto em Azure Synapse. A tabela seguinte mostra estes tipos de dados, juntamente com a abordagem recomendada para os mapear.
| Tipo de dados netezza | Azure Synapse tipo de dados |
|---|---|
| BIGINT | BIGINT |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEANO | BIT |
| BYTEINT | TINYINT |
| CARATERES VARIÁVEIS(n) | VARCHAR(n) |
| CARÁTER(n) | CHAR(n) |
| DATA | DATA(data) |
| DECIMAL(p;s) | DECIMAL(p;s) |
| PRECISÃO DUPLA | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVALO | Atualmente, os tipos de dados INTERVAL não são suportados diretamente no Azure Synapse Analytics, mas podem ser calculados com funções temporais, como DATEDIFF. |
| DINHEIRO | DINHEIRO |
| CARÁTER NACIONAL VARIANDO(n) | NVARCHAR(n) |
| CARÁTER NACIONAL(n) | NCHAR(n) |
| NUMERIC(p;s) | NUMERIC(p;s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Os tipos de dados espaciais, como ST_GEOMETRY não são atualmente suportados no Azure Synapse Analytics, mas os dados podem ser armazenados como VARCHAR ou VARBINARY. |
| HORA | HORA |
| HORA COM FUSO HORÁRIO | DATETIMEOFFSET |
| CARIMBO DE DATA/HORA | DATETIME |
Utilize os metadados das tabelas de catálogo do Netezza para determinar se algum destes tipos de dados precisa de ser migrado e permitir isso no seu plano de migração. As vistas de metadados importantes no Netezza para este tipo de consulta são:
_V_USER: a vista de utilizador fornece informações sobre os utilizadores no sistema Netezza._V_TABLE: a vista de tabela contém a lista de tabelas criadas no sistema de desempenho Netezza._V_RELATION_COLUMN: a vista de catálogo do sistema de colunas de relação contém as colunas disponíveis numa tabela._V_OBJECTS: a vista objetos lista os diferentes objetos, como tabelas, vistas, funções, entre outros, que estão disponíveis no Netezza.
Por exemplo, esta consulta SQL netezza mostra colunas e tipos de coluna:
SELECT
tablename,
attname AS COL_NAME,
b.FORMAT_TYPE AS COL_TYPE,
attnum AS COL_NUM
FROM _v_table a
JOIN _v_relation_column b
ON a.objid = b.objid
WHERE a.tablename = 'ATT_TEST'
AND a.schema = 'ADMIN'
ORDER BY attnum;
TABLENAME | COL_NAME | COL_TYPE | COL_NUM
----------+-------------+----------------------+--------
ATT_TEST | COL_INT | INTEGER | 1
ATT_TEST | COL_NUMERIC | NUMERIC(10,2) | 2
ATT_TEST | COL_VARCHAR | CHARACTER VARYING(5) | 3
ATT_TEST | COL_DATE | DATE | 4
(4 rows)
A consulta pode ser modificada para procurar em todas as tabelas quaisquer ocorrências de tipos de dados não suportados.
Azure Data Factory podem ser utilizadas para mover dados de um ambiente legado do Netezza. Para obter mais informações, veja CONECTOR IBM Netezza.
Os fornecedores de terceiros oferecem ferramentas e serviços para automatizar a migração, incluindo o mapeamento de tipos de dados, conforme descrito anteriormente. Além disso, as ferramentas ETL de terceiros, como a Informatica ou o Talend, já em utilização no ambiente Netezza, podem implementar todas as transformações de dados necessárias. A secção seguinte explora a migração de processos ETL de terceiros existentes.
Considerações sobre a migração de ETL
Decisões iniciais relativas à migração do Netezza ETL
Dica
Planeie a abordagem à migração etl com antecedência e tire partido das instalações do Azure sempre que adequado.
Para o processamento ETL/ELT, os armazéns de dados legados da Netezza podem utilizar scripts personalizados com utilitários Netezza, como nzsql e nzload, ou ferramentas ETL de terceiros, como Informatica ou Ab Initio. Por vezes, os armazéns de dados netezza utilizam uma combinação de abordagens ETL e ELT que evoluiu ao longo do tempo. Ao planear uma migração para Azure Synapse, tem de determinar a melhor forma de implementar o processamento ETL/ELT necessário no novo ambiente, minimizando o custo e o risco envolvidos. Para saber mais sobre o processamento de ETL e ELT, veja Abordagem de design ELT vs ETL.
