Модель счета аналитики документов
Это содержимое относится к: версии 4.0 (GA) | Предыдущие версии: ![]()
![]() v3.1 (GA) версии 3.0 (GA)
v3.1 (GA) версии 3.0 (GA) ![]() версии 2.1 (GA)
версии 2.1 (GA) ![]()
::: moniker-end
Это содержимое относится к: версия 3.1 (GA) | Последняя версия: ![]() версия 4.0 (GA) | Предыдущие версии:
версия 4.0 (GA) | Предыдущие версии: ![]()
![]() v3.0
v3.0![]() версии 2.1
версии 2.1
Это содержимое относится к: версия 3.0 (GA) | Последние версии: ![]()
![]() версия 4.0 (GA)
версия 4.0 (GA) ![]() версии 3.1 | Предыдущая версия:
версии 3.1 | Предыдущая версия: ![]() версия 2.1
версия 2.1
Это содержимое относится к: версии 2.1 Последняя версия: ![]()
![]() версия 4.0 (GA) |
версия 4.0 (GA) |
Модель счета аналитики документов использует мощные возможности оптического распознавания символов (OCR) для анализа и извлечения ключевых полей и элементов строки из счетов по продажам, счетов за служебные услуги и заказов на покупку. Счета могут иметь различные форматы и качество изображения, включая фотографии, полученные с камеры телефона, отсканированные документы и цифровые PDF-файлы. API анализирует текст счета, извлекает ключевые сведения (например, имя заказчика, адрес выставления счета, дату и сумму оплаты) и возвращает структурированное представление данных в формате JSON. В настоящее время модель поддерживает счета на 27 языках.
Поддерживаемые типы документов:
- Счета
- Счета за коммунальные услуги
- Заказы на продажу
- Заказы на покупку
Автоматическая обработка счетов
Автоматическая обработка счетов — это процесс извлечения ключевых accounts payable полей из документов учетной записи выставления счетов. Извлеченные данные включают элементы строк из счетов, интегрированных с рабочими процессами с оплатой счетов (AP) для проверок и платежей. Исторически процесс оплаты счетов выполняется вручную и, следовательно, очень много времени. Точное извлечение ключевых данных из счетов обычно является первым и одним из наиболее важных шагов в процессе автоматизации счетов.
Пример счета, обработанного с помощью Document Intelligence Studio:

Пример счета, обработанный с помощью средства создания меток для аналитики документов:
Варианты разработки
Аналитика документов версии 4.0: 2024-11-30 (GA) поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Model ID |
|---|---|---|
| Модель накладных | • Аналитика документов• REST API • ПАКЕТ SDK для C# • Пакет SDK для Python• Пакет SDK для Java • Пакет SDK java для JavaScript |
prebuilt-invoice |
Аналитика документов версии 3.1 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Model ID |
|---|---|---|
| Модель накладных | • Аналитика документов• REST API • ПАКЕТ SDK для C# • Пакет SDK для Python• Пакет SDK для Java • Пакет SDK java для JavaScript |
prebuilt-invoice |
Аналитика документов версии 3.0 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Model ID |
|---|---|---|
| Модель накладных | • Аналитика документов• REST API • ПАКЕТ SDK для C# • Пакет SDK для Python• Пакет SDK для Java • Пакет SDK java для JavaScript |
prebuilt-invoice |
Аналитика документов версии 2.1 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы |
|---|---|
| Модель накладных | • Средство аналитики документов • REST API • пакет SDK для клиентской библиотеки • Контейнер Docker аналитики документов |
Требования к входным данным
Поддерживаемые форматы файлов:
Модель PDF Изображение: JPEG/JPG, ,BMPPNGTIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и
4МБ для бесплатного уровня (F0).Размеры изображения должны составлять от 50 пикселей до 50 пикселей и 10 000 пикселей x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту
8точки в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и
1ГБ для нейронной модели.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1ГБ не более 10 000 страниц. Для 2024-11-30 (GA) общий размер обучающих данных составляет2ГБ с не более чем 10 000 страниц.
- Поддерживаемые форматы файлов: JPEG, PNG, PDF и TIFF.
- Обрабатываются поддерживаемые PDF-файлы и TIFF до 2000 страниц. Для подписчиков уровня "Бесплатный" обрабатываются только две первые страницы.
- Поддерживаемый размер файла должен быть меньше 50 МБ и размеров не менее 50 x 50 пикселей и не более 10 000 x 10 000 пикселей.
Извлечение данных модели счета
Узнайте, как данные, включая сведения о клиентах, сведения о поставщике и элементы строки, извлекаются из счетов. Вам потребуются следующие ресурсы:
Подписка Azure — ее можно создать бесплатно.
