Cópia rápida em Dataflows Gen2
Este artigo descreve o recurso de cópia rápida no Dataflows Gen2 for Data Factory no Microsoft Fabric. Os fluxos de dados ajudam na ingestão e transformação de dados. Com a introdução do dimensionamento do fluxo de dados com a computação SQL DW, você pode transformar seus dados em escala. No entanto, seus dados precisam ser ingeridos primeiro. Com a introdução da cópia rápida, você pode ingerir terabytes de dados com a experiência fácil de fluxos de dados, mas com o back-end escalável da atividade de cópia do pipeline.
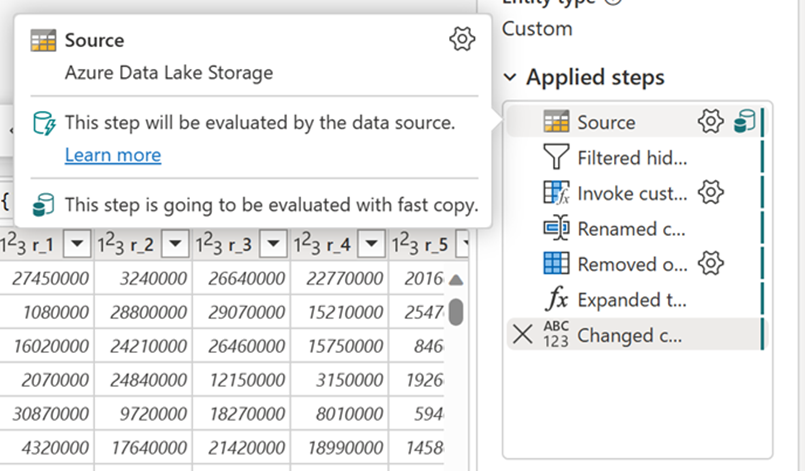
Depois de habilitar esse recurso, os fluxos de dados alternam automaticamente o back-end quando o tamanho dos dados excede um limite específico, sem a necessidade de alterar nada durante a criação dos fluxos de dados. Após a atualização de um fluxo de dados, você pode verificar no histórico de atualizações para ver se a cópia rápida foi usada durante a execução, observando o tipo de mecanismo que aparece lá.
Com a opção Exigir cópia rápida ativada, a atualização do fluxo de dados será cancelada se a cópia rápida não for usada. Isso ajuda a evitar esperar que um tempo limite de atualização continue. Esse comportamento também pode ser útil em uma sessão de depuração para testar o comportamento do fluxo de dados com seus dados enquanto reduz o tempo de espera. Usando os indicadores de cópia rápida no painel de etapas de consulta, você pode verificar facilmente se sua consulta pode ser executada com cópia rápida.
Pré-requisitos
- Você deve ter uma capacidade de malha.
- Para dados de arquivo, os arquivos estão em formato .csv ou parquet de pelo menos 100 MB e armazenados em uma conta de armazenamento do Azure Data Lake (ADLS) Gen2 ou Blob.
- Para banco de dados, incluindo Banco de Dados SQL do Azure e PostgreSQL, 5 milhões de linhas ou mais de dados na fonte de dados.
Nota
Você pode ignorar o limite para forçar a cópia rápida selecionando a configuração "Exigir cópia rápida".
Suporte de conector
Atualmente, a cópia rápida é suportada para os seguintes conectores Dataflow Gen2:
- ADLS Gen2
- Armazenamento de Blobs
- BD SQL do Azure
- Casa do Lago
- PostgreSQL
- SQL Server local
- Armazém
- Oracle
- Snowflake
A atividade de cópia suporta apenas algumas transformações ao se conectar a uma fonte de arquivo:
- Combinar ficheiros
- Selecionar colunas
- Alterar tipos de dados
- Renomear uma coluna
- Remover uma coluna
Você ainda pode aplicar outras transformações dividindo as etapas de ingestão e transformação em consultas separadas. A primeira consulta realmente recupera os dados e a segunda consulta faz referência aos seus resultados para que a computação DW possa ser usada. Para fontes SQL, qualquer transformação que faça parte da consulta nativa é suportada.
Quando você carrega diretamente a consulta para um destino de saída, apenas os destinos Lakehouse são suportados atualmente. Se quiser usar outro destino de saída, você pode preparar a consulta primeiro e fazer referência a ela depois.
Como usar cópia rápida
Navegue até o ponto de extremidade de malha apropriado.
Navegue até um espaço de trabalho premium e crie um fluxo de dados Gen2.
