Configurar o Message Passing Interface para HPC
Aplica-se a: ✔️ VMs ✔️ Linux VMs ✔️ do Windows Conjuntos ✔️ de escala flexíveis Conjuntos de balanças uniformes
O Message Passing Interface (MPI) é uma biblioteca aberta e padrão de fato para paralelização de memória distribuída. É comumente usado em muitas cargas de trabalho de HPC. As cargas de trabalho HPC nas VMs das séries HB e N compatíveis com RDMA podem usar o MPI para se comunicar através da rede InfiniBand de baixa latência e alta largura de banda.
- Os tamanhos de VM habilitados para SR-IOV no Azure permitem que quase qualquer tipo de MPI seja usado com o Mellanox OFED.
- Em VMs não habilitadas para SR-IOV, as implementações MPI com suporte usam a interface Microsoft Network Direct (ND) para se comunicar entre VMs. Assim, apenas as versões Microsoft MPI (MS-MPI) 2012 R2 ou posterior e Intel MPI 5.x são suportadas. As versões posteriores (2017, 2018) da biblioteca de tempo de execução Intel MPI podem ou não ser compatíveis com os drivers RDMA do Azure.
Para VMs compatíveis com RDMA habilitadas para SR-IOV, as imagens de VM Ubuntu-HPC e as imagens de VM AlmaLinux-HPC são adequadas. Essas imagens VM vêm otimizadas e pré-carregadas com os drivers OFED para RDMA e várias bibliotecas MPI comumente usadas e pacotes de computação científica e são a maneira mais fácil de começar.
Embora os exemplos aqui sejam para RHEL, mas as etapas são gerais e podem ser usadas para qualquer sistema operacional Linux compatível, como Ubuntu (18.04, 20.04, 22.04) e SLES (12 SP4 e 15 SP4). Mais exemplos para configurar outras implementações MPI em outras distros está no repositório azhpc-images.
Nota
A execução de trabalhos MPI em VMs habilitadas para SR-IOV com determinadas bibliotecas MPI (como a plataforma MPI) pode exigir a configuração de chaves de partição (chaves p) em um locatário para isolamento e segurança. Siga as etapas na seção Descobrir chaves de partição para obter detalhes sobre como determinar os valores de chave p e configurá-los corretamente para um trabalho MPI com essa biblioteca MPI.
Nota
Os trechos de código abaixo são exemplos. Recomendamos usar as versões estáveis mais recentes dos pacotes, ou fazer referência ao repositório azhpc-images.
Escolhendo a biblioteca MPI
Se um aplicativo HPC recomendar uma biblioteca MPI específica, tente essa versão primeiro. Se tiver flexibilidade em relação ao IPM que pode escolher e quiser o melhor desempenho, experimente o HPC-X. No geral, o HPC-X MPI tem o melhor desempenho usando a estrutura UCX para a interface InfiniBand e aproveita todos os recursos de hardware e software Mellanox InfiniBand. Além disso, HPC-X e OpenMPI são compatíveis com ABI, para que você possa executar dinamicamente um aplicativo HPC com HPC-X que foi construído com OpenMPI. Da mesma forma, Intel MPI, MVAPICH e MPICH são compatíveis com ABI.
A figura a seguir ilustra a arquitetura das populares bibliotecas MPI.
