Добавочное копирование данных из База данных SQL Azure в хранилище BLOB-объектов с помощью отслеживания изменений в портал Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В решениях для интеграции данных после начальной загрузки данных широко используется добавочная загрузка. Измененные данные в течение периода в исходном хранилище данных можно легко срезать (например, LastModifyTime). CreationTime Но в некоторых случаях нет явного способа определить разностные данные с момента последнего обработки данных. Для идентификации разностных данных можно использовать технологию отслеживания изменений, поддерживаемую хранилищами данных, такими как База данных SQL Azure и SQL Server.
В этом руководстве описывается, как использовать Фабрика данных Azure с отслеживанием изменений для добавочной загрузки разностных данных из База данных SQL Azure в Хранилище BLOB-объектов Azure. Дополнительные сведения об отслеживании изменений см. в разделе "Отслеживание изменений" в SQL Server.
В этом руководстве вы выполните следующие шаги:
- Подготовьте исходное хранилище данных.
- Создали фабрику данных.
- Создали связанные службы.
- создадите источник, приемник и наборы данных отслеживания изменений;
- Создание, запуск и мониторинг полного конвейера копирования.
- Добавьте или обновите данные в исходной таблице.
- Создание, запуск и мониторинг конвейера добавочного копирования.
Общее решение
В этом руководстве вы создадите два конвейера, которые выполняют следующие операции.
Примечание.
В этом руководстве в качестве исходного хранилища данных используется база данных Azure SQL. Вы также можете использовать SQL Server.
Начальная загрузка исторических данных: создается конвейер с действием копирования, копирующий все данные из исходного хранилища данных (База данных SQL Azure) в целевое хранилище данных (Хранилище BLOB-объектов Azure):
- Включите технологию отслеживания изменений в исходной базе данных в База данных SQL Azure.
- Получите начальное значение
SYS_CHANGE_VERSIONбазы данных в качестве базовой базы данных для записи измененных данных. - Загрузите полные данные из исходной базы данных в Хранилище BLOB-объектов Azure.

Добавочная загрузка разностных данных по расписанию: вы создаете конвейер со следующими действиями и периодически выполняете его:
Создайте два действия подстановки, чтобы получить старые и новые
SYS_CHANGE_VERSIONзначения из База данных SQL Azure.Создайте одно действие копирования для копирования вставленных, обновленных или удаленных данных (разностных данных) между двумя
SYS_CHANGE_VERSIONзначениями из База данных SQL Azure в Хранилище BLOB-объектов Azure.Вы загружаете разностные данные, присоединяя первичные ключи измененных строк (между двумя
SYS_CHANGE_VERSIONзначениями) изsys.change_tracking_tablesданных в исходной таблице, а затем перемещаете разностные данные в место назначения.Создайте одно действие хранимой процедуры, чтобы обновить значение следующего
SYS_CHANGE_VERSIONзапуска конвейера.

Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начать работу.
- База данных SQL Azure. База данных используется в База данных SQL Azure в качестве исходного хранилища данных. Если у вас нет базы данных, см. статью "Создание базы данных" в База данных SQL Azure действий по его созданию.
- Учетная запись хранения Azure. Хранилище BLOB-объектов используется в качестве хранилища данных приемника. Если у вас нет учетной записи хранения Azure, ознакомьтесь с инструкциями по созданию учетной записи хранения. Создайте контейнер с именем adftutorial.
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
Создание таблицы источника данных в Базе данных SQL Azure
Откройте SQL Server Management Studio и подключитесь к База данных SQL.
В обозревателе серверов щелкните правой кнопкой мыши базу данных и выберите команду "Создать запрос".
Выполните следующую команду SQL для базы данных, чтобы создать таблицу с именем
data_source_tableисходного хранилища данных:create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Включите отслеживание изменений в базе данных и исходной таблице (
data_source_table), выполнив следующий SQL-запрос.Примечание.
- Замените
<your database name>именем базы данных в База данных SQL Azure.data_source_table - Измененные данные в текущем примере хранятся в течение двух дней. Если загружать измененные данные каждые три дня или реже, некоторые измененные данные не будут включены. Необходимо либо изменить значение
CHANGE_RETENTIONбольшего числа, либо убедиться, что период загрузки измененных данных находится в течение двух дней. Дополнительные сведения см. в разделе "Включение отслеживания изменений" для базы данных.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Замените
Создайте таблицу и хранилище, вызываемое
ChangeTracking_versionсо значением по умолчанию, выполнив следующий запрос:create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Примечание.
Если данные не изменяются после включения отслеживания изменений для База данных SQL, значение версии отслеживания изменений равно
0.Выполните следующий запрос, чтобы создать хранимую процедуру в базе данных. Конвейер вызывает эту хранимую процедуру, чтобы обновить версию отслеживания изменений в таблице, созданной на предыдущем шаге.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Создание фабрики данных
Откройте веб-браузер Microsoft Edge или Google Chrome. В настоящее время только эти браузеры поддерживают пользовательский интерфейс фабрики данных.
В портал Azure в меню слева выберите команду "Создать ресурс".
Выберите фабрику данных интеграции>.
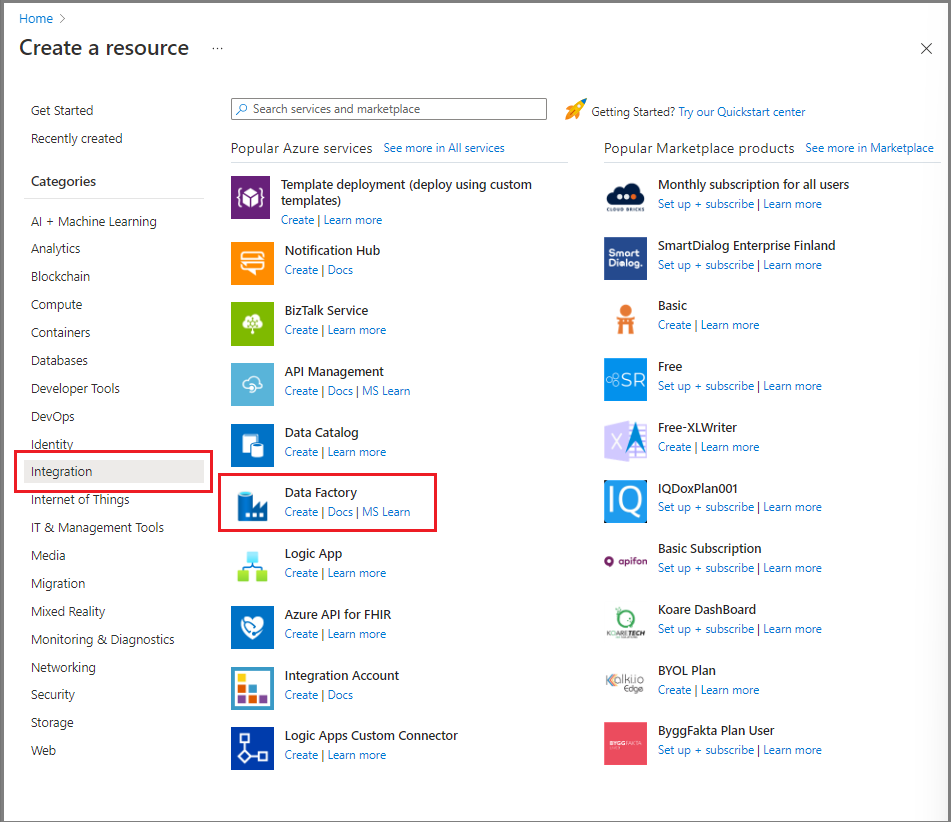
На странице "Новая фабрика данных" введите ADFTutorialDataFactory для имени.
Имя фабрики данных должно быть глобально уникальным. Если вы получите сообщение об ошибке, в котором указано, что выбранное имя недоступно, измените имя (например, на имяADFTutorialDataFactory) и повторите попытку создания фабрики данных. Дополнительные сведения см. в Фабрика данных Azure правила именования.
Выберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий:
- Выберите "Использовать существующий" и выберите существующую группу ресурсов из раскрывающегося списка.
- Выберите "Создать" и введите имя группы ресурсов.
Сведения о группах ресурсов см. в статье, где описывается использование групп ресурсов для управления ресурсами Azure.
Укажите V2 при выборе версии.
Для региона выберите регион для фабрики данных.
В раскрывающемся списке отображаются только поддерживаемые расположения. Хранилища данных (например, служба хранилища Azure и База данных SQL Azure) и вычислительные ресурсы (например, Azure HDInsight), которые фабрика данных может использовать в других регионах.
Выберите Далее: конфигурация Git. Настройте репозиторий, следуя инструкциям в методе конфигурации 4. Во время создания фабрики или установите флажок "Настроить Git позже ".
Выберите Review + create (Просмотреть и создать).
Нажмите кнопку создания.
На панели мониторинга на плитке "Развертывание фабрики данных" отображается состояние.

После завершения создания откроется страница фабрики данных. Щелкните плитку Launch Studio, чтобы открыть пользовательский интерфейс Фабрика данных Azure на отдельной вкладке.
Создание связанных служб
Связанная служба в фабрике данных связывает хранилища данных и службы вычислений с фабрикой данных. В этом разделе описано, как создать связанные службы для учетной записи хранения Azure и базы данных в База данных SQL Azure.
Создание связанной службы хранилища Azure
Чтобы связать учетную запись хранения с фабрикой данных, выполните следующие действия.
- В пользовательском интерфейсе фабрики данных на вкладке "Управление " в разделе "Подключения" выберите связанные службы. Затем нажмите кнопку "Создать " или "Создать связанную службу ".
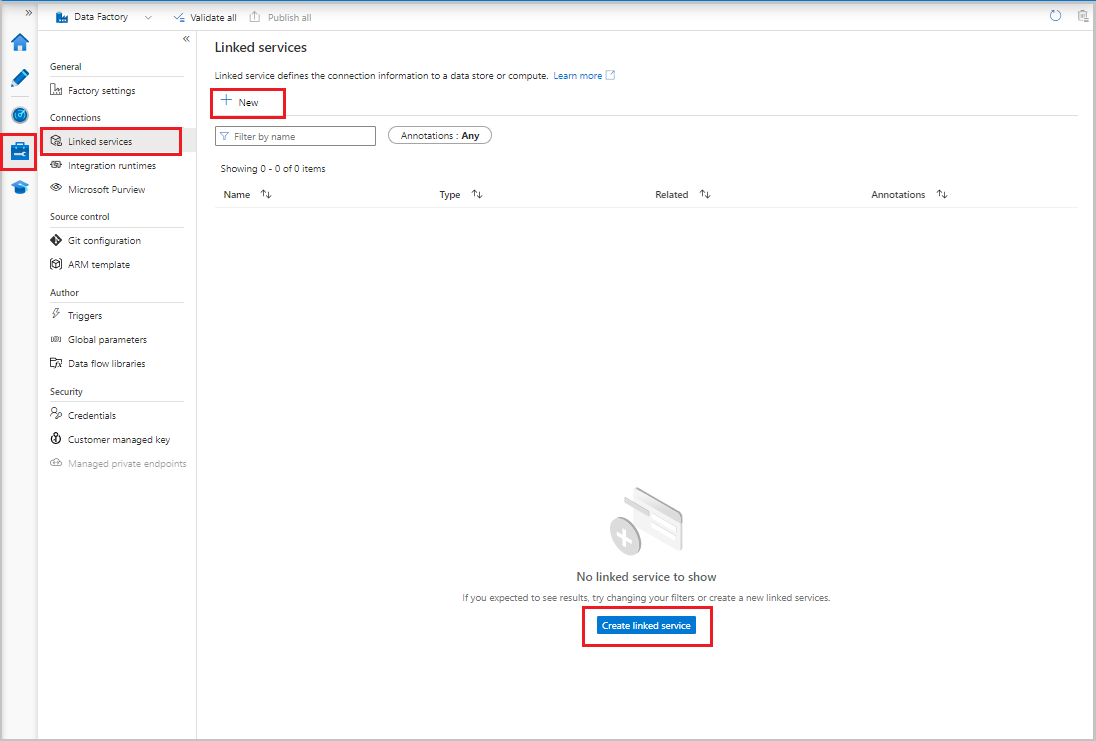
- В окне "Новая связанная служба" выберите Хранилище BLOB-объектов Azure и нажмите кнопку "Продолжить".
- Введите следующие сведения:
- Введите AzureStorageLinkedService в поле имени.
- Для подключения через среду выполнения интеграции выберите среду выполнения интеграции.
- Для типа проверки подлинности выберите метод проверки подлинности.
- Для имени учетной записи хранения выберите учетную запись хранения Azure.
- Нажмите кнопку создания.
Создание связанной службы Базы данных SQL Azure
Чтобы связать базу данных с фабрикой данных, выполните следующие действия.
В пользовательском интерфейсе фабрики данных на вкладке "Управление " в разделе "Подключения" выберите связанные службы. Выберите пункт + Создать.
