Июль 2019 г.
Эти функции и улучшения платформы Azure Databricks были выпущены в июле 2019 г.
Примечание.
Выпуски являются поэтапными. На обновление вашей учетной записи Azure Databricks может потребоваться до одной недели с даты выпуска.
В ближайшее время: Databricks 6.0 не будет поддерживать Python 2
Перед предстоящим прекращением поддержки Python 2, объявленного на 2020 г., мы сообщаем, что Python 2 не будет поддерживаться в Databricks Runtime 6.0. Более ранние версии Databricks Runtime сохраняют поддержку Python 2. Мы планируем выпустить Databricks Runtime 6.0 позднее в 2019 г.
Предварительная загрузка версии Databricks Runtime в свободных экземплярах пула
30 июля — 6 августа 2019 г.: версия 2.103
Теперь вы можете ускорить запуск кластеров на основе пулов, выбрав версию Databricks Runtime, которая будет загружаться на простаивающих экземплярах в пуле. Поле в пользовательском интерфейсе пула называется Предварительно загруженная версия Spark.

Улучшено взаимодействие пользовательских тегов кластера и тегов пула
30 июля — 6 августа 2019 г.: версия 2.103
Ранее в этом месяце в Azure Databricks были реализованы пулы, набор простаивающих экземпляров, которые позволяют быстро запускать кластеры. В исходном выпуске кластеры на основе пулов наследовали теги по умолчанию и пользовательские теги из конфигурации пула, при этом вы не могли изменять эти теги на уровне кластера. Теперь вы можете настроить пользовательские теги для конкретных кластеров на основе пулов, и такие кластеры будут применять все пользовательские теги, независимо от того, наследованы ли они из пула или специально назначены такому кластеру. Невозможно добавить специальный пользовательский тег кластера с тем же именем ключа, что и пользовательский тег, унаследованный от пула (т. е. невозможно переопределить пользовательский тег, наследуемый от пула). Дополнительные сведения см. в разделе Теги пулов.