As secções seguintes abordam as opções de migração e fazem recomendações para vários casos de utilização. Este fluxograma resume uma abordagem:
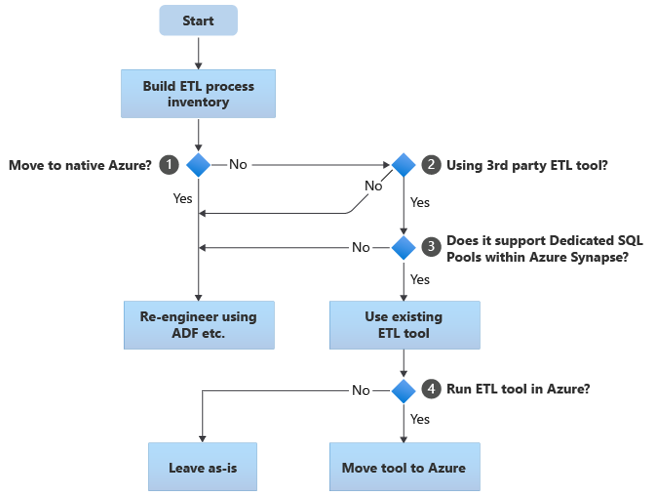
O primeiro passo é sempre criar um inventário de processos ETL/ELT que precisam de ser migrados. Tal como acontece com outros passos, é possível que as funcionalidades padrão do Azure "incorporadas" tornem desnecessário migrar alguns processos existentes. Para fins de planeamento, é importante compreender a escala da migração a realizar.
No fluxograma anterior, a decisão 1 diz respeito a uma decisão de alto nível sobre a migração para um ambiente totalmente nativo do Azure. Se estiver a mudar para um ambiente totalmente nativo do Azure, recomendamos que volte a criar o processamento ETL com Pipelines e atividades em pipelines Azure Data Factory ou Azure Synapse Pipelines. Se não estiver a mudar para um ambiente totalmente nativo do Azure, a decisão 2 é se já está a ser utilizada uma ferramenta ETL de terceiros existente.
Dica
Tire partido do investimento em ferramentas de terceiros existentes para reduzir o custo e o risco.
Se uma ferramenta ETL de terceiros já estiver a ser utilizada e, especialmente, se existir um grande investimento em competências ou vários fluxos de trabalho e agendamentos existentes utilizar essa ferramenta, a decisão 3 é se a ferramenta pode suportar eficientemente Azure Synapse como um ambiente de destino. Idealmente, a ferramenta incluirá conectores "nativos" que podem tirar partido das instalações do Azure, como o PolyBase ou COPY INTO, para o carregamento de dados mais eficiente. Existe uma forma de chamar um processo externo, como o PolyBase ou COPY INTO, e transmitir os parâmetros adequados. Neste caso, tire partido das competências e dos fluxos de trabalho existentes, com Azure Synapse como o novo ambiente de destino.
Se decidir manter uma ferramenta ETL de terceiros existente, poderá haver vantagens em executar essa ferramenta no ambiente do Azure (em vez de num servidor ETL no local existente) e ter Azure Data Factory processar a orquestração geral dos fluxos de trabalho existentes. Um benefício particular é que menos dados têm de ser transferidos do Azure, processados e, em seguida, carregados novamente para o Azure. Assim, a decisão 4 consiste em deixar a ferramenta existente em execução tal como está ou movê-la para o ambiente do Azure para obter benefícios de custos, desempenho e escalabilidade.
Reengenheirar scripts específicos do Netezza existentes
Se algum ou todos os processamentos ETL/ELT existentes do armazém netezza forem processados por scripts personalizados que utilizam utilitários específicos da Netezza, como nzsql ou nzload, estes scripts têm de ser recodificados para o novo ambiente de Azure Synapse. Da mesma forma, se os processos ETL tiverem sido implementados através de procedimentos armazenados no Netezza, estes também terão de ser recodificados.
Dica
O inventário de tarefas ETL a migrar deve incluir scripts e procedimentos armazenados.
