Migrar a definição de trabalho do Spark do Azure Synapse para o Fabric
Para mover as definições de trabalho do Spark (SJD) do Azure Synapse para o Fabric, você tem duas opções diferentes:
- Opção 1: criar a definição de trabalho do Spark manualmente no Fabric.
- Opção 2: você pode usar um script para exportar definições de trabalho do Spark do Azure Synapse e importá-las no Fabric usando a API.
Para obter considerações sobre a definição de trabalho do Spark, consulte as diferenças entre o Azure Synapse Spark e o Fabric.
Pré-requisitos
Se você ainda não tiver um, crie um espaço de trabalho de malha em seu locatário.
Opção 1: Criar definição de trabalho do Spark manualmente
Para exportar uma definição de trabalho do Spark do Azure Synapse:
- Abra o Synapse Studio: entre no Azure. Navegue até o espaço de trabalho do Azure Synapse e abra o Synapse Studio.
- Localize o trabalho Python/Scala/R Spark: localize e identifique a definição de trabalho Python/Scala/R Spark que você deseja migrar.
- Exporte a configuração de definição de tarefa:
- No Synapse Studio, abra a definição de trabalho do Spark.
- Exporte ou anote as definições de configuração, incluindo o local do arquivo de script, dependências, parâmetros e quaisquer outros detalhes relevantes.
Para criar uma nova definição de trabalho do Spark (SJD) com base nas informações de SJD exportadas na malha:
- Espaço de trabalho do Access Fabric: entre no Fabric e acesse seu espaço de trabalho.
- Crie uma nova definição de trabalho do Spark na malha:
- No Fabric, vá para a página inicial da Engenharia de Dados.
- Selecione Definição de trabalho do Spark.
- Configure o trabalho usando as informações exportadas do Synapse, incluindo local do script, dependências, parâmetros e configurações de cluster.
- Adaptar e testar: Faça qualquer adaptação necessária ao script ou configuração para se adequar ao ambiente Fabric. Teste o trabalho no Fabric para garantir que ele seja executado corretamente.
Depois que a definição de trabalho do Spark for criada, valide as dependências:
- Certifique-se de usar a mesma versão do Spark.
- Valide a existência do arquivo de definição principal.
- Valide a existência dos arquivos, dependências e recursos referenciados.
- Serviços vinculados, conexões de fonte de dados e pontos de montagem.
Saiba mais sobre como criar uma definição de trabalho do Apache Spark no Fabric.
Opção 2: Usar a API de malha
Siga estas etapas principais para a migração:
- Pré-requisitos.
- Etapa 1: Exportar a definição de trabalho do Spark do Azure Synapse para o OneLake (.json).
- Etapa 2: Importe a definição de tarefa do Spark automaticamente para o Fabric usando a API do Fabric.
Pré-requisitos
Os pré-requisitos incluem ações que você precisa considerar antes de iniciar a migração de definição de trabalho do Spark para o Fabric.
- Um espaço de trabalho de malha.
- Se você ainda não tiver um, crie um Fabric lakehouse em seu espaço de trabalho.
Etapa 1: Exportar a definição de trabalho do Spark do espaço de trabalho do Azure Synapse
O foco da Etapa 1 é exportar a definição de trabalho do Spark do espaço de trabalho do Azure Synapse para o OneLake no formato json. Este processo é o seguinte:
- 1.1) Importar bloco de anotações de migração SJD para o espaço de trabalho Fabric . Este bloco de anotações exporta todas as definições de trabalho do Spark de um determinado espaço de trabalho do Azure Synapse para um diretório intermediário no OneLake. Synapse API é usado para exportar SJD.
- 1.2) Configure os parâmetros no primeiro comando para exportar a definição de trabalho do Spark para um armazenamento intermediário (OneLake). Isso só exporta o arquivo de metadados json. O trecho a seguir é usado para configurar os parâmetros de origem e destino. Certifique-se de substituí-los por seus próprios valores.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
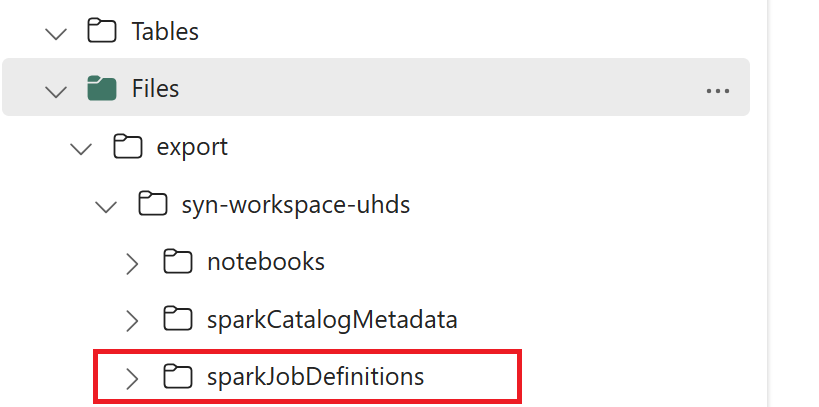
- 1.3) Execute as duas primeiras células do bloco de anotações de exportação/importação para exportar metadados de definição de trabalho do Spark para o OneLake. Quando as células são concluídas, essa estrutura de pastas sob o diretório de saída intermediário é criada.
Etapa 2: Importar a definição de trabalho do Spark para a malha
A etapa 2 é quando as definições de trabalho do Spark são importadas do armazenamento intermediário para o espaço de trabalho Fabric. Este processo é o seguinte:
- 2.1) Valide as configurações na versão 1.2 para garantir que o espaço de trabalho e o prefixo corretos sejam indicados para importar as definições de trabalho do Spark.
- 2.2) Execute a terceira célula do bloco de anotações de exportação/importação para importar todas as definições de trabalho do Spark do local intermediário.
Nota
A opção de exportação gera um arquivo de metadados json. Verifique se os arquivos executáveis, os arquivos de referência e os argumentos de definição de trabalho do Spark estão acessíveis a partir da malha.