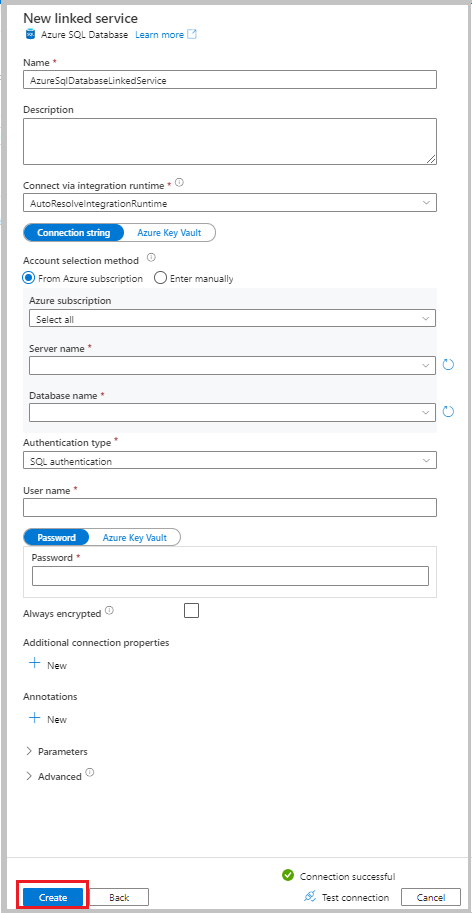
В окне "Новая связанная служба" выберите База данных SQL Azure и нажмите кнопку "Продолжить".
Введите следующие данные:
- В поле "Имя" введите AzureSqlDatabaseLinkedService.
- Для имени сервера выберите сервер.
- Для имени базы данных выберите базу данных.
- Для типа проверки подлинности выберите метод проверки подлинности. В этом руководстве используется проверка подлинности SQL для демонстрации.
- В поле "Имя пользователя" введите имя пользователя.
- В поле "Пароль" введите пароль для пользователя. Кроме того, укажите сведения для Azure Key Vault — связанная служба AKV, имя секрета и версия секрета.
Выберите Проверить подключение, чтобы проверить подключение.
Нажмите кнопку "Создать", чтобы создать связанную службу.
Создайте наборы данных.
В этом разделе вы создадите наборы данных для представления источника данных и назначения данных, а также места для хранения значений SYS_CHANGE_VERSION .
Создание набора данных для представления исходных данных
В пользовательском интерфейсе фабрики данных на вкладке "Автор " выберите знак плюса (+). Затем выберите набор данных или выберите многоточие для действий с набором данных.
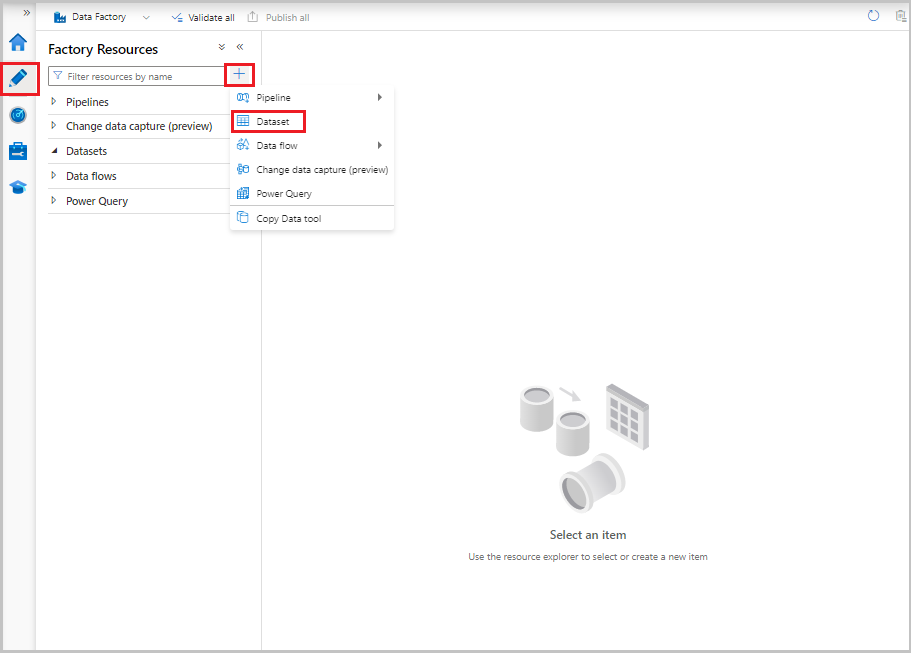
Выберите База данных SQL Azure и нажмите кнопку Продолжить.
В окне "Задать свойства" выполните следующие действия.
- В поле "Имя" введите SourceDataset.
- Для связанной службы выберите AzureSqlDatabaseLinkedService.
- Для имени таблицы выберите dbo.data_source_table.
- Для схемы импорта выберите параметр "Из подключения или хранилища".
- Нажмите ОК.

Создание набора данных для представления данных, скопированных в хранилище данных приемника
В следующей процедуре создается набор данных для представления данных, скопированных из исходного хранилища данных. Вы создали контейнер adftutorial в Хранилище BLOB-объектов Azure в рамках предварительных требований. Создайте контейнер (если его еще нет) или присвойте ему имя имеющегося контейнера. В этом руководстве имя выходного файла динамически создается из выражения @CONCAT('Incremental-', pipeline().RunId, '.txt').
В пользовательском интерфейсе фабрики данных на вкладке "Автор " выберите +. Затем выберите набор данных или выберите многоточие для действий с набором данных.
Выберите Хранилище BLOB-объектов Azure и нажмите кнопку "Продолжить".
Выберите формат типа данных в виде разделителя, а затем нажмите кнопку "Продолжить".
В окне "Задание свойств" выполните следующие действия.
- В поле "Имя" введите SinkDataset.
- Для связанной службы выберите AzureBlobStorageLinkedService.
- Для пути к файлу введите adftutorial/incchgtracking.
- Нажмите ОК.
После отображения набора данных в представлении дерева перейдите на вкладку "Подключение " и выберите текстовое поле "Имя файла". Когда появится параметр "Добавить динамическое содержимое", выберите его.
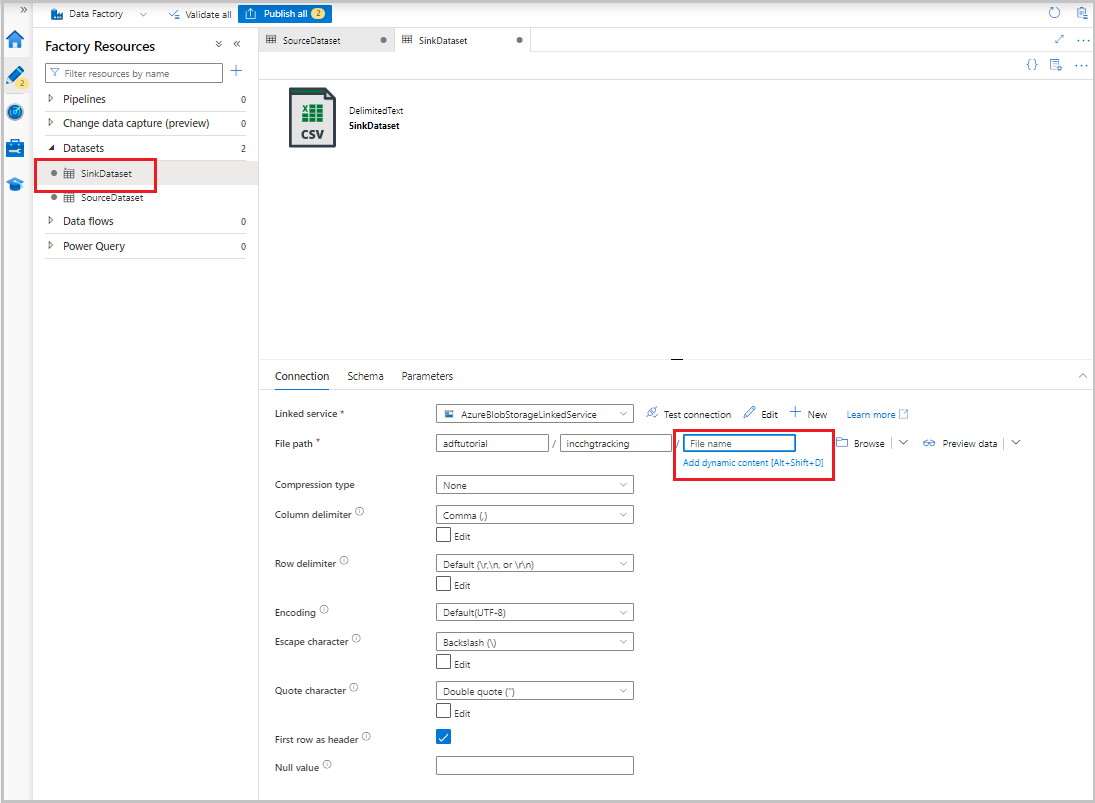
Откроется окно построителя выражений конвейера. Вставьте
@concat('Incremental-',pipeline().RunId,'.csv')в текстовое поле.Нажмите ОК.
Создание набора данных, который будет представлять данные отслеживания изменений
В следующей процедуре создается набор данных для хранения версии отслеживания изменений. Вы создали таблицу table_store_ChangeTracking_version в рамках предварительных требований.
- В пользовательском интерфейсе фабрики данных на вкладке "Автор " выберите +и выберите набор данных.
- Выберите База данных SQL Azure и нажмите кнопку Продолжить.
- В окне "Задать свойства" выполните следующие действия.
- В поле "Имя" введите ChangeTrackingDataset.
- Для связанной службы выберите AzureSqlDatabaseLinkedService.
- Для имени таблицы выберите dbo.table_store_ChangeTracking_version.
- Для схемы импорта выберите параметр "Из подключения или хранилища".
- Нажмите ОК.
Создание конвейера для полного копирования данных
В следующей процедуре создается конвейер с действием копирования, которое копирует все данные из исходного хранилища данных (База данных SQL Azure) в целевое хранилище данных (Хранилище BLOB-объектов Azure):
В пользовательском интерфейсе фабрики данных на вкладке "Автор" выберите +и выберите конвейер конвейера>.
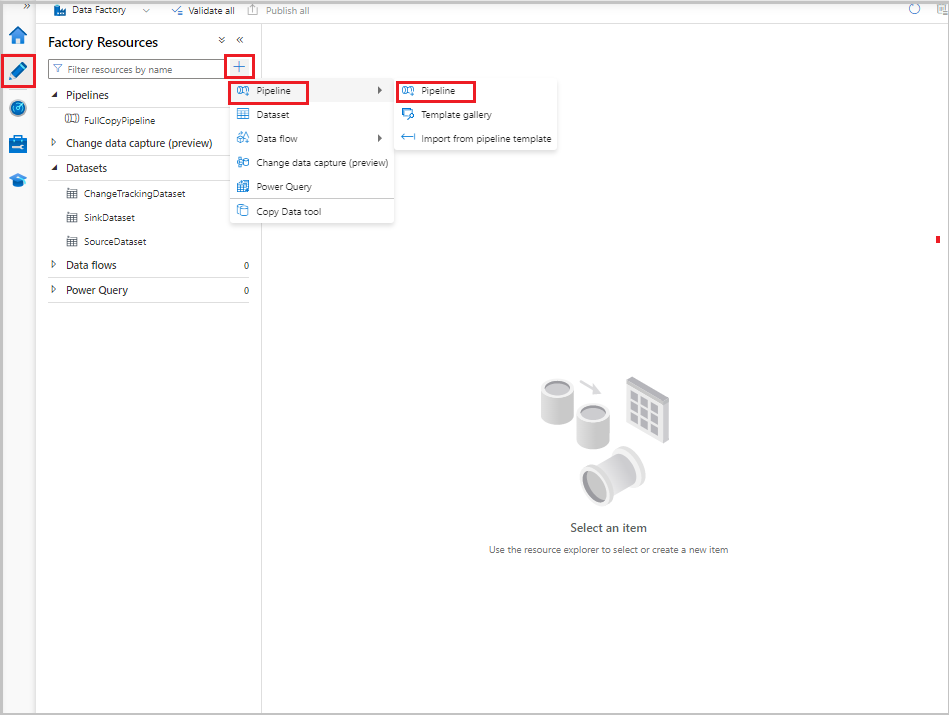
Откроется новая вкладка для настройки конвейера. Конвейер также отображается в представлении дерева. В окне Свойства укажите имя FullCopyPipeline для нового конвейера.
На панели элементов "Действия" разверните узел "Переместить и преобразовать". Выполните один из следующих шагов.
- Перетащите действие копирования в область конструктора конвейеров.
- На панели поиска в разделе "Действия" найдите действие копирования данных и задайте имя FullCopyActivity.
Перейдите на вкладку "Источник ". Для исходного набора данных выберите SourceDataset.
Перейдите на вкладку "Приемник ". Для набора данных приемника выберите SinkDataset.
Чтобы проверить определение конвейера, выберите " Проверить " на панели инструментов. Убедитесь, что проверка завершается без ошибок. Закройте выходные данные проверки конвейера.
Чтобы опубликовать сущности (связанные службы, наборы данных и конвейеры), выберите "Опубликовать все". Дождитесь сообщения Опубликовано.
