Выполнение задания Azure Databricks с бессерверными вычислениями для рабочих процессов
Внимание
Так как бессерверные вычисления для рабочих процессов не поддерживают управление исходящим трафиком, ваши задания имеют полный доступ к Интернету.
Бессерверные вычисления для рабочих процессов позволяют выполнять задание Azure Databricks без настройки и развертывания инфраструктуры. Благодаря бессерверным вычислениям вы можете сосредоточиться на реализации конвейеров обработки и анализа данных, а Azure Databricks эффективно управляет вычислительными ресурсами, включая оптимизацию и масштабирование вычислительных ресурсов для рабочих нагрузок. Автомасштабирование и фотона автоматически включены для вычислительных ресурсов, выполняющих задание.
Бессерверные вычисления для рабочих процессов автоматически и непрерывно оптимизируют инфраструктуру, например типы экземпляров, память и обработчики обработки, чтобы обеспечить оптимальную производительность на основе конкретных требований к обработке рабочих нагрузок.
Databricks автоматически обновляет версию Среды выполнения Databricks для поддержки улучшений и обновлений до платформы, обеспечивая стабильность заданий Azure Databricks. Сведения о текущей версии среды выполнения Databricks, используемой бессерверными вычислениями для рабочих процессов, см. в заметках о выпуске бессерверных вычислений.
Так как разрешение на создание кластера не требуется, все пользователи рабочей области могут использовать бессерверные вычисления для выполнения рабочих процессов.
В этой статье описывается использование пользовательского интерфейса заданий Azure Databricks для создания и запуска заданий, использующих бессерверные вычисления. Вы также можете автоматизировать создание и выполнение заданий, использующих бессерверные вычисления с ПОМОЩЬЮ API заданий, пакетов ресурсов Databricks и пакета SDK Databricks для Python.
- Дополнительные сведения об использовании API заданий для создания и запуска заданий, использующих бессерверные вычисления, см. в справочнике по REST API.
- Сведения об использовании пакетов ресурсов Databricks для создания и запуска заданий, использующих бессерверные вычисления, см. в статье "Разработка задания в Azure Databricks с помощью пакетов ресурсов Databricks".
- Сведения об использовании пакета SDK Databricks для Python для создания и запуска заданий, использующих бессерверные вычисления, см. в пакете SDK Databricks для Python.
Требования
В рабочей области Azure Databricks должна быть включена функция Unity Catalog.
Так как бессерверные вычисления для рабочих процессов используют режим общего доступа, рабочие нагрузки должны поддерживать этот режим доступа.
Рабочая область Azure Databricks должна находиться в поддерживаемом регионе. См. Функции с ограниченной региональной доступностью.
Учетная запись Azure Databricks должна иметь бессерверные вычислительные ресурсы. См. раздел "Включить бессерверные вычисления".
Создание задания с помощью бессерверных вычислений
Примечание.
Так как бессерверные вычислительные ресурсы для рабочих процессов обеспечивают подготовку достаточных ресурсов для выполнения рабочих нагрузок, при выполнении задания Azure Databricks может потребоваться большое количество памяти или множество задач.
Бессерверные вычисления поддерживаются с помощью записных книжек, скрипта Python, dbt и типов задач колеса Python. По умолчанию бессерверные вычисления выбираются в качестве типа вычислений при создании нового задания и добавляют один из этих поддерживаемых типов задач.