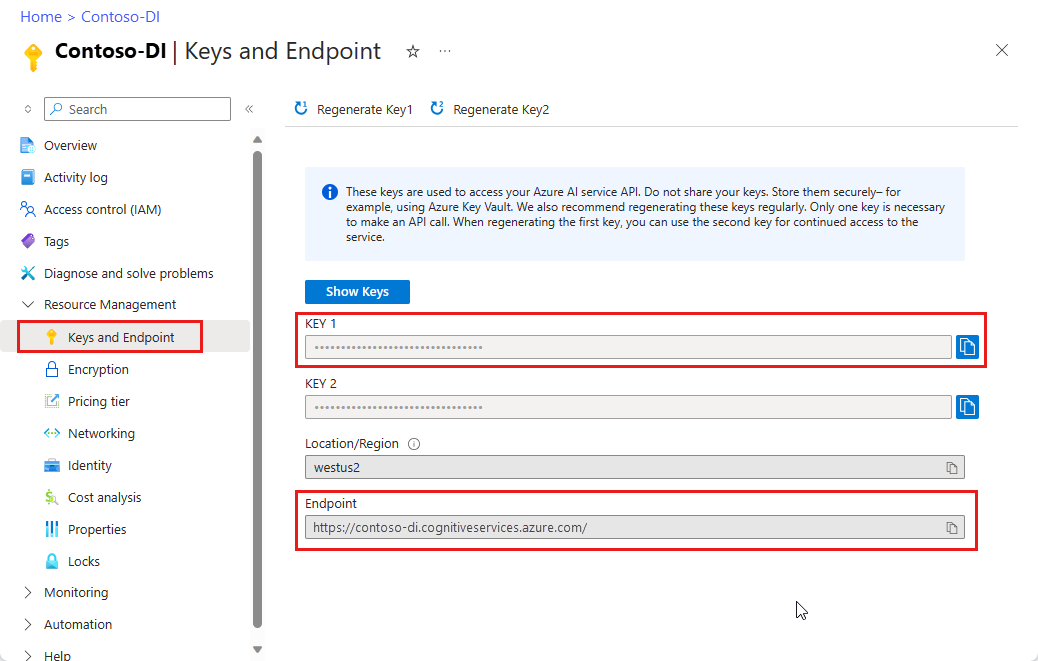
Экземпляр аналитики документов в портал Azure. Вы можете использовать ценовую категорию "Бесплатный" (
F0), чтобы поработать со службой. После развертывания ресурса выберите Перейти к ресурсу, чтобы получить ключ и конечную точку.
На домашней странице Document Intelligence Studio выберите "Счета".
Вы можете проанализировать пример счета или отправить собственные файлы.
Нажмите кнопку "Выполнить анализ ", а при необходимости настройте параметры анализа:

Средство разработки меток аналитики документов
Перейдите к инструменту аналитики документов.
На домашней странице примера инструмента выберите предварительно созданную модель, чтобы получить плитку данных .
Выберите тип формы для анализа из раскрывающегося меню.
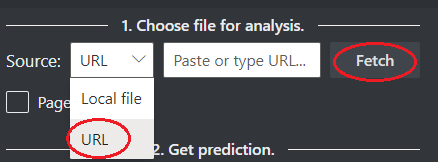
Выберите URL-адрес для файла, который необходимо проанализировать, в одном из следующих вариантов:
В поле Источник выберите URL-адрес в раскрывающемся меню, вставьте выбранный URL-адрес и нажмите кнопку Получить.
В поле конечной точки службы аналитики документов вставьте конечную точку, полученную в подписке Аналитики документов.
В поле ключа вставьте ключ, полученный из ресурса аналитики документов.

Щелкните элемент Run analysis (Выполнить анализ). Средство аналитики документов вызывает предварительно созданный API анализа и анализирует документ.
Просмотрите результаты. Просмотрите пары "ключ-значение", извлеченные, элементы строки, извлеченные текст и обнаруженные таблицы.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Примечание.
Пример средства маркировки данных не поддерживает файлы в формате BMP. Это ограничение средства, а не службы аналитики документов.
Поддерживаемые языки и языковые стандарты
Полный список поддерживаемых языков см . на странице поддержки языка предварительно созданной модели.
Извлечение полей
Поддерживаемые поля извлечения документов см . на странице схемы модели счета в нашем примере репозитория GitHub.
Пары ключ-значение счета и извлеченные позиции находятся в разделе
documentResultsвыходных данных JSON.
Пары "ключ-значение"
Предварительно созданная модель счета поддерживает необязательный возврат пар "ключ-значение". По умолчанию возврат пар "ключ-значение" отключен. Пары "ключ-значение" — это отдельные фрагменты внутри счета, которые определяют метку или ключ и связанный с ними ответ или значение. В счете эти пары могут быть меткой и значением, введенным пользователем для этого поля или номера телефона. Модель искусственного интеллекта предназначена для извлечения идентифицируемых ключей и значений на основе широкого спектра типов документов, форматов и структур.
Ключи также могут существовать в изоляции, когда модель обнаруживает, что ключ существует, но с ним не связано ни одно значение, или при обработке необязательных полей. Например, поле промежуточного имени можно оставить пустым в форме в некоторых экземплярах. Пары "ключ-значение" всегда являются диапазонами текста, содержащегося в документе. Для документов, в которых одно и то же значение описано разными способами, например клиент или пользователь, связанный ключ является клиентом или пользователем (в зависимости от контекста).
