Проведение собственной проверки производительности конечных точек LLM
В этой статье представлен пример записной книжки, рекомендованной Databricks, для бенчмаркинга конечной точки LLM. Он также содержит краткое введение в то, как Databricks выполняет вывод LLM и вычисляет задержку и пропускную способность в качестве метрик производительности конечных точек.
Вывод LLM на Databricks измеряет количество токенов в секунду в режиме выделенной пропускной способности для API базовой модели. См. раздел Что означают диапазоны токенов в секунду при предоставленной пропускной способности?.
Пример записной книжки для бенчмаркинга
Вы можете импортировать следующую записную книжку в среду Databricks и указать имя конечной точки LLM для выполнения нагрузочного теста.
Бенчмаркинг конечной точки LLM
введение вывода LLM
LLM выполняют выводы в двухэтапном процессе:
- предварительное заполнение, токены во входном запросе where обрабатываются параллельно.
- декодирование, where текст создается по одному токену за раз в авторегрессивном режиме. Каждый созданный маркер добавляется к входным данным и возвращается в модель, чтобы generate следующий маркер. Создание останавливается, когда LLM выводит специальный маркер остановки или когда выполняется определяемое пользователем условие.
Большинство рабочих приложений имеют бюджет задержки, и Databricks рекомендует максимально увеличить пропускную способность, учитывая этот бюджет задержки.
- Количество входных маркеров существенно влияет на требуемую память для обработки запросов.
- Число выходных маркеров доминирует в общей задержке отклика.
Databricks делит инференцию LLM на следующие подметрики.
- время появления первого токена (TTFT): это время, за которое пользователи начинают видеть результирующие данные модели после ввода запроса. Низкое время ожидания ответа важно в режиме реального времени взаимодействия, но менее важно в автономных рабочих нагрузках. Эта метрика зависит от времени, необходимого для обработки запроса, а затем generate первый выходной маркер.
- время для каждого маркера вывода (TPOT): время generate выходной маркер для каждого пользователя, запрашивающего систему. Эта метрика соответствует тем, как каждый пользователь воспринимает "скорость" модели. Например, TPOT в 100 миллисекунд на токен будет составлять 10 токенов в секунду или ~450 слов в минуту, что быстрее, чем обычный пользователь может читать.
На основе этих метрик можно определить общую задержку и пропускную способность следующим образом:
- Задержка = TTFT + (TPOT) * (число создаваемых токенов)
- пропускная способность = количество выходных токенов в секунду во всех запросах с параллельной обработкой
На платформе Databricks конечные точки обработки LLM могут масштабироваться, чтобы соответствовать нагрузке, отправляемой клиентами с несколькими одновременными запросами. Существует компромисс между задержкой и пропускной способностью. Это связано с тем, что в конечных точках обслуживания LLM одновременные запросы могут обрабатываться одновременно. При низкой нагрузке параллельного запроса задержка является самой низкой. Тем не менее, если увеличить нагрузку запроса, задержка может увеличиться, но пропускная способность, скорее всего, также увеличивается. Это связано с тем, что два запроса, которые требуют токенов в секунду, могут обрабатываться за время, менее чем вдвое превышающее стандартное.
Таким образом, управление числом параллельных запросов в систему является основным для балансировки задержки с пропускной способностью. Если у вас есть вариант использования с низкой задержкой, необходимо отправить меньше одновременных запросов в конечную точку, чтобы обеспечить низкую задержку. Если ваш вариант использования требует высокой пропускной способности, необходимо насытить конечную точку большим количеством конкурентных запросов, так как более высокая пропускная способность оправдывает даже увеличение задержки.
- Варианты использования высокой пропускной способности могут включать пакетные выводы прогнозов и другие не ориентированные на пользователя задачи.
- Варианты использования с низкой задержкой могут включать приложения в режиме реального времени, требующие немедленного ответа.
Стенд для бенчмаркинга Databricks
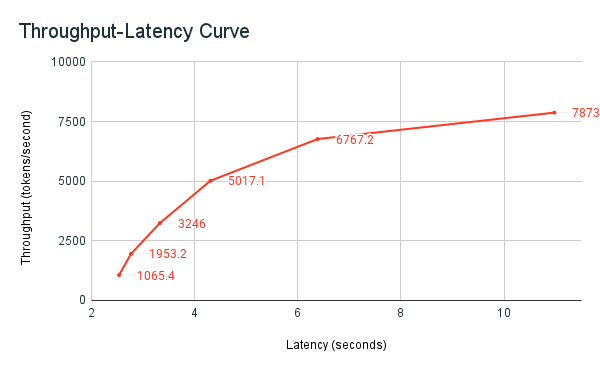
Ранее опубликованный пример записной книжки для тестирования является инструментом тестирования Databricks. Блокнот отображает общую задержку во времени для всех запросов и метрик пропускной способности и строит график кривой зависимости пропускной способности от задержки при разном числе параллельных запросов. Стратегия автомасштабирования конечных точек Databricks балансирует между задержкой и пропускной способностью. В блокноте вы замечаете, что задержка и пропускная способность увеличиваются по мере того как больше одновременных пользователей запрашивают точку доступа.
Однако вы также начинаете видеть, что по мере увеличения числа параллельных запросов пропускная способность начинается на плато, достигая limit около 8000 токенов в секунду. Это плато возникает, так как подготовленная пропускная способность для конечной точки ограничивает количество рабочих и параллельных запросов, которые можно сделать. По мере того как больше запросов выходит за пределы того, что конечная точка может обрабатывать одновременно, общая задержка продолжает увеличиваться по мере ожидания дополнительных запросов в очереди.
Дополнительные сведения о философии Databricks относительно производительности LLM описаны в блоге «Производительность запуска LLM: передовые практики».