Na guia Página Inicial do novo fluxo de dados, selecione Opções:
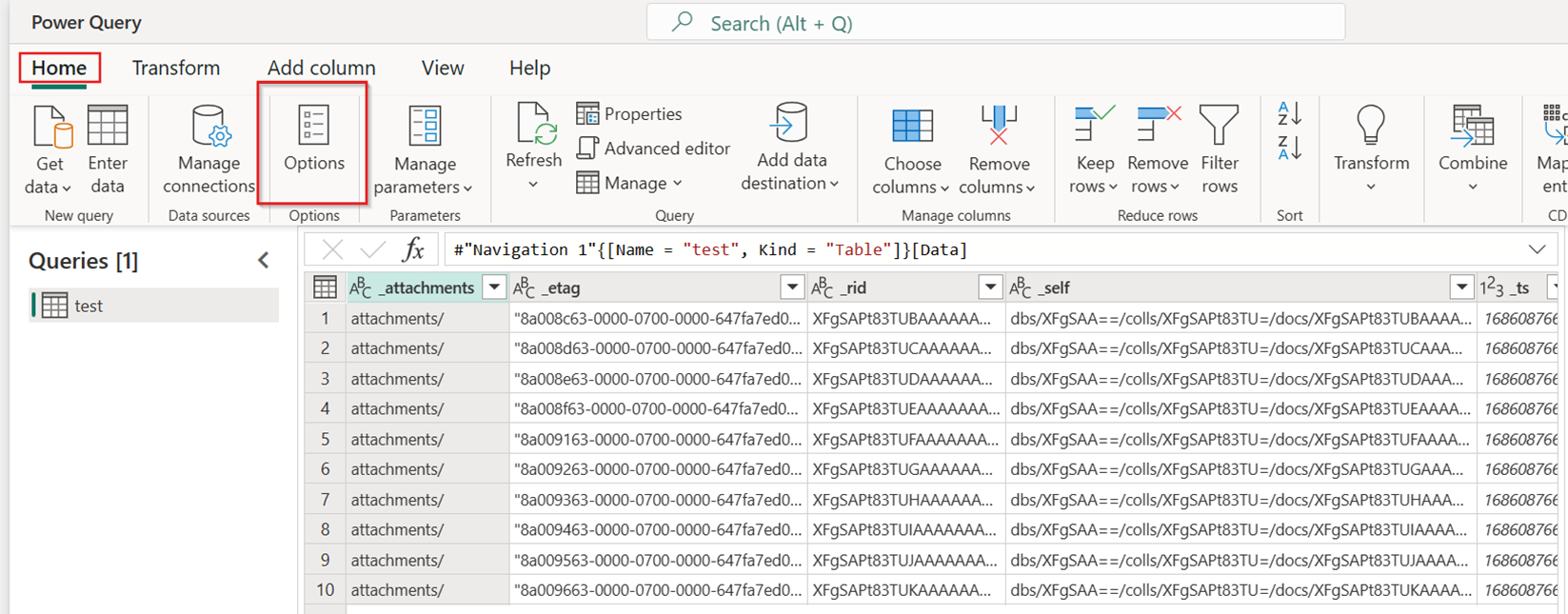
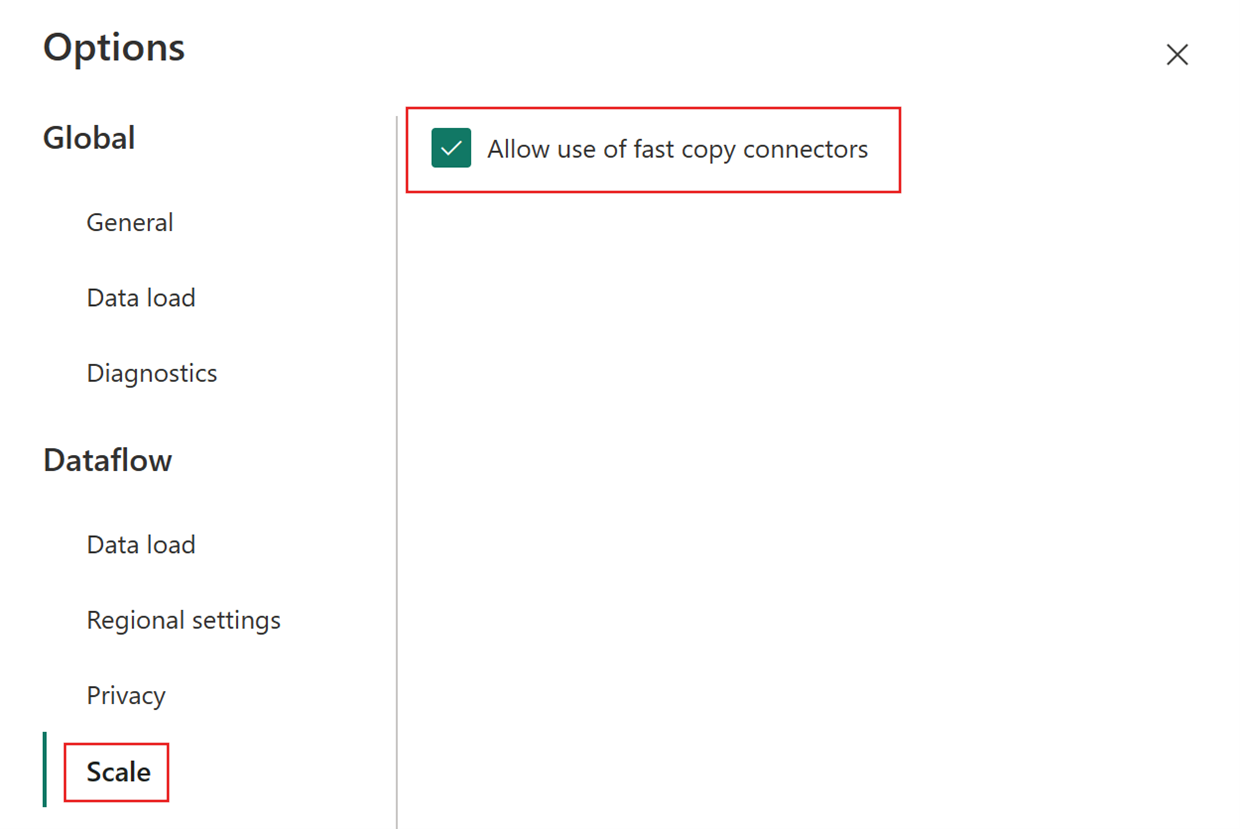
Em seguida, escolha a guia Escala na caixa de diálogo Opções e marque a caixa de seleção Permitir o uso de conectores de cópia rápida para ativar a cópia rápida. Em seguida, feche a caixa de diálogo Opções.
