dcount() (função de agregação)
Aplica-se a: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Calcula uma estimativa do número de valores distintos que são obtidos por uma expressão escalar no grupo de resumo.
Os valores nulos são ignorados e não são considerados no cálculo.
Observação
A função de agregação dcount() é principalmente útil para estimar a cardinalidade de grandes conjuntos. Ele troca precisão por desempenho e pode retornar um resultado que varia entre as execuções. A ordem das entradas pode ter um efeito na saída.
Observação
Essa função é usada em conjunto com o operador summarize.
Sintaxe
dcount(expr[,precisão])
Saiba mais sobre as convenções de sintaxe.
Parâmetros
| Nome | Digitar | Obrigatória | Descrição |
|---|---|---|---|
| expr | string |
✔️ | A entrada cujos valores distintos devem ser contados. |
| exatidão | int |
O valor que define a precisão da estimativa solicitada. O valor padrão é 1. Consulte Precisão da estimativa para obter os valores compatíveis. |
Devoluções
Retorna uma estimativa do número de valores distintos de expr no grupo.
Exemplo
Este exemplo mostra quantos tipos de eventos de tempestade aconteceram em cada estado.
StormEvents
| summarize DifferentEvents=dcount(EventType) by State
| order by DifferentEvents
A tabela de resultados mostrada inclui apenas as primeiras 10 linhas.
| Estado | Eventos Diferentes |
|---|---|
| TEXAS | 27 |
| CALIFÓRNIA | 26 |
| Pensilvânia | 25 |
| GEÓRGIA | 24 |
| ILLINOIS | 23 |
| MARYLAND | 23 |
| NORTH CAROLINA | 23 |
| MICHIGAN | 22 |
| FLÓRIDA | 22 |
| OREGON | 21 |
| KANSAS | 21 |
| ... | ... |
Precisão da estimativa
Essa função usa uma variante do algoritmo HyperLogLog (HLL), que faz uma estimativa estocástica da cardinalidade do conjunto. O algoritmo oferece um "botão" que pode ser usado para balancear a precisão e o tempo de execução por tamanho de memória:
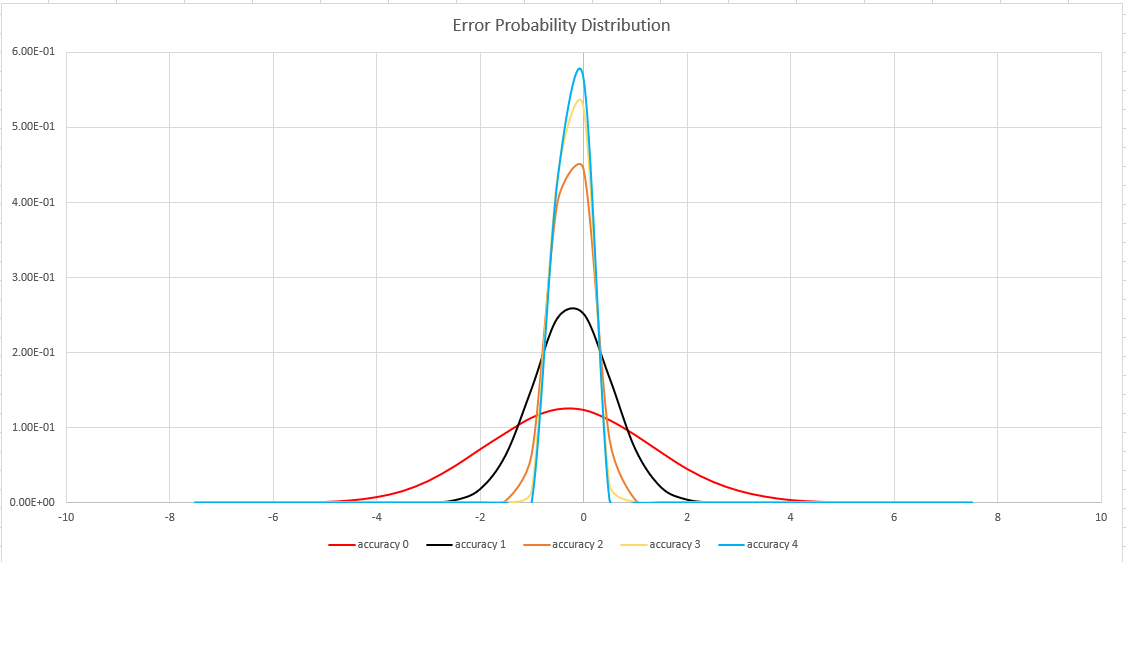
| Precisão | Erro (%) | Contagem de entradas |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0,2 | 218 |
Observação
A coluna "contagem de entradas" é o número de contadores de 1 byte na implementação de HLL.
O algoritmo inclui algumas provisões para fazer uma contagem perfeita (erro zero), se a cardinalidade definida for pequena o suficiente:
- Quando o nível de precisão é
1, mil valores são retornados - Quando o nível de precisão é
2, 8 mil valores são retornados
O erro associado é probabilístico, não um associado teórico. O valor é o desvio padrão da distribuição de erros (o sigma) e 99,7% das estimativas terão um erro relativo de menos de 3 x sigma.
A seguinte imagem mostra a função de distribuição de probabilidade do erro de estimativa relativa, em percentuais, para todas as configurações de precisão com suporte: