Добавочная загрузка данных из управляемого экземпляра SQL Azure в хранилище Azure с использованием технологии "Отслеживание измененных данных" (CDC)
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Из этого руководства вы узнаете, как создать фабрику данных Azure с конвейером, который копирует разностные данные на основе сведений об отслеживании измененных данных (CDC) в базе данных SQL Azure управляемого экземпляра в хранилище BLOB-объектов Azure.
В этом руководстве вы выполните следующие шаги:
- подготовите исходное хранилище данных;
- Создали фабрику данных.
- Создали связанные службы.
- Создали наборы данных приемника и источника.
- Создание, отладка и запуск конвейера для проверки измененных данных
- Изменение данных в таблице-источнике
- Создание, запуску и мониторинг конвейера добавочного копирования
Обзор
Для определения измененных данных используется технология "Отслеживание измененных данных", поддерживаемая такими хранилищами данных, как Управляемый экземпляр (MI) SQL Azure и SQL Server. В этом руководстве описано, как использовать службу "Фабрика данных Azure" с технологией "Отслеживание измененных данных" (SQL) для добавочной загрузки разностных данных из Управляемого экземпляра SQL Azure в хранилище BLOB-объектов Azure. Дополнительные сведения о технологии "Отслеживание измененных данных" (SQL) см. в статье Об отслеживании измененных данных (SQL Server).
Комплексный рабочий процесс
Ниже описан стандартный рабочий процесс по добавочной загрузке данных с помощью технологии "Отслеживание измененных данных".
Примечание.
И Управляемый экземпляр SQL Azure, и SQL Server поддерживают технологию "Отслеживание измененных данных". В этом руководстве в качестве исходного хранилища данных используется управляемый экземпляр SQL Azure. Вы также можете использовать локальную среду SQL Server.
Общее решение
В этом руководстве описано, как создать конвейер, который выполняет следующую операцию:
- Создайте действие уточнения, чтобы подсчитать количество измененных записей в таблице CDC базы данных SQL и передать их в действие условия ЕСЛИ.
- Создайте условие ЕСЛИ, чтобы проверить наличие измененных записей и, если это так, вызвать действие копирования.
- Создайте действие копирования, чтобы скопировать вставленные/обновленные/удаленные данные между таблицей CDC и хранилищем BLOB-объектов Azure.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
- Управляемый экземпляр SQL Azure Используйте базу данных как исходное хранилище данных. Если у вас нет Управляемый экземпляр SQL Azure, ознакомьтесь со статьей "Создание База данных SQL Azure Управляемый экземпляр", чтобы создать ее.
- Учетная запись хранения Azure. В этом руководстве в качестве приемника будет использоваться хранилище BLOB-объектов. Если у вас нет учетной записи хранения Azure, ознакомьтесь с разделом Создание учетной записи хранения. Создание контейнера с именем raw.
Создание таблицы источника данных в Базе данных SQL Azure
Запустите SQL Server Management Studio и подключитесь к серверу управляемого экземпляра SQL Azure.
В обозревателе сервера щелкните правой кнопкой мыши базу данных и выберите Создать запрос.
Выполните указанную ниже команду SQL для базы данных управляемых экземпляров SQL Azure, чтобы создать таблицу с именем
customersв качестве хранилища источника данных.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Включите функцию Отслеживание измененных данных для базы данных и исходной таблицы (customers), выполнив следующий SQL-запрос:
Примечание.
- Замените <имя вашей исходной схемы> схемой управляемого экземпляра SQL Azure с таблицей Customers.
- Система отслеживания измененных данных не выполняет никаких действий в рамках транзакций, изменяющих отслеживаемую таблицу. Вместо этого операции вставки, обновления и удаления записываются в журнал транзакций. Данные, хранящиеся в таблицах изменений, будут неуправляемо расти, если периодически и систематически не усекать эти данные. Дополнительные сведения см. в разделе Включение отслеживания измененных данных для базы данных
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Вставьте данные в таблицу Customers, выполнив следующую команду:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Примечание.
Перед включением системы отслеживания измененных данных никакие исторические изменения в таблице не фиксируются.
Создание фабрики данных
Выполните действия, описанные в кратком руководстве по созданию фабрики данных с помощью портал Azure для создания фабрики данных, если у вас еще нет этой фабрики данных.
Создание связанных служб
Связанная служба в фабрике данных связывает хранилища данных и службы вычислений с фабрикой данных. В этом разделе вы создадите связанные службы для учетной записи хранения Azure и управляемого экземпляра SQL Azure.
Создание связанной службы хранилища Azure
На этом шаге вы свяжете учетную запись хранения Azure с фабрикой данных.
Нажмите кнопку Подключения, а затем + Создать.
В окне New Linked Service (Новая связанная служба) выберите хранилище BLOB-объектов Azure и щелкните Continue (Продолжить).
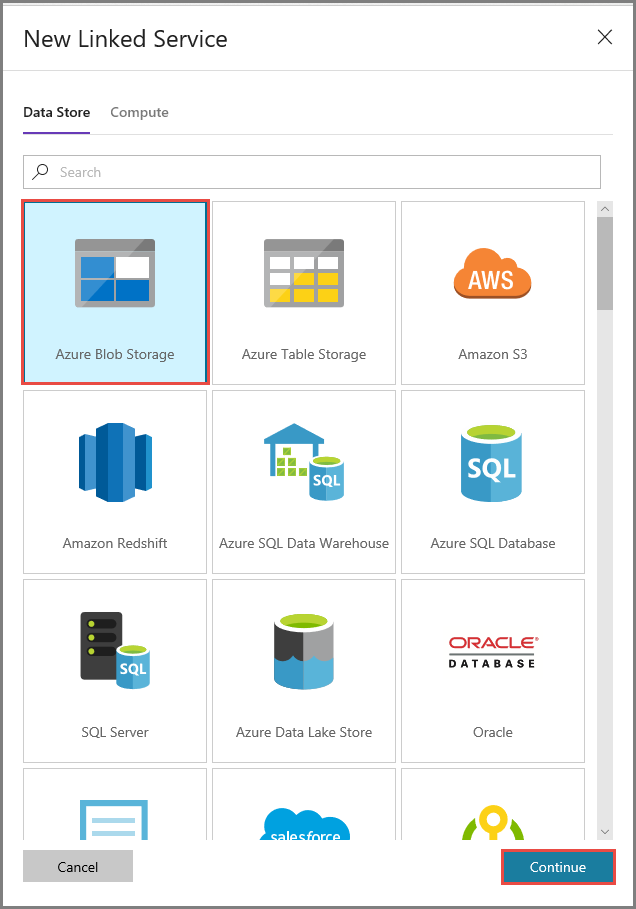
В окне New Linked Service (Новая связанная служба) выполните следующие действия:
- Введите AzureStorageLinkedService в поле имени.
- Выберите учетную запись хранения в списке Storage account name (Имя учетной записи хранения).
- Нажмите кнопку Сохранить.
Создание связанной службы базы данных управляемого экземпляра SQL Azure.
На этом шаге вы свяжете базу данных управляемого экземпляра SQL Azure с фабрикой данных.
Примечание.
Для тех, кто использует SQL MI, см. здесь сведения о доступе через публичную и частную конечную точку. При использовании частной конечной точки необходимо запустить этот конвейер с помощью локальной среды выполнения интеграции. Это же относится к тем, у кого запущен SQL Server локально, в сценариях виртуальной машины или виртуальной сети.
Нажмите кнопку Подключения, а затем + Создать.