MLflow 1.1 содержит несколько улучшений пользовательского интерфейса и API
30 июля — 6 августа 2019 г.: версия 2.103
В MLflow 1.1 реализовано несколько новых функций для улучшения работы с пользовательским интерфейсом и API:
Пользовательский интерфейс для просмотра запусков теперь позволяет просматривать несколько страниц запусков, если их число превышает 100. После 100-го запуска нажмите кнопку Загрузить еще, чтобы загрузить следующие 100 запусков.
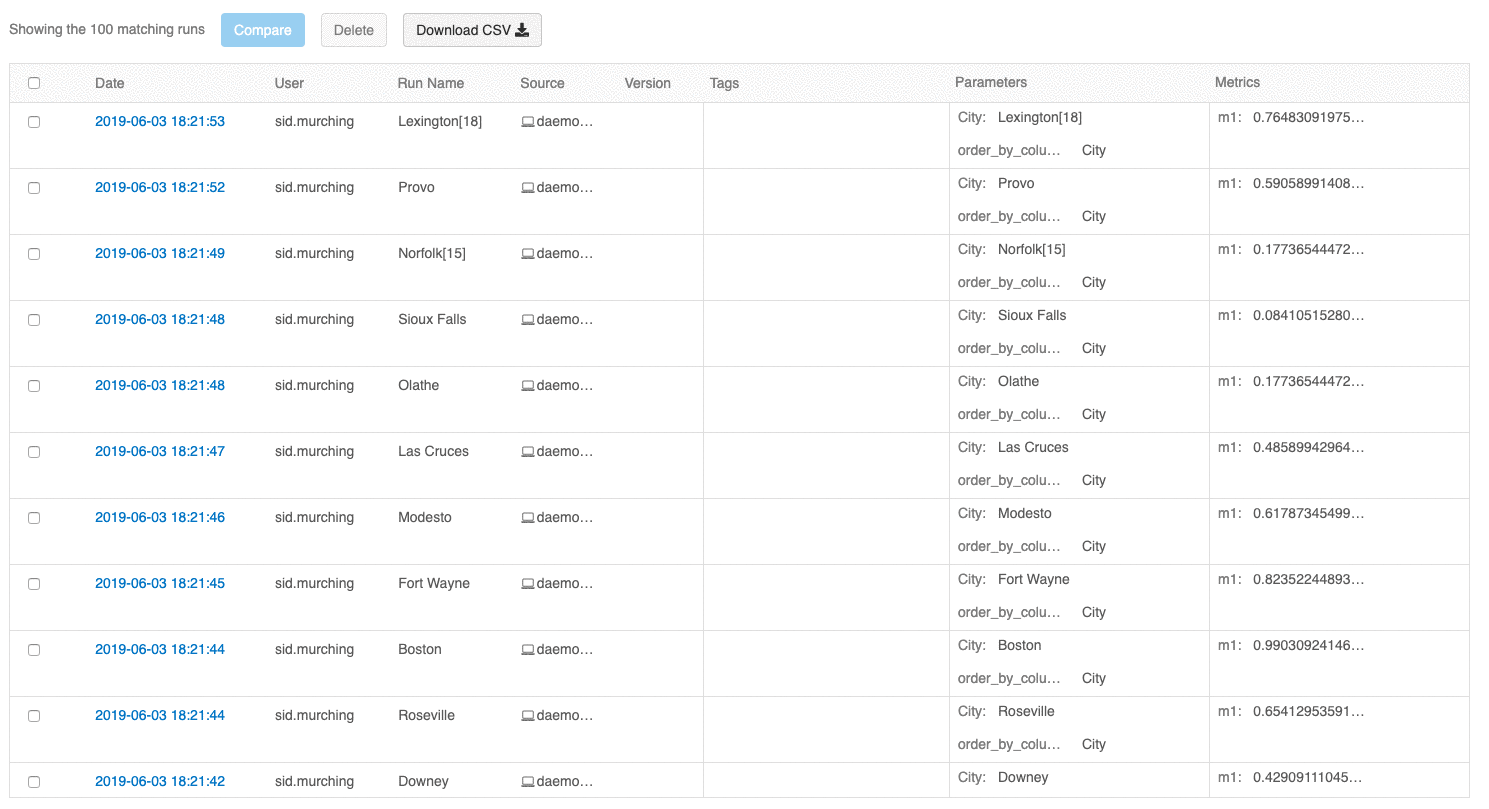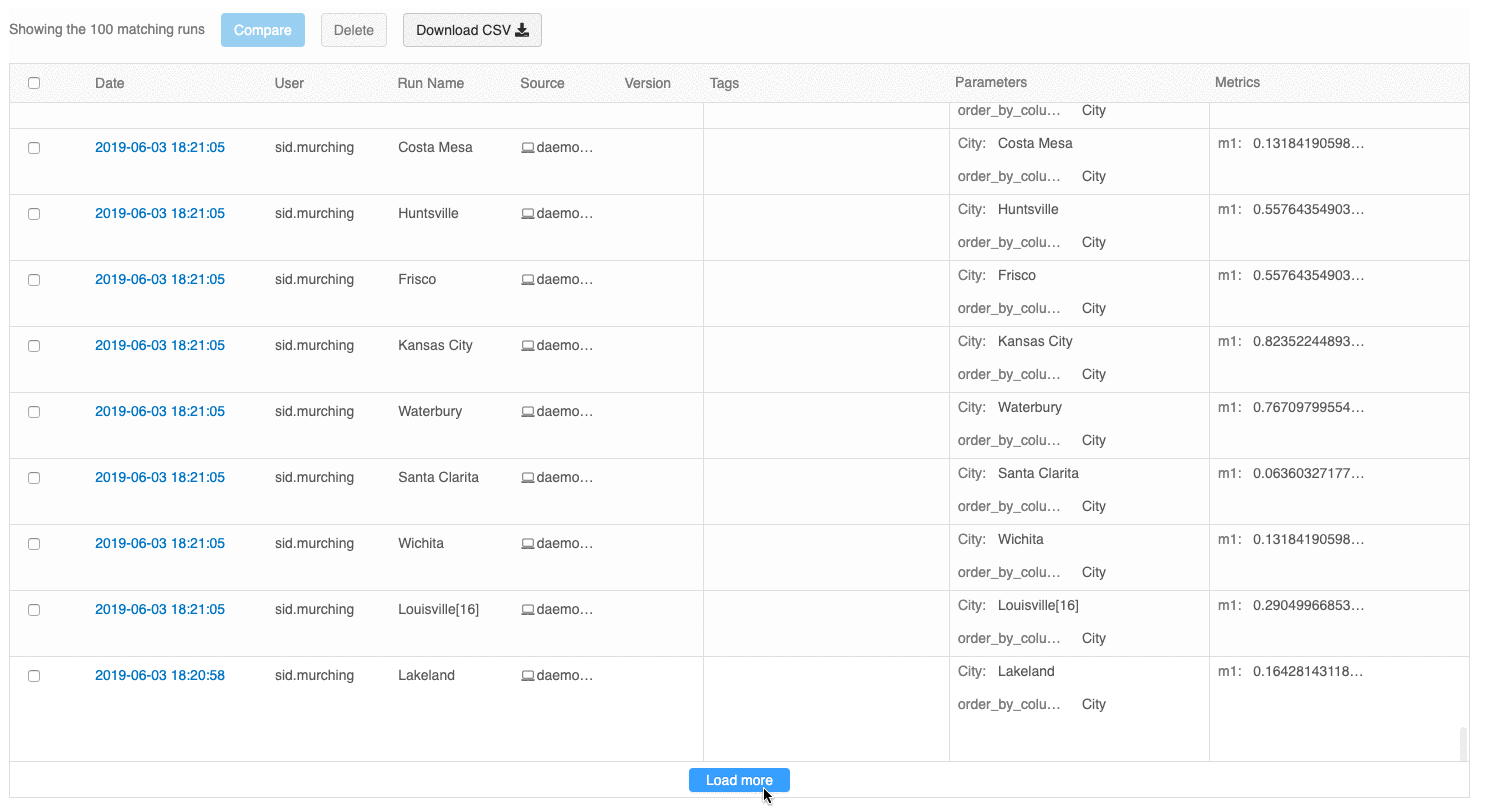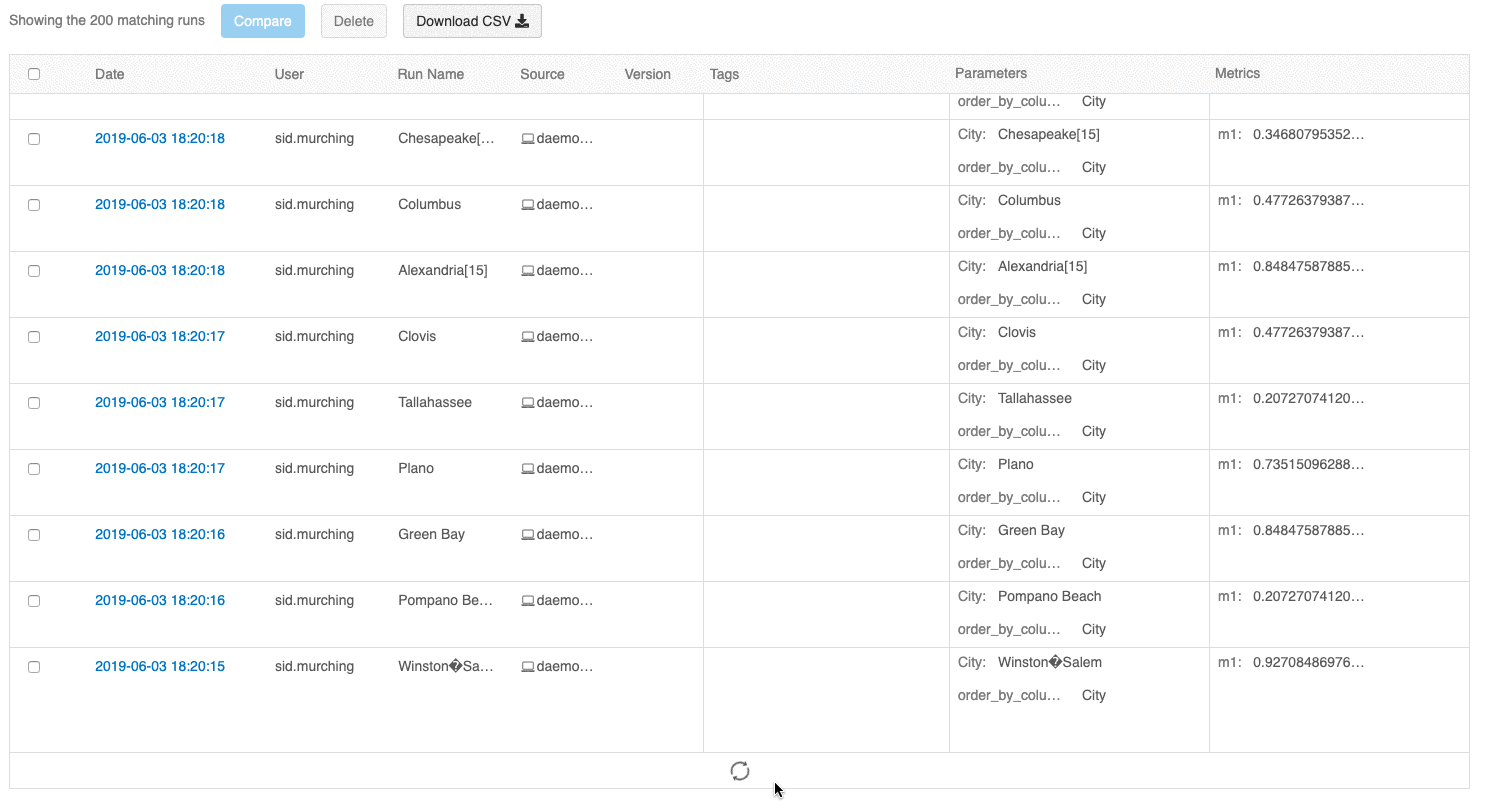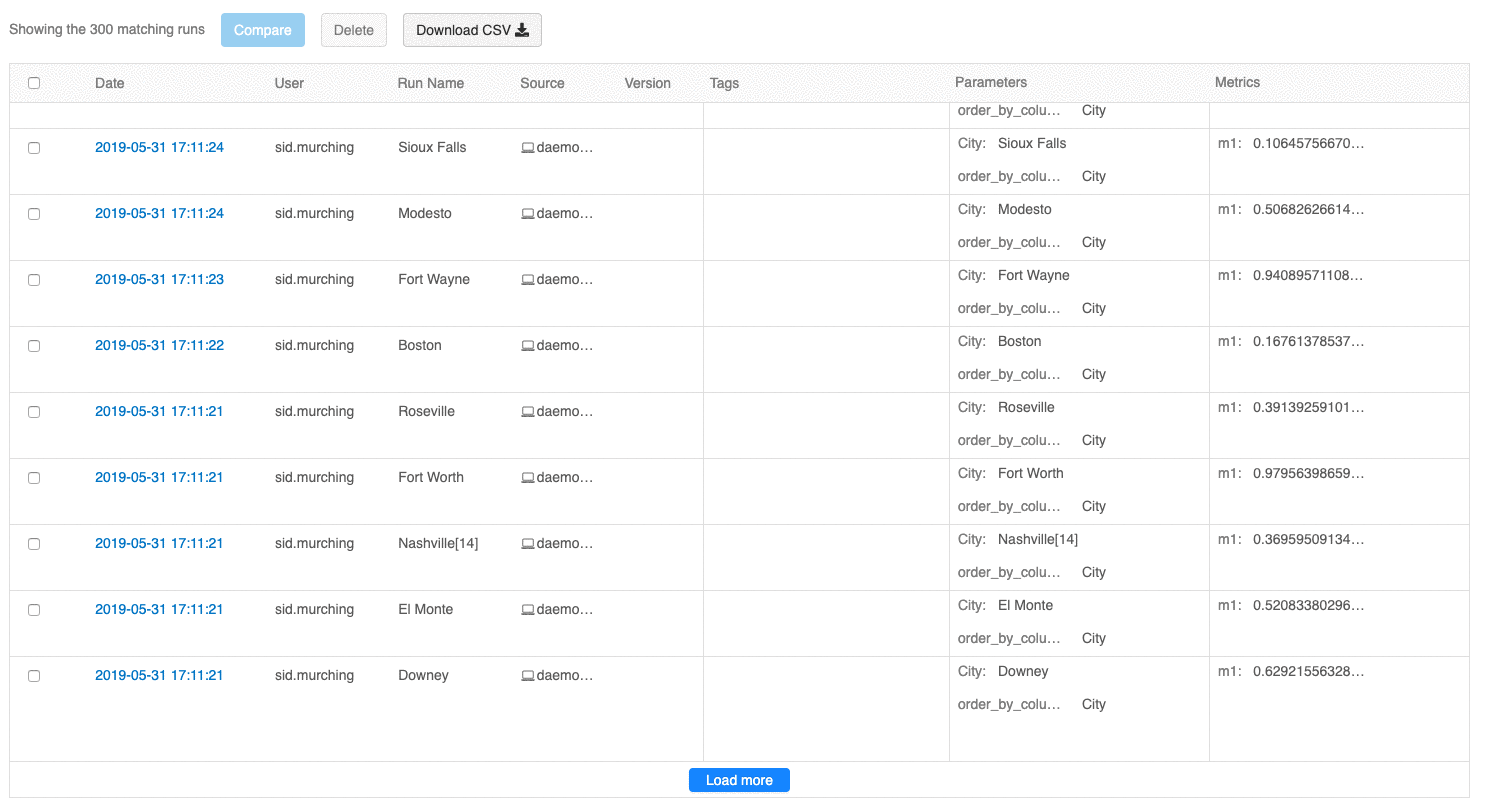
Пользовательский интерфейс сравнения запусков теперь выводит график с параллельными координатами. Такой график позволяет вам оценить отношения между n-мерным набором параметров и метрик. Он визуализирует все запуски в виде линий с цветовым кодированием, основанном на значении метрики (например, точность), и показывает значения параметров для каждого запуска.

