Combine e otimize dados
As organizações geralmente agrupam diferentes tipos de informações de muitas fontes. As informações são armazenadas em um grande número de tabelas. Ocasionalmente, você pode precisar unir tabelas com base em relações lógicas entre elas, para uma análise ou relatórios mais profundos. No cenário de empresa de varejo, você usa tabelas para clientes, produtos e informações de vendas.
Neste módulo, você aprende sobre várias maneiras de combinar dados em consultas Kusto para fornecer aos membros da sua equipe as informações de que precisam para aumentar o conhecimento do produto e aumentar as vendas.
Compreender os seus dados
Antes de começar a escrever consultas que combinam informações de suas tabelas, você precisa entender seus dados. Quando você trabalha com consultas Kusto, você quer pensar em tabelas como pertencendo amplamente a uma das duas categorias:
- Tabelas de fatos: tabelas cujos registros são fatos imutáveis, como a tabela SalesFact no cenário da empresa de varejo. Nessas tabelas, os registros são progressivamente anexados de forma em streaming ou em grandes partes. Os registos permanecem na tabela até serem removidos e nunca serem atualizados.
- Tabelas de dimensão: tabelas cujos registros são dimensões mutáveis, como as tabelas Clientes e Produtos no cenário da empresa de varejo. Essas tabelas contêm dados de referência, como tabelas de pesquisa de um identificador de entidade para suas propriedades. As tabelas de dimensão não são atualizadas regularmente com novos dados.
Em nosso cenário de empresa de varejo, você usa tabelas de dimensão para enriquecer a tabela SalesFact com informações adicionais ou para fornecer mais opções para filtrar os dados para consultas.
Você também deseja entender os volumes de dados com os quais está trabalhando e sua estrutura, ou esquema (nomes e tipos de coluna). Você pode executar as seguintes consultas para obter essas informações substituindo TABLE_NAME pelo nome da tabela que está examinando:
Para obter o número de registros em uma tabela, use o
countoperador:TABLE_NAME | countPara obter o esquema de uma tabela, use o
getschemaoperador :TABLE_NAME | getschema
A execução dessas consultas nas tabelas de fatos e dimensões no cenário da empresa de varejo fornece informações como o exemplo a seguir:
| Tabela | Registos | Esquema |
|---|---|---|
| Fato: Vendas | 2,832,193 | - SalesAmount (real) - Custo Total (real) - DateKey (datetime) - ProductKey (longo) - CustomerKey (longo) |
| Clientes | 18,484 | - CityName (string) - CompanyName (string) - ContinentName (string) - CustomerKey (longo) - Educação (string) - FirstName (string) - Sexo (string) - Sobrenome (string) - Estado Conjugal (string) - Ocupação (corda) - RegionCountryName (string) - StateProvinceName (string) |
| Produtos | 2,517 | - ProductName (string) - Fabricante (string) - ColorName (string) - ClassName (string) - ProductCategoryName (cadeia de caracteres) - ProductSubcategoryName (string) - ProductKey (longo) |
Na tabela, destacamos os identificadores exclusivos CustomerKey e ProductKey usados para combinar registros entre tabelas.
Compreender as consultas de várias tabelas
Depois de analisar seus dados, você precisa entender como combinar tabelas para fornecer as informações de que precisa. As consultas Kusto fornecem vários operadores que você pode usar para combinar dados de várias tabelas, incluindo os lookupoperadores , joine union .
O join operador mescla as linhas de duas tabelas combinando valores das colunas especificadas de cada tabela. A tabela resultante depende do tipo de junção que você usa. Por exemplo, se você usar uma junção interna, a tabela terá as mesmas colunas que a tabela esquerda (às vezes chamada de tabela externa), além das colunas da tabela direita (às vezes chamada de tabela interna). Saiba mais sobre os tipos de junção na próxima seção. Para obter o melhor desempenho, se uma tabela for sempre menor que a outra, use-a como o lado esquerdo do join operador.
O lookup operador é uma implementação especial de um join operador que otimiza o desempenho de consultas onde uma tabela de fatos é enriquecida com dados de uma tabela de dimensão. Ele estende a tabela de fatos com valores que são pesquisados em uma tabela de dimensão. Para obter o melhor desempenho, o sistema, por padrão, assume que a tabela esquerda é a tabela maior (fato) e a tabela direita é a tabela menor (dimensão). Esta suposição é exatamente o oposto da suposição usada pelo join operador.
O union operador retorna todas as linhas de duas ou mais tabelas. É útil quando você deseja combinar dados de várias tabelas.
A materialize() função armazena em cache os resultados dentro de uma execução de consulta para reutilização subsequente na consulta. É como tirar um instantâneo dos resultados de uma subconsulta e usá-lo várias vezes dentro da consulta. Esta função é útil na otimização de consultas para cenários onde os resultados:
- São caros para calcular
- São não determinísticos
Em breve, você aprenderá mais sobre os vários operadores de mesclagem de tabela e a materialize() função, e como usá-los.
Tipos de adesão
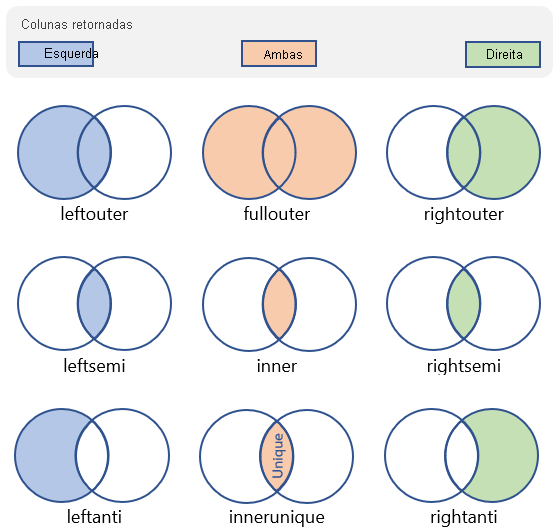
Há muitos tipos diferentes de junções que podem ser executadas que afetam o esquema e as linhas na tabela resultante. A tabela a seguir mostra os tipos de junções suportadas pela Kusto Query Language e o esquema e as linhas que elas retornam:
| Tipo de Associação | Description | Ilustração |
|---|---|---|
innerunique (padrão) |
Junção interna com desduplicação do lado esquerdo Esquema: Todas as colunas de ambas as tabelas, incluindo as teclas correspondentes Linhas: Todas as linhas desduplicadas da tabela esquerda que correspondem às linhas da tabela direita |

|
inner |
Junção interna padrão Esquema: Todas as colunas de ambas as tabelas, incluindo as teclas correspondentes Linhas: Apenas linhas correspondentes de ambas as tabelas |

|
leftouter |
Junção externa esquerda Esquema: Todas as colunas de ambas as tabelas, incluindo as teclas correspondentes Linhas: Todos os registos da tabela esquerda e apenas as linhas correspondentes da tabela direita |
|
rightouter |
Junção externa direita Esquema: Todas as colunas de ambas as tabelas, incluindo as teclas correspondentes Linhas: Todos os registos da tabela direita e apenas as linhas correspondentes da tabela esquerda |

|
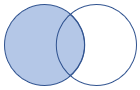
fullouter |
Junção exterior completa Esquema: Todas as colunas de ambas as tabelas, incluindo as teclas correspondentes Linhas: Todos os registros de ambas as tabelas com células incomparáveis preenchidas com nulo |
|
leftsemi |
Semi junta esquerda Esquema: Todas as colunas da tabela à esquerda Linhas: Todos os registos da tabela esquerda que correspondem aos registos da tabela direita |

|
leftanti, , antileftantisemi |
Esquerda anti junção e semi variante Esquema: Todas as colunas da tabela à esquerda Linhas: Todos os registos da tabela da esquerda que não correspondem aos registos da tabela da direita |

|
rightsemi |
Semi junção direita Esquema: Todas as colunas da tabela direita Linhas: Todos os registos da tabela da direita que correspondem aos registos da tabela da esquerda |

|
rightanti, rightantisemi |
Direito anti junção e semi variante Esquema: Todas as colunas da tabela direita Linhas: Todos os registos da tabela direita que não correspondem aos registos da tabela esquerda |

|
Observe que o tipo de associação padrão é innerunique, e não precisa ser especificado. No entanto, é uma prática recomendada sempre especificar explicitamente o tipo de junção para maior clareza.
À medida que você progride neste módulo, você também aprende sobre as arg_min() funções e arg_max() agregação, o as operador como uma alternativa à let instrução e a startofmonth() função para ajudar com o agrupamento de dados por mês.