Otimização do desempenho com vistas materializadas com o conjunto de SQL dedicado no Azure Synapse Analytics
No conjunto de SQL dedicado, as vistas materializadas fornecem um método de baixa manutenção para consultas analíticas complexas para obter um desempenho rápido sem qualquer alteração de consulta. Este artigo aborda as orientações gerais sobre a utilização de vistas materializadas.
Vistas materializadas vs. vistas padrão
O conjunto de SQL suporta vistas padrão e materializadas. Ambas são tabelas virtuais criadas com expressões SELECT e apresentadas a consultas como tabelas lógicas. As vistas revelam a complexidade da computação de dados comuns e adicionam uma camada de abstração às alterações de computação para que não seja necessário reescrever consultas.
Uma vista padrão calcula os respetivos dados sempre que a vista é utilizada. Não existem dados armazenados no disco. Pessoas normalmente utilizam vistas padrão como uma ferramenta que ajuda a organizar os objetos lógicos e as consultas numa base de dados. Para utilizar uma vista padrão, uma consulta tem de fazer referência direta à mesma.
Uma vista materializada pré-calcula, armazena e mantém os respetivos dados no conjunto de SQL dedicado, tal como uma tabela. A recompilação não é necessária sempre que é utilizada uma vista materializada. É por isso que as consultas que utilizam todos ou um subconjunto dos dados em vistas materializadas podem obter um desempenho mais rápido. Melhor ainda, as consultas podem utilizar uma vista materializada sem fazer referência direta à mesma, pelo que não é necessário alterar o código da aplicação.
A maioria dos requisitos de vista padrão ainda se aplicam a uma vista materializada. Para obter detalhes sobre a sintaxe da vista materializada e outros requisitos, consulte CRIAR VISTA MATERIALIZADA COMO SELECIONAR.
| Comparação | Vista | Vista materializada |
|---|---|---|
| Ver definição | Armazenado no armazém de dados do Azure. | Armazenado no armazém de dados do Azure. |
| Ver conteúdos | Gerado sempre que a vista é utilizada. | Pré-processado e armazenado no armazém de dados do Azure durante a criação da vista. Atualizado à medida que os dados são adicionados às tabelas subjacentes. |
| Atualização de dados | Sempre atualizado | Sempre atualizado |
| Velocidade para obter dados de visualização de consultas complexas | Lento | Rápido |
| Armazenamento extra | No | Yes |
| Syntax | CREATE VIEW | CRIAR VISTA MATERIALIZADA COMO SELECIONAR |
Benefícios de vistas materializadas
Uma vista materializada devidamente concebida proporciona as seguintes vantagens:
Tempo de execução reduzido para consultas complexas com JOINs e funções de agregação. Quanto mais complexa for a consulta, maior será o potencial de poupança de tempo de execução. O maior benefício é obtido quando o custo de computação de uma consulta é elevado e o conjunto de dados resultante é pequeno.
O otimizador de consultas no conjunto de SQL dedicado pode utilizar automaticamente vistas materializadas implementadas para melhorar os planos de execução de consultas. Este processo é transparente para os utilizadores que fornecem um desempenho de consulta mais rápido e não requer consultas para fazer referência direta às vistas materializadas.
Requer pouca manutenção nas vistas. Uma vista materializada armazena dados em dois locais, um índice columnstore em cluster para os dados iniciais no momento de criação da vista e um arquivo delta para as alterações de dados incrementais. Todas as alterações de dados das tabelas base são automaticamente adicionadas ao arquivo delta de forma síncrona. Um processo em segundo plano (tuple mover) move periodicamente os dados do arquivo delta para o índice columnstore da vista. Esta estrutura permite consultar vistas materializadas para devolver os mesmos dados que consultar diretamente as tabelas base.
Os dados numa vista materializada podem ser distribuídos de forma diferente das tabelas base.
Os dados em vistas materializadas obtêm os mesmos benefícios de elevada disponibilidade e resiliência que os dados em tabelas regulares.
Em comparação com outros fornecedores de armazém de dados, as vistas materializadas implementadas no conjunto de SQL dedicado também proporcionam os seguintes benefícios adicionais:
- Atualização automática e síncrona de dados com alterações de dados em tabelas base. Não é necessária nenhuma ação do utilizador.
- Suporte de funções de agregação abrangente. Veja CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL).
- O suporte para a recomendação de vista materializada específica da consulta. Veja EXPLAIN (Transact-SQL).