Selecione Obter dados e, em seguida, escolha a fonte ADLS Gen2 e preencha os detalhes do seu contêiner.
Use a funcionalidade Combinar arquivo .

Para garantir uma cópia rápida, aplique apenas as transformações listadas na seção Suporte ao conector deste artigo. Se você precisar aplicar mais transformações, prepare os dados primeiro e faça referência à consulta mais tarde. Faça outras transformações na consulta referenciada.
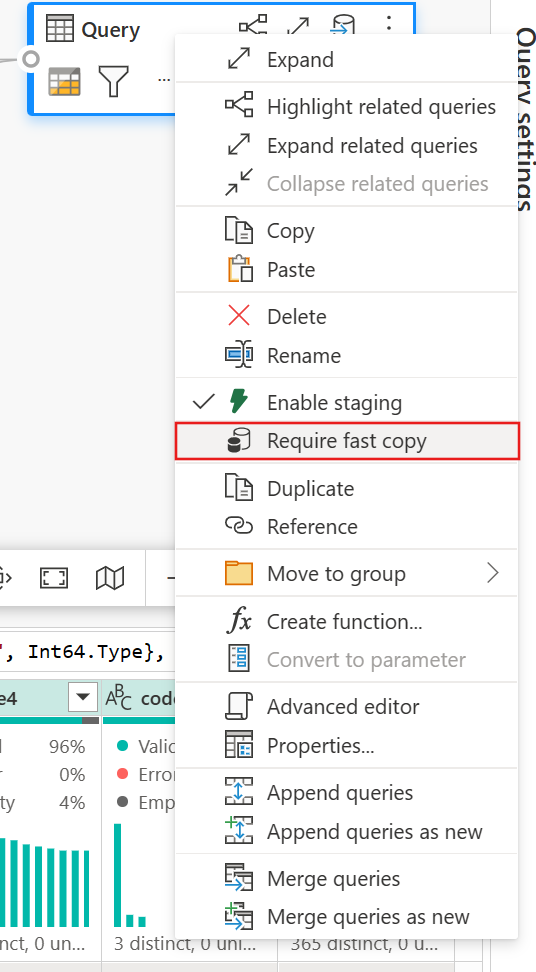
(Opcional) Você pode definir a opção Exigir cópia rápida para a consulta clicando com o botão direito do mouse nela para selecionar e habilitar essa opção.
(Opcional) Atualmente, você só pode configurar um Lakehouse como o destino de saída. Para qualquer outro destino, prepare a consulta e faça referência a ela posteriormente em outra consulta onde você pode enviar para qualquer fonte.