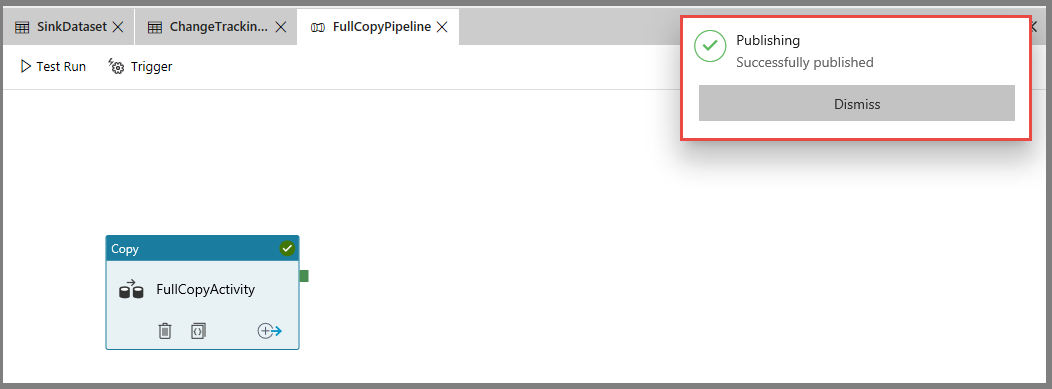
Чтобы просмотреть уведомления, нажмите кнопку "Показать уведомления ".
Запуск конвейера полного копирования
В пользовательском интерфейсе фабрики данных на панели инструментов для конвейера выберите "Добавить триггер", а затем нажмите кнопку "Активировать".
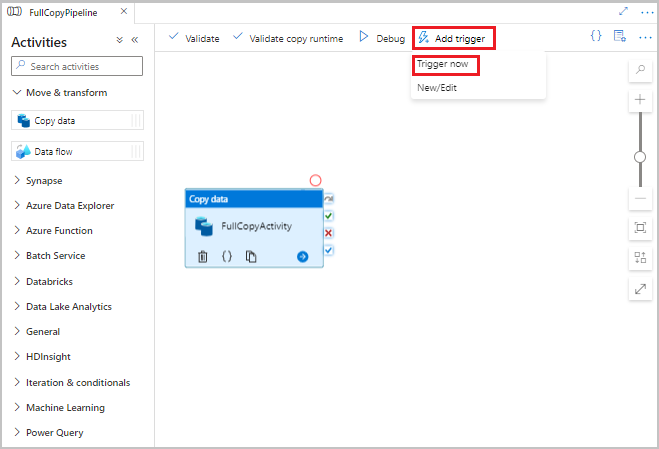
В окне запуска конвейера нажмите кнопку "ОК".

Мониторинг конвейера полного копирования
В пользовательском интерфейсе фабрики данных выберите вкладку "Монитор ". Запуск конвейера и его состояние отображаются в списке. Чтобы обновить список, нажмите кнопку "Обновить". Наведите указатель мыши на выполнение конвейера, чтобы получить параметр повторного запуска или потребления .
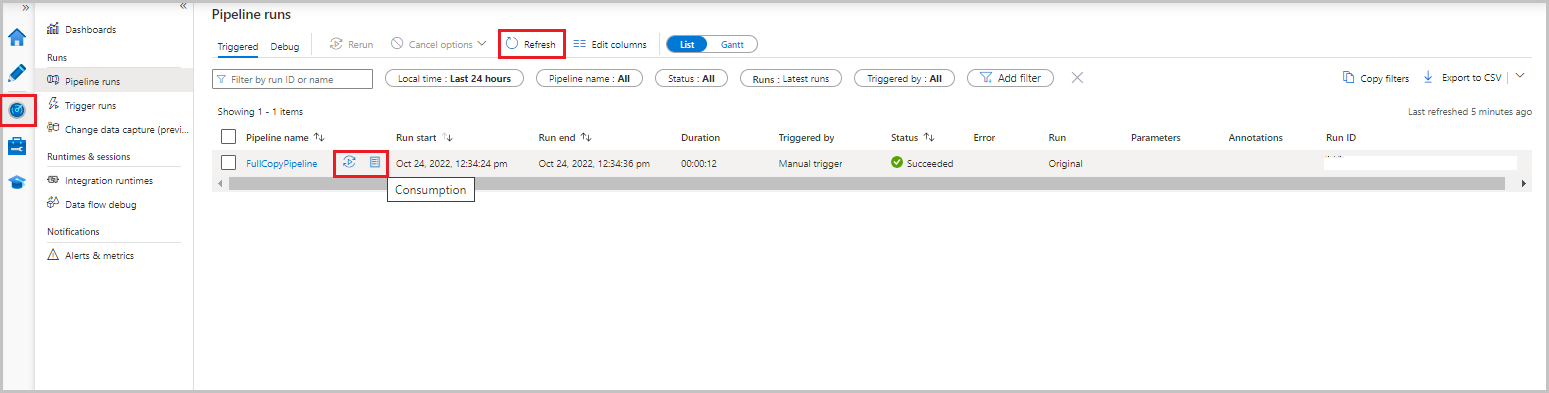
Чтобы просмотреть действия, связанные с выполнением конвейера, выберите имя конвейера из столбца имени конвейера. В конвейере есть только одно действие, поэтому в списке есть только одна запись. Чтобы вернуться к представлению запусков конвейера, выберите ссылку "Все запуски конвейера" в верхней части.
Проверьте результаты.
Папка incchgtracking контейнера adftutorial включает файл с именемincremental-<GUID>.csv.