Cenários comuns
Normalmente, as vistas materializadas são utilizadas nos seguintes cenários:
Precisa de melhorar o desempenho de consultas analíticas complexas em relação a dados grandes em tamanho
Normalmente, as consultas analíticas complexas utilizam mais funções de agregação e associações de tabelas, o que causa mais operações de computação intensiva, como aleatorizações e associações na execução de consultas. É por isso que essas consultas demoram mais tempo a ser concluídas, especialmente em tabelas grandes.
Os utilizadores podem criar vistas materializadas para os dados devolvidos a partir dos cálculos comuns das consultas, pelo que não é necessária uma recompilação quando estes dados são necessários por consultas, permitindo um custo de computação mais baixo e uma resposta de consulta mais rápida.
Precisa de um desempenho mais rápido sem alterações mínimas ou sem alterações de consulta
Normalmente, as alterações de esquemas e consultas nos armazéns de dados são mantidas no mínimo para suportar operações e relatórios de ETL regulares. Pessoas podem utilizar vistas materializadas para otimização do desempenho de consultas se o custo incorrido pelas vistas puder ser compensado pelo ganho no desempenho da consulta.
Em comparação com outras opções de otimização, como o dimensionamento e a gestão de estatísticas, é uma alteração de produção muito menos impactante para criar e manter uma vista materializada e o seu potencial ganho de desempenho também é maior.
- Criar ou manter vistas materializadas não afeta as consultas em execução nas tabelas de base.
- O otimizador de consultas pode utilizar automaticamente as vistas materializadas implementadas sem referência de vista direta numa consulta. Esta capacidade reduz a necessidade de alteração de consultas na otimização do desempenho.
Precisa de uma estratégia de distribuição de dados diferente para um desempenho de consulta mais rápido
O armazém de dados do Azure é um sistema de processamento paralelo distribuído e em massa (MPP).
O Synapse SQL é um sistema de consultas distribuído que permite às empresas implementar cenários de virtualização de dados e armazenamento de dados com experiências padrão de T-SQL familiares aos engenheiros de dados. Também expande as capacidades do SQL para abordar cenários de transmissão em fluxo e machine learning. Os dados numa tabela de armazém de dados são distribuídos por 60 nós com uma de três estratégias de distribuição (hash, round robin ou replicada).
A distribuição de dados é especificada no momento de criação da tabela e permanece inalterada até que a tabela seja removida. Vista materializada, sendo uma tabela virtual no disco, suporta as distribuições de dados hash e round robin. Os utilizadores podem escolher uma distribuição de dados diferente das tabelas base, mas ideal para o desempenho das consultas que utilizam frequentemente as vistas.
Orientações de conceção
Eis as orientações gerais sobre como utilizar vistas materializadas para melhorar o desempenho das consultas:
Estruturar para a carga de trabalho
Antes de começar a criar vistas materializadas, é importante ter uma compreensão profunda da carga de trabalho em termos de padrões de consulta, importância, frequência e o tamanho dos dados resultantes.
Os utilizadores podem executar a WITH_RECOMMENDATIONS EXPLAIN SQL_statement <> para as vistas materializadas recomendadas pelo otimizador de consultas. Uma vez que estas recomendações são específicas de consultas, uma vista materializada que beneficia uma única consulta pode não ser ideal para outras consultas na mesma carga de trabalho.
Avalie estas recomendações tendo em conta as suas necessidades de carga de trabalho. As vistas materializadas ideais são aquelas que beneficiam o desempenho da carga de trabalho.
Tenha em atenção o compromisso entre consultas mais rápidas e o custo
Para cada vista materializada, existe um custo de armazenamento de dados e um custo para manter a vista. À medida que os dados mudam nas tabelas base, o tamanho da vista materializada aumenta e a estrutura física também muda.
Para evitar a degradação do desempenho das consultas, cada vista materializada é mantida separadamente pelo motor do armazém de dados, incluindo mover linhas do arquivo delta para os segmentos de índice columnstore e consolidar alterações de dados.
A carga de trabalho de manutenção aumenta quando o número de vistas materializadas e de tabela base aumenta. Os utilizadores devem verificar se o custo incorrido a partir de todas as vistas materializadas pode ser compensado pelo ganho de desempenho da consulta.
Pode executar esta consulta para obter a lista de vistas materializadas numa base de dados:
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Opções para reduzir o número de vistas materializadas:
Identifique conjuntos de dados comuns frequentemente utilizados pelas consultas complexas na sua carga de trabalho. Crie vistas materializadas para armazenar esses conjuntos de dados para que o otimizador os possa utilizar como blocos modulares ao criar planos de execução.
