Controle do código-fonte com o Warehouse (visualização)
Este artigo explica como os pipelines de integração e implantação do Git funcionam para armazéns no Microsoft Fabric. Saiba como configurar uma conexão com seu repositório, gerenciar seus armazéns e implantá-los em diferentes ambientes. O controle do código-fonte para o Fabric Warehouse é atualmente um recurso de visualização.
Você pode usar os pipelines de integração e implantação do Git para diferentes cenários:
- Use projetos de banco de dados Git e SQL para gerenciar alterações incrementais, colaboração em equipe, histórico de confirmação em objetos de banco de dados individuais.
- Use pipelines de implantação para promover alterações de código em diferentes ambientes de pré-produção e produção.
Integração no Git
A integração do Git no Microsoft Fabric permite que os desenvolvedores integrem seus processos de desenvolvimento, ferramentas e práticas recomendadas diretamente na plataforma Fabric. Ele permite que os desenvolvedores que estão desenvolvendo no Fabric:
- Backup e versão do seu trabalho
- Reverter para estágios anteriores conforme necessário
- Colabore com outras pessoas ou trabalhe sozinho usando ramificações do Git
- Aplique os recursos das ferramentas familiares de controle do código-fonte para gerenciar itens do Fabric
Para obter mais informações sobre o processo de integração do Git, consulte:
- Integração com o Fabric Git
- Conceitos básicos em integração Git
- Introdução à integração com o Git (visualização)
Configurar uma conexão com o controle do código-fonte
Na página Configurações do espaço de trabalho , você pode facilmente configurar uma conexão com seu repositório para confirmar e sincronizar alterações.
- Para configurar a conexão, consulte Introdução à integração com o Git. Siga as instruções para Conectar-se a um repositório Git ao Azure DevOps ou ao GitHub como um provedor Git.
- Uma vez conectados, seus itens, incluindo armazéns, aparecem no painel de controle Origem.
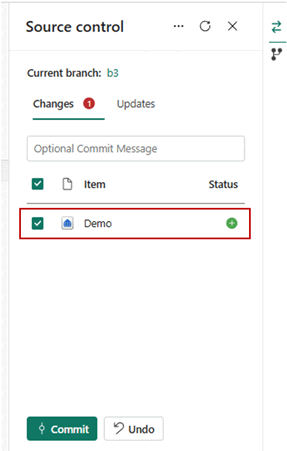
- Depois de conectar com êxito as instâncias de depósito ao repositório Git, você verá a estrutura de pastas do depósito no repositório. Agora você pode executar operações futuras, como a criação de uma solicitação pull.
Projetos de banco de dados para um armazém no Git
A imagem a seguir é um exemplo da estrutura de arquivos de cada item de depósito no repositório:

Quando você confirma o item de depósito no repositório Git, o depósito é convertido em um formato de código-fonte, como um projeto de banco de dados SQL. Um projeto SQL é uma representação local de objetos SQL que compõem o esquema para um único banco de dados, como tabelas, procedimentos armazenados ou funções. A estrutura de pastas dos objetos de banco de dados é organizada por Schema/Object Type. Cada objeto no armazém é representado com um arquivo .sql que contém sua definição de linguagem de definição de dados (DDL). Os dados da tabela de depósito e os recursos de segurança SQL não estão incluídos no projeto de banco de dados SQL.
As consultas compartilhadas também são confirmadas com o repositório e herdam o nome como foram salvas.
Baixe o projeto de banco de dados SQL de um depósito no Fabric
Com a extensão Projetos do Banco de Dados SQL disponível dentro do Azure Data Studio e do Visual Studio Code, você pode gerenciar um esquema de depósito e lidar com alterações de objeto do Warehouse como outros projetos de banco de dados SQL.
Para baixar uma cópia local do esquema do seu depósito, selecione Baixar projeto de banco de dados SQL na faixa de opções.

A cópia local de um projeto de banco de dados que contém a definição do esquema de depósito. O projeto de banco de dados pode ser usado para:
- Recrie o esquema de depósito em outro depósito.
- Desenvolva ainda mais o esquema de depósito em ferramentas de cliente, como o Azure Data Studio ou o Visual Studio Code.
Publicar projeto de banco de dados SQL em um novo depósito
Para publicar o esquema de depósito em um novo depósito:
- Crie um novo armazém no espaço de trabalho do Fabric.
