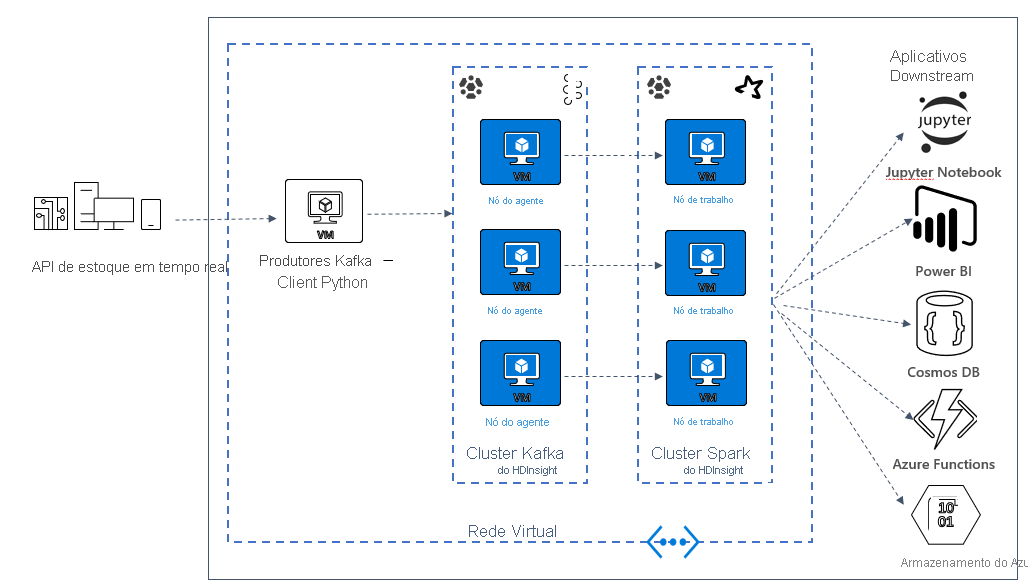
Crie uma arquitetura Kafka e Spark
Para usar Kafka e Spark juntos no Azure HDInsight, você deve colocá-los dentro da mesma VNet ou emparelhar as VNets para que os clusters operem com resolução de Nome DNS.
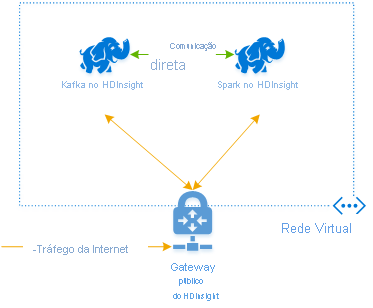
Para criar clusters na mesma rede virtual, o procedimento é:
- Criar um grupo de recursos
- Adicionar uma VNet ao grupo de recursos
- Adicione um cluster Kafka e um cluster Spark à mesma VNet ou, alternativamente, emparelhe as VNets nas quais esses serviços operam com resolução de nomes DNS.
A maneira recomendada de conectar o cluster HDInsight Kafka e Spark é o conector nativo Spark-Kafka, que permite que o cluster Spark acesse partições individuais de dados dentro do cluster Kafka, o que aumenta o paralelismo que você tem em seu trabalho de processamento em tempo real e fornece uma taxa de transferência muito alta.
Quando ambos os clusters estão na mesma VNet, você também pode usar FQDNs do Kafka Broker no código de streaming do Spark e pode criar regras NSG na VNet para segurança corporativa.
Arquitetura de soluções
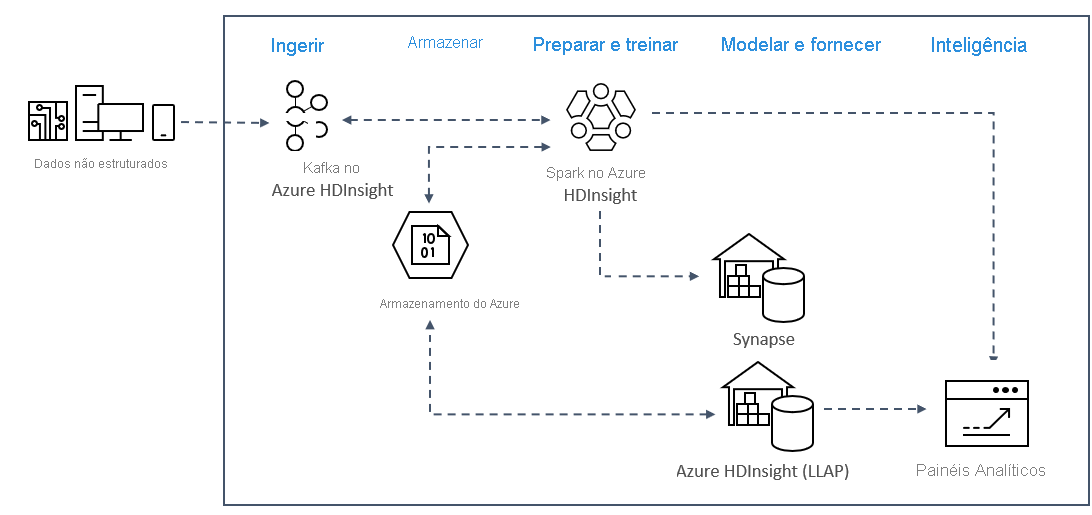
Os padrões de análise de streaming em tempo real no Azure normalmente usam a seguinte arquitetura de solução.
- Ingerir: dados não estruturados ou estruturados são ingeridos em um cluster Kafka no Azure HDInsight.
- Preparação e treino: os dados são preparados e treinados com o Spark no HDInsight.
- Modelar e servir: os dados são colocados em um data warehouse, como o Azure Synapse ou o HDInsight Interactive Query.
- Inteligência: os dados são servidos para o painel de análise, como o Power BI ou o Tableau.
- Armazenamento: os dados são colocados em uma solução de armazenamento frio, como o Armazenamento do Azure, e são servidos posteriormente.
Arquitetura de cenário de exemplo
Na próxima unidade, você começará a criar a arquitetura da solução para o aplicativo de exemplo. Este exemplo usa um arquivo de modelo do Azure Resource Manager para criar o grupo de recursos, a VNET, o cluster Spark e o cluster Kafka.
Depois que os clusters forem implantados, você entrará em um dos brokers Kafka e copiará o arquivo do produtor Python para o headnode. Esse arquivo do produtor fornece preços de estoque artificiais a cada 10 segundos, ele também grava o número da partição e o deslocamento da mensagem no console.
Quando o produtor estiver em execução, você poderá carregar o bloco de anotações Jupyter para o cluster do Spark. No bloco de anotações, você conectará os clusters Spark e Kafka e executará algumas consultas de exemplo nos dados, incluindo encontrar os valores altos e baixos de um estoque em uma janela de evento.