Obter dados do Eventstream
Neste artigo, você aprenderá como obter dados de um fluxo de eventos existente em uma tabela nova ou existente.
Para obter dados de um novo fluxo de eventos, consulte Obter dados de um novo fluxo de eventos.
Pré-requisitos
- Um espaço de trabalho com uma capacidade habilitada para Microsoft Fabric
- Um banco de dados KQL com permissões de edição
- Um fluxo de eventos com uma fonte de dados
Origem
Para obter dados de um fluxo de eventos, você precisa selecionar o fluxo de eventos como sua fonte de dados. Você pode selecionar um fluxo de eventos existente das seguintes maneiras:
Na faixa de opções inferior do banco de dados KQL:
No menu suspenso Obter dados e, em Contínuo, selecione Eventstream>Existing Eventstream.
Selecione Obter dados e, na janela Obter dados , selecione Fluxo de eventos.
No menu suspenso Obter dados, em Contínuo, selecione Fluxo de eventos existente do hub>de dados em tempo real.


Configurar
Selecione uma tabela de destino. Se pretender ingerir dados numa nova tabela, selecione + Nova tabela e introduza um nome de tabela.
Nota
Os nomes das tabelas podem ter até 1024 caracteres, incluindo espaços, alfanuméricos, hífenes e sublinhados. Não há suporte para caracteres especiais.
Em Configurar a fonte de dados, preencha as configurações usando as informações da tabela a seguir:

Definição Descrição Área de trabalho O local do espaço de trabalho do fluxo de eventos. Selecione um espaço de trabalho na lista suspensa. Nome do fluxo de eventos O nome do seu fluxo de eventos. Selecione um fluxo de eventos na lista suspensa. Nome da ligação de dados O nome usado para fazer referência e gerenciar sua conexão de dados em seu espaço de trabalho. O nome da conexão de dados é preenchido automaticamente. Opcionalmente, você pode inserir um novo nome. O nome só pode conter caracteres alfanuméricos, traços e pontos e ter até 40 caracteres. Processar evento antes da ingestão no Eventstream Esta opção permite configurar o processamento de dados antes que os dados sejam ingeridos na tabela de destino. Se selecionado, você continua o processo de ingestão de dados no Eventstream. Para obter mais informações, consulte Processar evento antes da ingestão no Eventstream. Filtros avançados Compressão Compactação de dados dos eventos, como provenientes do hub de eventos. As opções são Nenhum (padrão) ou Compactação Gzip. Propriedades do sistema de eventos Se houver vários registros por mensagem de evento, as propriedades do sistema serão adicionadas à primeira. Para obter mais informações, consulte Propriedades do sistema de eventos. Data de início da recuperação do evento A conexão de dados recupera eventos existentes criados desde a data de início da recuperação de eventos. Ele só pode recuperar eventos retidos pelo hub de eventos, com base em seu período de retenção. O fuso horário é UTC. Se nenhuma hora for especificada, a hora padrão será a hora em que a conexão de dados for criada. Selecione Seguinte

Processar evento antes da ingestão no Eventstream
A opção Processar evento antes da ingestão no Eventstream permite processar os dados antes que eles sejam ingeridos na tabela de destino. Com essa opção, o processo get data continua perfeitamente no Eventstream, com a tabela de destino e os detalhes da fonte de dados preenchidos automaticamente.
Para processar o evento antes da ingestão no Eventstream:
Na guia Configurar, selecione Processar evento antes da ingestão em Eventstream.
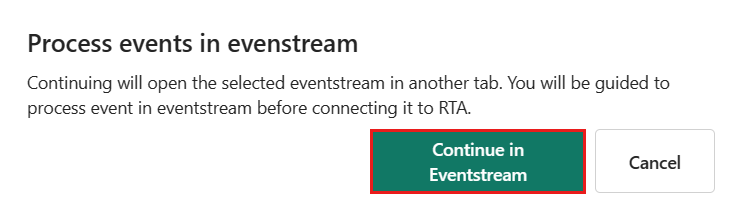
Na caixa de diálogo Processar eventos no fluxo de eventos, selecione Continuar no fluxo de eventos.
Importante
Selecionar Continuar no Eventstream encerra o processo de obtenção de dados no Real-Time Intelligence e continua no Eventstream com a tabela de destino e os detalhes da fonte de dados preenchidos automaticamente.
Em Eventstream, selecione o nó de destino do Banco de Dados KQL e, no painel Banco de Dados KQL, verifique se o processamento de eventos antes da ingestão está selecionado e se os detalhes do destino estão corretos.