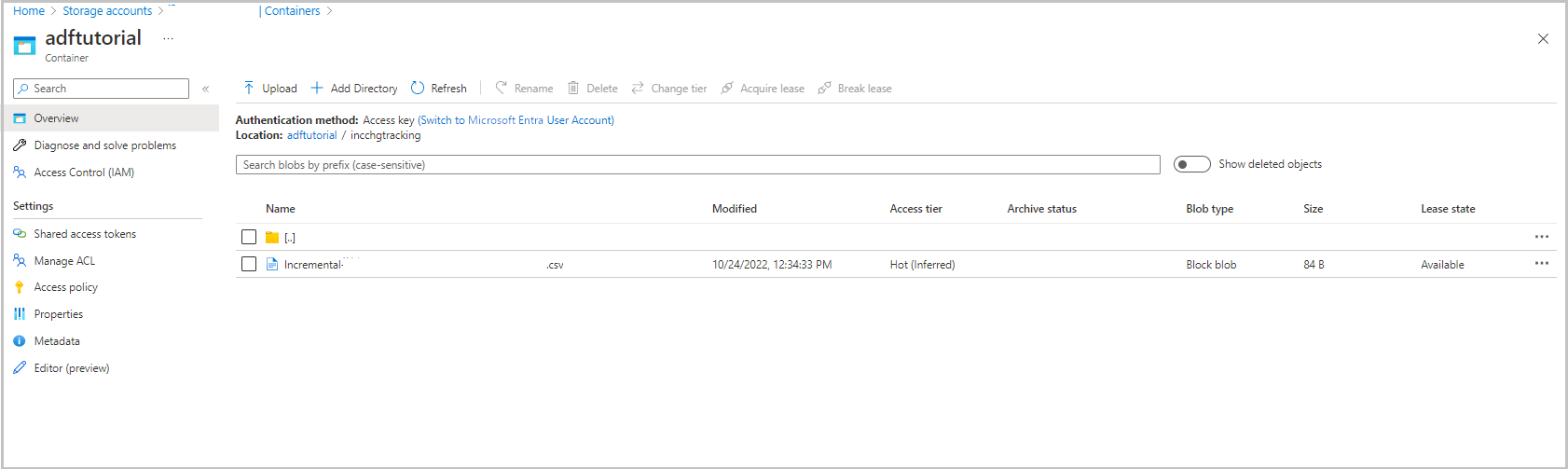
Файл должен включать данные из базы данных:
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Добавление данных в исходную таблицу
Выполните следующий запрос к базе данных, чтобы добавить строку и обновить строку:
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Создание конвейера для копирования разностных данных
В следующей процедуре вы создаете конвейер с действиями и периодически выполняете его. При запуске конвейера:
- Действия подстановки получают старые и новые
SYS_CHANGE_VERSIONзначения из База данных SQL Azure и передают их в действие копирования. - Действие копирования копирует вставленные, обновленные или удаленные данные между двумя
SYS_CHANGE_VERSIONзначениями из База данных SQL Azure в Хранилище BLOB-объектов Azure. - Действие хранимой процедуры обновляет значение следующего
SYS_CHANGE_VERSIONзапуска конвейера.
В пользовательском интерфейсе фабрики данных перейдите на вкладку "Автор". Выберите +и выберите конвейер конвейера>.
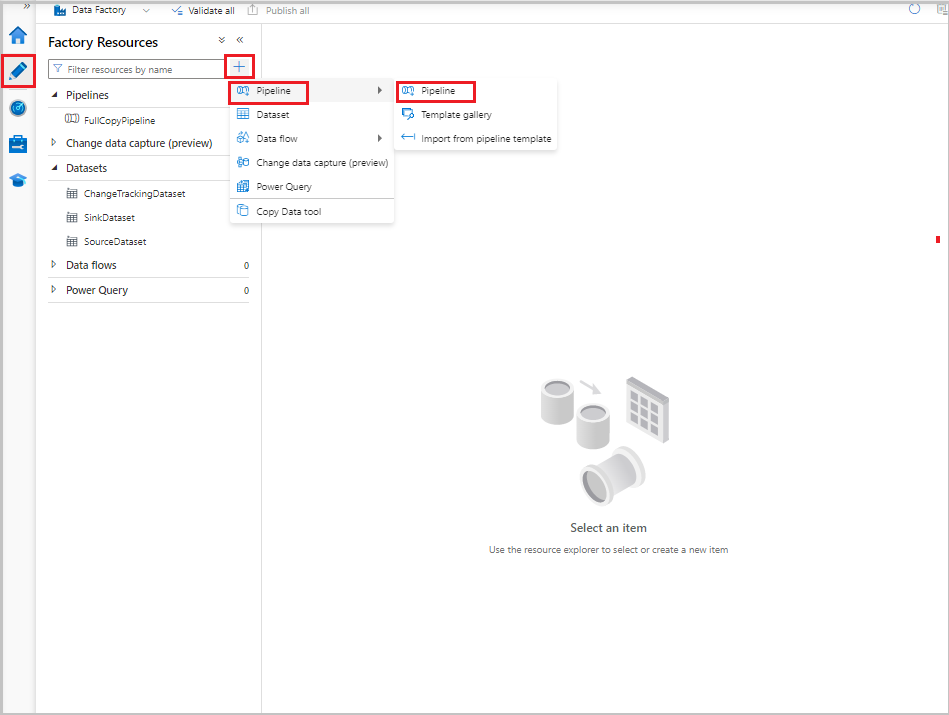
Откроется новая вкладка для настройки конвейера. Конвейер также отображается в представлении дерева. В окне Свойства укажите имя IncrementalCopyPipeline для нового конвейера.
Разверните узел "Общие " на панели элементов действий . Перетащите действие подстановки в область конструктора конвейеров или выполните поиск в поле действий поиска. Задайте для этого действия имя LookupLastChangeTrackingVersionActivity. Это действие получает версию отслеживания изменений, используемую в последней операции копирования, которая хранится в
table_store_ChangeTracking_versionтаблице.Перейдите на вкладку Настройки в окне Свойства. Для исходного набора данных выберите ChangeTrackingDataset.
Перетащите действие подстановки из панели элементов "Действия " в область конструктора конвейеров. Задайте для этого действия имя LookupCurrentChangeTrackingVersionActivity. Это действие возвращает текущую версию отслеживания изменений.
Перейдите на вкладку "Параметры" в окне "Свойства ", а затем выполните следующие действия:
Для исходного набора данных выберите SourceDataset.
В поле "Использовать запрос" выберите "Запрос".
В поле "Запрос" введите следующий SQL-запрос:
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
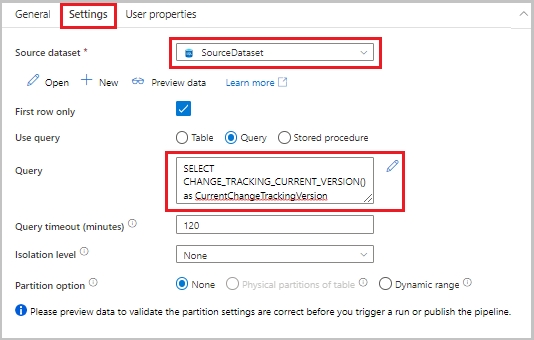
На панели элементов "Действия" разверните узел "Переместить и преобразовать". Перетащите действие копирования данных в область конструктора конвейеров. Присвойте этому действию имя IncrementalCopyActivity. Это действие копирует данные между последней версией отслеживания изменений и текущей версией отслеживания изменений в целевое хранилище данных.
Перейдите на вкладку "Источник" в окне "Свойства", а затем выполните следующие действия:
Для исходного набора данных выберите SourceDataset.
В поле "Использовать запрос" выберите "Запрос".