Теперь вы можете добавлять и изменять теги из пользовательского интерфейса просмотра запусков и просматривать теги в представлении поиска экспериментов.
Новый API MLflowContext позволяет создавать и регистрировать запуски так же, как и с помощью API Python. Этот API отличается от существующего API
MlflowClientнижнего уровня, который просто выполняет роль оболочки для REST API.Теперь вы можете удалить теги из запусков MLflow с помощью API удаления тегов.
Дополнительные сведения см. в записи блога о MLflow 1.1. Полный список функций и исправлений см. в журнале изменений MLflow.
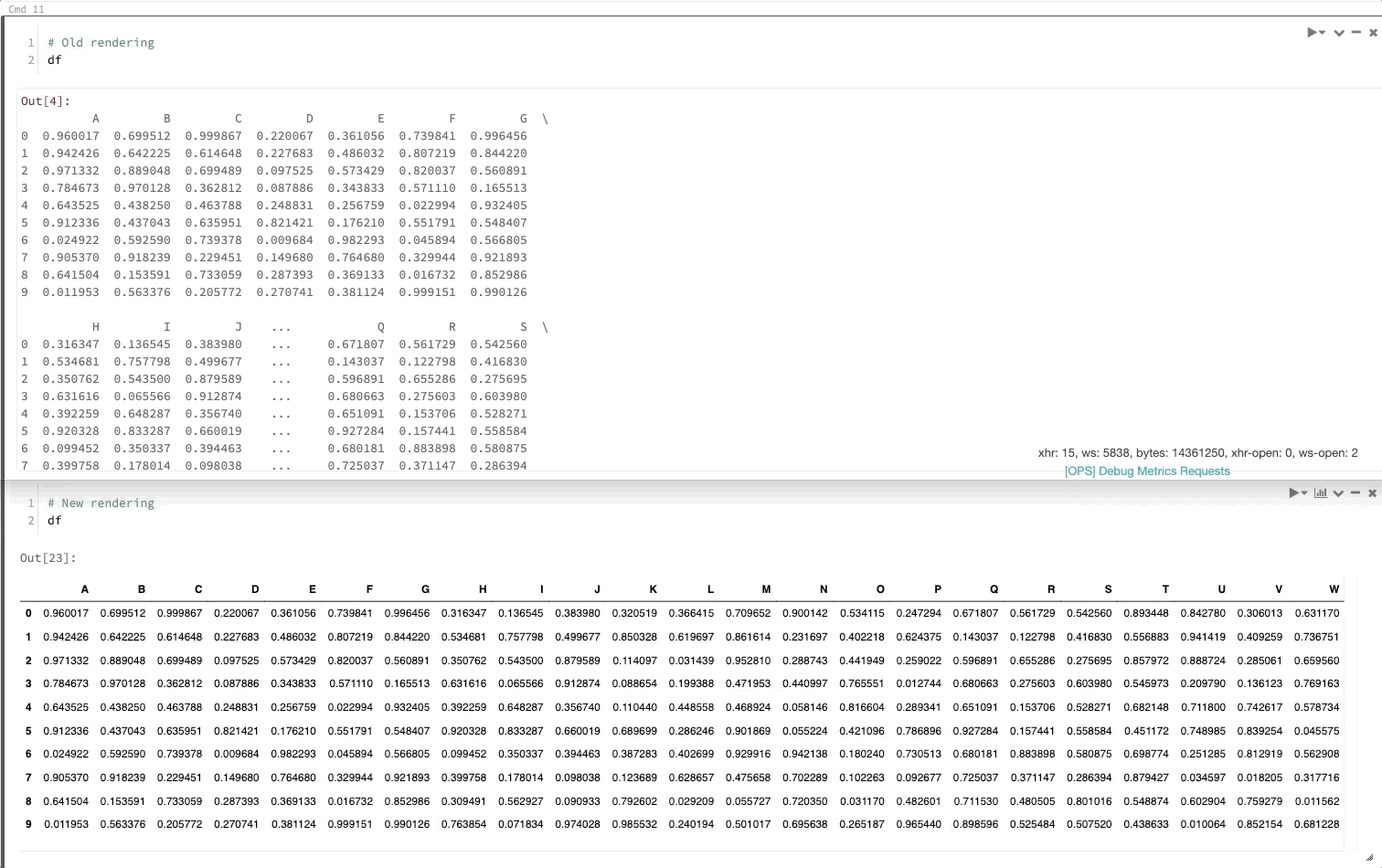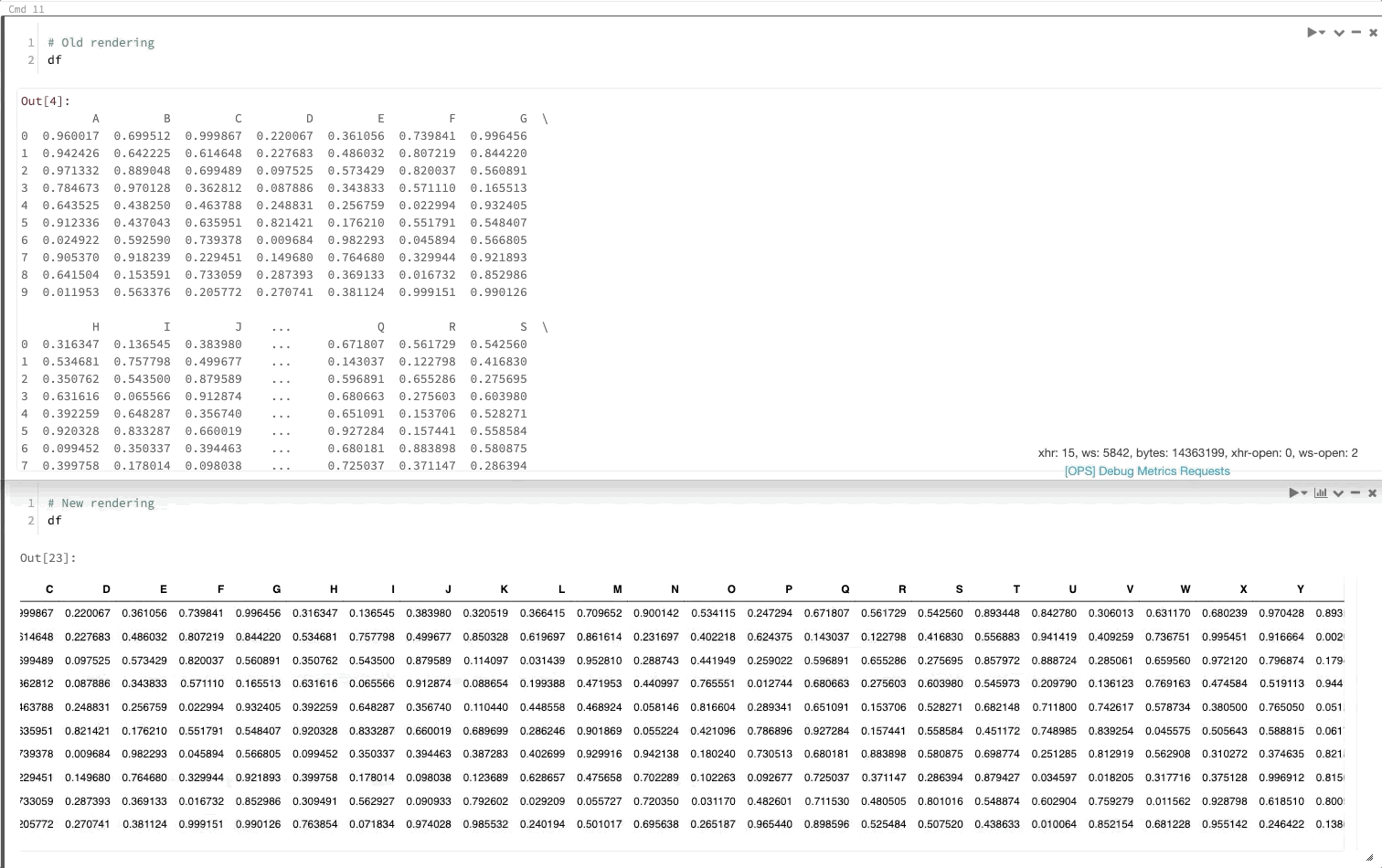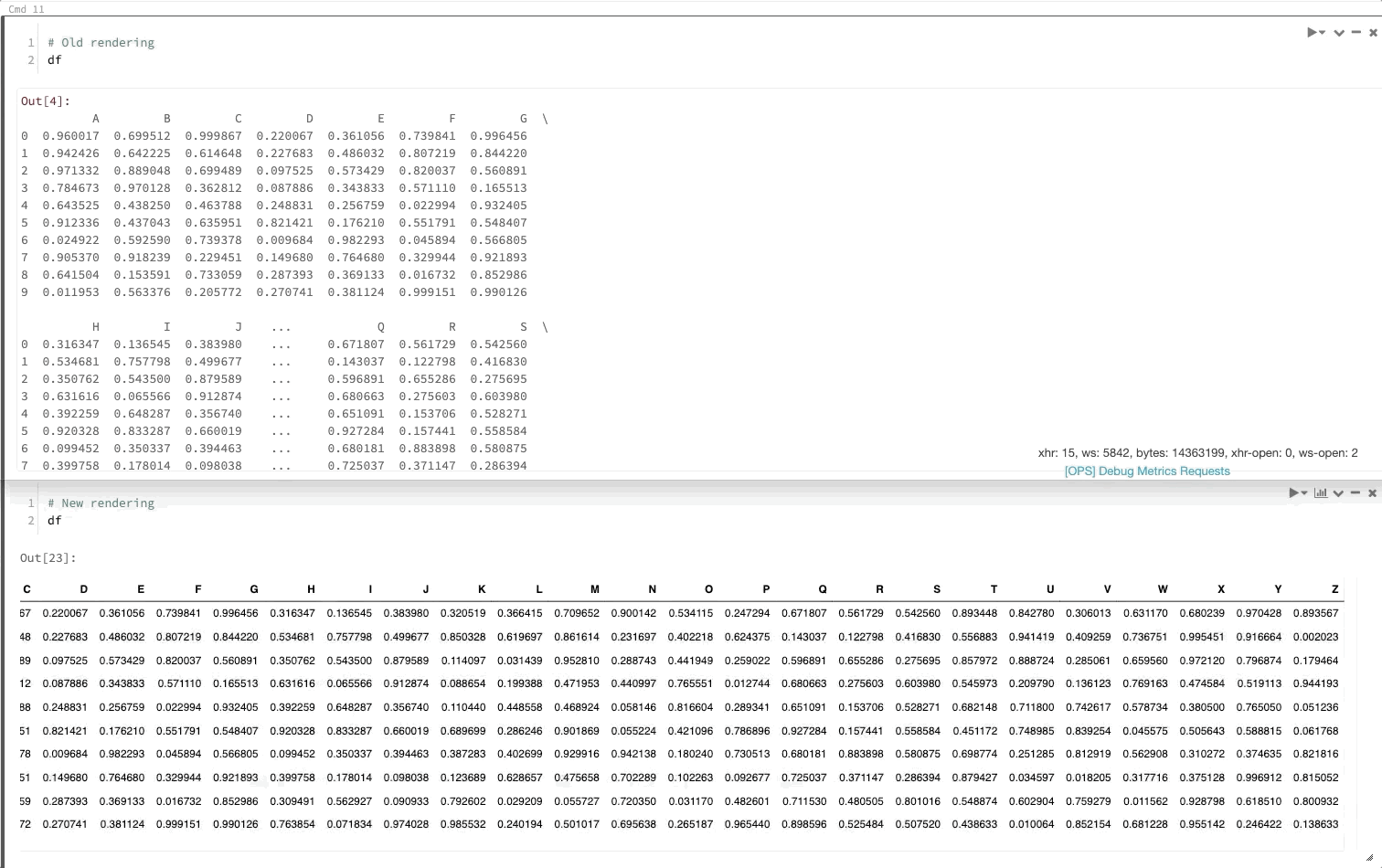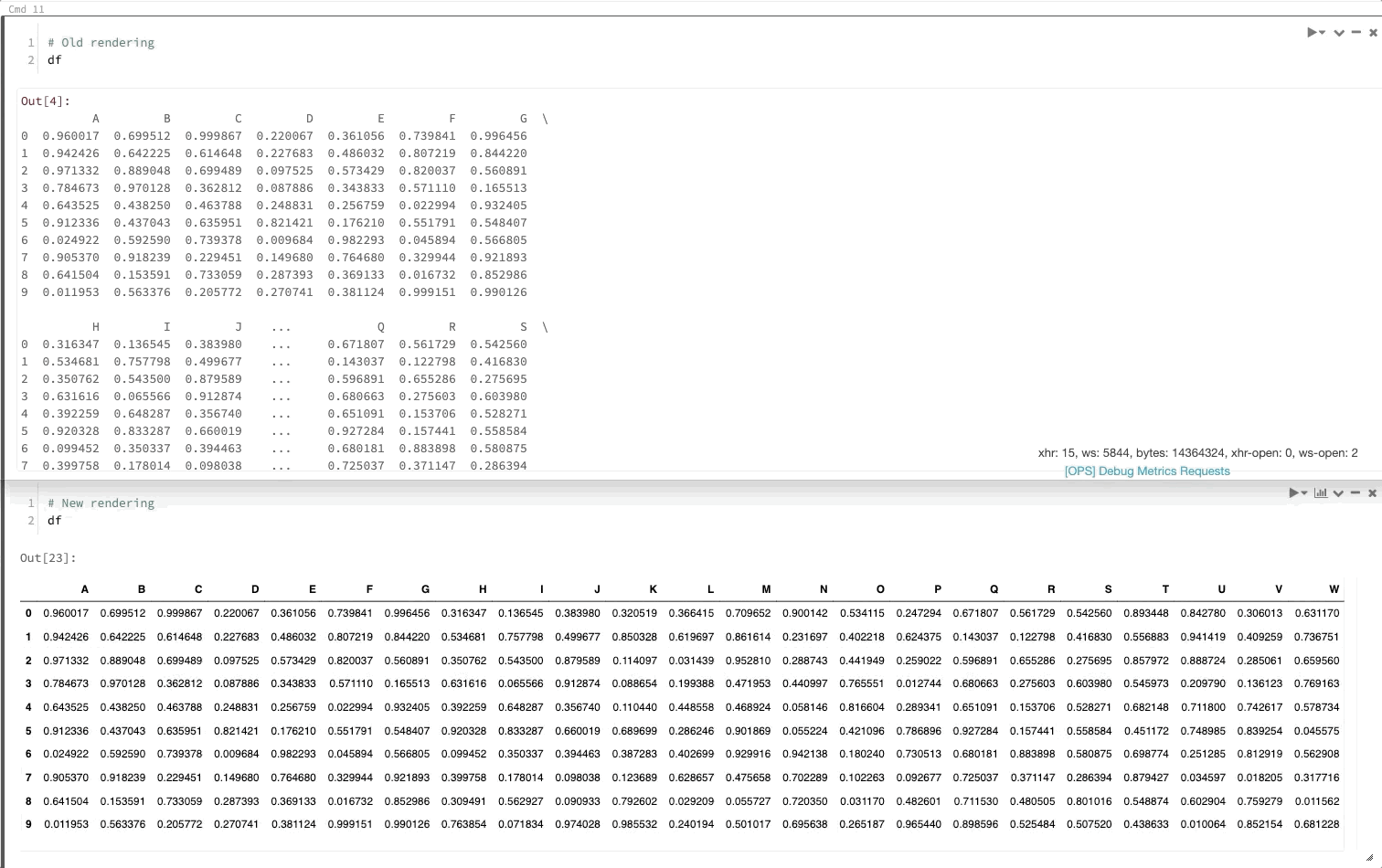
Пакет DataFrame Pandas преобразует данные для просмотра так же, как в Jupyter
30 июля — 6 августа 2019 г.: версия 2.103
Теперь при вызове DataFrame pandas он будет отображаться так же, как и в Jupyter.
Новые регионы
30 июля 2019 г.
Azure Databricks теперь доступен в следующих дополнительных регионах.
- Республика Корея, центральный регион
- Северная часть ЮАР
Обновлено ограничение на число подключений к хранилищу метаданных
16–23 июля 2019 г.: версия 2.102
Новые рабочие области Azure Databricks в регионах eastus, eastus2, centralus, westus, westus2, westeurope, northeurope будут иметь повышенный лимит подключений к хранилищу метаданных (250). Существующие рабочие области будут по-прежнему использовать текущее хранилище метаданных без перерывов с лимитом в 100 подключений.
Настройка разрешений для пулов (общедоступная предварительная версия)
16–23 июля 2019 г.: версия 2.102
Пользовательский интерфейс пула теперь поддерживает установку разрешений для пользователей, которые могут управлять пулами и которые могут подключать кластеры к пулам.
Дополнительные сведения см. в разделе "Разрешения пула".
