Configurar um grupo de disponibilidade Always On distribuído
Aplica-se: ![]() SQL Server
SQL Server
Para criar um grupo de disponibilidade distribuído, você deve criar dois grupos de disponibilidade, cada um com seu próprio ouvinte. Em seguida, você combina esses grupos de disponibilidade em um grupo de disponibilidade distribuída. As etapas a seguir fornecem um exemplo básico em Transact-SQL. Este exemplo não abrange todos os detalhes da criação de grupos de disponibilidade e ouvintes, focando apenas nos requisitos básicos.
Para obter uma visão geral técnica dos grupos de disponibilidade distribuídos, consulte Grupos de disponibilidade distribuídos.
Pré-requisitos
Para configurar um grupo de disponibilidade distribuída, você deve ter o seguinte:
- Uma versão do SQL Server com suporte
Observação
Se você configurou o ouvinte para o grupo de disponibilidade em seu SQL Server na VM do Azure usando um DNN (nome de rede distribuído), não há suporte para a configuração de um grupo de disponibilidade distribuído na parte superior do grupo de disponibilidade. Para saber mais, confira SQL Server na interoperabilidade de recursos de VM do Azure com o ouvinte AG e DNN.
Definir os ouvintes do ponto de extremidade para escutar em todos os endereços IP
Verifique se os pontos de extremidade podem se comunicar entre os diferentes grupos de disponibilidade no grupo de disponibilidade distribuído. Se um grupo de disponibilidade for definido como uma rede específica no ponto de extremidade, o grupo de disponibilidade distribuída não funcionará corretamente. Em cada servidor que hospeda uma réplica no grupo de disponibilidade distribuído, configure o ouvinte para ouvir em todos os endereços IP (LISTENER_IP = ALL).
Criar um ponto de extremidade para escutar todos os endereços IP
Por exemplo, o script a seguir cria um ponto de extremidade do ouvinte na porta TCP 5022 que escuta em todos os endereços IP.
CREATE ENDPOINT [aodns-hadr]
STATE=STARTED
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL)
FOR DATA_MIRRORING (
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
)
GO
Alterar um ponto de extremidade para escutar todos os endereços IP
Por exemplo, o script a seguir altera um ponto de extremidade do ouvinte para que ele escute em todos os endereços IP.
ALTER ENDPOINT [aodns-hadr]
AS TCP (LISTENER_IP = ALL)
GO
Criar o primeiro grupo de disponibilidade
Criar o grupo de disponibilidade primário no primeiro cluster
Crie um grupo de disponibilidade no primeiro WSFC (cluster de failover do Windows Server). Neste exemplo, o grupo de disponibilidade é denominado ag1 para o banco de dados db1. A réplica primária do grupo de disponibilidade primário é conhecida como a primária global em um grupo de disponibilidade distribuído. Neste exemplo, a primária global é o servidor1.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Observação
O exemplo anterior usa a propagação automática, em que SEEDING_MODE é definido como AUTOMATIC para as réplicas e o grupo de disponibilidade distribuído. Essa configuração define que as réplicas secundárias e o grupo de disponibilidade secundário serão preenchidos automaticamente sem a necessidade de backup e restauração manual do banco de dados primário.
Unir as réplicas secundárias ao grupo de disponibilidade primário
Qualquer réplica secundária deve ser unida ao grupo de disponibilidade com ALTER AVAILABILITY GROUP usando a opção JOIN . Como a propagação automática é usada neste exemplo, você também deve chamar ALTER AVAILABILITY GROUP com a opção GRANT CREATE ANY DATABASE. Essa configuração permite que o grupo de disponibilidade crie o banco de dados e comece propagá-lo automaticamente da réplica primária.
Neste exemplo, os seguintes comandos são executados na réplica secundária, server2, para unir o grupo de disponibilidade ag1 . O grupo de disponibilidade então pode criar bancos de dados na réplica secundária.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Observação
Quando o grupo de disponibilidade cria um banco de dados em uma réplica secundária, ele define o proprietário do banco de dados como a conta que executou a instrução ALTER AVAILABILITY GROUP para conceder permissão para criar qualquer banco de dados. Para obter mais informações, consulte Conceder permissão para criar banco de dados na réplica secundária do grupo de disponibilidade.