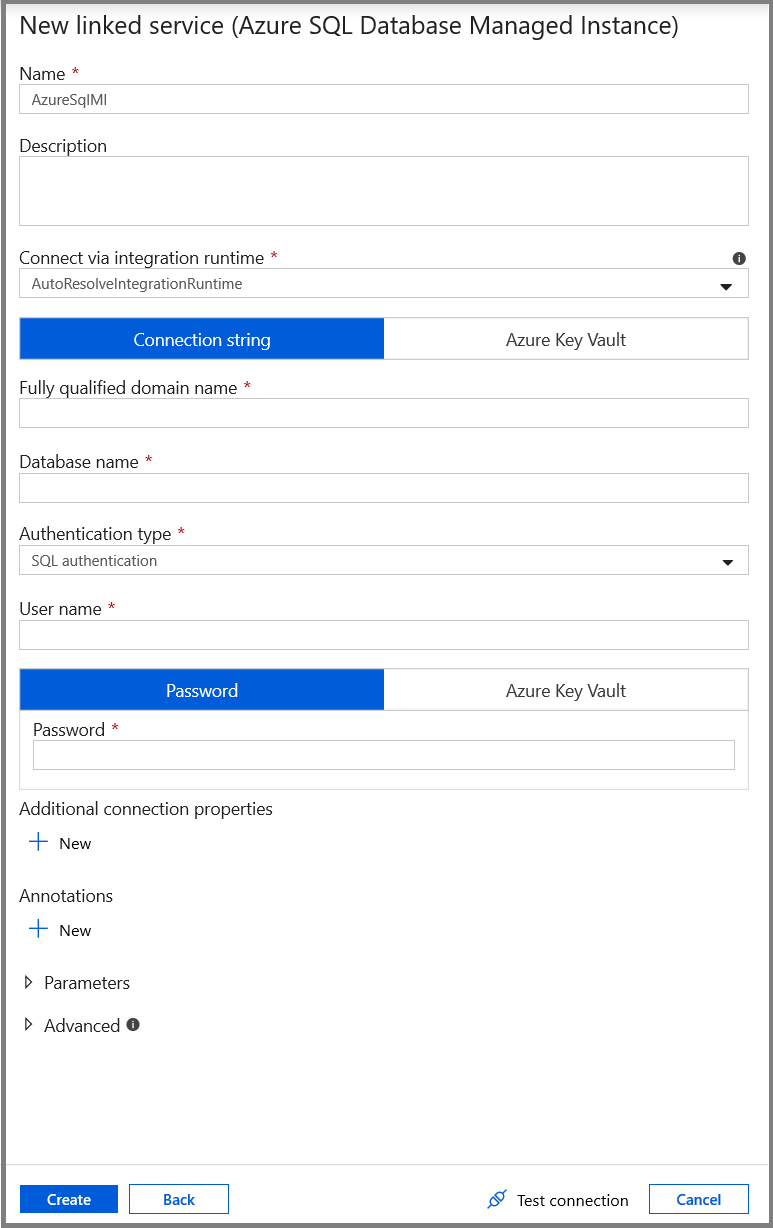
В окне New Linked Service (Новая связанная служба) выберите Azure SQL Database Managed Instance (Управляемый экземпляр базы данных SQL Microsoft Azure) и щелкните Continue (Продолжить).
В окне New Linked Service (Новая связанная служба) выполните следующие действия:
- Введите AzureSqlMI1 в поле Имя.
- Выберите нужный SQL-сервер в поле Имя сервера.
- Выберите базу данных SQL в поле Имя базы данных.
- Введите имя пользователя в поле User name (Имя пользователя).
- Введите пароль для этого пользователя в поле Password (Пароль).
- Нажмите кнопку Test connection (Проверить подключение), чтобы проверить подключение.
- Нажмите кнопку Save (Сохранить), чтобы сохранить связанную службу.
Создайте наборы данных.
На этом шаге вы создадите наборы данных, которые представляют данные источника и приемника.
Создание набора данных для представления исходных данных
На этом шаге вы создадите набор данных для представления исходных данных.
В представлении в виде дерева щелкните значок + (плюс) и выберите вариант Набор данных.
Выберите Azure SQL Database Managed Instance (Управляемый экземпляр базы данных SQL Microsoft Azure) и щелкните Continue (Продолжить).
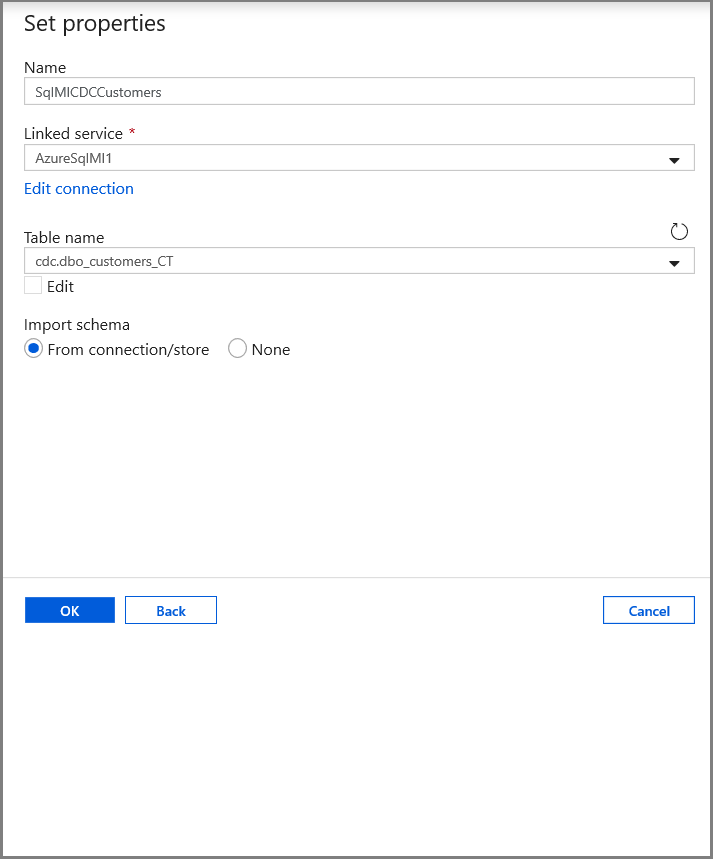
На вкладке Свойства набора задайте имя набора данных и сведения о соединении:
- Выберите AzureSqlMI1 для связанной службы.
- Выберите [dbo]. [dbo_customers_CT] в качестве имени таблицы. Примечание. Эта таблица была автоматически создана при включении CDC в таблице Customers. Измененные данные никогда не запрашиваются из этой таблицы напрямую, а извлекаются с помощью функций CDC.
Создайте набор данных, который будет представлять данные для копирования в целевое хранилище данных.
На этом шаге вы создадите набор данных для представления данных, которые копируются из исходного хранилища данных. Для работы с этим руководством нужен контейнер data lake, созданный в хранилище BLOB-объектов Azure. Создайте контейнер (если его еще нет) или присвойте ему имя имеющегося контейнера. В этом руководстве имя файла выходных данных создается динамически с помощью времени триггера, который будет настроен позже.
В представлении в виде дерева щелкните значок + (плюс) и выберите вариант Набор данных.
Выберите Хранилище BLOB-объектов Azure и щелкните Продолжить.

Выберите DelimitedText в качестве формата и щелкните Продолжить.

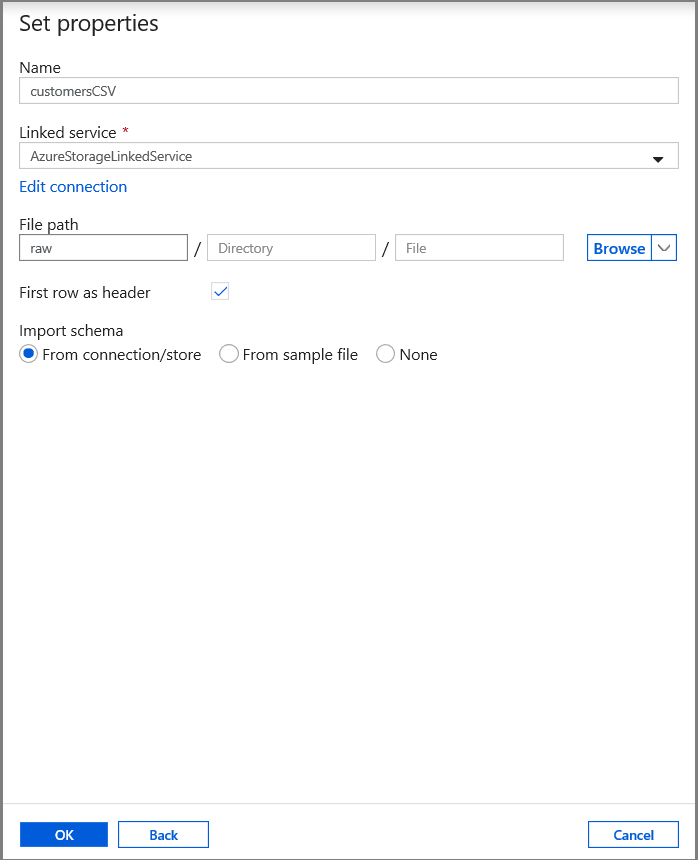
На вкладке Свойства набора задайте имя набора данных и сведения о соединении:
- Выберите AzureStorageLinkedService в списке Связанная служба.
- Введите raw для части контейнера filePath.
- Включите Использовать первую строку в качестве заголовка
- Нажмите кнопку ОК.
Создание конвейера для копирования измененных данных
На этом шаге вы создадите конвейер, который сначала проверяет число измененных записей, имеющихся в таблице изменений, с помощью действия уточнения. Условие ЕСЛИ проверяет, что число измененных записей больше нуля, и запускает действие копирования, чтобы скопировать вставленные/обновленные/удаленные данные из базы данных SQL Azure в хранилище BLOB-объектов Azure. Наконец, триггер смены окна настроен на время начала и окончания, которые будут переданы действиям в качестве параметров начального и конечного окон.
В пользовательском интерфейсе фабрики данных перейдите на вкладку "Изменить ". Щелкните +(плюс) в левой области и нажмите кнопку "Конвейер".
Вы увидите новую вкладку для настройки конвейера. Также этот конвейер появится в отображении дерева. В окне Свойства укажите имя IncrementalCopyPipeline для нового конвейера.
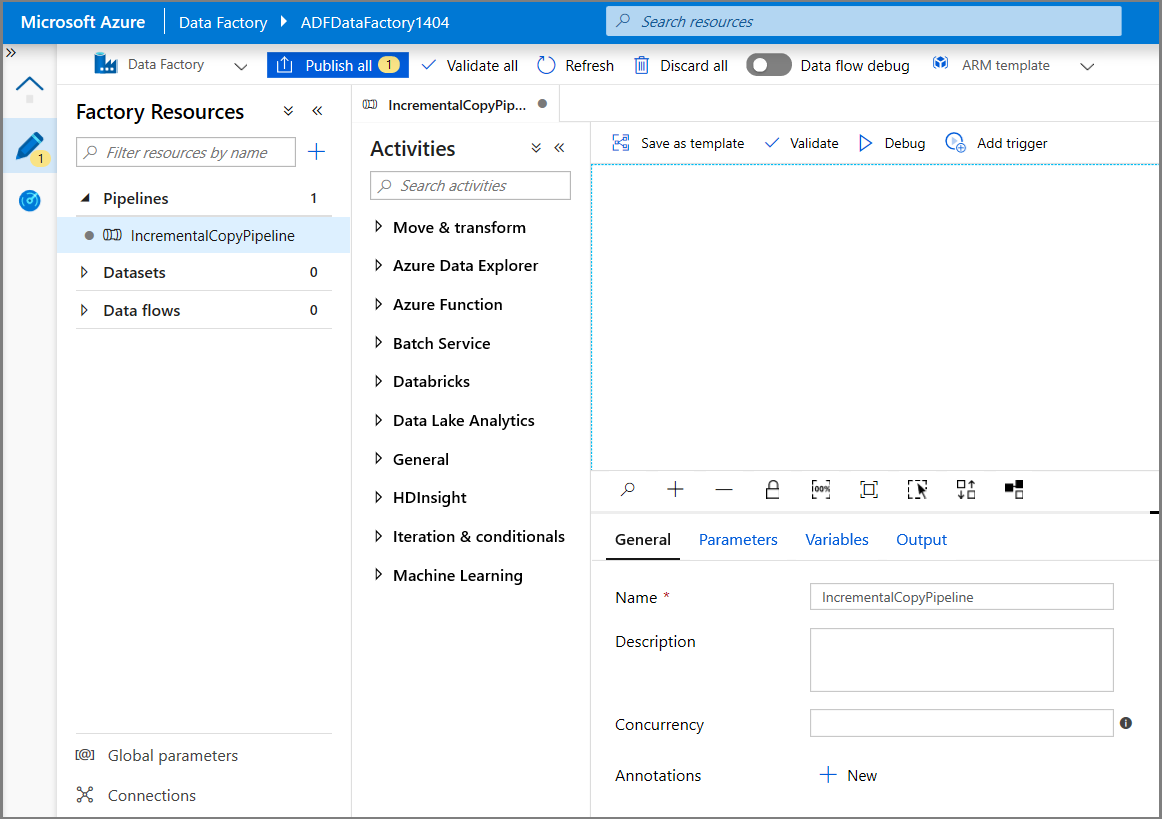
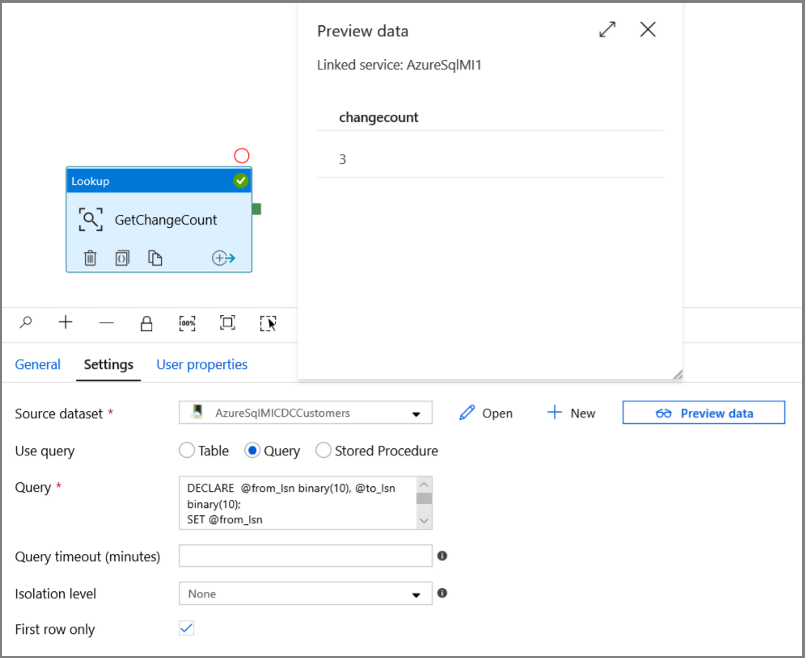
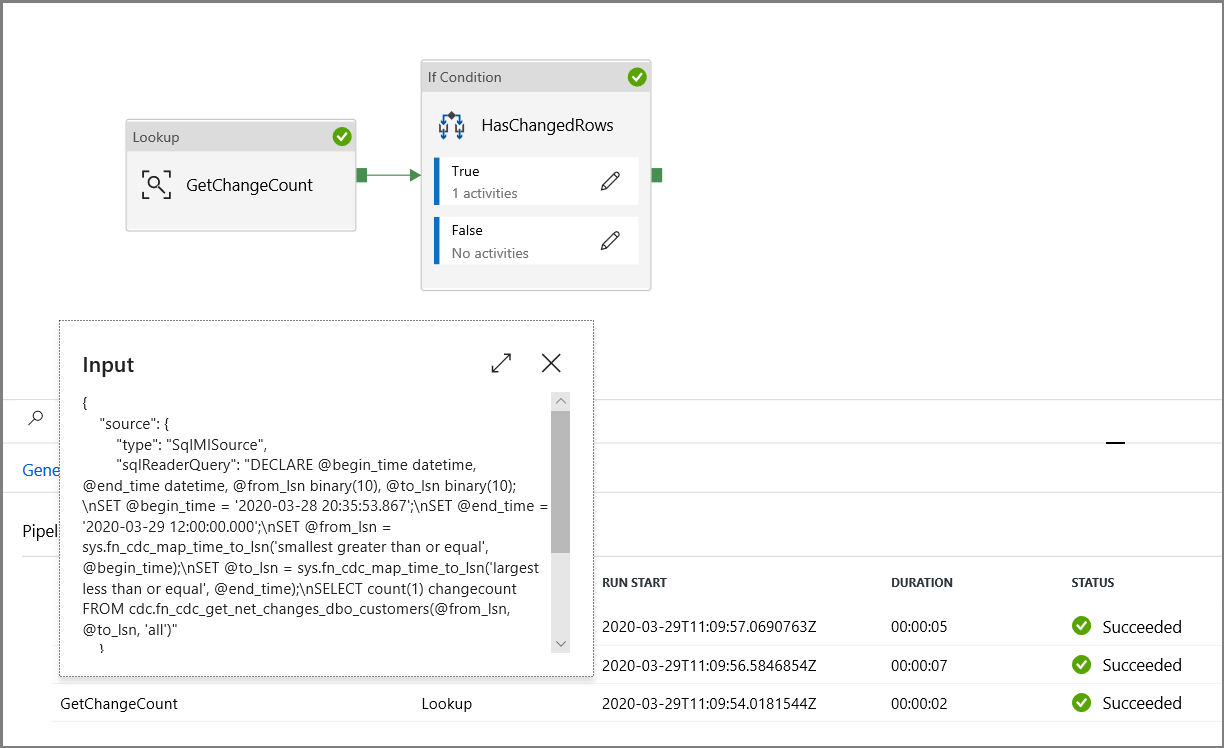
Разверните элемент Общие на панели Действия и перетащите действие Поиск в область конструктора конвейера. Для имени действия задайте значение GetChangeCount. Это действие получает количество записей в таблице изменений для заданного временного окна.
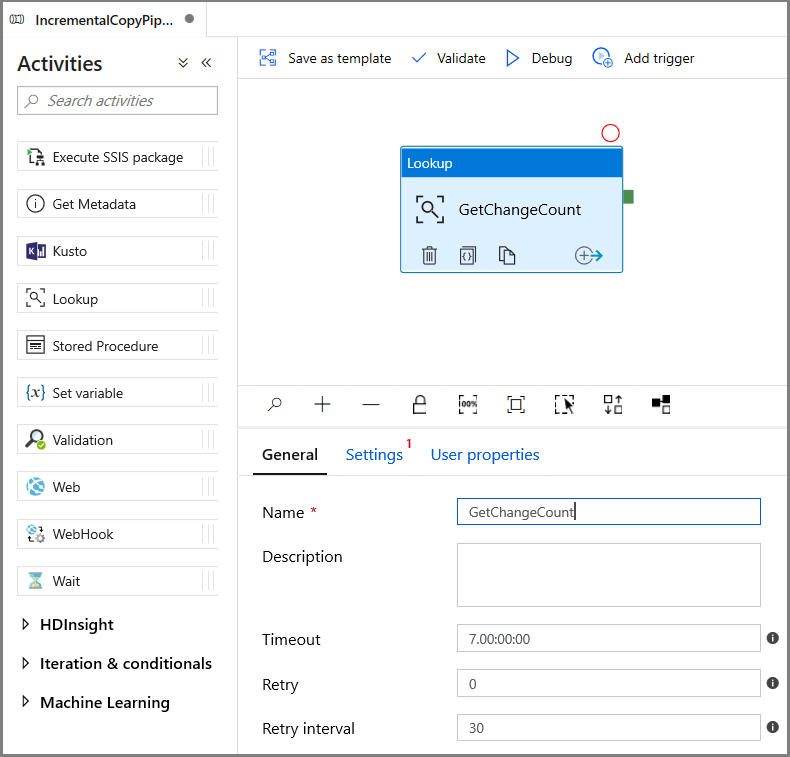
Перейдите на вкладку Настройки в окне Свойства:
Укажите имя набора данных SQL MI для поля Исходный набор данных .
Выберите параметр запроса и введите в поле запроса следующее:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Включите Только первая строка
Нажмите кнопку Предварительный просмотр данных, чтобы обеспечить получение достоверных выходных данных действием поиска
На панели Действия разверните элемент Итерация и условия, а затем перетащите действие If Condition в область конструктора конвейера. Для имени действия задайте значение HasChangedRows.
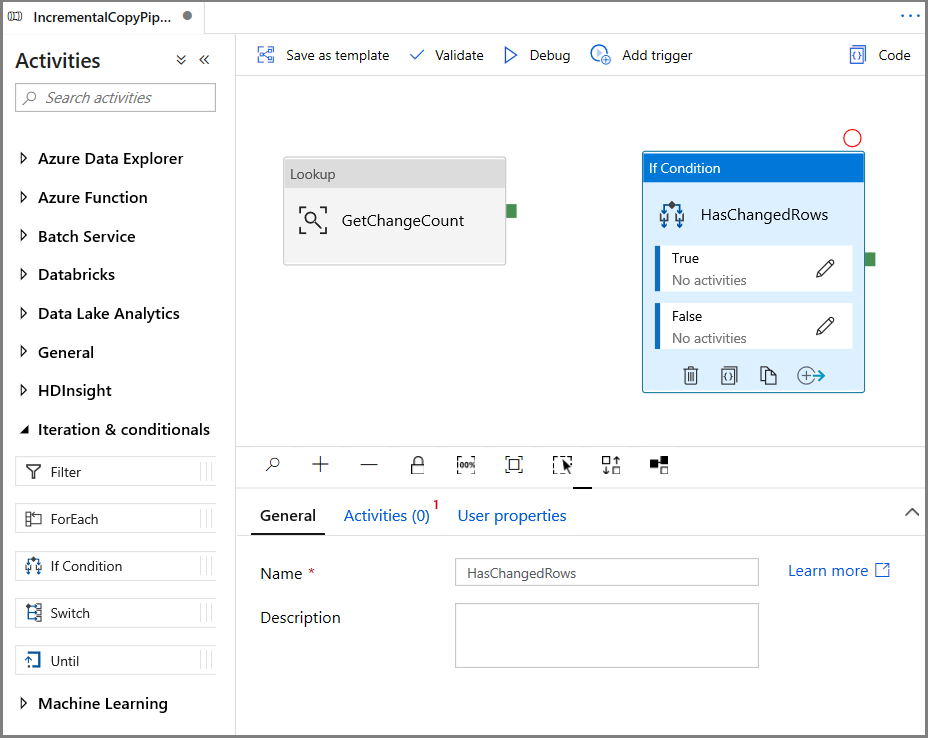
Перейдите на вкладку Действия в окне Свойства:
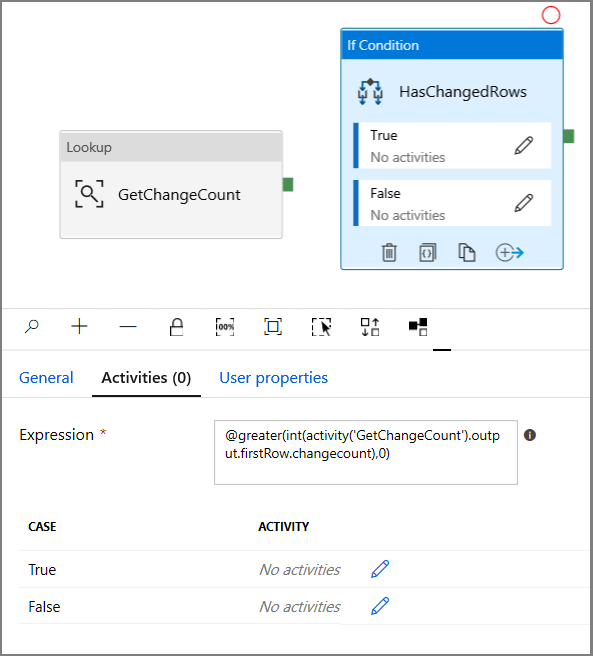
- Введите следующее Выражение
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Щелкните значок с изображением карандаша, чтобы изменить истинное условие.
- Разверните Общие в панели элементов Действия и перетащите действие Ждать в область конструктора конвейера. Это временное действие для отладки условия If; оно будет изменено далее в этом руководстве.
- Щелкните элемент в пути IncrementalCopyPipeline, чтобы вернуться к основному конвейеру.
Запустите конвейер в режиме Отладка, чтобы убедиться, что конвейер успешно выполнен.
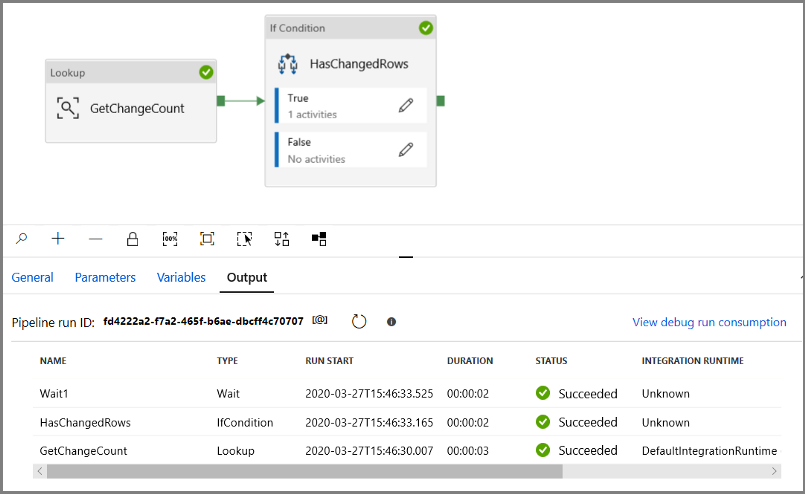
Затем вернитесь к верному шагу условия и удалите действие Ждать. На панели элементов Действия разверните узел Переместить и преобразовать и перетащите действие Копирование в область конструктора конвейера. Присвойте этому действию имя IncrementalCopyActivity.
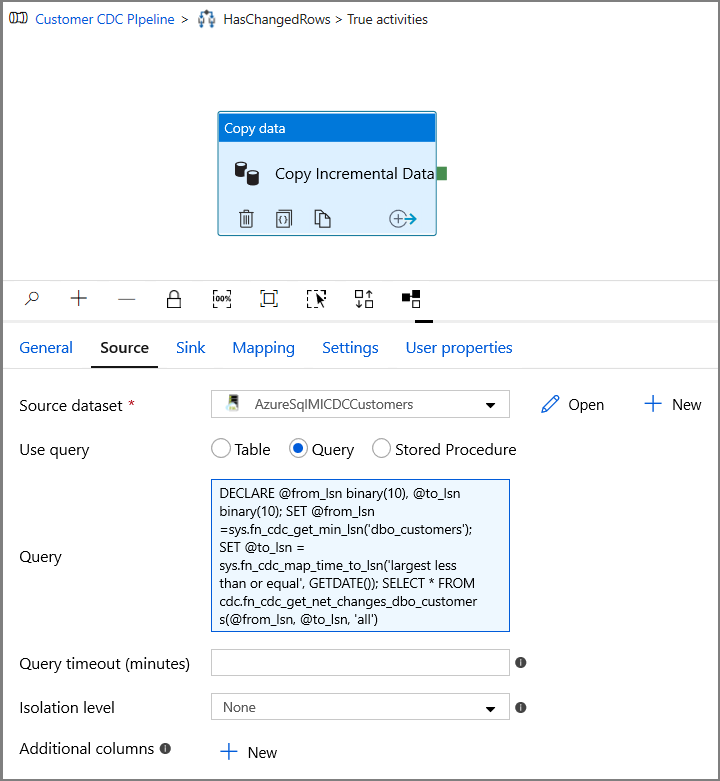
Откройте вкладку Источник в окне Свойства и выполните здесь следующие действия.
Укажите имя набора данных SQL MI для поля Исходный набор данных .
Выберите Запрос в списке Use Query (Пользовательский запрос).
Введите следующий Запрос.
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
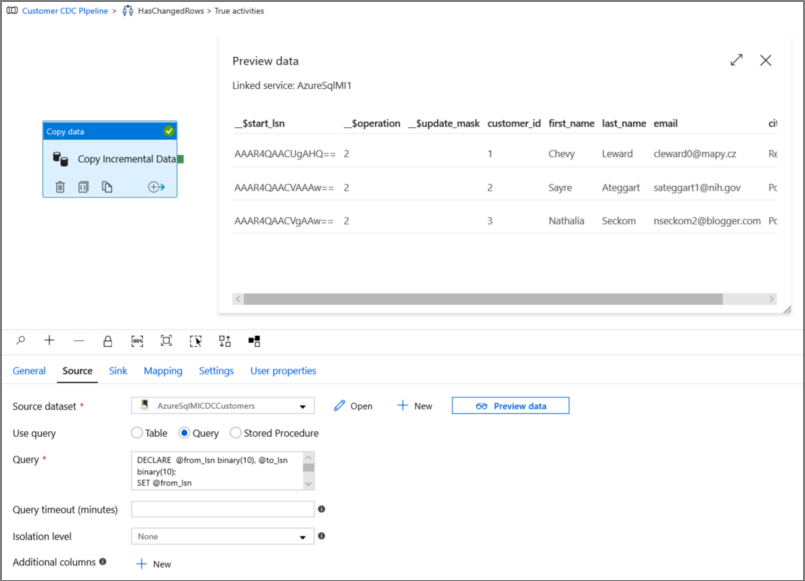
Нажмите кнопку предварительного просмотра, чтобы убедиться, что запрос правильно возвращает измененные строки.
Перейдите на вкладку Приемник и укажите набор данных Хранилища Azure в поле Sink Dataset (Целевой набор данных).

Нажмите кнопку назад на главном холсте конвейера и подключите действие Поиск к действию If Condition по одному. Перетащите зеленую кнопку, присоединенную к действию Поиск, на блок действия If Condition.
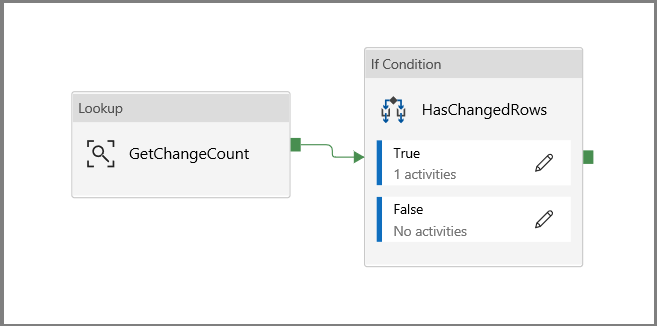
Нажмите кнопку Проверить на панели инструментов. Убедитесь, что проверка завершается без ошибок. Закройте окно отчета о проверке конвейера, щелкнув >>.
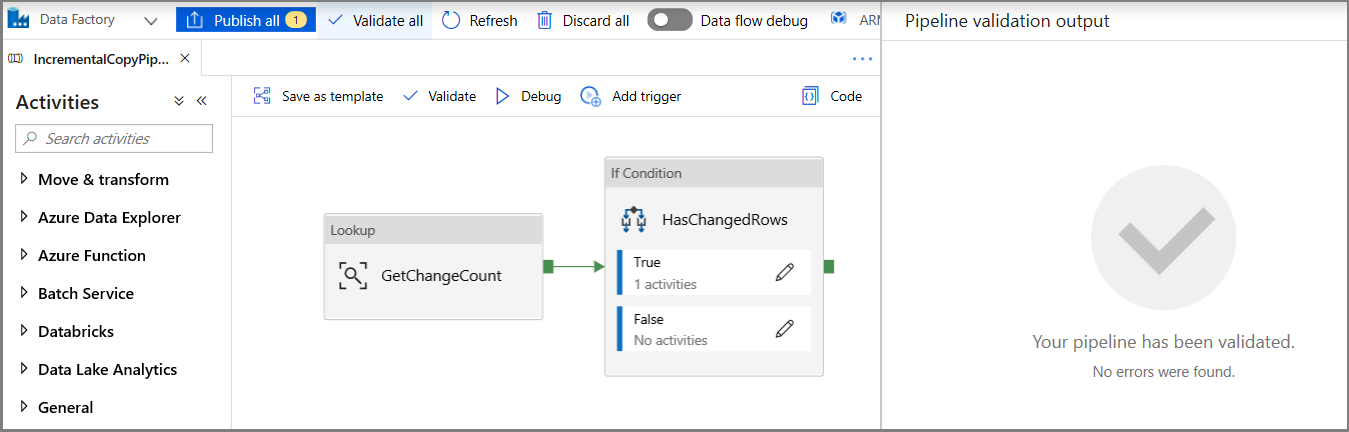
Щелкните кнопку "Отладка", чтобы проверить конвейер и убедиться, что файл создается в месте хранения.
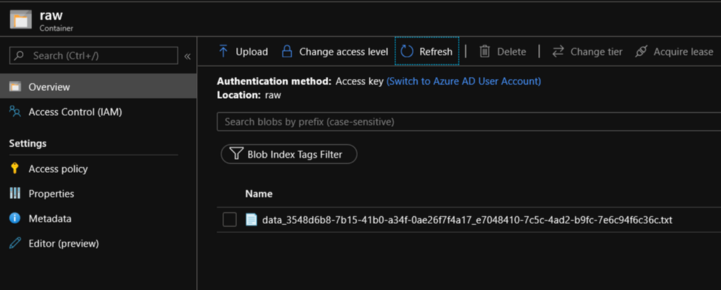
Опубликуйте сущности (связанные службы, наборы данных и конвейеры) в службе "Фабрика данных", нажав кнопку Опубликовать все. Дождитесь сообщения Публикация успешно выполнена.
Настройка триггера переворачивающегося окна и параметра окна CDC
На этом шаге вы создадите триггер переворачивающегося окна для запуска задания по частому расписанию. Вы будете использовать системные переменные WindowStart и WindowEnd для триггера переворачивающегося окна и передавать их в качестве параметров конвейера для использования в запросе CDC.
Перейдите на вкладку Параметры в конвейере IncrementalCopyPipeline и с помощью кнопки + Новый добавьте два параметра (triggerStartTime и triggerEndTime) в конвейер, который будет представлять время начала и окончания переворачивающегося окна. В целях отладки добавьте значения по умолчанию в формате ГГГГ-ММ-ДД ЧЧ24:ММ:СС.ДОЛИСЕКУНД, но убедитесь, что triggerStartTime не включен в таблицу CDC, в противном случае это приведет к ошибке.
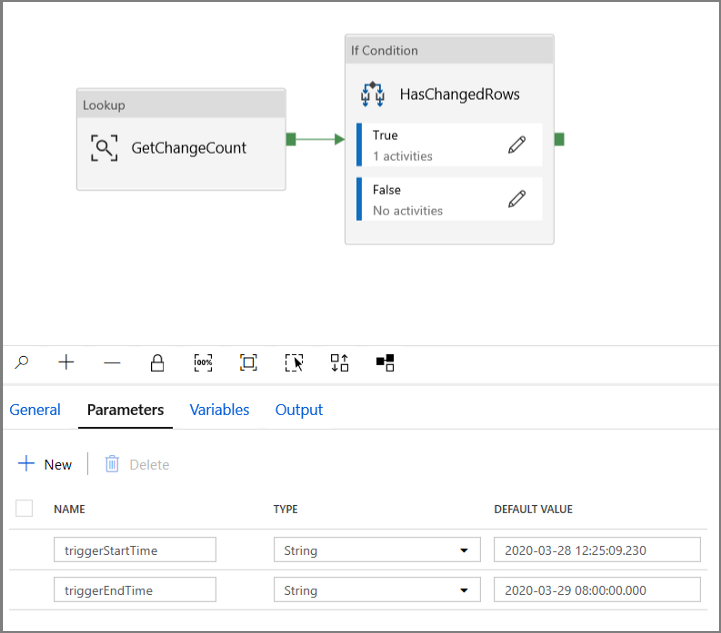
Перейдите на вкладку "Параметры действия" Поиск и настройте запрос на использование параметров начала и окончания. Скопируйте следующий код в редактор запросов:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Перейдите к действию копирования в случае действия "True" действия "Если условие " и перейдите на вкладку "Источник ". Скопируйте следующее в запрос:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Перейдите на вкладку Приемник действия Копирование и щелкните кнопку Открыть, чтобы изменить свойства набора данных. Перейдите на вкладку Параметры и добавьте новый параметр с именем triggerStart
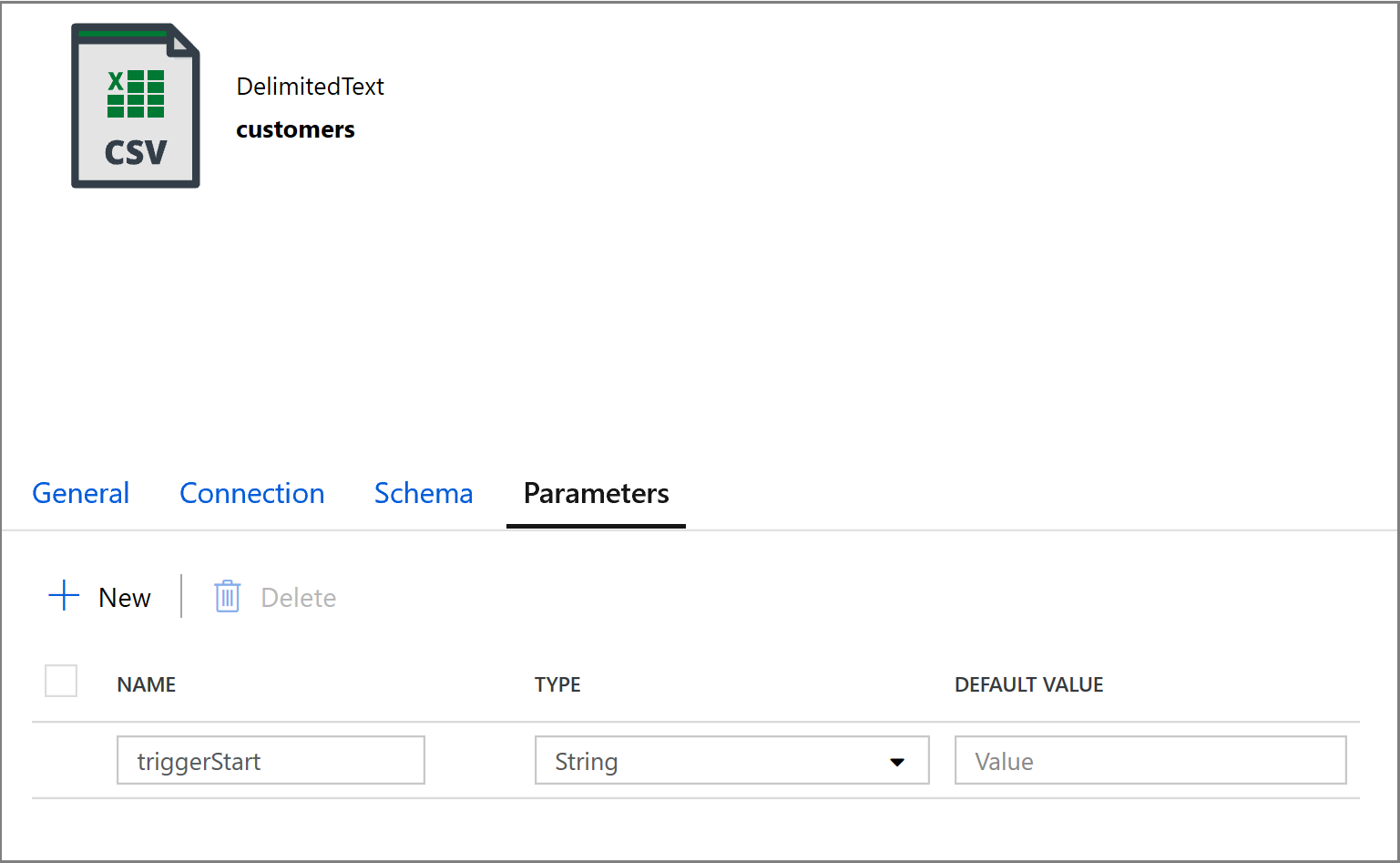
Затем настройте свойства набора данных для хранения данных в подкаталоге клиенты/добавочный с разделением по данным.
Перейдите на вкладку Подключение в свойствах набора данных и добавьте динамическое содержимое для разделов Каталог и Файл.
