Explore uma solução de alta disponibilidade e recuperação de desastres IaaS
Há muitas combinações diferentes de recursos que podem ser implantados no Azure para IaaS. Esta seção abordará cinco exemplos comuns de arquiteturas HADR (alta disponibilidade e recuperação de desastres) do SQL Server no Azure.
Exemplo de alta disponibilidade de região única 1 – Grupos de disponibilidade Always On
Se você só precisa de alta disponibilidade e não de recuperação de desastres, configurar um AG (grupo de disponibilidade) é um dos métodos mais onipresentes, não importa onde você esteja usando o SQL Server. A imagem abaixo é um exemplo de como poderia ser um possível AG em uma única região.
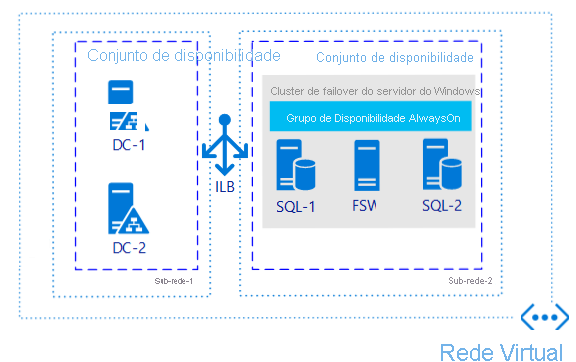
Por que vale a pena considerar essa arquitetura?
Essa arquitetura protege os dados por ter mais de uma cópia em máquinas virtuais (VMs) diferentes.
Essa arquitetura permite que você atenda ao RTO (Recovery Time Objetive, objetivo de tempo de recuperação) e ao RPO (Recovery Point Objetive, objetivo de ponto de recuperação) com perda de dados mínima a nenhuma, se implementada corretamente.
Essa arquitetura fornece um método fácil e padronizado para que os aplicativos acessem réplicas primárias e secundárias (se coisas como réplicas somente leitura forem usadas).
Essa arquitetura fornece disponibilidade aprimorada durante cenários de aplicação de patches.
Essa arquitetura não precisa de armazenamento compartilhado, portanto, há menos complicações do que ao usar uma FCI (instância de cluster de failover).
Exemplo de alta disponibilidade de região única 2 – Instância de cluster de failover Always On
Até os AGs serem introduzidos, as FCIs eram a maneira mais popular de implementar a alta disponibilidade do SQL Server. As FCIs, no entanto, foram projetadas quando as implantações físicas eram dominantes. Em um mundo virtualizado, as FCIs não fornecem muitas das mesmas proteções da mesma forma que no hardware físico, porque é raro uma VM ter um problema. As FCIs foram projetadas para proteger contra coisas como falha de placa de rede ou falha de disco, que provavelmente não aconteceriam no Azure.
Dito isto, as FCIs têm um lugar no Azure. Eles funcionam, e desde que você tenha as expectativas certas sobre o que é ou não fornecido, uma FCI é uma solução perfeitamente aceitável. A imagem abaixo, da documentação da Microsoft, mostra uma visão de alto nível da aparência de uma implantação FCI ao usar o Storage Spaces Direct.
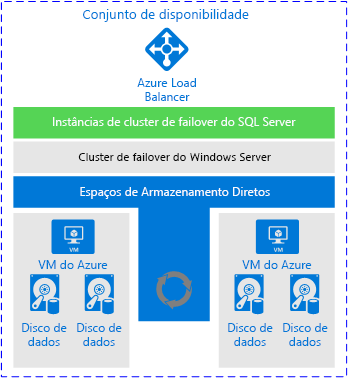
Por que vale a pena considerar essa arquitetura?
As FCIs ainda são uma solução de disponibilidade popular.
A história do armazenamento compartilhado está melhorando com recursos como o Azure Shared Disk.
Essa arquitetura atende à maioria dos RTO e RPO para HA (embora o DR não seja manipulado).
Essa arquitetura fornece um método fácil e padronizado para os aplicativos acessarem a instância clusterizada do SQL Server.
Essa arquitetura fornece disponibilidade aprimorada durante cenários de aplicação de patches.
Exemplo de recuperação de desastres 1 – Grupo de disponibilidade Always On híbrido ou multirregião
Se você estiver usando AGs, uma opção é configurar o AG em várias regiões do Azure ou potencialmente como uma arquitetura híbrida. Isso significa que todos os nós que contêm as réplicas participam do mesmo WSFC. Isso pressupõe uma boa conectividade de rede, especialmente se esta for uma configuração híbrida. Uma das maiores considerações seria o recurso de testemunhas para o WSFC. Essa arquitetura exigiria que o AD DS e o DNS estivessem disponíveis em todas as regiões e, potencialmente, também no local, se essa for uma solução híbrida. A imagem abaixo mostra a aparência de um único AG configurado em dois locais usando o Windows Server.

Por que vale a pena considerar essa arquitetura?
Esta arquitetura é uma solução comprovada; não é diferente de ter dois data centers hoje em uma topologia AG.
Essa arquitetura funciona com as edições Standard e Enterprise do SQL Server.
Os AGs fornecem naturalmente redundância com cópias adicionais de dados.
Essa arquitetura faz uso de um recurso que fornece HA e D/R
Exemplo 2 de recuperação de desastres – Grupo de disponibilidade distribuída
Um AG distribuído é um recurso somente Enterprise Edition introduzido no SQL Server 2016. É diferente de uma AG tradicional. Em vez de ter um WSFC subjacente onde todos os nós contêm réplicas que participam de um AG, conforme descrito no exemplo anterior, um AG distribuído é composto por vários AGs. A réplica primária que contém o banco de dados de gravação de leitura é conhecida como primária global. O primário do segundo AG é conhecido como um encaminhador e mantém a(s) réplica(s) secundária(s) desse AG em sincronia. No essencial, trata-se de uma AG de AG.
Essa arquitetura torna mais fácil lidar com coisas como quórum, uma vez que cada agrupamento manteria seu próprio quórum, o que significa que também tem seu próprio testemunho. Uma AG distribuída funcionaria se você estiver usando o Azure para todos os recursos ou se estiver usando uma arquitetura híbrida.
A imagem abaixo mostra um exemplo de configuração AG distribuída. Existem dois WSFCs. Imagine que cada um está em uma região diferente do Azure ou um está no local e o outro está no Azure. Cada WSFC tem um AG com duas réplicas. O primário global no AG 1 está mantendo o secundário da réplica do AG 1 sincronizado, bem como o forwarder, que também é o primário do AG 2. Essa réplica mantém sincronizada a réplica secundária do AG 2.
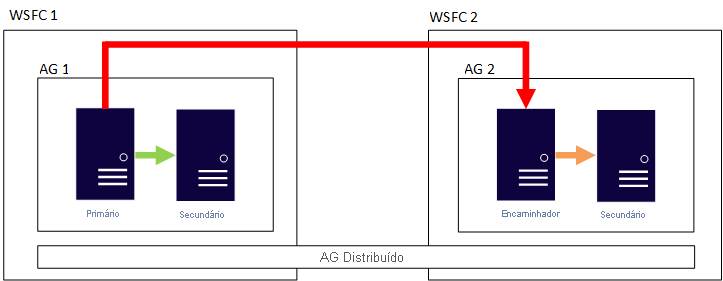
Por que vale a pena considerar essa arquitetura?
Essa arquitetura separa o WSFC como um único ponto de falha se todos os nós perderem a comunicação
Nessa arquitetura, um primário não está sincronizando todas as réplicas secundárias.
Essa arquitetura pode fornecer failback de um local para outro.
Exemplo 3 de recuperação de desastres – Envio de logs
O envio de logs é um dos métodos HADR mais antigos para configurar a recuperação de desastres para o SQL Server. Conforme descrito acima, a unidade de medida é o backup do log de transações. A menos que a mudança para um modo de espera quente seja planejada para garantir que não haja perda de dados, a perda de dados provavelmente ocorrerá. Quando se trata de recuperação de desastres, é sempre melhor assumir alguma perda de dados, mesmo que mínima. A imagem abaixo, da documentação da Microsoft, mostra um exemplo de topologia de envio de logs.
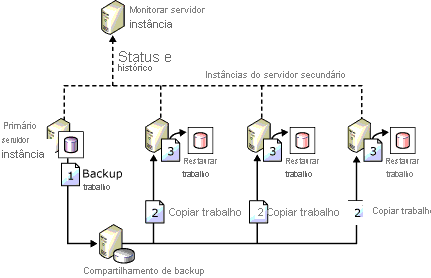
Por que vale a pena considerar essa arquitetura?
O envio de logs é um recurso comprovado e comprovado que existe há mais de 20 anos
O envio de logs é fácil de implantar e administrar, pois se baseia em backup e restauração.
O envio de logs é tolerante a redes que não são robustas.
O envio de logs atende à maioria das metas de RTO e RPO para DR.
O envio de logs é uma boa maneira de proteger as FCIs.
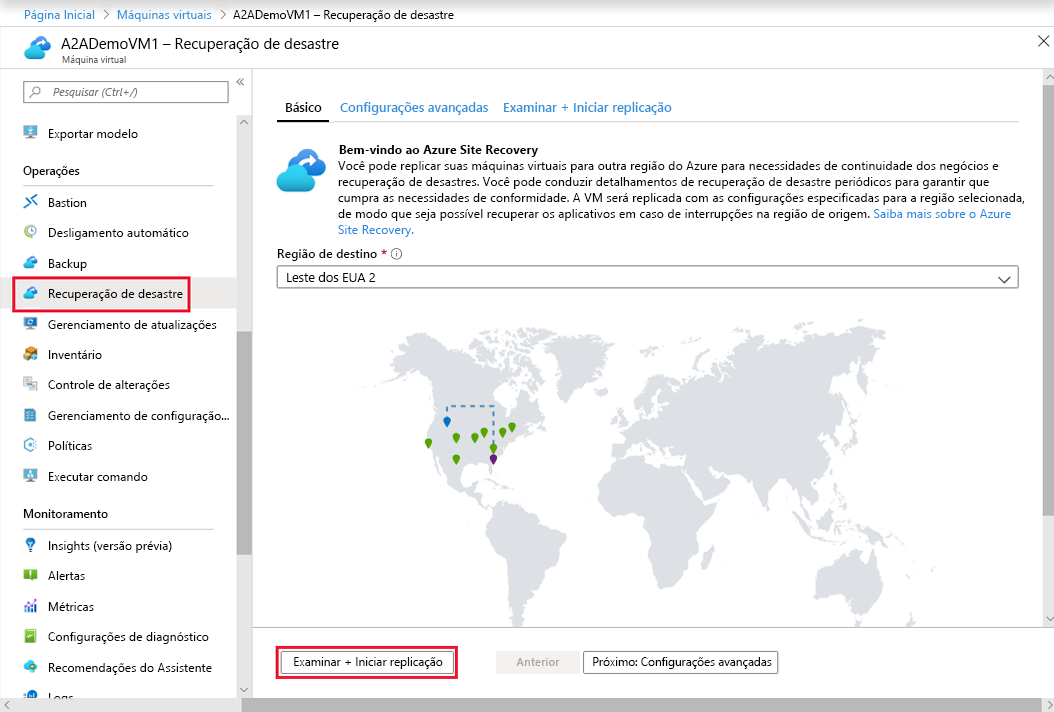
Exemplo de recuperação de desastres 4 – Azure Site Recovery
Para aqueles que não desejam implementar uma solução de desastre baseada no SQL Server, o Azure Site Recovery é uma opção potencial. No entanto, a maioria dos profissionais de dados prefere uma abordagem centrada no banco de dados, pois geralmente terá um RPO mais baixo.
A imagem abaixo, da documentação da Microsoft. mostra onde no portal do Azure você configuraria a replicação para o Azure Site Recovery.
Por que vale a pena considerar essa arquitetura?
O Azure Site Recovery funcionará com mais do que apenas o SQL Server.
O Azure Site Recovery pode atender ao RTO e, possivelmente, ao RPO.
O Azure Site Recovery é fornecido como parte da plataforma Azure.