Criar um ouvinte para o grupo de disponibilidade primário
Em seguida, crie um ouvinte para o grupo de disponibilidade primário no primeiro WSFC. Neste exemplo, o ouvinte é denominado ag1-listener. Para obter instruções detalhadas sobre como criar um ouvinte, confira Criar ou configurar um ouvinte do grupo de disponibilidade (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Criar o segundo grupo de disponibilidade
Em seguida, no segundo WSFC, crie um segundo grupo de disponibilidade, ag2. Neste caso, o banco de dados não é especificado, pois ele é propagado automaticamente do grupo de disponibilidade primário. A réplica primária do grupo de disponibilidade secundário é conhecida como o encaminhador em um grupo de disponibilidade distribuído. Neste exemplo, o servidor3 é o encaminhador.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Observação
O grupo de disponibilidade secundário deve usar o mesmo ponto de extremidade de espelhamento do banco de dados (no exemplo, a porta 5022). Caso contrário, a replicação será interrompida após um failover local.
Unir as réplicas secundárias ao grupo de disponibilidade secundário
Neste exemplo, os seguintes comandos são executados na réplica secundária, server4, para unir o grupo de disponibilidade ag2 . O grupo de disponibilidade então pode criar bancos de dados na réplica secundária para oferecer suporte à propagação automática.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Criar um ouvinte para o grupo de disponibilidade secundário
Em seguida, crie um ouvinte para o grupo de disponibilidade secundário no segundo WSFC. Neste exemplo, o ouvinte é denominado ag2-listener. Para obter instruções detalhadas sobre como criar um ouvinte, confira Criar ou configurar um ouvinte do grupo de disponibilidade (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Criar um grupo de disponibilidade distribuído no primeiro cluster
No primeiro WSFC, crie um grupo de disponibilidade distribuído (denominado distributedag neste exemplo). Use o comando CREATE AVAILABILITY GROUP com a opção DISTRIBUTED . O parâmetro AVAILABILITY GROUP ON especifica os grupos de disponibilidade membros, ag1 e ag2.
Para criar seu grupo de disponibilidade distribuída usando a propagação automática, use o seguinte código Transact-SQL:
CREATE AVAILABILITY GROUP [distributedag]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Observação
O LISTENER_URL especifica o ouvinte para cada grupo de disponibilidade, juntamente com o ponto de extremidade de espelhamento de banco de dados do grupo de disponibilidade. Neste exemplo, esse ponto de extremidade é a porta 5022 (não a porta 60173 usada para criar o ouvinte). Se você estiver usando um balanceador de carga, por exemplo, no Azure, adicione uma regra de balanceamento de carga à porta do grupo de disponibilidade distribuído. Adicione a regra à porta do ouvinte, além da porta da instância do SQL Server.
Cancelar a propagação automática para o encaminhador
Se, por qualquer motivo, for necessário cancelar a inicialização do encaminhador antes de os dois grupos de disponibilidade serem sincronizados, ALTERE o grupo de disponibilidade distribuído definindo o parâmetro SEEDING_MODE do encaminhador como MANUAL e cancele imediatamente a propagação. Execute o comando no primário global:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedag]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Ingressar o grupo de disponibilidade distribuído no segundo cluster
Em seguida, una o grupo de disponibilidade distribuída no segundo WSFC.
Para ingressar em seu grupo de disponibilidade distribuída usando a propagação automática, use o seguinte código Transact-SQL:
ALTER AVAILABILITY GROUP [distributedag]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Ingressar no banco de dados no secundário do segundo grupo de disponibilidade
Se o segundo grupo de disponibilidade foi configurado para usar a propagação automática, vá para a etapa 2.
- Se o segundo grupo de disponibilidade está usando propagação manual, restaure o backup que você fez no primário global para o secundário do segundo grupo de disponibilidade:
RESTORE DATABASE [db1]
FROM DISK = '<full backup location>' WITH NORECOVERY
RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY
- Depois que o banco de dados na réplica secundária do segundo grupo de disponibilidade tiver entrado em um estado de repouso, será necessário uni-o manualmente ao grupo de disponibilidade.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Fazer failover de um grupo de disponibilidade distribuído
Como o SQL Server 2022 (16.x) introduziu o suporte ao grupo de disponibilidade distribuído para a configuração REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, as instruções para fazer failover de uma disponibilidade distribuída são diferentes para o SQL Server 2022 e versões posteriores do que para o SQL Server 2019 e versões anteriores.