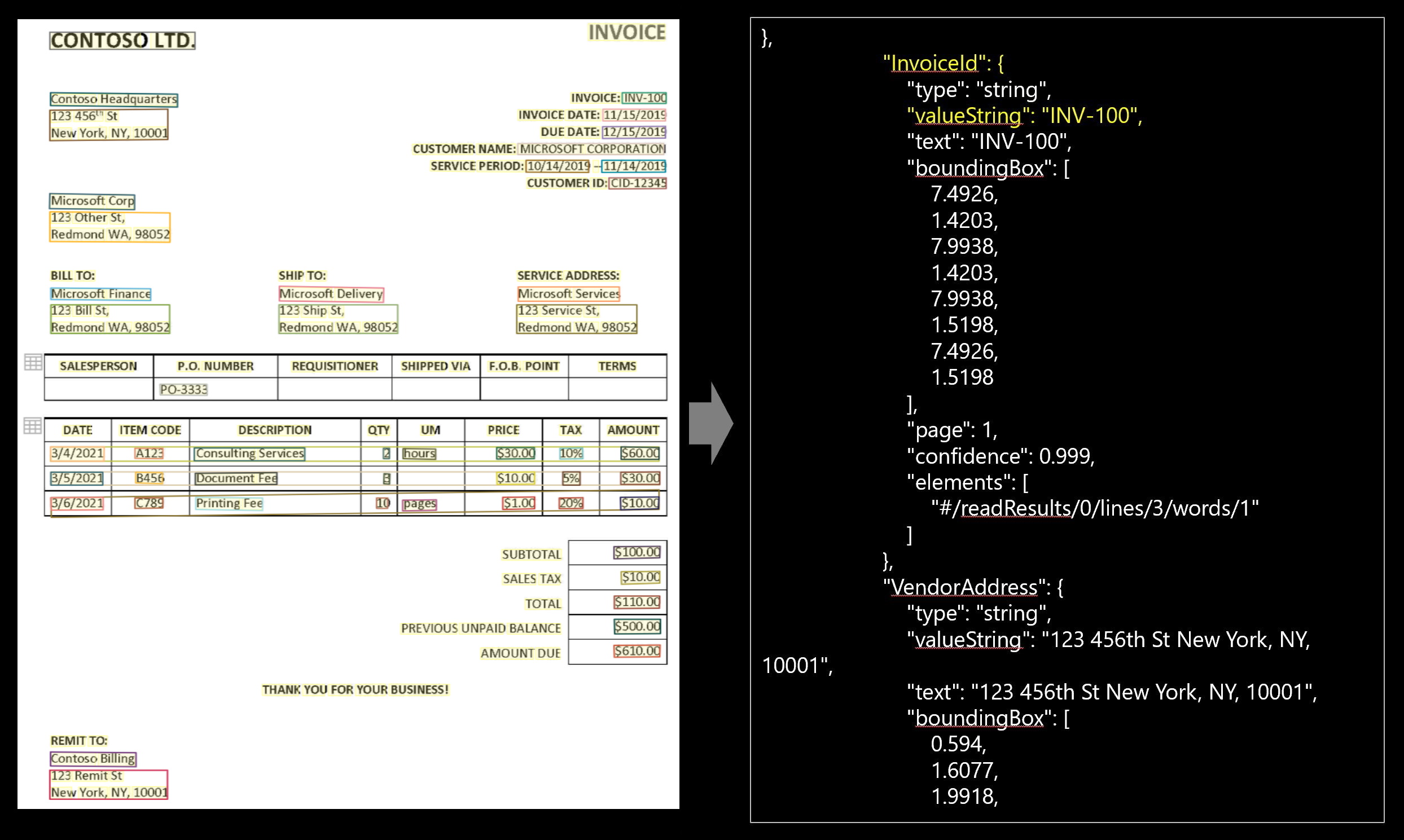
Выходные данные JSON
Выходные данные JSON состоят из трех частей:
- Узел
"readResults"содержит весь распознанный текст и все метки выделения. Текст организован по страницам, а затем по строкам, а затем по отдельным словам. "pageResults"узел содержит таблицы и ячейки, извлеченные с ограничивающими прямоугольниками, уверенностью и ссылкой на строки и слова в readResults.- В узле
"documentResults"содержатся специфичные для счета значения и позиции, обнаруженные моделью. Здесь можно найти все поля из счета, например идентификатора счета, отправки, выставления счетов, клиента, общего объема, элементов строки и многое другое.
Руководство по миграции
- Следуйте руководству по миграции с помощью аналитики документов версии 3.1, чтобы узнать, как использовать версию версии 3.0 в приложениях и рабочих процессах.
::: moniker-end
Следующие шаги
Попробуйте обработать собственные формы и документы с помощью Document Intelligence Studio.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.
Попробуйте обработать собственные формы и документы с помощью средства проверки меток для аналитики документов.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.