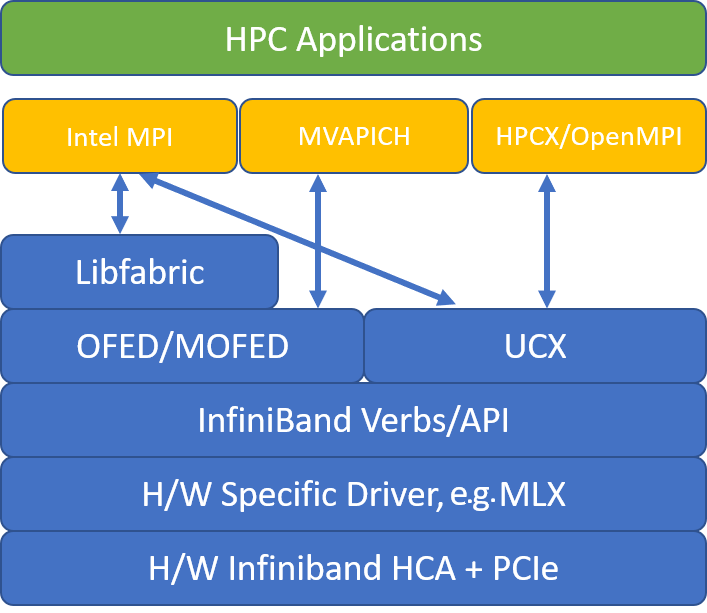
HPC-X
O kit de ferramentas de software HPC-X contém UCX e HCOLL e pode ser construído contra UCX.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
O comando a seguir ilustra alguns argumentos mpirun recomendados para HPC-X e OpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
onde:
| Parâmetro | Description |
|---|---|
NPROCS |
Especifica o número de processos MPI. Por exemplo: -n 16. |
$HOSTFILE |
Especifica um arquivo contendo o nome do host ou endereço IP, para indicar o local onde os processos MPI são executados. Por exemplo: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Especifica o número de processos MPI executados em cada domínio NUMA. Por exemplo, para especificar quatro processos MPI por NUMA, use --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Especifica o número de threads por processo MPI. Por exemplo, para especificar um processo MPI e quatro threads por NUMA, use --map-by ppr:1:numa:pe=4. |
-report-bindings |
Imprime o mapeamento de processos MPI para núcleos, o que é útil para verificar se a fixação do processo MPI está correta. |
$MPI_EXECUTABLE |
Especifica o executável MPI criado vinculando em bibliotecas MPI. Os wrappers do compilador MPI fazem isso automaticamente. Por exemplo: mpicc ou mpif90. |
Um exemplo de execução do microbenchmark de latência OSU é o seguinte:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
Otimizando coletivos MPI
Os primitivos de comunicação coletiva do IPM oferecem uma maneira flexível e portátil de implementar operações de comunicação em grupo. Eles são amplamente utilizados em várias aplicações científicas paralelas e têm um impacto significativo no desempenho geral do aplicativo. Consulte o artigo TechCommunity para obter detalhes sobre parâmetros de configuração para otimizar o desempenho da comunicação coletiva usando a biblioteca HPC-X e HCOLL para comunicação coletiva.
Por exemplo, se suspeitar que a sua aplicação MPI fortemente acoplada está a fazer uma quantidade excessiva de comunicação coletiva, pode tentar ativar coletivos hierárquicos (HCOLL). Para habilitar esses recursos, use os seguintes parâmetros.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Nota
Com o HPC-X 2.7.4+, pode ser necessário passar explicitamente LD_LIBRARY_PATH se a versão UCX no MOFED versus a versão no HPC-X for diferente.
OpenMPI
Instale o UCX conforme descrito acima. O HCOLL faz parte do kit de ferramentas de software HPC-X e não requer instalação especial.
OpenMPI pode ser instalado a partir dos pacotes disponíveis no repo.
sudo yum install –y openmpi
Recomendamos a criação de uma versão mais recente e estável do OpenMPI com UCX.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
Para um desempenho ideal, execute o OpenMPI com ucx e hcoll. Veja também o exemplo com HPC-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
Verifique a sua chave de partição como mencionado acima.
Intel MPI
Faça o download da versão escolhida do Intel MPI. A versão Intel MPI 2019 mudou da estrutura Open Fabrics Alliance (OFA) para a estrutura Open Fabrics Interfaces (OFI) e atualmente suporta libfabric. Existem dois provedores para suporte InfiniBand: mlx e verbos. Altere a variável de ambiente I_MPI_FABRICS dependendo da versão.