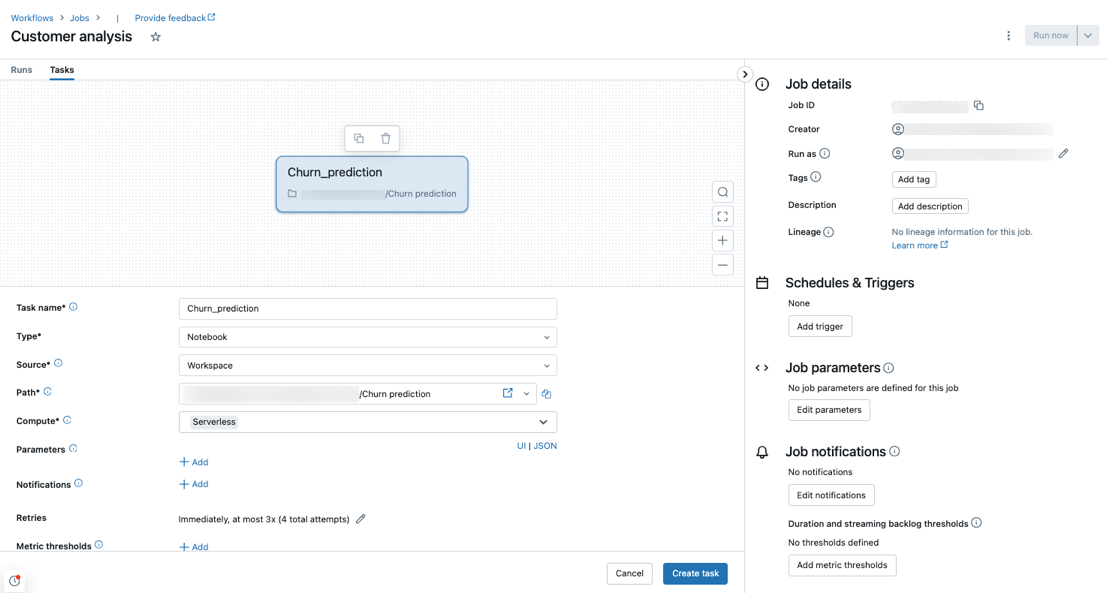
Databricks рекомендует использовать бессерверные вычисления для всех задач задания. Можно также указать различные типы вычислений для задач в задании, которые могут потребоваться, если тип задачи не поддерживается бессерверными вычислениями для рабочих процессов.
Настройка существующего задания для использования бессерверных вычислений
При изменении задания можно переключить существующее задание на использование бессерверных вычислений для поддерживаемых типов задач. Чтобы переключиться на бессерверные вычисления, выполните указанные действия.
- На боковой панели сведений о задании под разделом Вычислениещелкните Заменить, щелкните Новый, введите или измените любые параметры update и щелкните Update.
- В меню раскрывающегося списка вычислений щелкните
 и selectServerless.
и selectServerless.

Планирование записной книжки с помощью бессерверных вычислений
Помимо использования пользовательского интерфейса заданий для создания и планирования задания с помощью бессерверных вычислений, можно создать и запустить задание, использующее бессерверные вычисления непосредственно из записной книжки Databricks. См. статью "Создание запланированных заданий записной книжки и управление ими".
Select бюджетную политику для бессерверного использования
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
Политики бюджета позволяют организации применять пользовательские теги к бессерверному использованию для детализированного выставления счетов.
Если в рабочей области используются политики бюджета для атрибута бессерверного использования, вы можете select бюджетную политику задания с помощью политики бюджета в пользовательском интерфейсе сведений о задании. Если вы назначены только одной политике бюджета, политика автоматически выбирается для новых заданий.
Примечание.
После назначения политики бюджета существующие задания не будут автоматически помечены политикой. Вам нужно вручную выполнить действие по update на существующих заданиях, если вы хотите подключить к ним политику.
Дополнительные сведения о политиках бюджета см. в разделе "Бессерверное использование атрибутов" с политиками бюджета.
Set конфигурации Spark parameters
Чтобы автоматизировать настройку Spark на бессерверных вычислениях, Databricks позволяет задать только определенную конфигурацию Spark parameters. Сведения о list допустимых parametersсм. в разделе поддерживаемых конфигураций Spark parameters.
Конфигурацию Spark можно setparameters только на уровне сеанса. Для этого set их в записную книжку и добавьте записную книжку в задачу, включенную в то же задание, которое использует parameters. См. Get и set свойства конфигурации Apache Spark в записной книжке.