Databricks Runtime 5.5 для Машинного обучения
15 июля 2019 г.
Databricks Runtime 5.5 ML построен на основе Databricks Runtime 5.5 LTS (EoS). Эта версия содержит множество популярных библиотек машинного обучения, включая TensorFlow, PyTorch, keras и XGBoost, а также распределенное обучение TensorFlow с помощью Horovod.
Этот выпуск включает следующие новые функции и усовершенствования:
- Добавлен пакет MLflow 1.0 для Python.
- Обновленные библиотеки машинного обучения
- TensorFlow обновлен с версии 1.12.0 до 1.13.1
- Выполнено обновление PyTorch с 0.4.1 до 1.1.0.
- Выполнено обновление scikit-learn с 0.19.1 до 0.20.3.
- Реализована работа с одним узлом для HorovodRunner.
Дополнительные сведения см. в разделе Databricks Runtime 5.5 LTS для машинного обучения (EoS).
Databricks Runtime 5.5
15 июля 2019 г.
Теперь доступна версия Databricks Runtime 5.5. Databricks Runtime 5.5 включает Apache Spark 2.4.3, обновленные библиотеки Python, R, Java и Scala, а также следующие новые функции:
- Delta Lake в Azure Databricks с автоматической оптимизацией уже общедоступно.
- Delta Lake в Azure Databricks повышает производительность запросов агрегатов min, max и count
- Ускорение конвейеров вывода модели с улучшенным источником данных в виде двоичного файла и скалярным итератором pandas UDF (общедоступная предварительная версия)
- API секретов в записных книжках R
Дополнительные сведения см. в разделе Databricks Runtime 5.5 LTS (EoS).
Поддержка экземпляров пула в режиме ожидания для быстрого запуска кластера (общедоступная предварительная версия)
9–11 июля 2019 г.: версия 2.101
Чтобы сократить время запуска кластера, Azure Databricks теперь поддерживает подключение кластера к предварительно определенному пулу простаивающих экземпляров. При подключении к пулу кластер выделяет узлы драйвера и рабочие узлы из пула. Если в пуле недостаточно простаивающих ресурсов для удовлетворения запроса кластера, пул расширяется путем выделения новых экземпляров от поставщика облачных служб. При завершении работы подключенного кластера используемые им экземпляры возвращаются в пул и могут быть повторно использованы другим кластером.
Azure Databricks не взимает плату (DBU), пока экземпляры остаются в пуле и бездействуют. Но к ним применяется оплата, предусмотренная поставщиком экземпляров. См. сведения о ценах.
Дополнительные сведения см . в справочнике по конфигурации пула.
Метрики Ganglia
9–11 июля 2019 г.: версия 2.101
Ganglia — это масштабируемая распределенная система мониторинга, которая теперь доступна в кластерах Azure Databricks. Метрики Ganglia помогают отслеживать производительность и работоспособность кластера. Просмотреть метрики Ganglia можно на странице со сведениями о кластере:
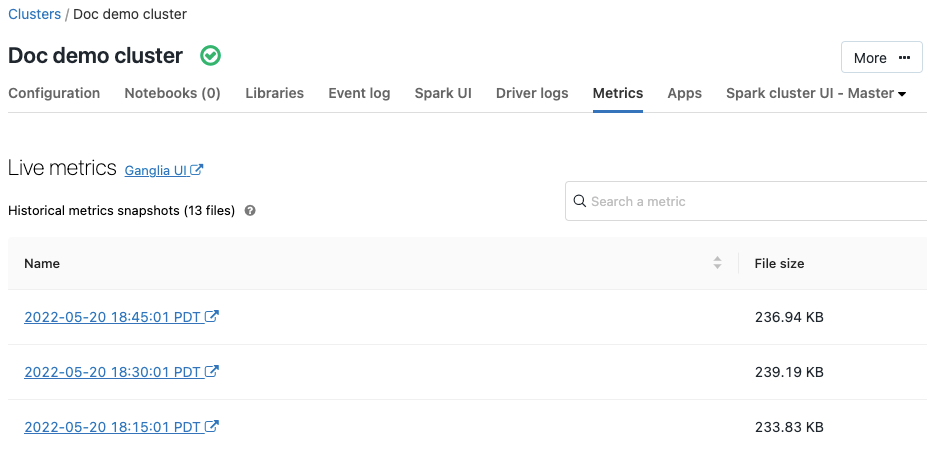
Дополнительные сведения об использовании и настройке метрик см. в разделе "Метрики Ganglia".