Para um grupo de disponibilidade distribuído, o único tipo de failover com suporte é um FORCE_FAILOVER_ALLOW_DATA_LOSS. Portanto, para evitar a perda de dados, você deve executar etapas extras (descritas em detalhes nesta seção) para garantir que os dados sejam sincronizados entre as duas réplicas antes de iniciar o failover.
No caso de uma emergência em que a perda de dados é aceitável, você pode iniciar um failover sem garantir a sincronização de dados executando:
ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS
Você pode usar o mesmo comando para fazer failover para o encaminhador, bem como failback para o primário global.
No SQL Server 2022 (16.x) e posterior, você pode definir a configuração REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT de um grupo de disponibilidade distribuído, que foi projetado para garantir que não haja perda de dados quando um grupo de disponibilidade distribuído falhar. Se essa configuração estiver definida, siga as etapas nesta seção para fazer failover do grupo de disponibilidade distribuído. Se você não quiser usar a configuração REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, siga as instruções para fazer failover de um grupo de disponibilidade distribuído no SQL Server 2019 e versões anteriores.
Para garantir que não haja perda de dados:
- Interrompa todas as transações nos bancos de dados primários globais (ou seja, bancos de dados do grupo de disponibilidade primário)
- Defina o grupo de disponibilidade distribuído como confirmação síncrona.
- Aguarde até que o grupo de disponibilidade distribuído seja sincronizado e tenha o mesmo last_hardened_lsn por banco de dados.
Depois que os dados forem sincronizados, você poderá fazer failover do grupo de disponibilidade distribuído:
- Na réplica primária global, defina a função do grupo de disponibilidade distribuído como
SECONDARY, o que torna o grupo de disponibilidade distribuído indisponível. - Defina a configuração
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITdo grupo de disponibilidade distribuído como 1 usando ALTER AVAILABILITY GROUP. - Teste a prontidão de failover.
- Faça failover do grupo de disponibilidade primário usando ALTER AVAILABILITY GROUP com
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Defina o grupo de disponibilidade distribuído REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT como 0.
Os exemplos de Transact-SQL a seguir demonstram as etapas detalhadas para fazer failover do grupo de disponibilidade distribuído denominado distributedag:
Para verificar se nenhum dado foi perdido, interrompa todas as transações nos bancos de dados primários globais (ou seja, bancos de dados do grupo de disponibilidade primário). Em seguida, defina o grupo de disponibilidade distribuído como commit síncrono executando o código a seguir em ambos, no primário global e no encaminhador.
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedag] MODIFY AVAILABILITY GROUP ON 'ag1' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), 'ag2' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ); -- verifies the commit state of the distributed availability group select ag.name, ag.is_distributed, ar.replica_server_name, ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc, ars.operational_state_desc, ars.synchronization_health_desc from sys.availability_groups ag join sys.availability_replicas ar on ag.group_id=ar.group_id left join sys.dm_hadr_availability_replica_states ars on ars.replica_id=ar.replica_id where ag.is_distributed=1 GOObservação
Em um grupo de disponibilidade distribuído, o status de sincronização entre os dois grupos de disponibilidade depende do modo de disponibilidade de ambas as réplicas. Para o modo de confirmação síncrona, tanto o grupo de disponibilidade primária quanto o grupo de disponibilidade secundária atuais precisam ter o modo de disponibilidade
SYNCHRONOUS_COMMIT. Por esse motivo, você precisa executar o script anterior, tanto na réplica primária global quanto no encaminhador.Aguarde até que o status do grupo de disponibilidade distribuído seja alterado para
SYNCHRONIZEDe todas as réplicas tenham o mesmo last_hardened_lsn (por banco de dados). Execute a seguinte consulta no primário global, que é a réplica primária do grupo de disponibilidade primário, bem como o encaminhador para verificar synchronization_state_desc e last_hardened_lsn:-- Run this query on the Global Primary and the forwarder -- Check the results to see if synchronization_state_desc is SYNCHRONIZED, and the last_hardened_lsn is the same per database on both the global primary and forwarder -- If not rerun the query on both side every 5 seconds until it is the case -- SELECT ag.name , drs.database_id , db_name(drs.database_id) as database_name , drs.group_id , drs.replica_id , drs.synchronization_state_desc , drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag on drs.group_id = ag.group_id;Continue depois que o grupo de disponibilidade synchronization_state_desc for
SYNCHRONIZEDe last_hardened_lsn for igual por banco de dados no primário global e no encaminhador. Se synchronization_state_desc não forSYNCHRONIZEDou last_hardened_lsn não for igual, execute o comando a cada cinco segundos até que ele seja alterado. Não continue até que synchronization_state_desc =SYNCHRONIZEDe last_hardened_lsn sejam iguais por banco de dados.Na primária global, defina a função do grupo de disponibilidade distribuído como
SECONDARY.ALTER AVAILABILITY GROUP distributedag SET (ROLE = SECONDARY);Neste ponto, o grupo de disponibilidade distribuído não está disponível.