Введите следующее выражение в разделе Каталог, щелкнув на динамическое содержимое в текстовом поле:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Введите следующее выражение в разделе Файл. Это создаст имена файлов на основе даты и времени начала триггера с расширением CSV:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')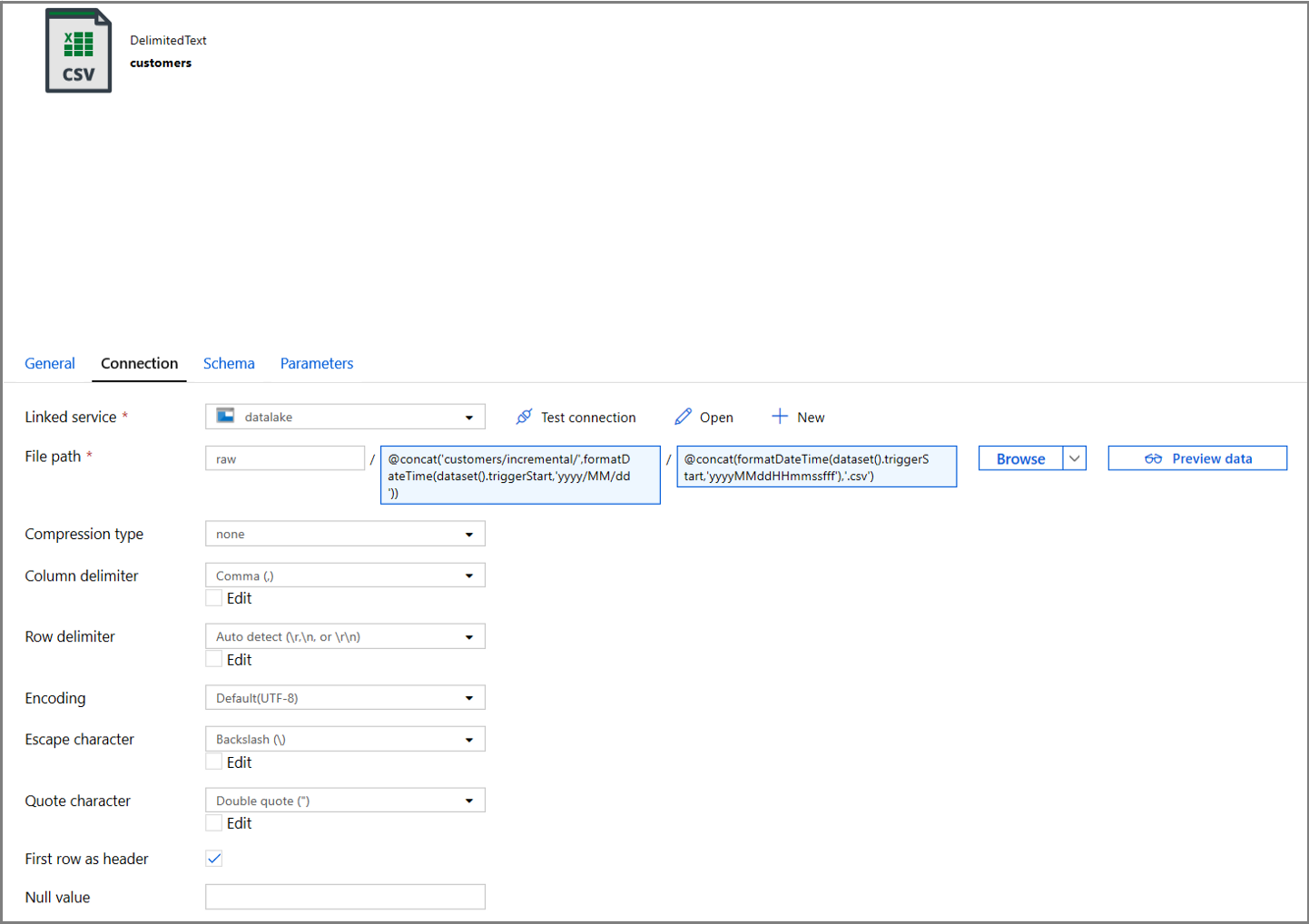
Вернитесь к параметрам Приемника в действии Копирование, щелкнув вкладку IncrementalCopyPipeline.
Разверните свойства набора данных и введите динамическое содержимое в значение параметра triggerStart с помощью следующего выражения:
@pipeline().parameters.triggerStartTime
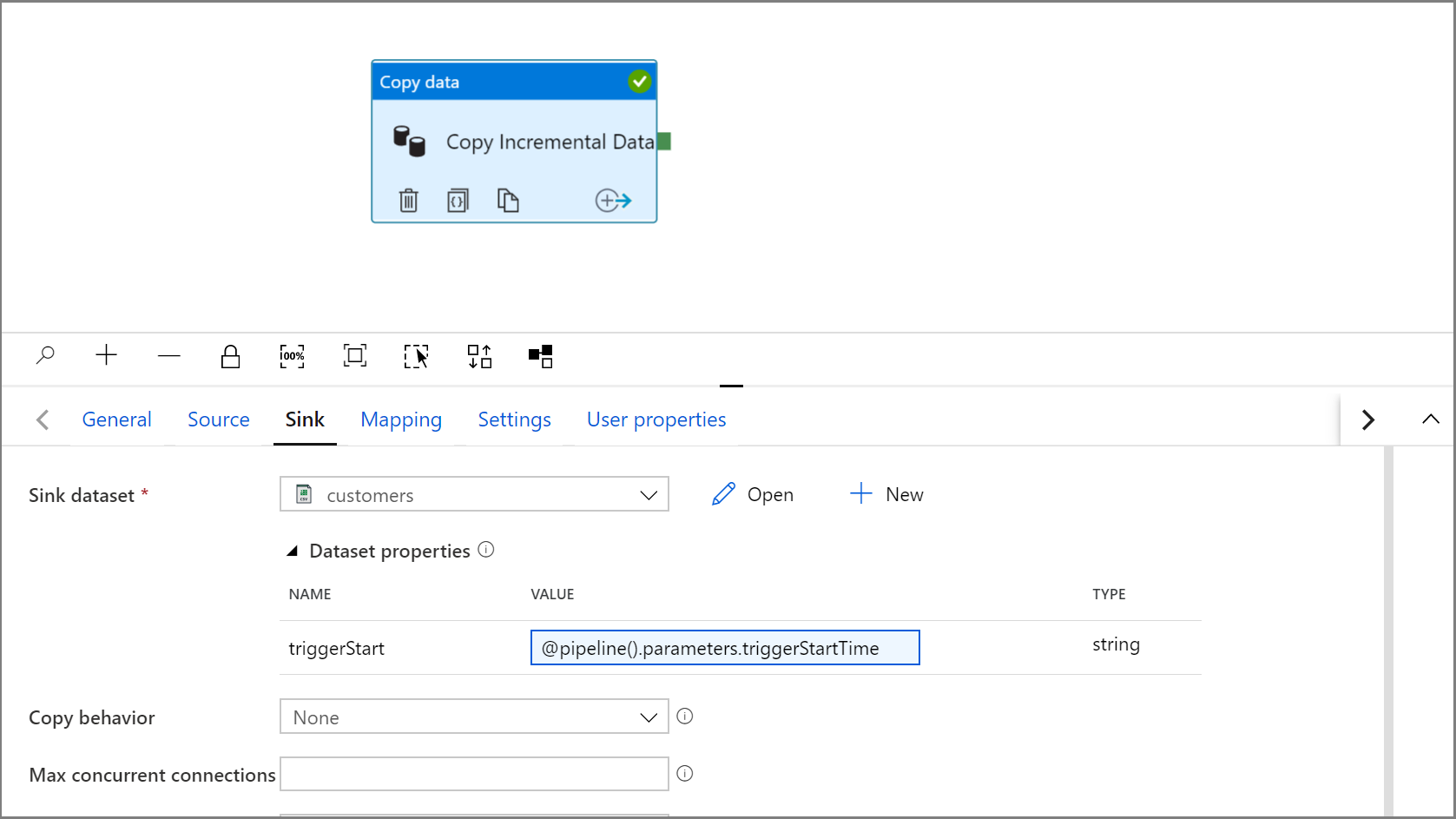
Щелкните кнопку "Отладка", чтобы проверить конвейер и убедиться, что структура папок и выходной файл созданы должным образом. Скачайте и откройте файл, чтобы проверить его содержимое.
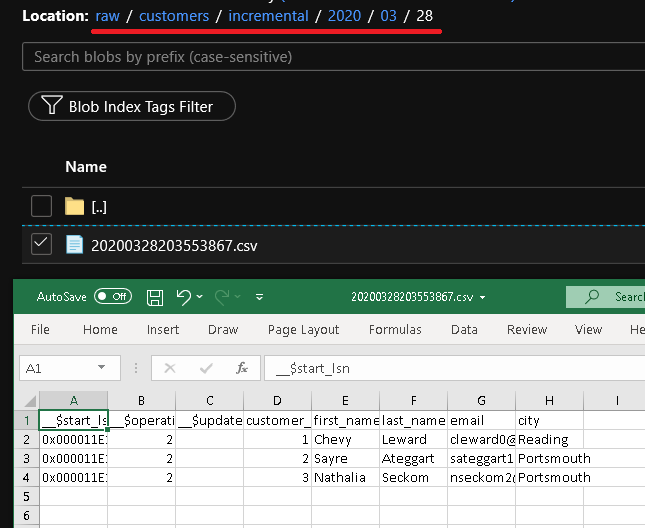
Убедитесь, что параметры добавлены в запрос, просмотрев входные параметры выполнения конвейера.
Опубликуйте сущности (связанные службы, наборы данных и конвейеры) в службе "Фабрика данных", нажав кнопку Опубликовать все. Дождитесь сообщения Публикация успешно выполнена.