- Intel MPI 2019 e 2021: use
I_MPI_FABRICS=shm:ofi,I_MPI_OFI_PROVIDER=mlx. Omlxprovedor usa UCX. O uso de verbos foi considerado instável e menos eficiente. Consulte o artigo TechCommunity para obter mais detalhes. - Intel MPI 2018: uso
I_MPI_FABRICS=shm:ofa - Intel MPI 2016: uso
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
Aqui estão alguns argumentos mpirun sugeridos para a atualização 5+ do Intel MPI 2019.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
onde:
| Parâmetro | Description |
|---|---|
FI_PROVIDER |
Especifica qual provedor libfabric usar, o que afetará a API, o protocolo e a rede usados. verbos é outra opção, mas geralmente mlx dá-lhe melhor desempenho. |
I_MPI_DEBUG |
Especifica o nível de saída de depuração extra, que pode fornecer detalhes sobre onde os processos são fixados e qual protocolo e rede são usados. |
I_MPI_PIN_DOMAIN |
Especifica como você deseja fixar seus processos. Por exemplo, você pode fixar núcleos, soquetes ou domínios NUMA. Neste exemplo, você define essa variável ambiental como numa, o que significa que os processos serão fixados em domínios de nó NUMA. |
Otimizando coletivos MPI
Existem algumas outras opções que você pode tentar, especialmente se as operações coletivas estão consumindo uma quantidade significativa de tempo. A atualização 5+ do Intel MPI 2019 suporta o fornecer mlx e usa a estrutura UCX para se comunicar com o InfiniBand. Também suporta HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
VMs não SR-IOV
Para VMs não SR-IOV, um exemplo de download da versão de avaliação 5.x runtime free é o seguinte:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
Para conhecer as etapas de instalação, consulte o Guia de instalação da biblioteca Intel MPI. Opcionalmente, você pode habilitar o ptrace para processos não-raiz não-depurador (necessário para as versões mais recentes do Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
Para versões de imagem de VM do SUSE Linux Enterprise Server - SLES 12 SP3 para HPC, SLES 12 SP3 para HPC (Premium), SLES 12 SP1 para HPC, SLES 12 SP1 para HPC (Premium), SLES 12 SP4 e SLES 15, os drivers RDMA são instalados e os pacotes Intel MPI são distribuídos na VM. Instale o Intel MPI executando o seguinte comando:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
Segue-se um exemplo de construção de MVAPICH2. Observe que versões mais recentes podem estar disponíveis do que as usadas abaixo.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
Um exemplo de execução do microbenchmark de latência OSU é o seguinte:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
A lista a seguir contém vários argumentos recomendados mpirun .
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
onde:
| Parâmetro | Description |
|---|---|
MV2_CPU_BINDING_POLICY |
Especifica qual política de vinculação usar, o que afetará como os processos são fixados às IDs principais. Nesse caso, você especifica scatter, para que os processos sejam distribuídos uniformemente entre os domínios NUMA. |
MV2_CPU_BINDING_LEVEL |
Especifica onde fixar processos. Nesse caso, você o define como numanode, o que significa que os processos são fixados em unidades de domínios NUMA. |
MV2_SHOW_CPU_BINDING |
Especifica se você deseja obter informações de depuração sobre onde os processos são fixados. |
MV2_SHOW_HCA_BINDING |
Especifica se você deseja obter informações de depuração sobre qual adaptador de canal de host cada processo está usando. |
Plataforma MPI
Instale os pacotes necessários para o Platform MPI Community Edition.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
Siga o processo de instalação.
MPICH
Instale o UCX conforme descrito acima. Construa o MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
Executando o MPICH.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
Verifique a sua chave de partição como mencionado acima.
OSU MPI Benchmarks
Download OSU MPI Benchmarks e untar.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
Crie benchmarks usando uma biblioteca MPI específica:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
Os benchmarks do IPM estão na mpi/ pasta.
Descubra chaves de partição
Descubra chaves de partição (chaves p) para comunicação com outras VMs dentro do mesmo locatário (Conjunto de Disponibilidade ou Conjunto de Escala de Máquina Virtual).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
A maior das duas é a chave de inquilino que deve ser usada com o IPM. Exemplo: Se as seguintes forem as chaves p, 0x800b devem ser usadas com MPI.
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
Observação As interfaces são nomeadas como mlx5_ib* dentro de imagens de VM HPC.
Observe também que, enquanto o locatário (Conjunto de Disponibilidade ou Conjunto de Escala de Máquina Virtual) existir, os PKEYs permanecerão os mesmos. Isso é verdade mesmo quando nós são adicionados/excluídos. Os novos inquilinos obtêm diferentes PKEYs.
Configurar limites de usuário para MPI
Configure limites de usuário para MPI.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
Configurar chaves SSH para MPI
Configure chaves SSH para tipos de MPI que o exijam.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
A sintaxe acima pressupõe um diretório base compartilhado, caso contrário .ssh , o diretório deve ser copiado para cada nó.
Próximos passos
- Saiba mais sobre as VMs das séries HB e N habilitadas para InfiniBand.
- Analise a visão geral da série HBv3 e a visão geral da série HC.
- Leia Posicionamento ideal do processo MPI para VMs da série HB.
- Leia sobre os anúncios mais recentes, exemplos de carga de trabalho HPC e resultados de desempenho nos Blogs da Comunidade de Tecnologia de Computação do Azure.
- Para obter uma exibição de arquitetura de nível superior da execução de cargas de trabalho HPC, consulte Computação de alto desempenho (HPC) no Azure.