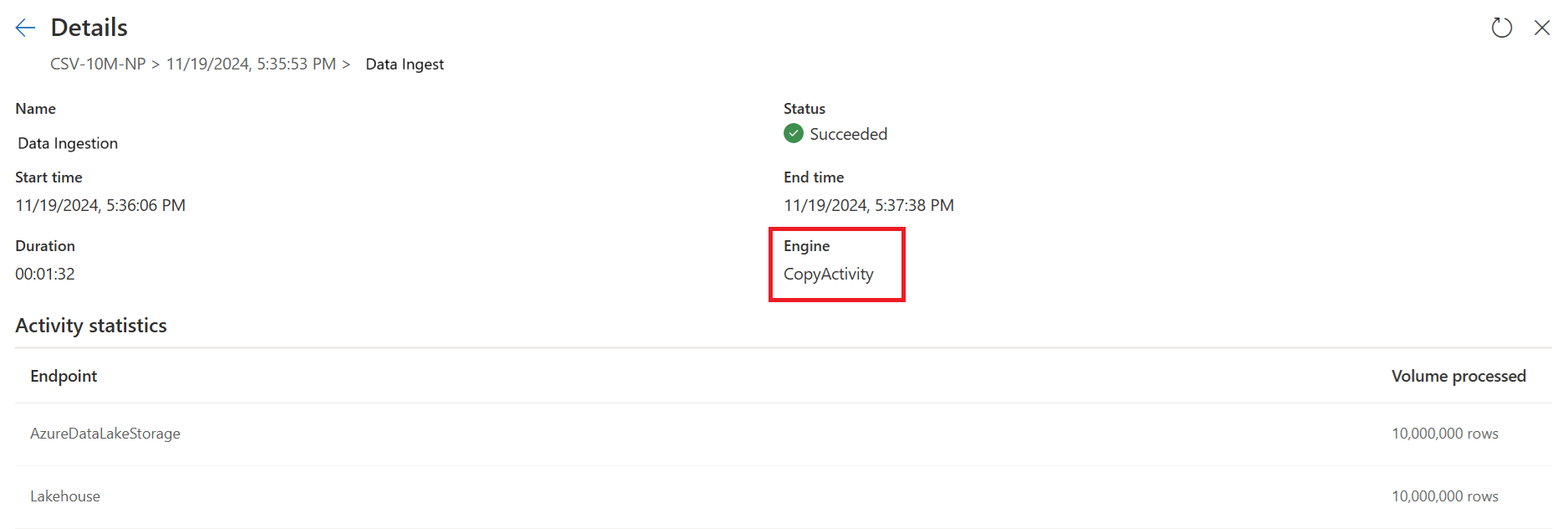
Verifique os indicadores de cópia rápida para ver se a sua consulta pode ser executada com cópia rápida. Em caso afirmativo, o tipo Engine mostra CopyActivity.

Publique o fluxo de dados.
Verifique após a atualização concluída para confirmar que a cópia rápida foi usada.

Como dividir sua consulta para aproveitar a cópia rápida
Para obter um desempenho ideal ao processar grandes volumes de dados com o Dataflow Gen2, use o recurso Fast Copy para primeiro carregar os dados em preparação e, em seguida, transformá-los em escala com a capacidade de processamento do SQL DW. Essa abordagem melhora significativamente o desempenho de ponta a ponta.
Para implementar isso, os indicadores do Fast Copy podem orientá-lo a dividir a consulta em duas partes: ingestão de dados para preparo e transformação em grande escala com computação SQL DW. Você é incentivado a delegar a maior parte da avaliação de uma consulta ao Fast Copy, o qual pode ser utilizado para importar os seus dados. Quando os indicadores do Fast Copy informam que as etapas restantes não podem ser executadas pelo Fast Copy, pode-se dividir o restante da consulta com a encenação habilitada.
Indicadores de diagnóstico por etapas
| Indicador | Ícone | Descrição |
|---|---|---|
| Esta etapa será avaliada com cópia rápida | 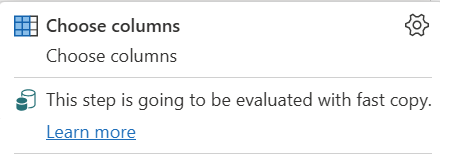
|
O indicador Fast Copy informa que a consulta até esta etapa suporta cópia rápida. |
| Esta etapa não é suportada pelo de cópia rápida | 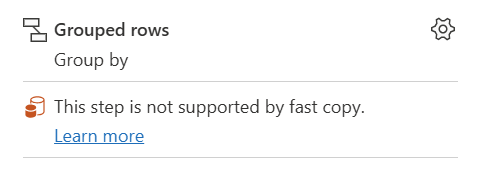
|
O indicador Fast Copy mostra que este passo não suporta Fast Copy. |
| Uma ou mais etapas da sua consulta não são suportadas pela consulta rápida | 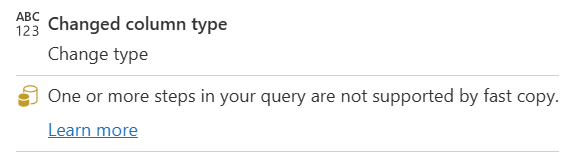
|
O indicador Fast Copy mostra que alguns passos nesta consulta suportam Fast Copy, enquanto outros não. Para otimizar, divida a consulta: etapas amarelas (potencialmente suportadas pelo Fast Copy) e vermelhas (não suportadas). |
Orientação passo a passo
Depois de concluir sua lógica de transformação de dados no Dataflow Gen2, o indicador Fast Copy avalia cada etapa para determinar quantas etapas podem aproveitar o Fast Copy para obter um melhor desempenho.
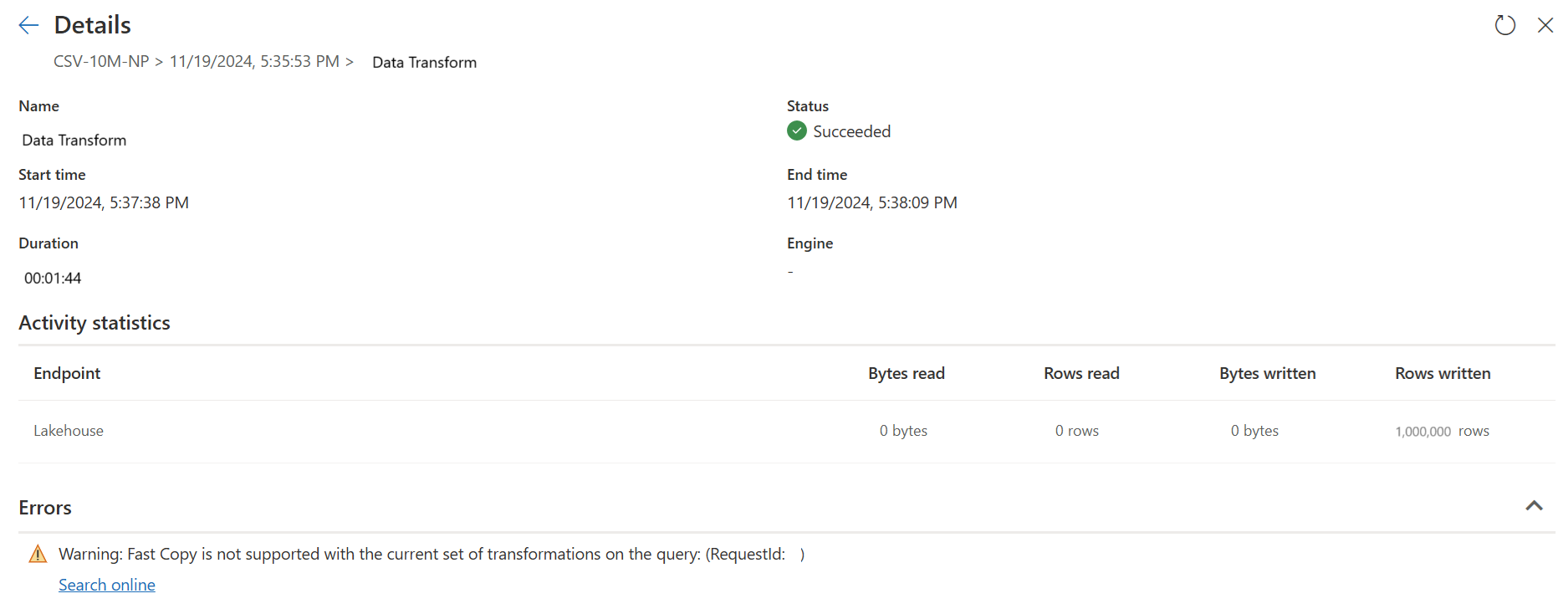
No exemplo abaixo, a última etapa mostra vermelho, indicando que a etapa com Group By não é suportada pelo Fast Copy. No entanto, todas as etapas anteriores mostrando amarelo podem ser potencialmente suportadas pelo Fast Copy.
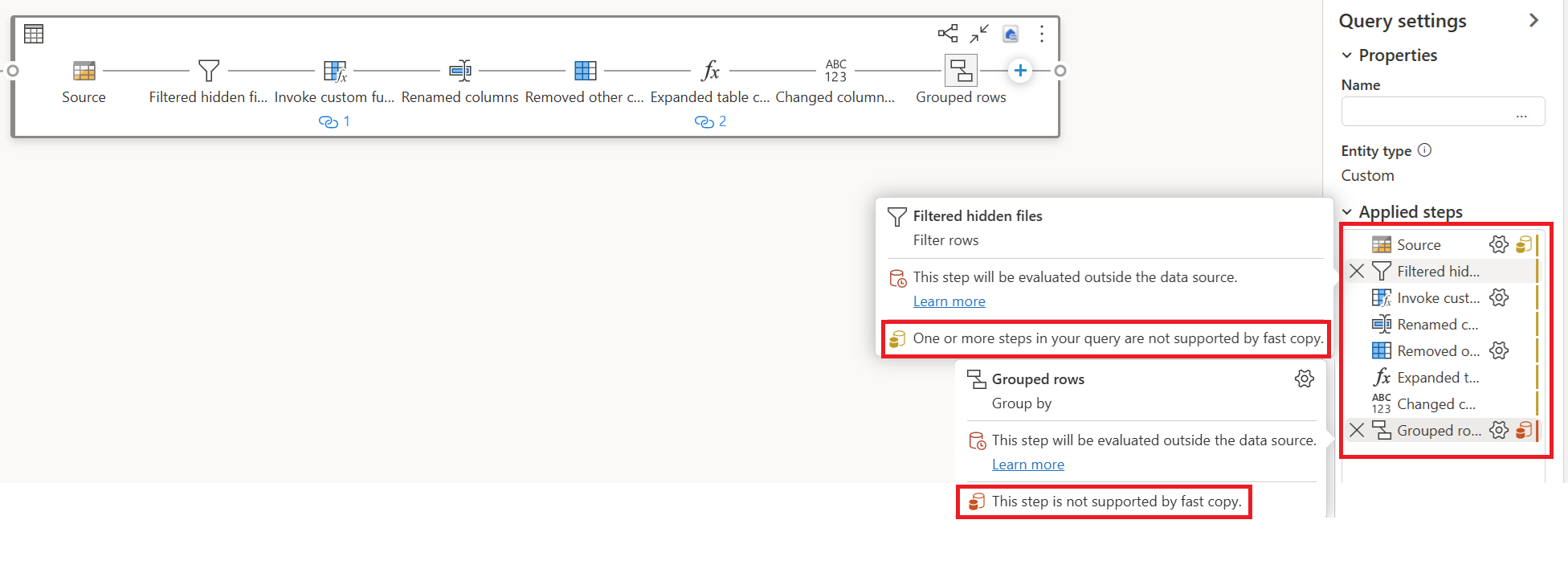
Neste momento, se você publicar e executar diretamente seu Dataflow Gen2, ele não usará o mecanismo Fast Copy para carregar seus dados como a imagem abaixo:
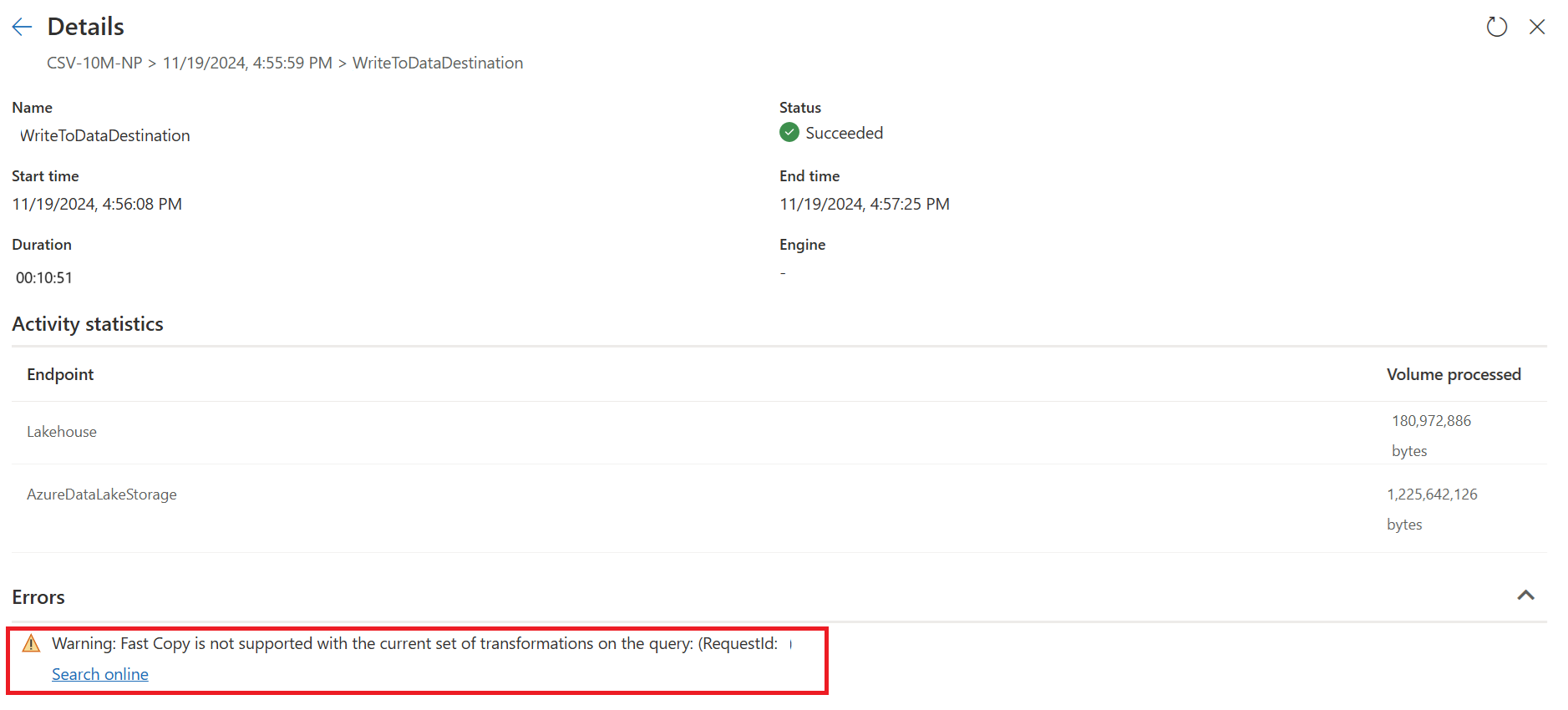
Para usar o mecanismo Fast Copy e melhorar o desempenho do seu Dataflow Gen2, você pode dividir sua consulta em duas partes: ingestão de dados para preparo e transformação em grande escala com computação SQL DW, da seguinte forma:
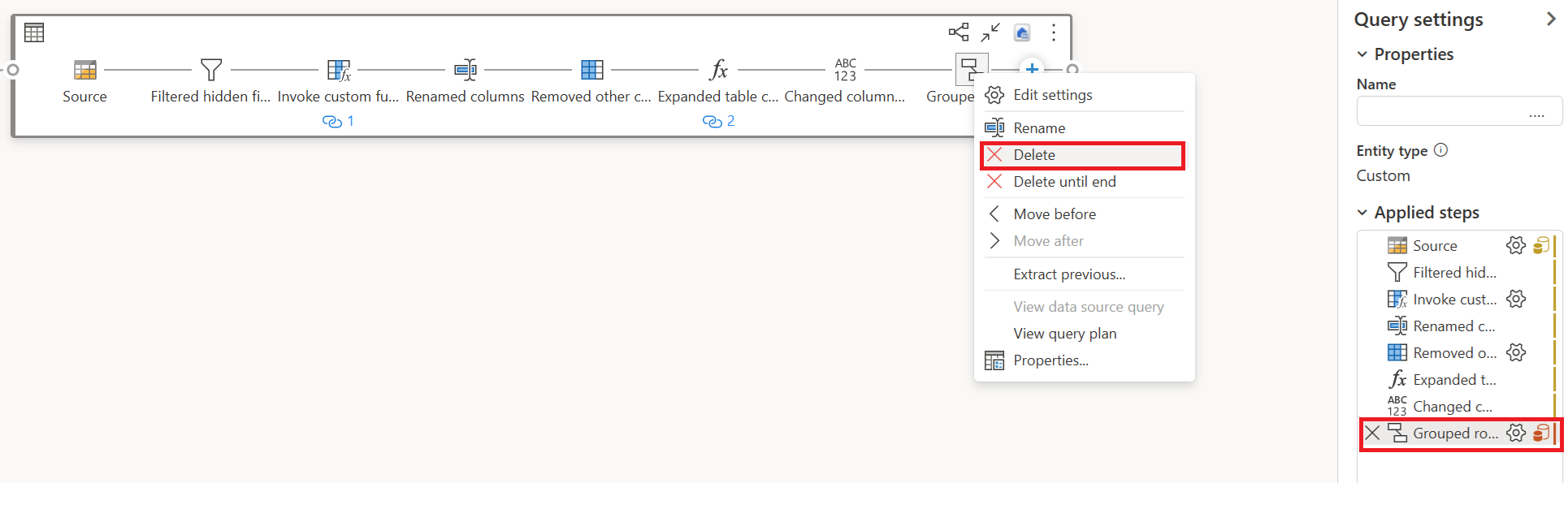
Remova as transformações (mostrando vermelho) que não são suportadas pelo Fast Copy, juntamente com o destino (se definido).
O indicador Fast Copy agora mostra verde para as etapas restantes, o que significa que sua primeira consulta pode aproveitar o Fast Copy para obter um melhor desempenho.
Selecione Ação para a(s) sua(s) primeira(s) consulta(s), e depois escolha Ativar Ensaios e Referência.
Em uma nova consulta referenciada, readicione a transformação "Agrupar por" e o destino (se aplicável).
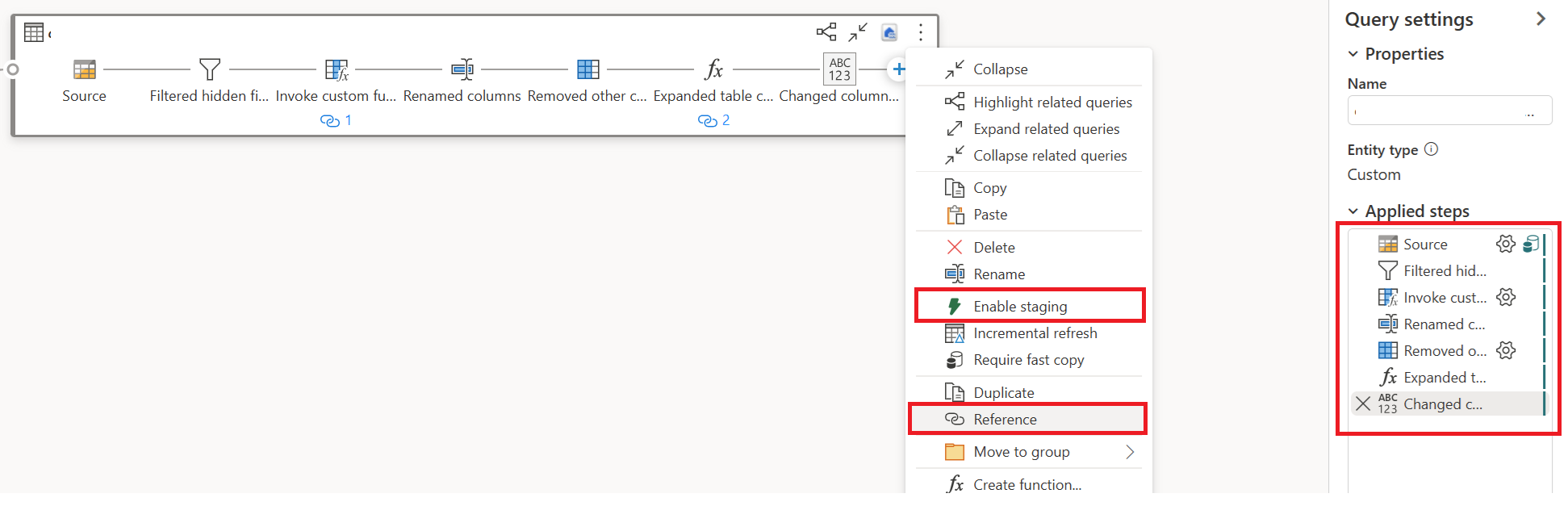
Publique e atualize seu Dataflow Gen2. Agora você verá duas consultas em seu Dataflow Gen2, e a duração total é amplamente reduzida.