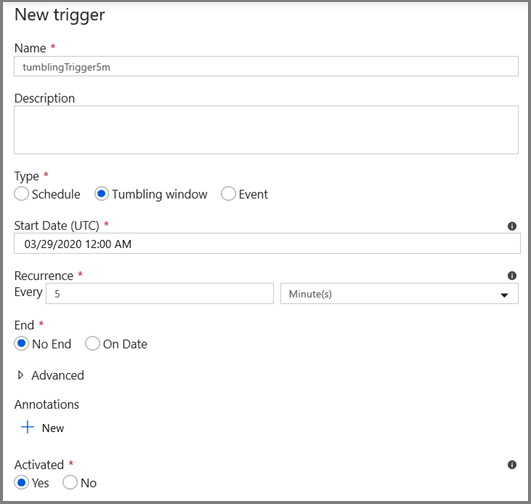
Наконец, настройте триггер переворачивающегося окна для запуска конвейера через обычный интервал и задайте параметры времени начала и окончания.
- Нажмите кнопку Добавить триггер и выберите Создать/изменить
- Введите имя триггера и укажите время начала, равное времени окончания окна отладки выше.
На следующем экране укажите следующие значения параметров начала и окончания соответственно.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')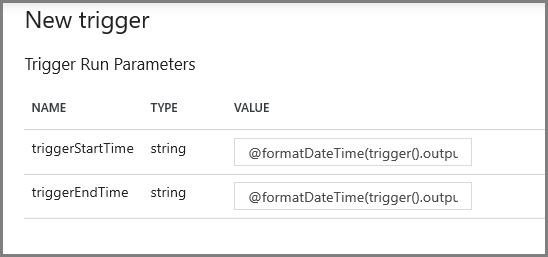
Примечание.
Триггер будет выполняться только после его публикации. Кроме того, ожидаемым поведением переворачивающегося окна является выполнение всех интервалов с даты начала до настоящего момента. Дополнительные сведения о триггерах переворачивающегося окна можно найти здесь.
С помощью SQL Server Management Studio внесите некоторые дополнительные изменения в таблицу Customer, выполнив следующий SQL:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Нажмите кнопку Опубликовать все. Дождитесь сообщения Публикация успешно выполнена.
Через несколько минут сработает триггер конвейера, а новый файл будет загружен в службу хранилища Azure
Мониторинг конвейера добавочного копирования
Щелкните вкладку Мониторинг слева. В открывшемся списке вы увидите запуск конвейера и его текущее состояние. Щелкните Refresh (Обновить), чтобы обновить этот список. Наведите курсор мыши на имя конвейера, чтобы получить доступ к действию и отчету о потреблении.
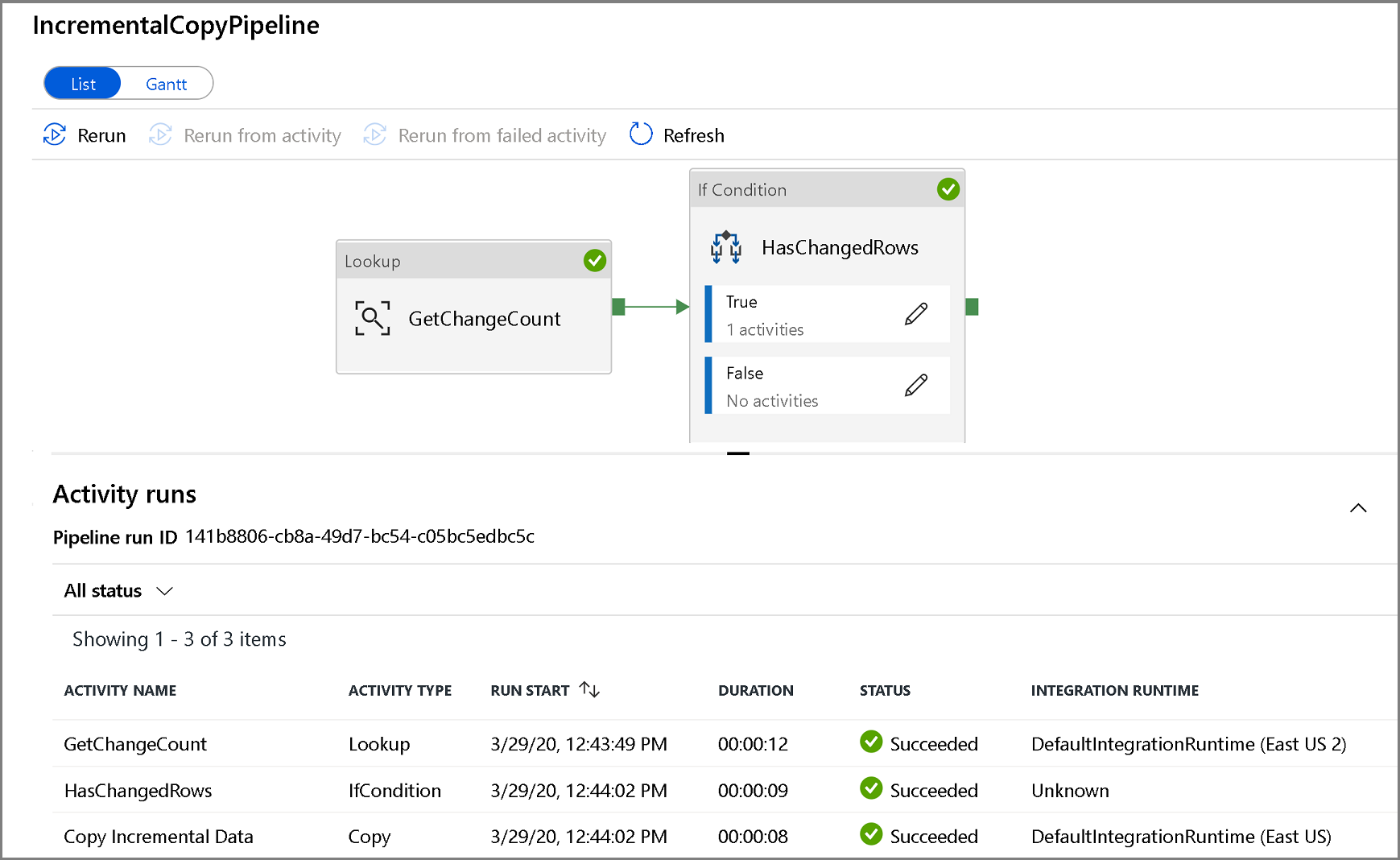
Чтобы просмотреть запуски действий, связанные с этим запуском конвейера, щелкните имя Конвейера. Если обнаружены измененные данные, в списке будут три действия, включая действие копирования, в противном случае в списке останутся только две записи. Чтобы вернуться к просмотру запусков конвейера, щелкните ссылку Все конвейеры в верхней части окна.
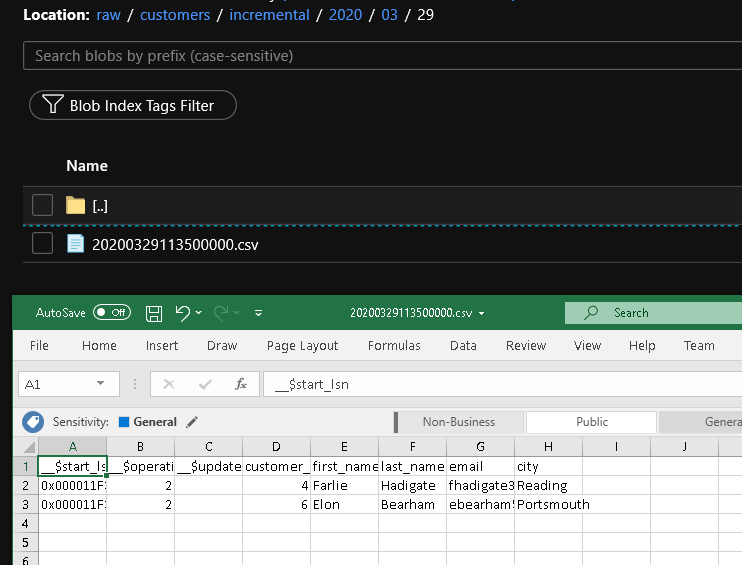
Проверьте результаты.
Вы увидите второй файл в папке customers/incremental/YYYY/MM/DD контейнера raw.
Связанный контент
В этом руководстве рассказывается о копировании новых и измененных файлов на основе параметра LastModifiedDate:
Copy new files by lastmodifieddate (Копирование новых файлов с использованием параметра LastModifiedDate)