Инференция tables для мониторинга и отладки моделей
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
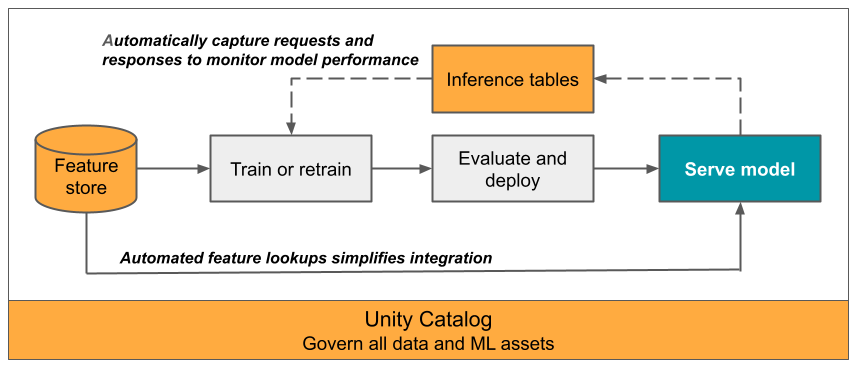
В этой статье описывается вывод tables для обслуживаемой модели мониторинга. На следующей схеме показан типичный рабочий процесс с инференцией tables. Вывод table автоматически фиксирует входящие запросы и исходящие ответы для конечной точки обслуживания модели и записывает их в журнал как Unity Catalog Delta table. Данные в этом table можно использовать для мониторинга, отладки и улучшения моделей машинного обучения.
Для конечных точек обслуживания моделей, в которых размещаются внешние модели, можно включить вывод tables только с помощьюшлюза ИИ.
Что такое умозаключения tables?
Мониторинг производительности моделей в рабочих процессах является важным аспектом жизненного цикла модели искусственного интеллекта и машинного обучения. Вывод tables упростить мониторинг и диагностику моделей путем непрерывного ведения журнала запросов, обслуживающих входные данные и ответы (прогнозы) из конечных точек службы модели ИИ Мозаики и сохранения их в delta table в Unity Catalog. Затем можно использовать все возможности платформы Databricks, такие как запросы Databricks SQL, записные книжки и мониторинг Lakehouse для мониторинга, отладки и optimize моделей.
Вы можете включить инференцию tables на любой существующей или недавно созданной конечной точке обслуживания модели, а затем запросы к этой конечной точке автоматически логируются в table в UC.
Ниже приведены некоторые распространенные приложения для вывода tables.
- Мониторинг качества данных и моделей. Вы можете постоянно отслеживать производительность модели и смещение данных с помощью мониторинга Lakehouse. Мониторинг Lakehouse автоматически создает панели мониторинга качества данных и модели, которые можно поделиться с заинтересованными лицами. Кроме того, вы можете включить оповещения, чтобы узнать, когда необходимо переобучить модель на основе сдвигов входящих данных или уменьшения производительности модели.
- Отладка рабочих проблем. Данные журнала для такого процесса как Inference Tables, включая коды состояния HTTP, время выполнения модели, а также запросы и ответы в формате JSON. Эти данные производительности можно использовать для отладки. Вы также можете использовать исторические данные в выводе Tables для сравнения производительности модели на исторических запросах.
- Создайте обучающий корпус. Присоединив вывод Inference Tables с эталонными метками, вы можете создать обучающий корпус, который можно использовать для повторного обучения или доточной настройки модели. С помощью заданий Databricks можно set цикл непрерывной обратной связи и автоматизировать повторное обучение.
Требования
- В вашей рабочей области должна быть включена версия Unity Catalog.
- Создатель конечной точки и модификатора должны иметь разрешение "Управление " на конечной точке. См. раздел Списки управления доступом.
- Создатель конечной точки и модификатора должны иметь следующие разрешения в Unity Catalog:
-
USE CATALOGразрешения для указанного catalog. -
USE SCHEMAразрешения для указанного schema. -
CREATE TABLEразрешения в schema.
-
Включение и отключение вывода tables
В этом разделе показано, как включить или отключить вывод tables с помощью пользовательского интерфейса Databricks. Вы также можете использовать API; см. Включение вывода данных tables на конечных точках для обслуживания моделей с помощью API для получения инструкций.
Владелец вывода tables является пользователем, создавшим конечную точку. Все списки управления доступом (ACL) на table соответствуют стандартным разрешениям Unity Catalog и могут быть изменены владельцем table.
Предупреждение
Вывод table может стать поврежденным, если выполнить одно из следующих действий:
- Измените tableschema.
- Измените имя table.
- Удалите table.
- Потеря разрешений на Unity Catalog,catalog или schema.
В этом случае состояние конечной точки auto_capture_config показывает состояние FAILED для полезных данных table. В этом случае необходимо создать новую конечную точку для продолжения использования инференса tables.
Чтобы активировать инференцию tables во время создания конечной точки, выполните следующие действия.
Щелкните "Служить " в пользовательском интерфейсе ИИ Для Мозаики Databricks.
Нажмите кнопку "Создать конечную точку обслуживания".
Select Включить вывод tables.
В раскрывающихся меню select требуемые catalog и schemawhere, которые вы хотите найти table.
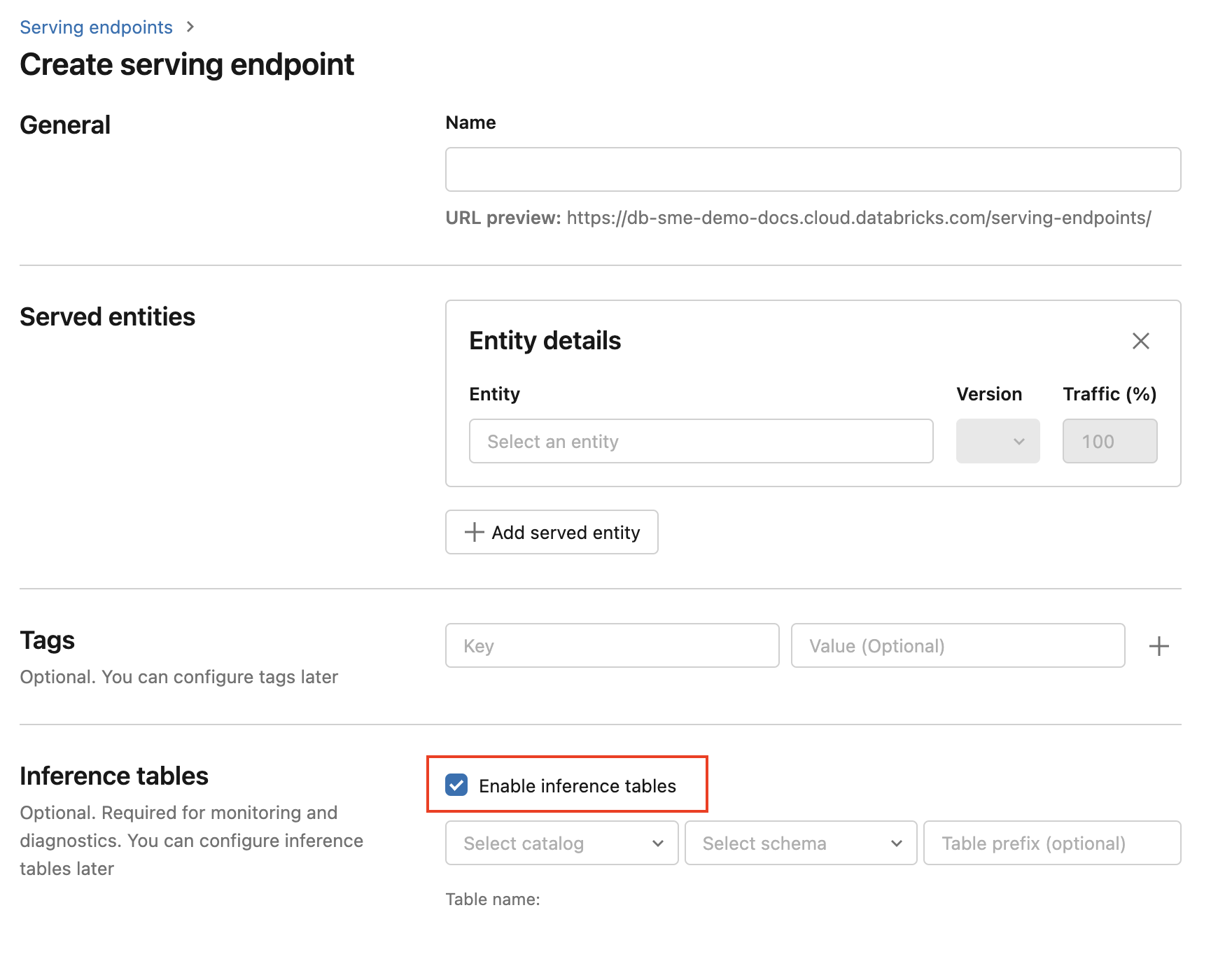
Имя table по умолчанию —
<catalog>.<schema>.<endpoint-name>_payload. При желании можно ввести настраиваемый префикс table.Нажмите кнопку "Создать конечную точку обслуживания".
Вы также можете включить инференцию tables на существующем конечном узле. Чтобы изменить существующую конфигурацию конечной точки, сделайте следующее:
- Перейдите на страницу конечной точки.
- Нажмите кнопку "Изменить конфигурацию".
- Выполните предыдущие инструкции, начиная с шага 3.
- После завершения щелкните Update обслуживающий конечный узел.
Выполните следующие инструкции, чтобы отключить вывод tables:
- Перейдите на страницу конечной точки.
- Нажмите кнопку "Изменить конфигурацию".
- Щелкните Включить логическое заключение table, чтобы поставить remove флажок.
- Как только вы будете удовлетворены спецификациями конечной точки, щелкните Update.
рабочий процесс . Мониторинг производительности модели с помощью tables вывода
Чтобы отслеживать производительность модели с помощью вывода tables, выполните следующие действия.
- Включите инференцию tables на вашем эндпоинте при его создании или обновите его позже.
- Запланируйте рабочий процесс для обработки JSON данных в инференсе table, распаковав их в соответствии с характеристиками schema конечной точки.
- (Необязательно) Join распакованные запросы и ответы с метками "земляная истина", чтобы вычислить метрики качества модели.
- Создайте монитор для результирующего разностного table и refresh метрик.
Начальные записные книжки реализуют этот рабочий процесс.
Стартовый блокнот для мониторинга инференса table
Следующая записная книжка реализует описанные выше шаги для распаковки запросов из вывода мониторинга Lakehouse table. Записная книжка может выполняться по запросу или по регулярному расписанию с помощью заданий Databricks.
Стартовый ноутбук для инференции table Lakehouse Monitoring
Начальная записная книжка для мониторинга качества текста из конечных точек, обслуживающих LLM
Следующий ноутбук распаковывает запросы из вывода table, вычисляет set метрик оценки текста (например, удобочитаемость и токсичность) и обеспечивает наблюдение за этими метриками. Записная книжка может выполняться по запросу или по регулярному расписанию с помощью заданий Databricks.
Начальная записная книжка для вывода LLM table Lakehouse Monitoring
Запрос и анализ результатов в инференции table.
После подготовки обслуживаемых моделей все запросы, сделанные к вашим моделям, автоматически регистрируются в журнале инференса tableи ответы. Вы можете просмотреть table в пользовательском интерфейсе, запросить table из DBSQL или записной книжки или запросить table с помощью REST API.
Чтобы просмотреть table в интерфейсе: На странице конечной точки щелкните на имени вывода table, чтобы открыть table в обозревателе Catalog.

Запрос table из DBSQL или записной книжки Databricks: Можно выполнить код, аналогичный следующему, чтобы запросить инференцию table.
SELECT * FROM <catalog>.<schema>.<payload_table>
Если вы включили инференцию tables с помощью пользовательского интерфейса, payload_table — это имя table, которое вы назначили при создании конечной точки. Если вы включили инференцию tables с помощью API, payload_table указывается в разделе state ответа auto_capture_config. Пример см. в статье Включение инференса tables в конечных точках сервиса моделей с использованием API.
Примечание о производительности
После вызова конечной точки, вы можете увидеть, что запрос зарегистрирован в вашей системе вывода инференции table в течение часа после отправки запроса оценки. Кроме того, Azure Databricks гарантирует доставку журналов по крайней мере один раз, поэтому это возможно, хотя и маловероятно, что повторяющиеся журналы отправляются.
Вывод Catalog Unity tableschema
Каждый запрос и ответ, который регистрируется в выводе table, записывается в Delta table со следующими параметрами schema.
Примечание.
При вызове конечной точки с пакетом входных данных весь пакет регистрируется как одна строка.
| Column имя | Описание | Тип |
|---|---|---|
databricks_request_id |
Запрос identifier, созданный Azure Databricks, прикреплен ко всем запросам на обслуживание моделей. | STRING |
client_request_id |
Необязательный запрос, созданный клиентом, identifier, который можно указать в тексте запроса на обслуживание модели. Дополнительные сведения см. в разделе "Указание client_request_id ". |
STRING |
date |
Дата UTC, по которой был получен запрос на обслуживание модели. | DATE |
timestamp_ms |
Метка времени в миллисекундах эпохи при получении запроса на обслуживание модели. | LONG |
status_code |
Код состояния HTTP, возвращенный из модели. | INT |
sampling_fraction |
Дробь выборки, используемая в том случае, если запрос был понижен. Это значение составляет от 0 до 1, where 1 означает, что было включено 100% входящих запросов. | DOUBLE |
execution_time_ms |
Время выполнения в миллисекундах, для которого модель выполнила вывод. Это не включает задержки сети из-за накладных расходов и представляет только время, за которое модель generate сделала прогнозы. | LONG |
request |
Необработанный текст JSON запроса, отправленный в конечную точку обслуживания модели. | STRING |
response |
Текст JSON необработанного ответа, возвращаемый конечной точкой обслуживания модели. | STRING |
request_metadata |
Карта метаданных, связанных с конечной точкой обслуживания модели, связанной с запросом. Эта карта содержит имя конечной точки, имя модели и версию модели, используемую для конечной точки. | MAP<STRING, STRING> |
Уточнять client_request_id
Поле client_request_id является необязательным значением, которое пользователь может предоставить в тексте запроса на обслуживание модели. Это позволяет пользователю предоставлять свои собственные identifier для запроса, который отображается в окончательном выводе table под client_request_id и может использоваться для объединения вашего запроса с другими tables, которые используют client_request_id, например, для объединения с истинными метками. Чтобы указать client_request_idзначение, добавьте его в качестве ключа верхнего уровня полезных данных запроса. Если значение не client_request_id указано, значение отображается как null в строке, соответствующей запросу.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
client_request_id позже можно использовать для объединения истинных меток, если существуют другие tables с метками, связанными с client_request_id.
Ограничения
- Управляемые клиентом ключи не поддерживаются.
- Для конечных точек, которые хостят базовые модели, инференс tables поддерживается только на рабочих нагрузках с подготовленной пропускной способностью .
- Брандмауэр Azure может привести к сбою создания Unity Catalog Delta table, поэтому он не поддерживается по умолчанию. Обратитесь к группе учетных записей Databricks, чтобы включить ее.
- Если включена функция tables вывода, limit для максимального параллелизма выполнения всех обслуживаемых моделей в одной конечной точке равно 128. Обратитесь к команде по работе с клиентами Azure Databricks, чтобы запросить увеличение этого limit.
- Если вывод table содержит более 500 тысяч файлов, дополнительные данные не записываются. Чтобы избежать переполнения этого limit, включите функции OPTIMIZE или set для удержания данных на table, удаляя старые данные. Чтобы проверить количество файлов в table, выполните команду
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>. - В настоящее время доставка журнала tables осуществляется по принципу наилучшего исполнения, однако вы можете ожидать, что журналы будут доступны в течение 1 часа после запроса. Обратитесь к группе учетных записей Databricks, чтобы получить дополнительные сведения.
Общие ограничения конечных точек обслуживания модели см. в разделе "Ограничения службы моделей" и "Регионы".