- Na página de inicialização do novo depósito, em Criar um depósito, selecione Projeto de banco de dados SQL.
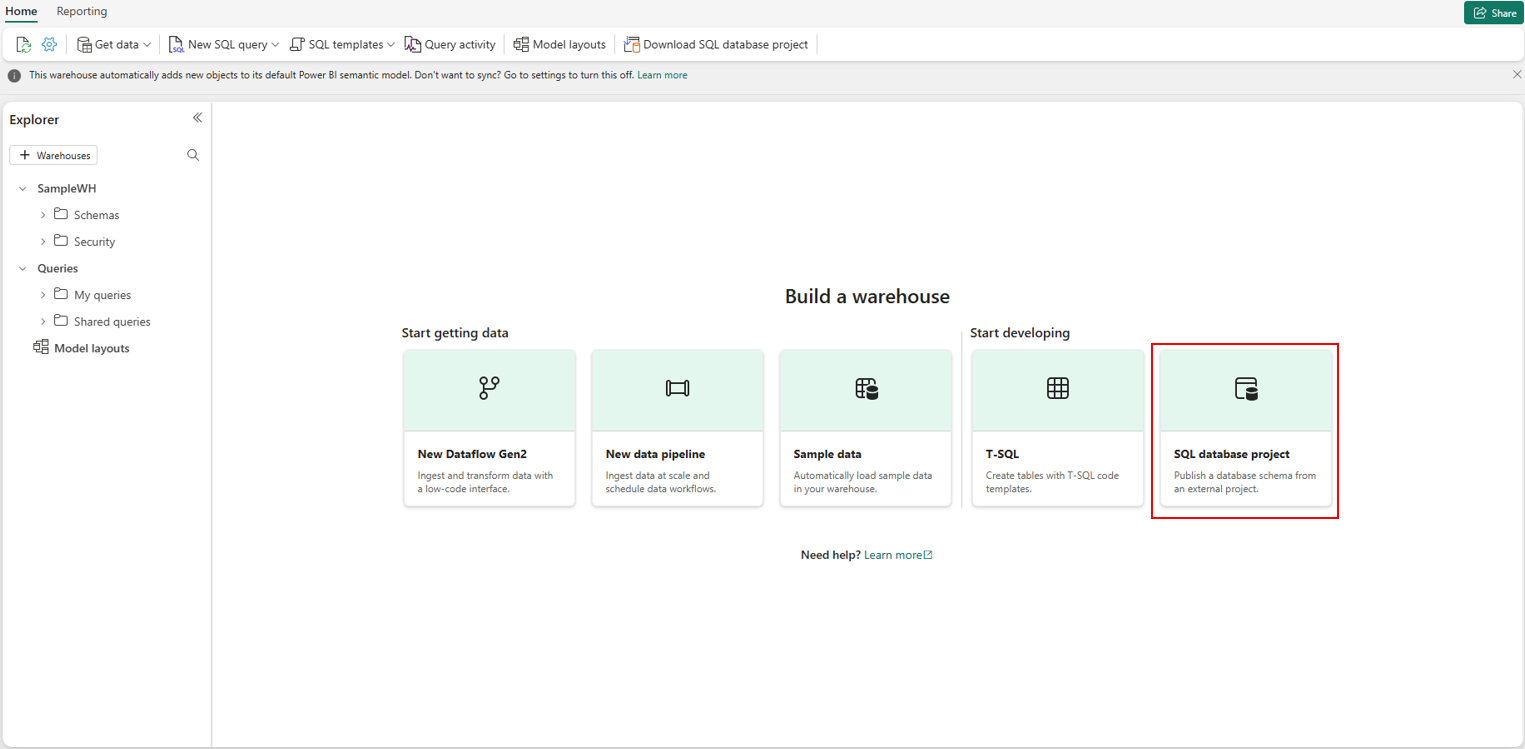
- Selecione o arquivo .zip que foi baixado do depósito existente.
- O esquema de depósito é publicado no novo depósito.

Pipelines de implementação
Você também pode usar pipelines de implantação para implantar o código do seu armazém em diferentes ambientes, como desenvolvimento, teste e produção. Os pipelines de implantação não expõem um projeto de banco de dados.