Alguns elementos do processo ETL são fáceis de migrar, por exemplo, através da simples carga de dados em massa para uma tabela de teste a partir de um ficheiro externo. Pode até ser possível automatizar essas partes do processo, por exemplo, com o PolyBase em vez de nzload. Outras partes do processo que contêm procedimentos arbitrários complexos de SQL e/ou armazenados demorarão mais tempo a voltar a criar.
Uma forma de testar o NETezza SQL para compatibilidade com Azure Synapse é capturar algumas instruções SQL representativas do histórico de consultas netezza e, em seguida, prefixar essas consultas com EXPLAINe, em seguida, ( assumindo um modelo de dados migrado semelhante para semelhante no Azure Synapse ) executar essas EXPLAIN instruções no Azure Synapse. Qualquer SQL incompatível irá gerar um erro e as informações de erro podem determinar a escala da tarefa de recodificação.
Os parceiros da Microsoft oferecem ferramentas e serviços para migrar o NETezza SQL e os procedimentos armazenados para Azure Synapse.
Utilizar ferramentas ETL de terceiros
Conforme descrito na secção anterior, em muitos casos, o sistema de armazém de dados legado existente já será preenchido e mantido por produtos ETL de terceiros. Para obter uma lista de parceiros de integração de dados da Microsoft para Azure Synapse, veja Parceiros de integração de dados.
Carregamento de dados a partir do Netezza
Opções disponíveis ao carregar dados do Netezza
Dica
As ferramentas de terceiros podem simplificar e automatizar o processo de migração e, por conseguinte, reduzir o risco.
Quando se trata de migrar dados de um armazém de dados netezza, existem algumas questões básicas associadas ao carregamento de dados que têm de ser resolvidas. Terá de decidir como os dados serão movidos fisicamente do ambiente netezza no local existente para Azure Synapse na cloud e quais as ferramentas que serão utilizadas para efetuar a transferência e a carga. Considere as seguintes perguntas, que são abordadas nas secções seguintes.
Irá extrair os dados para ficheiros ou movê-los diretamente através de uma ligação de rede?
Irá orquestrar o processo a partir do sistema de origem ou do ambiente de destino do Azure?
Que ferramentas irá utilizar para automatizar e gerir o processo?
Transferir dados através de ficheiros ou ligação de rede?
Dica
Compreenda os volumes de dados a migrar e a largura de banda de rede disponível, uma vez que estes fatores influenciam a decisão de abordagem de migração.
Assim que as tabelas de bases de dados a migrar tiverem sido criadas no Azure Synapse, pode mover os dados para preencher essas tabelas do sistema Netezza legado e para o novo ambiente. Existem duas abordagens básicas:
Extração de ficheiros: extraia os dados das tabelas Netezza para ficheiros simples, normalmente no formato CSV, através de nzsql com a opção -o ou através da
CREATE EXTERNAL TABLEinstrução. Utilize uma tabela externa sempre que possível, uma vez que é a mais eficiente em termos de débito de dados. O seguinte exemplo de SQL cria um ficheiro CSV através de uma tabela externa:CREATE EXTERNAL TABLE '/data/export.csv' USING (delimiter ',') AS SELECT col1, col2, expr1, expr2, col3, col1 || col2 FROM your table;Utilize uma tabela externa se estiver a exportar dados para um sistema de ficheiros montado num anfitrião netezza local. Se estiver a exportar dados para um computador remoto com JDBC, ODBC ou OLEDB instalados, a opção "odbc de origem remota" é a
USINGcláusula .Esta abordagem requer espaço para localizar os ficheiros de dados extraídos. O espaço pode ser local para a base de dados de origem netezza (se estiver disponível armazenamento suficiente) ou remoto no Armazenamento de Blobs do Azure. O melhor desempenho é alcançado quando um ficheiro é escrito localmente, uma vez que evita a sobrecarga de rede.
Para minimizar os requisitos de armazenamento e transferência de rede, é boa prática comprimir os ficheiros de dados extraídos com um utilitário como o gzip.
Uma vez extraídos, os ficheiros simples podem ser movidos para Armazenamento de Blobs do Azure (agrupados com a instância Azure Synapse de destino) ou carregados diretamente para Azure Synapse com o PolyBase ou COPY INTO. O método para mover fisicamente dados do armazenamento local no local para o ambiente da cloud do Azure depende da quantidade de dados e da largura de banda de rede disponível.
A Microsoft fornece várias opções para mover grandes volumes de dados, incluindo o AzCopy para mover ficheiros através da rede para o Armazenamento do Azure, o Azure ExpressRoute para mover dados em massa através de uma ligação de rede privada e o Azure Data Box para ficheiros que se movem para um dispositivo de armazenamento físico que é depois enviado para um datacenter do Azure para carregamento. Para obter mais informações, veja Transferência de dados.
Extrair e carregar diretamente através da rede: o ambiente do Azure de destino envia um pedido de extração de dados, normalmente através de um comando SQL, para o sistema Netezza legado para extrair os dados. Os resultados são enviados através da rede e carregados diretamente para Azure Synapse, sem necessidade de colocar os dados em ficheiros intermédios. O fator limitativo neste cenário é normalmente a largura de banda da ligação de rede entre a base de dados Netezza e o ambiente do Azure. Para volumes de dados muito grandes, esta abordagem pode não ser prática.
Também existe uma abordagem híbrida que utiliza ambos os métodos. Por exemplo, pode utilizar a abordagem de extração de rede direta para tabelas de dimensões mais pequenas e amostras das tabelas de factos maiores para fornecer rapidamente um ambiente de teste no Azure Synapse. Para tabelas de factos históricos de grandes volumes, pode utilizar a abordagem de extração e transferência de ficheiros com o Azure Data Box.
Orquestrar a partir do Netezza ou do Azure?
A abordagem recomendada ao mover para Azure Synapse é orquestrar o extrato de dados e o carregamento a partir do ambiente do Azure com Azure Synapse Pipelines ou Azure Data Factory, bem como utilitários associados, como o PolyBase ou COPY INTO, para o carregamento de dados mais eficiente. Esta abordagem tira partido das capacidades do Azure e fornece um método fácil para criar pipelines de carregamento de dados reutilizáveis.
Outras vantagens desta abordagem incluem o impacto reduzido no sistema Netezza durante o processo de carregamento de dados, uma vez que o processo de gestão e carregamento está em execução no Azure e a capacidade de automatizar o processo com pipelines de carregamento de dados baseados em metadados.
Que ferramentas podem ser utilizadas?
A tarefa de transformação e movimento de dados é a função básica de todos os produtos ETL. Se um destes produtos já estiver a ser utilizado no ambiente Netezza existente, a utilização da ferramenta ETL existente poderá simplificar a migração de dados do Netezza para o Azure Synapse. Esta abordagem pressupõe que a ferramenta ETL suporta Azure Synapse como um ambiente de destino. Para obter mais informações sobre as ferramentas que suportam Azure Synapse, veja Parceiros de integração de dados.
Se estiver a utilizar uma ferramenta ETL, considere executar essa ferramenta no ambiente do Azure para beneficiar do desempenho, escalabilidade e custo da cloud do Azure e libertar recursos no datacenter do Netezza. Outro benefício é a redução do movimento de dados entre a cloud e os ambientes no local.
Resumo
Resumindo, as nossas recomendações para migrar dados e processos ETL associados do Netezza para Azure Synapse são:
Planeie com antecedência para garantir um exercício de migração bem-sucedido.
Crie um inventário detalhado de dados e processos para serem migrados o mais rapidamente possível.
Utilize metadados do sistema e ficheiros de registo para obter uma compreensão precisa dos dados e da utilização do processo. Não dependa da documentação, uma vez que pode estar desatualizada.
Compreenda os volumes de dados a migrar e a largura de banda de rede entre o datacenter no local e os ambientes na cloud do Azure.
Tire partido das funcionalidades do Azure "incorporadas" padrão para minimizar a carga de trabalho de migração.
Identifique e compreenda as ferramentas mais eficientes para extração e carregamento de dados em ambientes do Netezza e do Azure. Utilize as ferramentas adequadas em cada fase do processo.
Utilize instalações do Azure, como pipelines do Azure Synapse ou Azure Data Factory, para orquestrar e automatizar o processo de migração, minimizando o impacto no sistema Netezza.
Passos seguintes
Para saber mais sobre as operações de acesso de segurança, veja o próximo artigo desta série: Segurança, acesso e operações para migrações netezza.