Настройка сред и зависимостей
Сведения об установке библиотек и зависимостей с помощью бессерверных вычислений см. в статье "Установка зависимостей записной книжки".
Настройка автоматической оптимизации бессерверных вычислений для запрета повторных попыток
Бессерверные вычисления для автоматический оптимизации рабочих процессов автоматически оптимизируют вычислительные ресурсы, используемые для выполнения заданий и повторных попыток неудачных задач. Автоматическая оптимизация включена по умолчанию, и Databricks рекомендует оставить ее включено, чтобы обеспечить успешное выполнение критически важных рабочих нагрузок по крайней мере один раз. Однако если у вас есть рабочие нагрузки, которые должны выполняться по крайней мере один раз, например задания, которые не идемпотентны, можно отключить автоматическую оптимизацию при добавлении или редактировании задачи:
- Рядом с
 повторными попытками нажмите кнопку "Добавить" (или если политика повторных попыток уже существует).
повторными попытками нажмите кнопку "Добавить" (или если политика повторных попыток уже существует). - В диалоговом окне политики повторных попыток снимите флажок Включить автоматическую оптимизацию без сервера (может включать дополнительные повторные попытки).
- Нажмите кнопку Подтвердить.
- Если вы добавляете задачу, нажмите кнопку "Создать задачу". Если вы редактировать задачу, нажмите кнопку "Сохранить".
Мониторинг затрат на задания, использующие бессерверные вычисления для рабочих процессов
Вы можете отслеживать затраты на задания, использующие бессерверные вычисления для рабочих процессов, запрашивая систему учёта оплачиваемого использования table. Эта table обновляется, чтобы включить атрибуты пользователя и нагрузки, связанные с бессерверными затратами. См. справочную информацию о системе выставления счетов за использование table.
Сведения о текущих ценах и любых рекламных акциях см. на странице цен рабочих процессов.
Просмотр сведений о запросах для выполнения заданий
Подробные сведения о среде выполнения можно просмотреть для инструкций Spark, таких как метрики и планы запросов.
Чтобы получить доступ к сведениям о запросах из пользовательского интерфейса заданий, выполните следующие действия.
Щелкните
 рабочие процессы на боковой панели.
рабочие процессы на боковой панели.Щелкните имя задания, которое вы хотите просмотреть.
Щелкните конкретный запуск, который вы хотите просмотреть.
Щелкните временную шкалу, чтобы просмотреть запуск в виде временной шкалы , разделенную на отдельные задачи.
Щелкните стрелку рядом с именем задачи, чтобы отобразить инструкции запроса и их среды выполнения.
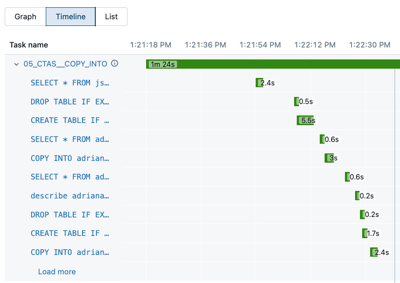
Щелкните инструкцию, чтобы открыть панель сведений о запросе. Дополнительные сведения о запросах см. в разделе "Просмотр сведений ", доступных на этой панели.
Чтобы просмотреть журнал запросов для задачи, выполните следующие действия.
- В разделе вычислений на боковой панели запуска задачи щелкните журнал запросов.
- Вы перенаправляетесь в журнал запросов, префильтрованный на основе идентификатора выполнения задачи, в который вы находились.
См. раздел Журнал запросов Access для конвейеров Delta Live и Tables и Журнал запросовдля получения информации об использовании журнала запросов.
Ограничения
Сведения о list бессерверных вычислений для ограничений рабочих процессов см. в ограничениях бессерверных вычислений в заметках о выпуске бессерверных вычислений.