Отправка заданий Spark в Машинное обучение Azure
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Машинное обучение Azure поддерживает автономные отправки заданий машинного обучения и создание конвейеров машинного обучения, которые включают несколько шагов рабочего процесса машинного обучения. Машинное обучение Azure обрабатывает как автономное создание задания Spark, так и создание повторно используемых компонентов Spark, которые Машинное обучение Azure конвейеры могут использовать. В этой статье вы узнаете, как отправить задания Spark с помощью следующих сведений:
- Пользовательский интерфейс Студия машинного обучения Azure
- Интерфейс командной строки службы "Машинное обучение Azure"
- пакет SDK для Машинного обучения Azure;
Дополнительные сведения об Apache Spark в концепциях Машинное обучение Azure см. в этом ресурсе.
Необходимые компоненты
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
- Подписка Azure; Если у вас нет подписки Azure, создайте бесплатную учетную запись перед началом работы.
- Рабочая область Машинного обучения Azure. Дополнительные сведения см. в разделе "Создание ресурсов рабочей области".
- Создайте Машинное обучение Azure вычислительный экземпляр.
- Установите интерфейс командной строки Машинное обучение Azure.
- (Необязательно): присоединенный пул Synapse Spark в рабочей области Машинное обучение Azure.
Примечание.
- Дополнительные сведения о доступе к ресурсам при использовании Машинное обучение Azure бессерверных вычислений Spark и присоединенного пула Synapse Spark см. в статье "Обеспечение доступа к ресурсам для заданий Spark".
- Машинное обучение Azure предоставляет общий пул квот, из которого все пользователи могут получить доступ к квоте вычислений для выполнения тестирования в течение ограниченного времени. При использовании бессерверных вычислений Spark Машинное обучение Azure позволяет получить доступ к этой общей квоте в течение короткого времени.
Присоединение управляемого удостоверения, назначаемого пользователем, с помощью CLI версии 2
- Создайте файл YAML, определяющий управляемое удостоверение, назначаемое пользователем, которое должно быть присоединено к рабочей области:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} --fileС параметром используйте файл YAML в командеaz ml workspace update, чтобы подключить назначенное пользователем управляемое удостоверение:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Присоединение управляемого удостоверения, назначаемого пользователем, с помощью ARMClient
- Установите
ARMClientпростое средство командной строки, которое вызывает API Azure Resource Manager. - Создайте JSON-файл, определяющий управляемое удостоверение, назначаемое пользователем, которое должно быть присоединено к рабочей области:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Чтобы подключить назначаемое пользователем управляемое удостоверение к рабочей области, выполните следующую команду в командной строке PowerShell или командной строке.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Примечание.
- Чтобы обеспечить успешное выполнение задания Spark, назначьте роли участника и участника данных BLOB-объектов хранилища в учетной записи хранения Azure, используемой для ввода и вывода данных, идентификатору, используемому заданием Spark.
- Доступ к общедоступной сети должен быть включен в рабочей области Azure Synapse, чтобы обеспечить успешное выполнение задания Spark с помощью подключенного пула Synapse Spark.
- В рабочей области Azure Synapse с управляемой виртуальной сетью, связанной с ней, если подключенный пул Synapse Spark указывает на пул Synapse Spark, необходимо настроить управляемую частную конечную точку в учетной записи хранения, чтобы обеспечить доступ к данным.
- Бессерверные вычисления Spark поддерживают Машинное обучение Azure управляемой виртуальной сети. Если управляемая сеть подготовлена для бессерверных вычислений Spark, соответствующие частные конечные точки для учетной записи хранения также должны быть подготовлены для обеспечения доступа к данным.
Отправка автономного задания Spark
После внесения необходимых изменений для параметризации скрипта Python можно использовать скрипт Python, разработанный с интерактивными данными для отправки пакетного задания, для обработки большего объема данных. Вы можете отправить пакетное задание обработки данных как автономное задание Spark.
Для задания Spark требуется скрипт Python, который принимает аргументы. Вы можете изменить код Python, изначально разработанный на основе интерактивных данных , для разработки этого скрипта. Пример скрипта Python показан здесь.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Примечание.
В этом примере кода Python используется pyspark.pandas. Поддерживается только среда выполнения Spark версии 3.2 или более поздней.
Этот скрипт принимает два аргумента, которые передают путь входных данных и выходной папки соответственно:
--titanic_data--wrangled_data
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
Чтобы создать задание, можно определить автономное задание Spark как файл спецификации YAML, который можно использовать в команде az ml job create с параметром --file . Определите эти свойства в файле YAML:
Свойства YAML в спецификации задания Spark
type— задано значениеspark.code— определяет расположение папки, содержащей исходный код и скрипты для этого задания.entry— определяет точку входа для задания. Он должен охватывать одно из следующих свойств:file— определяет имя скрипта Python, который служит точкой входа для задания.class_name— определяет имя класса, который серверы служат точкой входа для задания.
py_files— определяет список.zip,.eggили.pyфайлы, которые должны быть помещены вPYTHONPATHобъект , для успешного выполнения задания. Это необязательное свойство.jars— определяет список.jarфайлов для включения в драйвер Spark и исполнителяCLASSPATHдля успешного выполнения задания. Это необязательное свойство.files— определяет список файлов, которые должны быть скопированы в рабочий каталог каждого исполнителя для успешного выполнения задания. Это необязательное свойство.archives— определяет список архивов, которые должны быть извлечены в рабочий каталог каждого исполнителя для успешного выполнения задания. Это необязательное свойство.conf— определяет следующие свойства драйвера Spark и исполнителя:spark.driver.cores: число ядер для драйвера Spark.spark.driver.memory: выделенная память для драйвера Spark в гигабайтах (ГБ).spark.executor.cores: число ядер для исполнителя Spark.spark.executor.memory: выделение памяти для исполнителя Spark в гигабайтах (ГБ).spark.dynamicAllocation.enabled— следует ли динамически выделять исполнителей как значениеTrueилиFalseзначение.- Если включено динамическое выделение исполнителей, определите следующие свойства:
spark.dynamicAllocation.minExecutors— минимальное количество экземпляров исполнителей Spark для динамического выделения.spark.dynamicAllocation.maxExecutors— максимальное количество экземпляров исполнителей Spark для динамического выделения.
- Если динамическое выделение исполнителей отключено, определите это свойство:
spark.executor.instances— количество экземпляров исполнителя Spark.
environment— среда Машинное обучение Azure для запуска задания.args— аргументы командной строки, которые должны передаваться в скрипт точки входа задания Python. Ознакомьтесь с файлом спецификации YAML, приведенным здесь, например.resources— это свойство определяет ресурсы, используемые Машинное обучение Azure бессерверным вычислением Spark. В нем используются следующие свойства:instance_type— тип вычислительного экземпляра, используемый для пула Spark. В настоящее время поддерживаются следующие типы экземпляров:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version— определяет версию среды выполнения Spark. В настоящее время поддерживаются следующие версии среды выполнения Spark:3.33.4Внимание
Среда выполнения Azure Synapse для Apache Spark: объявления
- Среда выполнения Azure Synapse для Apache Spark 3.3:
- Дата объявления EOLA: 12 июля 2024 г.
- Дата окончания поддержки: 31 марта 2025 г. После этой даты среда выполнения будет отключена.
- Для непрерывной поддержки и оптимальной производительности рекомендуется перенести в Apache Spark 3.4.
- Среда выполнения Azure Synapse для Apache Spark 3.3:
Это пример YAML-файла:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute— это свойство определяет имя присоединенного пула Synapse Spark, как показано в этом примере:compute: mysparkpoolinputs— это свойство определяет входные данные для задания Spark. Входные данные для задания Spark могут быть литеральным значением или данными, хранящимися в файле или папке.- Литеральное значение может быть числом, логическим значением или строкой. Ниже приведены некоторые примеры:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Данные , хранящиеся в файле или папке, должны быть определены с помощью следующих свойств:
type— задайте для этого свойстваuri_fileзначение илиuri_folderдля входных данных, содержащихся в файле или папке соответственно.path— универсальный код ресурса (URI) входных данных, напримерazureml://,abfss://илиwasbs://.mode— задайте для этого свойства значениеdirect. В этом примере показано определение входных данных задания, которое можно называть следующим$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Литеральное значение может быть числом, логическим значением или строкой. Ниже приведены некоторые примеры:
outputs— это свойство определяет выходные данные задания Spark. Выходные данные для задания Spark можно записать в файл или расположение папки, которое определяется с помощью следующих трех свойств:type— это свойствоuri_fileuri_folderможно задать для записи выходных данных в файл или папку соответственно.path— это свойство определяет универсальный код ресурса (URI) выходного расположения, напримерazureml://,abfss://илиwasbs://.mode— задайте для этого свойства значениеdirect. В этом примере показано определение выходных данных задания, к которому можно ссылаться:${{outputs.wrangled_data}}outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity— это необязательное свойство определяет удостоверение, используемое для отправки этого задания. Он может иметьuser_identityиmanagedзначения. Если спецификация YAML не определяет удостоверение, задание Spark использует удостоверение по умолчанию.