Use as etapas a seguir para concluir a implantação do depósito usando o pipeline de implantação.
- Crie um novo pipeline de implantação ou abra um pipeline de implantação existente. Para obter mais informações, consulte Introdução aos pipelines de implantação.
- Atribua espaços de trabalho a diferentes estágios de acordo com suas metas de implantação.
- Selecione, visualize e compare itens, incluindo armazéns, entre diferentes estágios, conforme mostrado no exemplo a seguir.
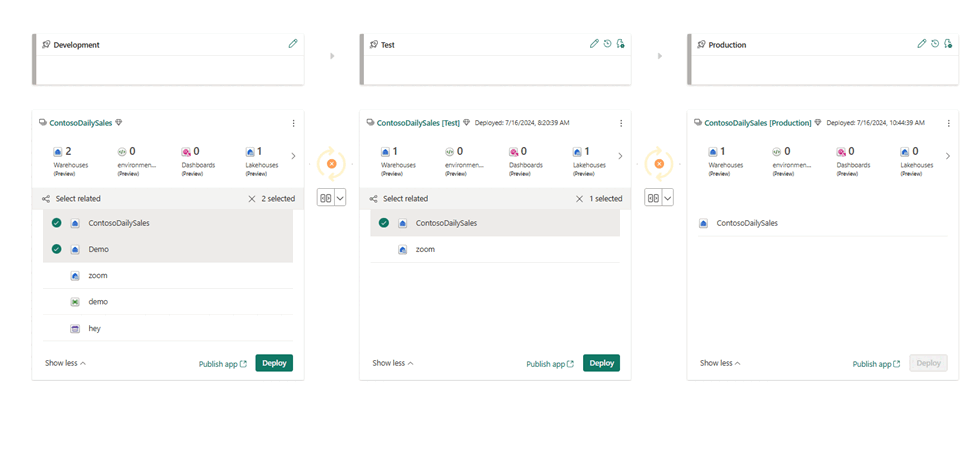
- Selecione Implantar para implantar seus armazéns nos estágios de desenvolvimento, teste e produção .

Para obter mais informações sobre o processo de pipelines de implantação de malha, consulte Visão geral dos pipelines de implantação de malha.
Limitações no controle do código-fonte
- Os recursos de segurança SQL devem ser exportados/migrados usando uma abordagem baseada em script. Considere usar um script pós-implantação em um projeto de banco de dados SQL, que você pode configurar abrindo o projeto com a extensão Projetos do Banco de Dados SQL disponível dentro do Azure Data Studio.
Limitações na integração com o Git
- Atualmente, se você usar
ALTER TABLEpara adicionar uma restrição ou coluna no projeto de banco de dados, a tabela será descartada e recriada durante a implantação, resultando em perda de dados. Considere a seguinte solução alternativa para preservar a definição de tabela e os dados:- Crie uma nova cópia da tabela no depósito, usando
CREATE TABLEeINSERT,CREATE TABLE AS SELECTou Clonar tabela. - Modifique a nova definição de tabela com novas restrições ou colunas, conforme desejado, usando
ALTER TABLE. - Exclua a tabela antiga.
- Renomeie a nova tabela para o nome da tabela antiga usando sp_rename.
- Modifique a definição da tabela antiga no projeto de banco de dados SQL exatamente da mesma maneira. O projeto de banco de dados SQL do depósito no controle do código-fonte e o armazém dinâmico agora devem corresponder.
- Crie uma nova cópia da tabela no depósito, usando
- Atualmente, não crie um Dataflow Gen2 com um destino de saída para o depósito. A confirmação e a atualização do Git seriam bloqueadas por um novo item chamado
DataflowsStagingWarehouseque aparece no repositório. - O ponto de extremidade de análise SQL não é suportado com a integração Git.
Limitações para pipelines de implantação
- Atualmente, se você usar
ALTER TABLEpara adicionar uma restrição ou coluna no projeto de banco de dados, a tabela será descartada e recriada durante a implantação, resultando em perda de dados. - Atualmente, não crie um Dataflow Gen2 com um destino de saída para o depósito. A implantação seria bloqueada por um novo item chamado
DataflowsStagingWarehouseque aparece no pipeline de implantação. - O ponto de extremidade de análise SQL não é suportado em pipelines de implantação.