Para o SQL Server 2022 (16.x) e posterior, no primário global, defina REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.
ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Teste a prontidão de failover. Execute a seguinte consulta no primário global e no encaminhador:
-- Run this query on the Global Primary and the forwarder -- Check the results to see if the last_hardened_lsn is the same per database on both the global primary and forwarder -- The availability group is ready to fail over when the last_hardened_lsn is the same for both availability groups per database -- SELECT ag.name, drs.database_id, db_name(drs.database_id) as database_name, drs.group_id, drs.replica_id, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag ON drs.group_id = ag.group_id;O grupo de disponibilidade estará pronto para fazer failover quando last_hardened_lsn for igual para ambos os grupos de disponibilidade por banco de dados. Se last_hardened_lsn não for igual após um período de tempo, para evitar a perda de dados, faça failback para o primário global executando esse comando nele e, em seguida, comece de novo da segunda etapa:
-- If the last_hardened_lsn is not the same after a period of time, to avoid data loss, -- we need to fail back to the global primary by running this command on the global primary -- and then start over from the second step: ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Faça failover do grupo de disponibilidade primário para o grupo de disponibilidade secundário. Execute o comando a seguir no encaminhador, o SQL Server que hospeda a réplica primária do grupo de disponibilidade secundário.
-- Once the last_hardened_lsn is the same per database on both sides -- We can Fail over from the primary availability group to the secondary availability group. -- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Após esta etapa, o grupo de disponibilidade distribuído estará disponível.
Para SQL Server 2022 (16.x) e posterior, desmarque o grupo de disponibilidade distribuído
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);
Depois de concluir essas etapas, será executado failover do grupo de disponibilidade distribuído sem perda de dados. Se os grupos de disponibilidade estiverem em uma distância geográfica que causa latência, altere o modo de disponibilidade de volta para ASYNCHRONOUS_COMMIT.
Remover um grupo de disponibilidade distribuída
A seguinte instrução Transact-SQL remove um grupo de disponibilidade distribuído denominado distributedag:
DROP AVAILABILITY GROUP [distributedag]
Criar um grupo de disponibilidade distribuído com instâncias de cluster de failover
Você pode criar um grupo de disponibilidade distribuído usando um grupo de disponibilidade em uma FCI (instância de cluster de failover). Nesse caso, não é necessário um ouvinte do grupo de disponibilidade. Use o VNN (nome de rede virtual) para a réplica primária da instância FCI. O exemplo a seguir mostra um grupo de disponibilidade distribuído chamado SQLFCIDAG. Um grupo de disponibilidade é SQLFCIAG. SQLFCIAG tem duas réplicas FCI. O VNN da réplica FCI primária é SQLFCIAG-1, e o VNN da réplica FCI secundária é SQLFCIAG-2. O grupo de disponibilidade distribuído também inclui o SQLAG-DR, para a recuperação de desastre.
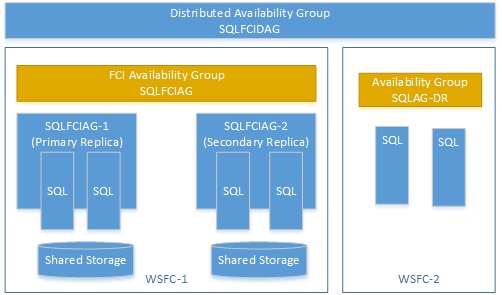
A DDL a seguir cria esse grupo de disponibilidade distribuído.
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
A URL do ouvinte é o VNN da instância da FCI primária.
Fazer failover manual da FCI no grupo de disponibilidade distribuído
Para fazer failover manual do grupo de disponibilidade da FCI, atualize o grupo de disponibilidade distribuído para que ele reflita a alteração da URL do ouvinte. Por exemplo, execute a seguinte DDL no primário global do AG distribuído e o encaminhador do AG distribuído do SQLFCIDAG:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)
Próximas etapas
CREATE AVAILABILITY GROUP (Transact-SQL)
ALTER AVAILABILITY GROUP (Transact-SQL)