Автономное задание Spark
В этом примере спецификации YAML показано автономное задание Spark. Он использует Машинное обучение Azure бессерверные вычисления Spark:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Примечание.
Чтобы использовать подключенный пул Synapse Spark, определите compute свойство в примере файла спецификации YAML, показанного resources ранее, а не свойство.
Вы можете использовать файлы YAML, показанные ранее в команде az ml job create , с --file параметром, чтобы создать автономное задание Spark, как показано ниже.
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Из следующей команды можно выполнить следующую команду:
- терминал вычислительного экземпляра Машинное обучение Azure.
- терминал Visual Studio Code, подключенный к Машинное обучение Azure вычислительному экземпляру.
- локальный компьютер с установленным Машинное обучение Azure CLI.
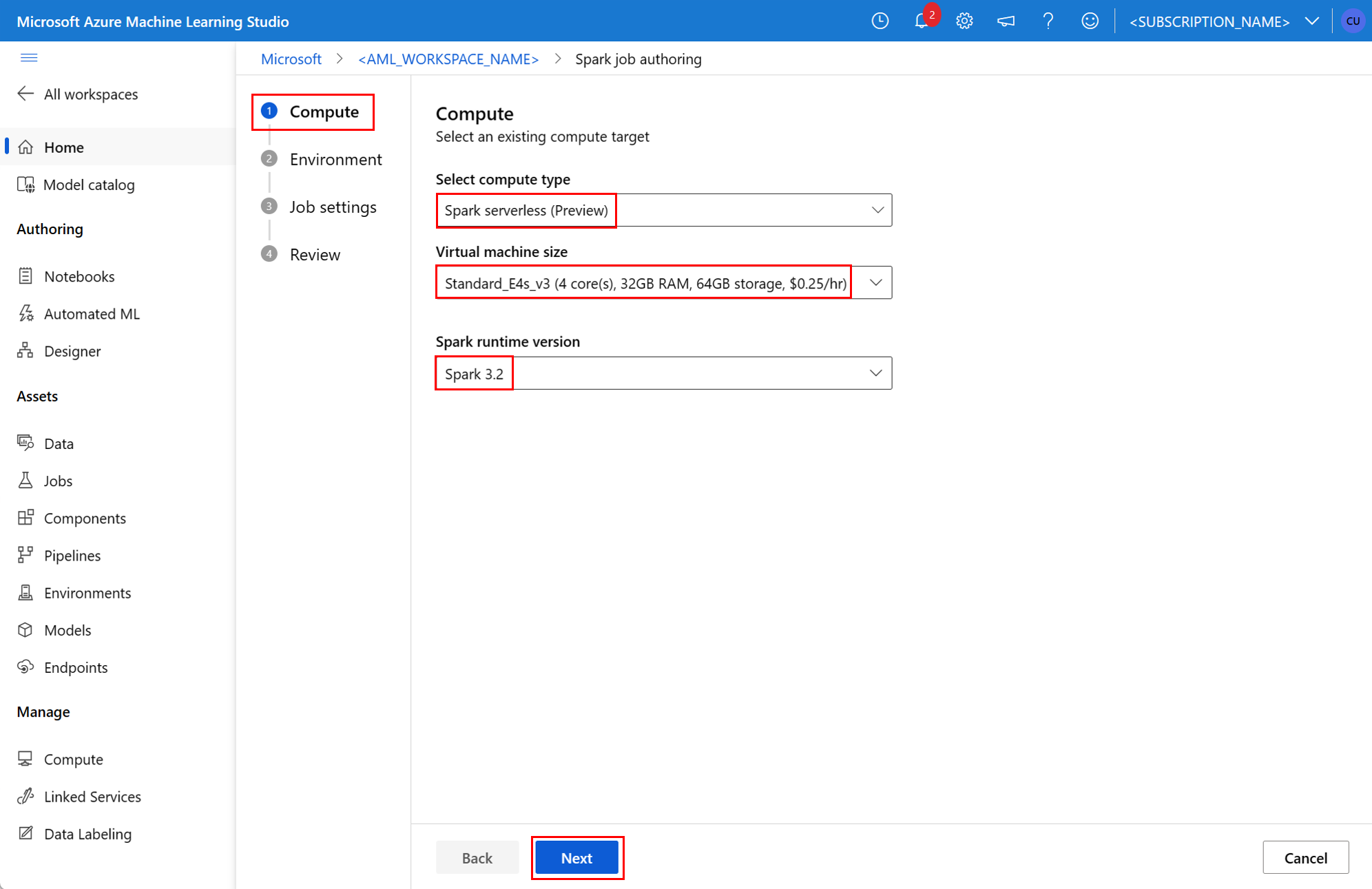
Компонент Spark в задании конвейера
Компонент Spark обеспечивает гибкость использования одного компонента в нескольких конвейерах Машинное обучение Azure в качестве шага конвейера.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
Синтаксис YAML для компонента Spark напоминает синтаксис YAML для спецификации задания Spark в большинстве случаев. Эти свойства определяются по-разному в спецификации YAML компонента Spark:
name— имя компонента Spark.version— версия компонента Spark.display_name— имя компонента Spark, отображаемого в пользовательском интерфейсе и в другом месте.description— описание компонента Spark.inputs— это свойство напоминаетinputsсвойство, описанное в синтаксисе YAML для спецификации задания Spark, за исключением того, что оно не определяетpathсвойство. В этом фрагменте кода показан пример свойства компонентаinputsSpark:inputs: titanic_data: type: uri_file mode: directoutputs— это свойство напоминаетoutputsсвойство, описанное в синтаксисе YAML для спецификации задания Spark, за исключением того, что оно не определяетpathсвойство. В этом фрагменте кода показан пример свойства компонентаoutputsSpark:outputs: wrangled_data: type: uri_folder mode: direct
Примечание.
Компонент Spark не определяет identitycompute свойства или resources свойства. Файл спецификации YAML конвейера определяет эти свойства.