В поле "Запрос" введите следующий SQL-запрос:
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
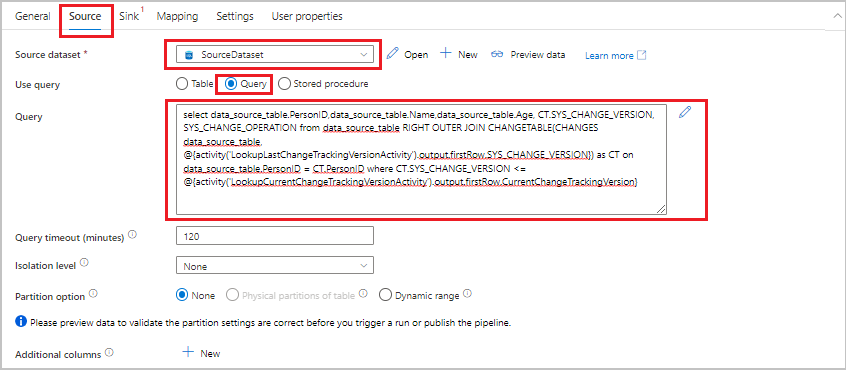
Перейдите на вкладку "Приемник ". Для набора данных приемника выберите SinkDataset.
Подключите оба действия подстановки к действиям копирования по одному. Перетащите зеленую кнопку, присоединенную к действию подстановки, в действие копирования.
Перетащите действие хранимой процедуры из панели элементов "Действия " в область конструктора конвейеров. Присвойте новому действию имя StoredProceduretoUpdateChangeTrackingActivity. Это действие обновляет версию отслеживания изменений в
table_store_ChangeTracking_versionтаблице.Перейдите на вкладку "Параметры" и выполните следующие действия:
- Для связанной службы выберите AzureSqlDatabaseLinkedService.
- Укажите Update_ChangeTracking_Version в качестве имени хранимой процедуры.
- Выберите Импорт.
- В разделе параметров хранимой процедуры укажите следующие значения параметров:
Имя. Тип значение CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameСтрока @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}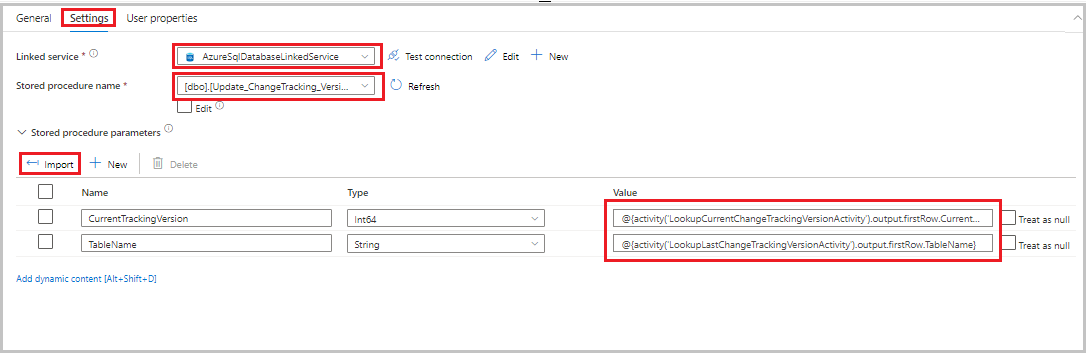
Подключите действие копирования к действию хранимой процедуры. Перетащите зеленую кнопку, присоединенную к действию копирования, в действие хранимой процедуры.
Выберите " Проверить " на панели инструментов. Убедитесь, что проверка завершается без ошибок. Закройте окно отчета проверки конвейера.
Опубликуйте сущности (связанные службы, наборы данных и конвейеры) в службу фабрики данных, нажав кнопку "Опубликовать все ". Подождите, пока сообщение публикации не появится.
Запуск конвейера добавочного копирования
Выберите "Добавить триггер" на панели инструментов для конвейера, а затем нажмите кнопку "Активировать".
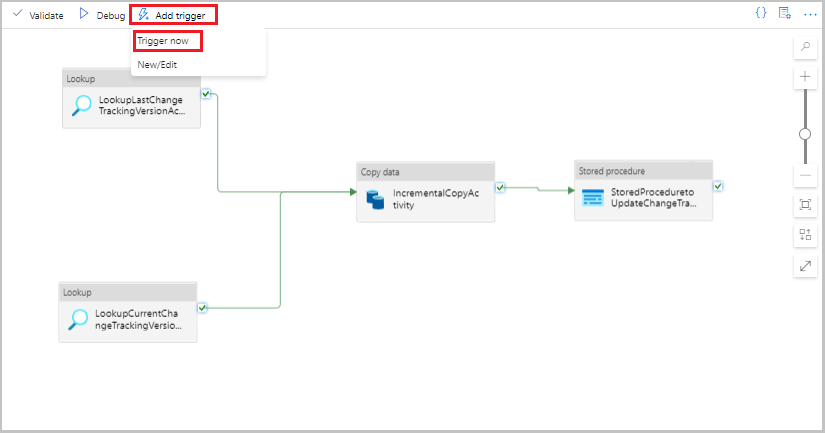
В окне запуска конвейера нажмите кнопку "ОК".
Мониторинг конвейера добавочного копирования
Выберите вкладку "Монитор ". Запуск конвейера и его состояние отображаются в списке. Чтобы обновить список, нажмите кнопку "Обновить".
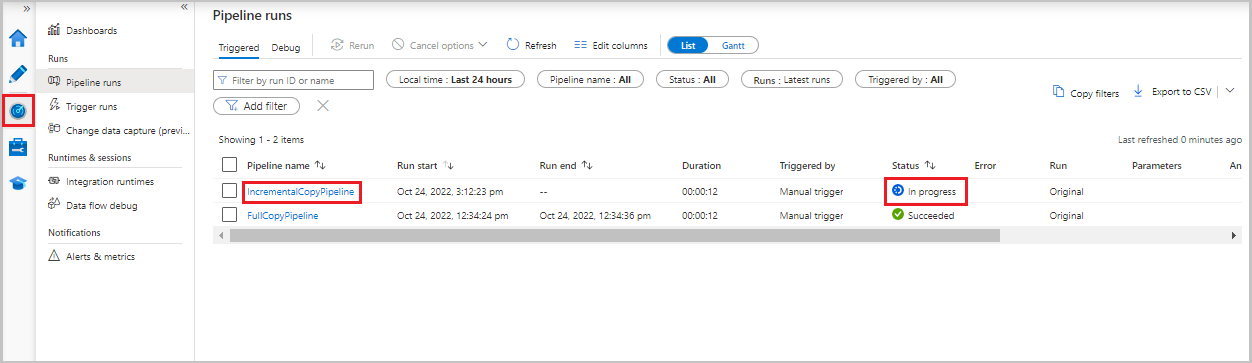
Чтобы просмотреть выполнение действий, связанных с выполнением конвейера, выберите ссылку IncrementalCopyPipeline в столбце имени конвейера. Действия отображаются в списке.