Selecione Abrir processador de eventos para configurar o processamento de dados e, em seguida, selecione Salvar. Para obter mais informações, consulte Processar dados de eventos com o editor do processador de eventos.
De volta ao painel Banco de Dados KQL, selecione Adicionar para concluir a configuração do nó de destino do Banco de Dados KQL.
Verifique se os dados foram ingeridos na tabela de destino.


Nota
O evento de processo antes da ingestão no processo Eventstream está concluído e as etapas restantes neste artigo não são necessárias.
Inspecionar
A guia Inspecionar é aberta com uma visualização dos dados.
Para concluir o processo de ingestão, selecione Concluir.

Opcionalmente:
- Selecione Visualizador de comandos para visualizar e copiar os comandos automáticos gerados a partir de suas entradas.
- Altere o formato de dados inferido automaticamente selecionando o formato desejado na lista suspensa. Os dados são lidos do hub de eventos na forma de objetos EventData . Os formatos suportados são CSV, JSON, PSV, SCsv, SOHsv TSV, TXT e TSVE.
- Editar colunas.
- Explore as opções avançadas com base no tipo de dados.
Editar colunas
Nota
- Para formatos tabulares (CSV, TSV, PSV), não é possível mapear uma coluna duas vezes. Para mapear para uma coluna existente, primeiro exclua a nova coluna.
- Não é possível alterar um tipo de coluna existente. Se você tentar mapear para uma coluna com um formato diferente, você pode acabar com colunas vazias.
As alterações que você pode fazer em uma tabela dependem dos seguintes parâmetros:
- O tipo de tabela é novo ou existente
- O tipo de mapeamento é novo ou existente
| Tipo de tabela | Tipo de mapeamento | Ajustes disponíveis |
|---|---|---|
| Nova tabela | Novo mapeamento | Renomear coluna, alterar tipo de dados, alterar fonte de dados, mapear transformação, adicionar coluna, excluir coluna |
| Tabela existente | Novo mapeamento | Adicionar coluna (na qual você pode alterar o tipo de dados, renomear e atualizar) |
| Tabela existente | Mapeamento existente | nenhum |

Mapeando transformações
Alguns mapeamentos de formato de dados (Parquet, JSON e Avro) suportam transformações simples em tempo de ingestão. Para aplicar transformações de mapeamento, crie ou atualize uma coluna na janela Editar colunas .
As transformações de mapeamento podem ser executadas em uma coluna do tipo string ou datetime, com a fonte tendo o tipo de dados int ou long. As transformações de mapeamento suportadas são:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opções avançadas com base no tipo de dados
Tabela (CSV, TSV, PSV):
Os dados tabulares não incluem necessariamente os nomes das colunas usadas para mapear os dados de origem para as colunas existentes. Para usar a primeira linha como nomes de coluna, ative Primeira linha é cabeçalho de coluna.

JSON:
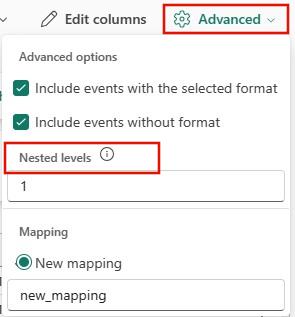
Para determinar a divisão de colunas dos dados JSON, selecione Níveis aninhados avançados>, de 1 a 100.
Resumo
Na janela Preparação de dados, todas as três etapas são marcadas com marcas de seleção verdes quando a ingestão de dados é concluída com êxito. Você pode selecionar um cartão para consultar, soltar os dados ingeridos ou ver um painel do resumo da sua ingestão. Selecione Fechar para fechar a janela.

Conteúdos relacionados
- Para gerenciar seu banco de dados, consulte Gerenciar dados
- Para criar, armazenar e exportar consultas, consulte Consultar dados em um conjunto de consultas KQL