Этот файл спецификации YAML содержит пример компонента Spark:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Компонент Spark, определенный в приведенном выше файле спецификации YAML, можно использовать в задании конвейера Машинное обучение Azure. Посетите ресурс схемы задания конвейера YAML, чтобы узнать больше о синтаксисе YAML, определяющем задание конвейера. В этом примере показан файл спецификации YAML для задания конвейера с компонентом Spark и Машинное обучение Azure бессерверным вычислением Spark:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Примечание.
Чтобы использовать подключенный пул Synapse Spark, определите compute свойство в примере файла спецификации YAML, показанного resources выше, вместо свойства.
Файл спецификации YAML, показанный выше в az ml job create команде, с помощью --file параметра, можно создать задание конвейера, как показано ниже.
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Из следующей команды можно выполнить следующую команду:
- терминал вычислительного экземпляра Машинное обучение Azure.
- терминал Visual Studio Code, подключенный к Машинное обучение Azure вычислительному экземпляру.
- локальный компьютер с установленным Машинное обучение Azure CLI.
Устранение неполадок заданий Spark
Чтобы устранить неполадки с заданием Spark, вы можете получить доступ к журналам, созданным для этого задания в Студия машинного обучения Azure. Чтобы просмотреть журналы для задания Spark, выполните следующие действия.
- Перейдите к заданиям слева на панели в пользовательском интерфейсе Студия машинного обучения Azure
- Выберите вкладку "Все задания"
- Выберите значение отображаемого имени для задания
- На странице сведений о задании перейдите на вкладку "Выходные данные и журналы"
- В проводнике разверните папку журналов и разверните папку azureml.
- Доступ к журналам заданий Spark в папках диспетчера драйверов и библиотек
Примечание.
Чтобы устранить неполадки с заданиями Spark, созданными во время интерактивной обработки данных в сеансе записной книжки, выберите сведения о задании в правом верхнем углу пользовательского интерфейса записной книжки. Задания Spark из интерактивного сеанса записной книжки создаются под именем записной книжки эксперимента.