A primeira consulta ingere dados em estágio usando Fast Copy.
A segunda consulta executa transformações em grande escala usando a computação SQL DW.
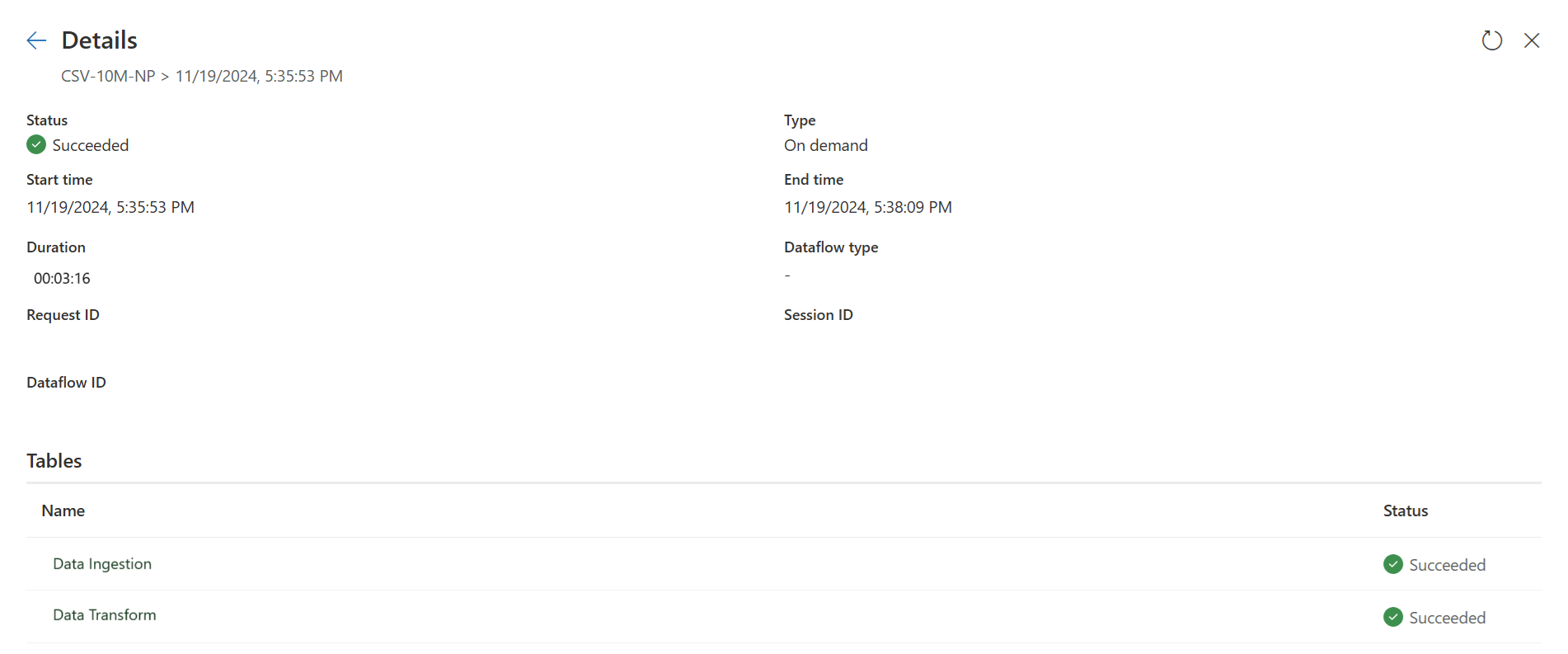
A primeira consulta:
A segunda consulta:
Limitações conhecidas
- É necessário um gateway de dados local versão 3000.214.2 ou mais recente para suportar o Fast Copy.
- O gateway VNet não é suportado.
- Não há suporte para gravação de dados em uma tabela existente no Lakehouse.
- Não há suporte para esquema fixo.