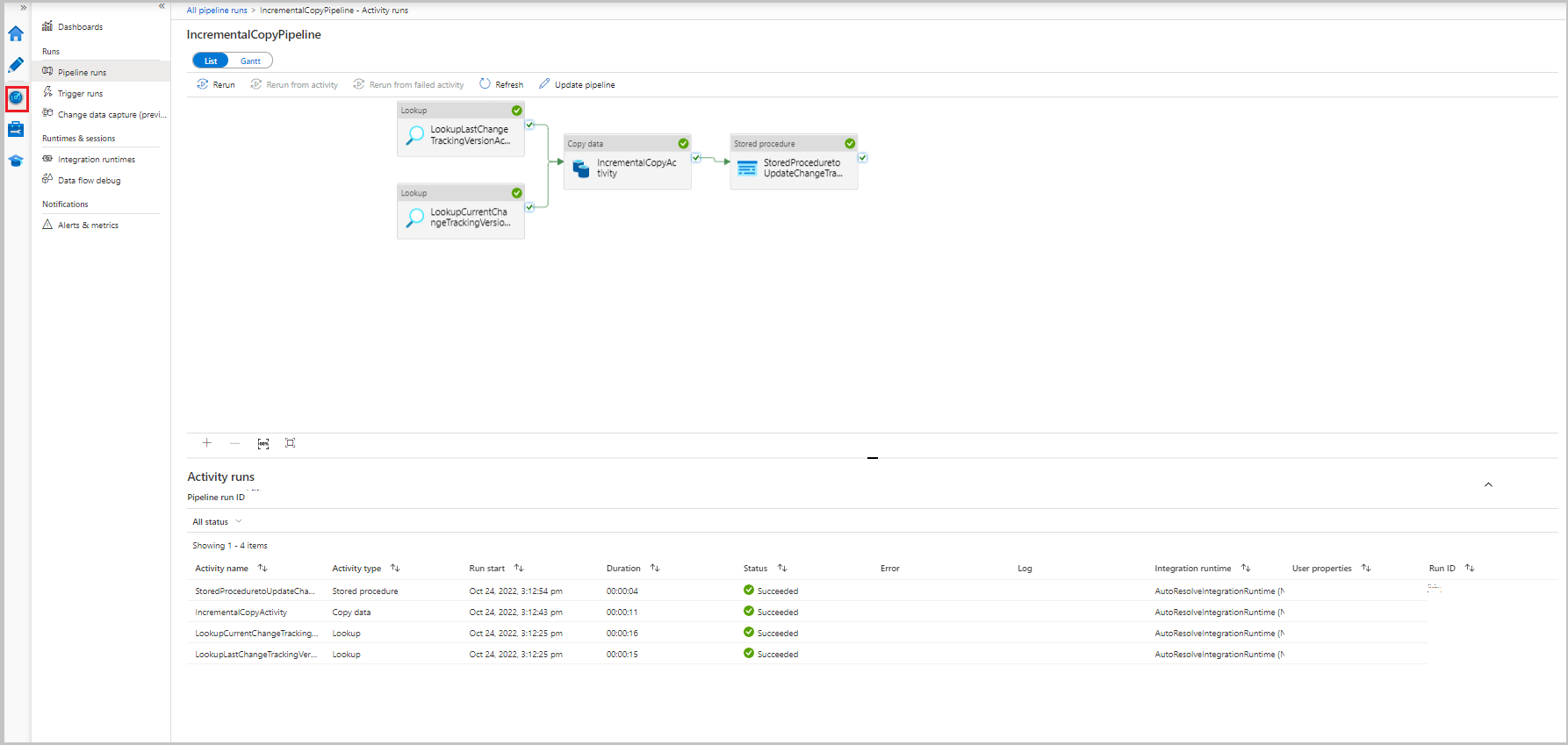
Проверьте результаты.
Второй файл отображается в папке incchgtracking контейнера adftutorial.
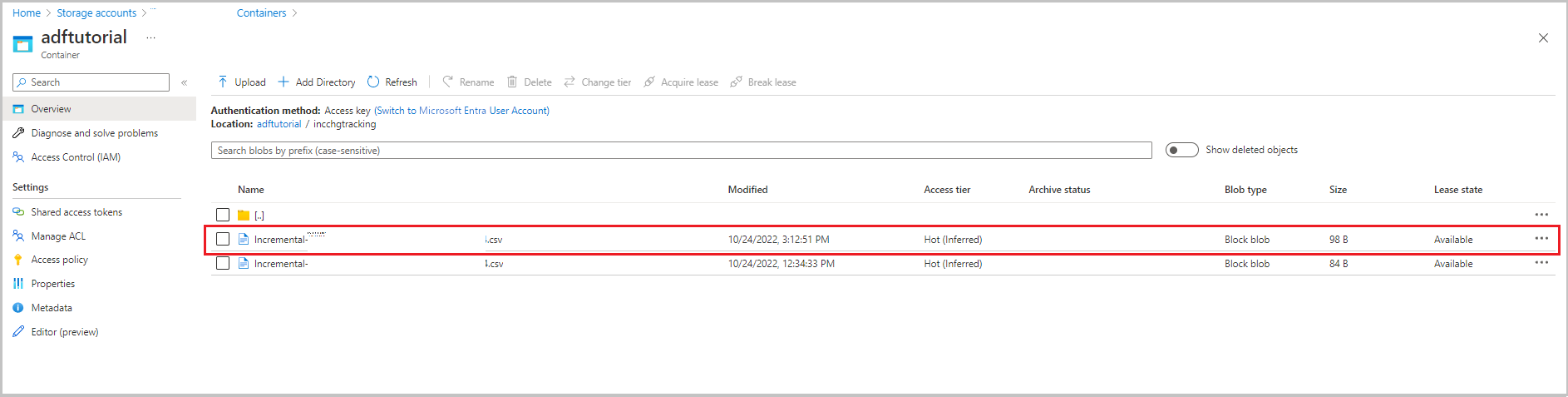
Файл должен включать только разностные данные из базы данных. Запись с U обновленной строкой в базе данных и I является одной добавленной строкой.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
Первые три столбца изменены с data_source_table. Последние два столбца — это метаданные из таблицы для системы отслеживания изменений. Четвертый столбец — это значение для каждой SYS_CHANGE_VERSION измененной строки. Пятый столбец — это операция: U = update, I = insert. Дополнительные сведения об отслеживании изменений см. в описании функции CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Связанный контент
Перейдите к следующему руководству, чтобы узнать о копировании только новых и измененных файлов на основе LastModifiedDate: