Логирование, загрузка и регистрация моделей MLflow
Модель MLflow — это стандартный формат для упаковки моделей машинного обучения, который можно использовать в различных нижестоящих инструментах, например для вывода пакетов на Apache Spark или при обслуживании в режиме реального времени через REST API. Формат определяет соглашение, позволяющее сохранить модель в различных вариантах (python-function, pytorch, sklearn и т. д.), которые могут быть понятны различным моделям и платформам вывода.
Сведения о том, как регистрировать и оценить модель потоковой передачи, см. в статье "Как сохранить и загрузить модель потоковой передачи".
Журналы и загрузка моделей
При регистрации модели MLflow автоматически записывает журналы requirements.txt и conda.yaml файлы. Эти файлы можно использовать для повторного создания среды разработки модели и переустановки зависимостей с помощью virtualenv (рекомендуется) или conda.
Внимание
Корпорация Anaconda Inc. обновила свои условия предоставления услуг для каналов anaconda.org. В соответствии с новыми условиями предоставления услуг для использования пакетов и распространения Anaconda может потребоваться коммерческая лицензия. Дополнительные сведения см. в часто задаваемых вопросах о коммерческом выпуске Anaconda. Использование любых каналов Anaconda регулируется условиями предоставления услуг Anaconda.
Модели MLflow, зарегистрированные до выхода версии 1.18 (Databricks Runtime 8.3 ML или более ранней версии), по умолчанию регистрировались с каналом conda defaults (https://repo.anaconda.com/pkgs/) в качестве зависимости. Из-за этого изменения условий предоставления услуг компания Databricks прекратила использовать канал defaults для моделей, зарегистрированных с помощью MLflow 1.18 и более поздних версий. По умолчанию теперь регистрируется канал conda-forge, который указывает на управляемый сообществом сайт https://conda-forge.org/.
Если вы зарегистрировали модель до выхода MLflow версии 1.18 и не исключили канал defaults из среды conda для модели, эта модель может иметь зависимость от канала defaults, которая, возможно, не предполагалась.
Чтобы узнать, имеет ли модель эту зависимость, можно проверить значение channel в файле conda.yaml, который упакован с зарегистрированной моделью. Например, conda.yaml модели с зависимостью от канала defaults может выглядеть так:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Так как Databricks не может определить, разрешено ли вам использовать репозиторий Anaconda для взаимодействия с моделями, Databricks не требует от пользователей вносить какие-либо изменения. Если вы используете репозиторий Anaconda.com с помощью Databricks в соответствии с условиями Anaconda, вам не нужно предпринимать никаких действий.
Если вы хотите изменить канал, используемый в среде модели, можно повторно зарегистрировать модель в реестре моделей с новым conda.yaml. Это можно сделать, указав канал в параметре conda_envlog_model().
Дополнительные сведения об API log_model() см. в документации по MLflow для варианта модели, с которым вы работаете, например log_model для scikit-learn.
Дополнительные сведения о файлах conda.yaml см. в документации по MLflow.
Команды API
Чтобы зарегистрировать модель на сервере отслеживания MLflow, используйте mlflow.<model-type>.log_model(model, ...).
Чтобы загрузить ранее зарегистрированную модель для вывода или дальнейшей разработки, используйте mlflow.<model-type>.load_model(modelpath), wheremodelpath является одной из следующих:
- путь, относительный для выполнения (например,
runs:/{run_id}/{model-path}) - Путь в Unity Catalogvolumes (например,
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - Путь к хранилищу артефактов, управляемым MLflow, начиная с
dbfs:/databricks/mlflow-tracking/ - путь к зарегистрированной модели (например,
models:/{model_name}/{model_stage}).
Для полного list вариантов загрузки моделей MLflow см. раздел ссылки на артефакты в документации по MLflow.
Для моделей MLflow Python можно использовать mlflow.pyfunc.load_model() для загрузки модели в качестве универсальной функции Python.
Чтобы загрузить точки данных модели и оценки, можно использовать следующий фрагмент кода.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
В качестве альтернативы можно экспортировать модель в качестве Apache Spark UDF для оценки в кластере Spark либо в виде пакетного задания, либо в виде задания потоковой передачи Spark в реальном времени.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Зависимости модели журналов
Чтобы правильно загрузить модель, необходимо убедиться, что зависимости модели загружены в среду записной книжки с подходящими версиями. В Databricks Runtime 10.5 ML и более поздних версий MLflow предупреждает о несоответствии между текущей средой и зависимостями модели.
Дополнительные функции, упрощающие восстановление зависимостей модели, включены в Databricks Runtime 11.0 ML и более поздних версий. В Databricks Runtime 11.0 ML и более поздних версий для варианта моделей pyfunc можно вызывать mlflow.pyfunc.get_model_dependencies, чтобы извлечь и скачать зависимости модели. Эта функция возвращает путь к файлу зависимостей, который затем можно установить с помощью %pip install <file-path>. При загрузке модели в качестве определяемой пользователем функции PySpark укажите env_manager="virtualenv" в вызове mlflow.pyfunc.spark_udf. Это восстанавливает зависимости модели в контексте определяемой пользователем функции PySpark и не влияет на внешнюю среду.
Эту функцию также можно использовать в Databricks Runtime 10.5 или более ранних версий, вручную установив MLflow версии 1.25.0 или выше:
%pip install "mlflow>=1.25.0"
Дополнительные сведения о том, как регистрировать зависимости модели (Python и не python) и артефакты, см. в разделе "Зависимости модели журнала".
Узнайте, как регистрировать зависимости модели и пользовательские артефакты для обслуживания моделей:
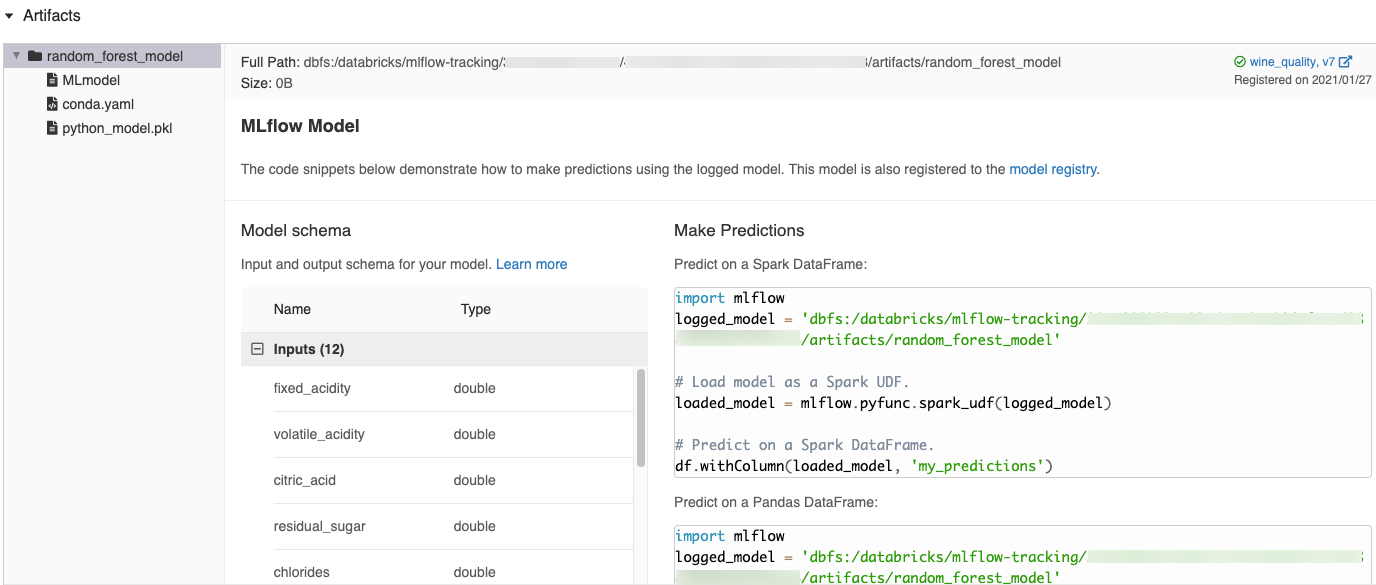
Автоматически созданные фрагменты кода в пользовательском интерфейсе MLflow
При регистрации модели в записной книжке Azure Databricks Azure Databricks автоматически создает фрагменты кода, которые можно копировать и использовать для загрузки и запуска модели. Чтобы просмотреть эти фрагменты кода, сделайте следующее:
- Перейдите на экран "Запуски" для поиска запуска, создавшего модель. (Дополнительные сведения о том, как отобразить экран "Запуски", см. в разделе Просмотр эксперимента записной книжки.)
- Прокрутите до раздела Артефакты.
- Нажмите на имя зарегистрированной модели. Справа откроется панель с кодом, который можно использовать для загрузки зарегистрированной модели и выполнения прогнозов в кадрах данных Spark или Pandas.
Примеры
Примеры моделей ведения журнала см. в примерах, приведенных в разделе Примеры отслеживания пробных запусков машинного обучения.
Регистрация моделей в реестре модели
Вы можете зарегистрировать модели в реестре моделей MLflow, централизованное хранилище моделей, которое предоставляет пользовательский интерфейс и set API для управления полным жизненным циклом моделей MLflow. Инструкции по использованию реестра моделей для управления моделями в Databricks Unity Catalogсм. в статье Управление жизненным циклом модели в CatalogUnity. Сведения об использовании реестра моделей рабочей области см. в разделе "Управление жизненным циклом модели" с помощью реестра моделей рабочей области (устаревшая версия).
Для регистрации модели с помощью API, воспользуйтесь mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}").
Сохраните модели в Unity Catalogvolumes
Чтобы сохранить модель локально, воспользуйтесь mlflow.<model-type>.save_model(model, modelpath).
modelpath должен быть путём Catalogvolumes Unity. Например, если вы используете Unity расположение Catalogvolumesdbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models для хранения работы над проектом, необходимо использовать путь модели /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models.
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
Для моделей MLlib используйте конвейеры машинного обучения.
Скачать артефакты модели
Можно скачать зарегистрированные артефакты модели (например, файлы модели, графики и метрики) для зарегистрированных моделей с помощью различных API.
Пример API Python:
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
Пример API Java:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
Пример команды CLI:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Развертывание моделей для обслуживания в сети
Используйте Mosaic AI Model Serving для размещения моделей машинного обучения, зарегистрированных в реестре моделей Unity Catalog, в качестве REST-эндпоинтов. Эти конечные точки обновляются автоматически на основе доступности версий модели.