Tutorial: Descobrir relações em um modelo semântico, usando link semântico
Este tutorial ilustra como interagir com o Power BI a partir de um bloco de anotações Jupyter e detetar relações entre tabelas com a ajuda da biblioteca SemPy.
Neste tutorial, você aprenderá a:
- Descubra relações em um modelo semântico (conjunto de dados do Power BI), usando a biblioteca Python do link semântico (SemPy).
- Use componentes do SemPy que oferecem suporte à integração com o Power BI e ajudam a automatizar a análise de qualidade de dados. Esses componentes incluem:
- FabricDataFrame - uma estrutura semelhante a pandas aprimorada com informações semânticas adicionais.
- Funções para extrair modelos semânticos de um espaço de trabalho do Fabric para o seu caderno.
- Funções que automatizam a avaliação de hipóteses sobre dependências funcionais e que identificam violações de relações em seus modelos semânticos.
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou inscreva-se para obter uma avaliação gratuita do Microsoft Fabric.
Entre na Microsoft Fabric.
Use o seletor de experiência no lado esquerdo da sua página inicial para alternar para a experiência Synapse Data Science.

Selecione Workspaces no painel de navegação esquerdo para localizar e selecionar seu espaço de trabalho. Este espaço de trabalho torna-se o seu espaço de trabalho atual.
Baixe o
Customer Profitability Sample.pbix eCustomer Profitability Sample (auto).pbix modelos semânticos do repositório GitHubde amostras de malha e carregue-os para seu espaço de trabalho.
Acompanhe no caderno
O notebook
Para abrir o bloco de anotações que acompanha este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados, para importar o bloco de anotações para seu espaço de trabalho.
Se preferir copiar e colar o código desta página, pode criar um novo bloco de notas.
Certifique-se de anexar um lakehouse ao bloco de notas antes de começar a executar o código.
Configurar o portátil
Nesta seção, você configura um ambiente de notebook com os módulos e dados necessários.
Instale
SemPydo PyPI usando a capacidade de instalação em linha%pipno notebook:%pip install semantic-linkExecute as importações necessárias de módulos SemPy que você precisará mais tarde:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImporte pandas para impor uma opção de configuração que ajude na formatação de saída:
import pandas as pd pd.set_option('display.max_colwidth', None)
Explora modelos semânticos
Este tutorial usa um modelo semântico de exemplo padrão Customer Profitability Sample.pbix. Para obter uma descrição do modelo semântico, consulte exemplo de Rentabilidade do Cliente para o Power BI.
Use a função
list_datasetsdo SemPy para explorar modelos semânticos em seu espaço de trabalho atual:fabric.list_datasets()
Para o restante deste bloco de anotações, você usa duas versões do modelo semântico Customer Profitability Sample:
- Exemplo de rentabilidade do cliente: o modelo semântico que vem de exemplos do Power BI com relações de tabela predefinidas
- Exemplo de Rentabilidade do Cliente (auto): os mesmos dados, mas as relações são limitadas àqueles que o Power BI detetaria automaticamente.
Extraia um modelo semântico de exemplo com o seu modelo semântico predefinido
Carregue relacionamentos que são predefinidos e armazenados dentro do modelo semântico Customer Profitability Sample, usando a função do SemPy
list_relationships. Esta função lista a partir do modelo de objeto tabular:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualize o
relationshipsDataFrame como um gráfico, usando a funçãoplot_relationship_metadatado SemPy:plot_relationship_metadata(relationships)

Este gráfico mostra a "verdade básica" para as relações entre tabelas neste modelo semântico, pois reflete como elas foram definidas no Power BI por um especialista no assunto.
Descoberta de relacionamentos complementares
Se você começasse com relacionamentos que o Power BI detetasse automaticamente, teria um conjunto menor.
Visualize as relações que o Power BI detetou automaticamente no modelo semântico:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)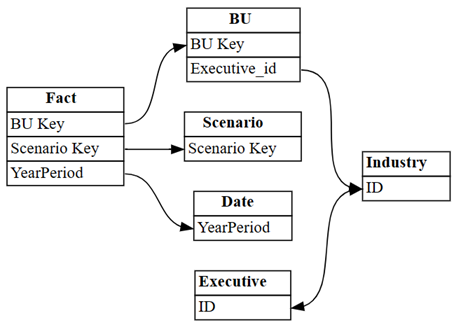
A deteção automática do Power BI não conseguiu identificar muitos relacionamentos. Além disso, duas das relações detetadas automaticamente são semanticamente incorretas:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
Imprima as relações como uma tabela:
autodetectedRelações incorretas com a tabela
Industryaparecem em linhas com índice 3 e 4. Use essas informações para remover essas linhas.Descarte as relações identificadas incorretamente.
autodetected.drop(index=[3,4], inplace=True) autodetectedAgora você tem relacionamentos corretos, mas incompletos.
Visualize essas relações incompletas, usando
plot_relationship_metadata:plot_relationship_metadata(autodetected)
Carregue todas as tabelas do modelo semântico, usando as funções
list_tableseread_tabledo SemPy:tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Encontre relações entre tabelas, usando
find_relationshipse revise a saída de log para obter algumas informações sobre como essa função funciona:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Visualize relacionamentos recém-descobertos:
plot_relationship_metadata(suggested_relationships_all)
SemPy foi capaz de detetar todos os relacionamentos.
Use o parâmetro
excludepara limitar a pesquisa a relações adicionais que não foram identificadas anteriormente:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Validar as relações
Primeiro, carregue os dados do modelo semântico Customer Profitability Sample:
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Verifique se há sobreposição de valores de chave primária e estrangeira usando a função
list_relationship_violations. Fornecer a saída da funçãolist_relationshipscomo entrada paralist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))As violações de relacionamento fornecem alguns insights interessantes. Por exemplo, um em cada sete valores em
Fact[Product Key]não está presente emProduct[Product Key], e essa chave ausente é50.
A análise exploratória de dados é um processo empolgante, assim como a limpeza de dados. Há sempre algo que os dados estão escondendo, dependendo de como você olha para eles, o que você quer perguntar e assim por diante. O link semântico fornece novas ferramentas que você pode usar para obter mais com seus dados.
Conteúdo relacionado
Confira outros tutoriais para link semântico / SemPy:
- Tutorial: Limpar dados com dependências funcionais
- Tutorial: Analisar dependências funcionais em um modelo semântico de exemplo
- Tutorial: Extrair e calcular medidas do Power BI a partir de um bloco de anotações Jupyter
- Tutorial: Descubra relações no conjunto de dados Synthea, usando o link semântico
- Tutorial: Validar dados usando SemPy e Grandes Expectativas (GX)