Remova as vistas materializadas que têm baixa utilização ou que já não são necessárias. Uma vista materializada desativada não é mantida, mas ainda implica custos de armazenamento.
Combine vistas materializadas criadas nas mesmas tabelas base ou tabelas de base semelhantes, mesmo que os dados não se sobreponham. Combinar vistas materializadas pode resultar numa vista maior em tamanho do que a soma das vistas separadas, no entanto, o custo de manutenção da vista deve reduzir. Por exemplo:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single materialized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Nem toda a otimização do desempenho requer alteração de consulta
O otimizador do armazém de dados pode utilizar automaticamente vistas materializadas implementadas para melhorar o desempenho das consultas. Este suporte é aplicado de forma transparente a consultas que não referenciam as vistas e a consultas que utilizam agregações não suportadas na criação de vistas materializadas. Não é necessária nenhuma alteração de consulta. Pode verificar o plano de execução estimado de uma consulta para confirmar se é utilizada uma vista materializada.
- Para obter mais informações sobre como obter o plano de execução real, veja Monitorizar a carga de trabalho do conjunto de SQL dedicado do Azure Synapse Analytics com DMVs.
- Pode obter um plano de execução estimado através de SQL Server Management Studio (SSMS) ou set SHOWPLAN_XML.
Monitorizar vistas materializadas
Uma vista materializada é armazenada no armazém de dados tal como uma tabela com índice columnstore em cluster (CCI). A leitura de dados de uma vista materializada inclui analisar o índice e aplicar alterações a partir do arquivo delta. Quando o número de linhas no arquivo delta é demasiado elevado, a resolução de uma consulta a partir de uma vista materializada pode demorar mais tempo do que consultar diretamente as tabelas base.
Para evitar a degradação do desempenho de consultas, é uma boa prática executar PDW_SHOWMATERIALIZEDVIEWOVERHEAD DBCC para monitorizar a overhead_ratio da vista (total_rows/base_view_row). Se a overhead_ratio for demasiado elevada, considere reconstruir a vista materializada para que todas as linhas no arquivo delta sejam movidas para o índice columnstore.
Colocação em cache da vista materializada e do conjunto de resultados
Estas duas funcionalidades são introduzidas no conjunto de SQL dedicado ao mesmo tempo para otimização do desempenho de consultas. A colocação em cache de conjuntos de resultados é utilizada para alcançar tempos de resposta rápidos e de simultaneidade elevada a partir de consultas repetitivas em relação a dados estáticos.
Para utilizar o resultado em cache, a forma da consulta de pedido da cache tem de corresponder à consulta que produziu a cache. Além disso, o resultado em cache tem de ser aplicado a toda a consulta.
As vistas materializadas permitem alterações de dados nas tabelas base. Os dados em vistas materializadas podem ser aplicados a uma parte de uma consulta. Este suporte permite que as mesmas vistas materializadas sejam utilizadas por diferentes consultas que partilham alguma computação para um desempenho mais rápido.
Exemplo
Este exemplo utiliza uma consulta semelhante a TPCDS que localiza clientes que gastam mais dinheiro através do catálogo do que nas lojas. Também identifica os clientes preferenciais e o respetivo país/região de origem. A consulta envolve a seleção dos 100 registos TOP na UNION de três instruções sub-SELECT que envolvem SUM() e GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Verifique o plano de execução estimado da consulta. Existem 18 operações aleatórias e 17 associações, que demoram mais tempo a ser executadas.
Agora, vamos criar uma vista materializada para cada uma das três instruções sub-SELECT.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Verifique novamente o plano de execução da consulta original. Agora, o número de associações muda de 17 para 5 e já não há aleatorização. Selecione o ícone Operação de filtro no plano. A Lista de Saída mostra que os dados são lidos a partir das vistas materializadas em vez de tabelas de base.
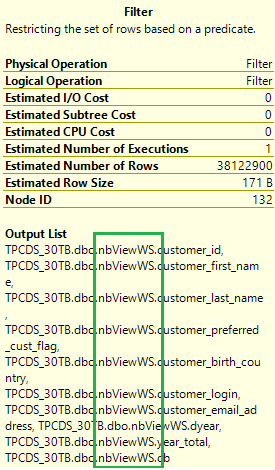
Com vistas materializadas, a mesma consulta é executada muito mais rapidamente sem qualquer alteração de código.
Passos seguintes
Para obter mais sugestões de desenvolvimento, veja Descrição geral do desenvolvimento do SQL do Synapse.