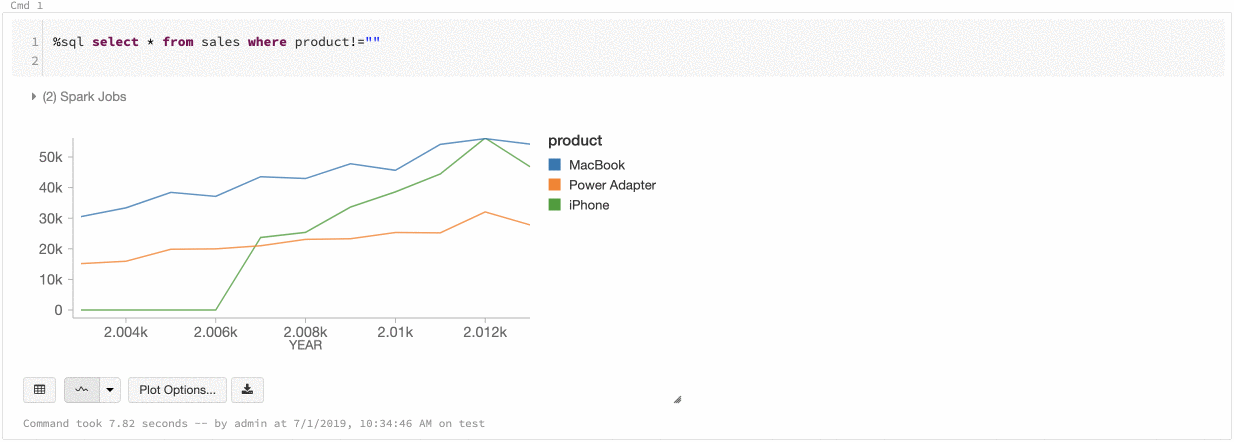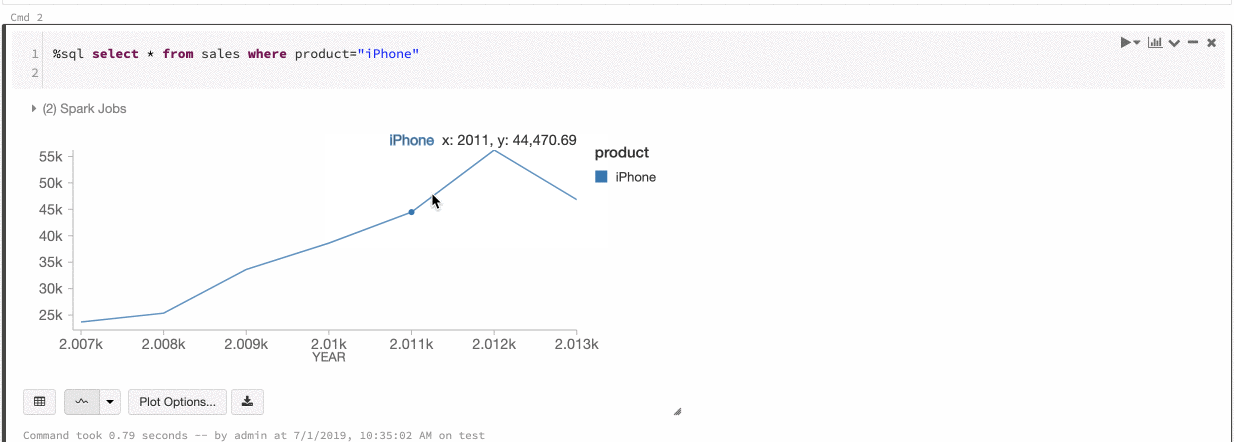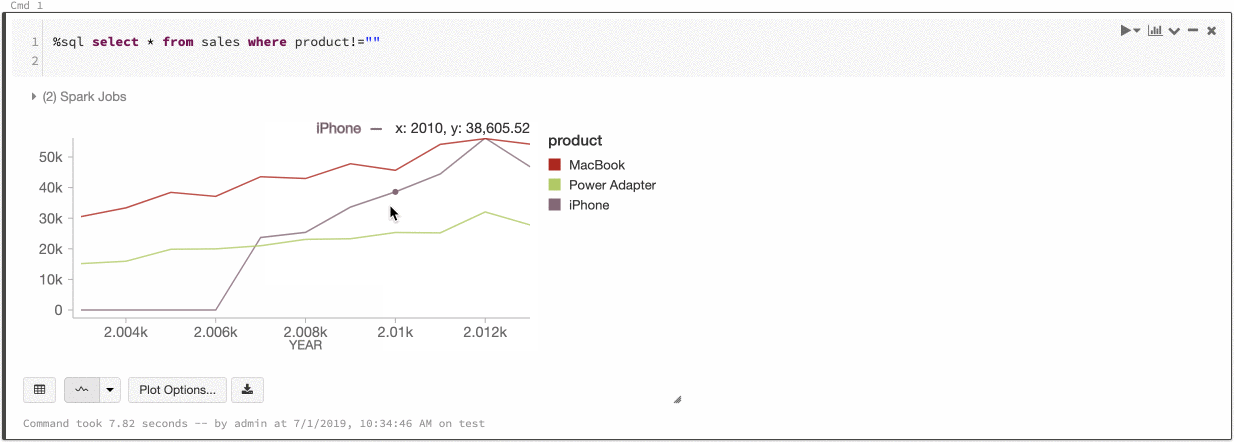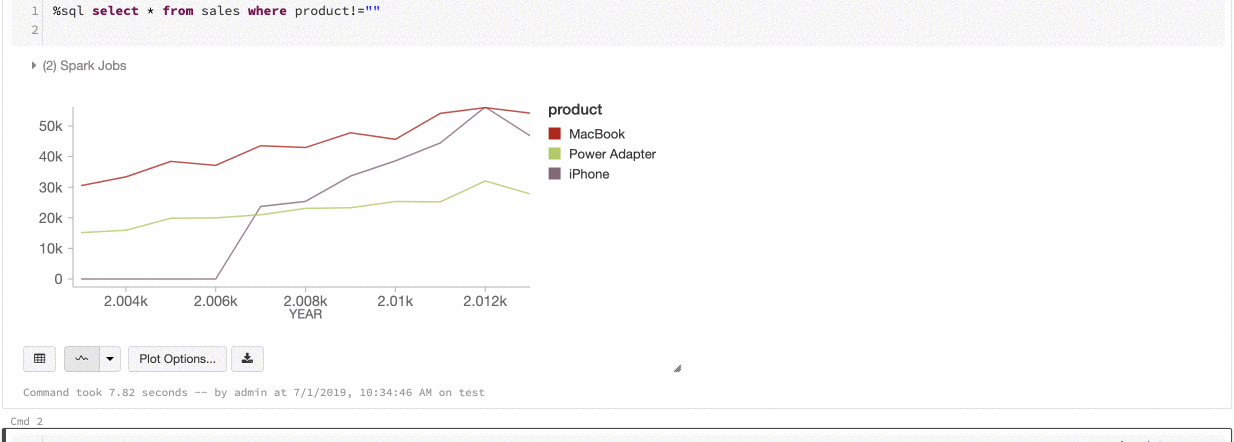
Глобальная согласованность цветов для рядов
9–11 июля 2019 г.: версия 2.101
Теперь вы можете указать, что цвета серии должны быть одинаковы во всех диаграммах в записной книжке. См. раздел Согласованность цветов в диаграммах.