Conheça o Apache Spark
O Apache Spark é uma estrutura de processamento de dados distribuídos que permite a análise de dados em grande escala coordenando o trabalho entre vários nós de processamento em um cluster.
Como funciona o Spark
Os aplicativos Apache Spark são executados como conjuntos independentes de processos em um cluster, coordenados pelo objeto SparkContext em seu programa principal (chamado de programa de driver). O SparkContext se conecta ao gerenciador de cluster, que aloca recursos entre aplicativos usando uma implementação do Apache Hadoop YARN. Uma vez conectado, o Spark adquire executores em nós no cluster para executar o código do aplicativo.
O SparkContext executa a função principal e as operações paralelas nos nós do cluster e, em seguida, coleta os resultados das operações. Os nós leem e gravam dados de e para o sistema de arquivos e o cache transforma dados na memória como RDDs (Resilient Distributed Datasets ).
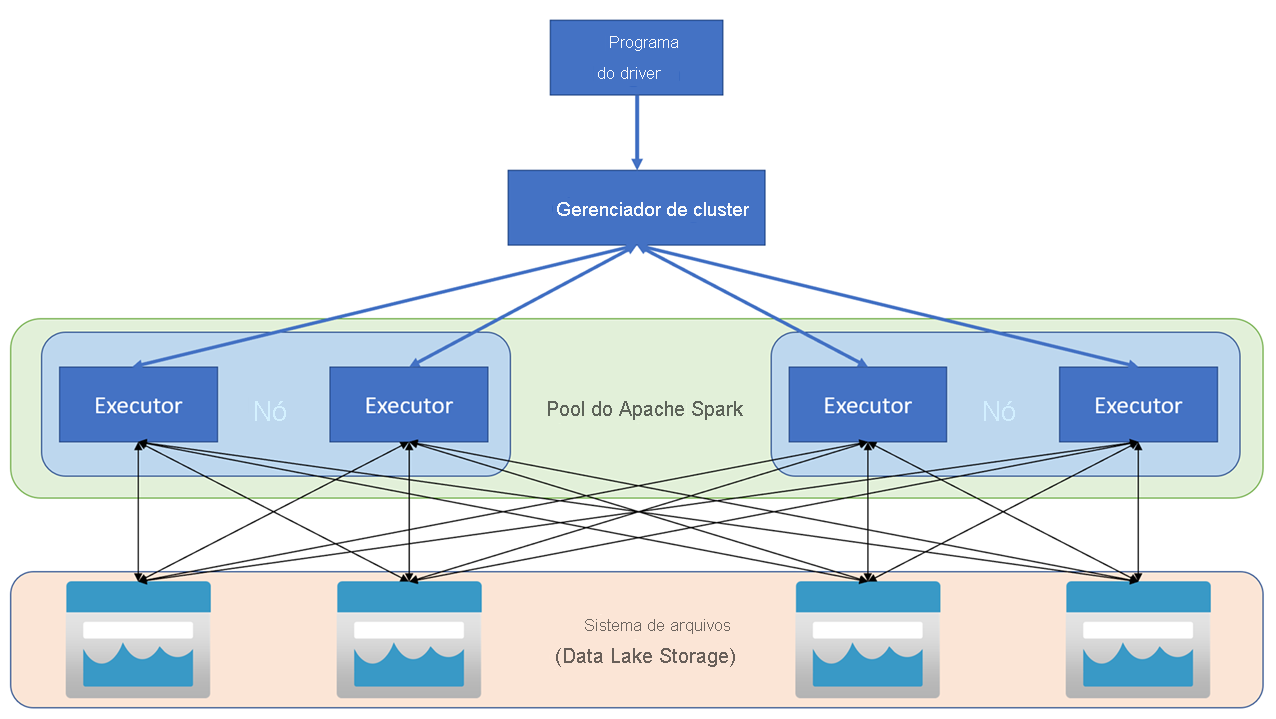
O SparkContext é responsável por converter um aplicativo em um gráfico acíclico direcionado (DAG). O gráfico consiste em tarefas individuais que são executadas dentro de um processo executor nos nós. Cada aplicação tem os seus próprios processos de executor, que permanecem em funcionamento ao longo da duração de toda a aplicação e executam tarefas em múltiplos threads.
Pools de faíscas no Azure Synapse Analytics
No Azure Synapse Analytics, um cluster é implementado como um pool do Spark, que fornece um tempo de execução para operações do Spark. Você pode criar um ou mais pools do Spark em um espaço de trabalho do Azure Synapse Analytics usando o portal do Azure ou no Azure Synapse Studio. Ao definir um pool do Spark, você pode especificar opções de configuração para o pool, incluindo:
- Um nome para a piscina de faíscas.
- O tamanho da máquina virtual (VM) usada para os nós no pool, incluindo a opção de usar nós habilitados para GPU acelerada por hardware.
- O número de nós no pool e se o tamanho do pool é fixo ou nós individuais podem ser colocados online dinamicamente para dimensionar automaticamente o cluster, caso em que você pode especificar o número mínimo e máximo de nós ativos.
- A versão do Spark Runtime a ser usada no pool, que dita as versões de componentes individuais, como Python, Java e outros que são instalados.
Gorjeta
Para obter mais informações sobre as opções de configuração do pool do Spark, consulte Configurações do pool do Apache Spark no Azure Synapse Analytics na documentação do Azure Synapse Analytics.
Os pools de faíscas em um espaço de trabalho do Azure Synapse Analytics não têm servidor - eles começam sob demanda e param quando ociosos.