Аналитика запросов в хранилище данных Fabric
Область применения:✅ конечная точка аналитики SQL и хранилище в Microsoft Fabric
В Microsoft Fabric функция аналитики запросов — это масштабируемое, устойчивое и расширяемое решение для улучшения возможностей аналитики SQL. С помощью данных журнала запросов, агрегированных аналитических сведений и доступа к фактическому тексту запроса можно анализировать и настраивать производительность запросов. QI предоставляет сведения о запросах, выполняемых только в контексте пользователя, системные запросы не учитываются.
Функция аналитики запросов предоставляет центральное расположение для исторических данных запросов и полезных сведений в течение 30 дней, помогая принимать обоснованные решения для повышения производительности конечной точки хранилища или аналитики SQL. При выполнении SQL-запроса в Microsoft Fabric функция аналитики запросов собирает и объединяет данные о выполнении, предоставляя ценные сведения. Полный текст запроса можно просмотреть для ролей администратора, участника и участника.
- Данные журнала: функция аналитики запросов сохраняет исторические данные о выполнении запросов, что позволяет отслеживать изменения производительности с течением времени. Системные запросы не хранятся в аналитике запросов.
- Агрегированная аналитика: функция аналитики запросов объединяет данные выполнения запросов в аналитические сведения, которые являются более активными, например определение длительных запросов или наиболее активных пользователей. Эти агрегаты основаны на фигуре запроса. Дополнительные сведения см. в статье о том, как аналогичные запросы, агрегированные для создания аналитических сведений?
Подготовка к работе
У вас должен быть доступ к конечной точке аналитики SQL или хранилищув рабочей области емкости Premium с разрешениями участника или более высокого уровня.
Когда требуется аналитика запросов?
Функция аналитики запросов решает несколько вопросов и проблем, связанных с производительностью запросов и оптимизацией базы данных, в том числе:
Анализ производительности запросов
- Что такое историческая производительность наших запросов?
- Существуют ли длительные запросы, требующие внимания?
- Можно ли определить запросы, вызывающие узкие места производительности?
- Был ли кэш использован для моих запросов?
- Какие запросы используют большую часть ЦП?
Оптимизация запросов и настройка
- Какие запросы часто выполняются и могут быть улучшены их производительность?
- Можно ли определить запросы, которые завершились сбоем или были отменены?
- Можно ли отслеживать изменения производительности запросов с течением времени?
- Есть ли запросы, которые последовательно выполняются плохо?
Мониторинг активности пользователей
- Кто отправил конкретный запрос?
- Кто является наиболее активными пользователями или пользователями с самыми длительными запросами?
Существует три системных представления для предоставления ответов на следующие вопросы:
queryinsights.exec_requests_history (Transact-SQL)
- Возвращает сведения о каждом завершенных sql-запросах или запросах.
queryinsights.exec_sessions_history (Transact-SQL)
- Возвращает сведения о часто выполняемых запросах.
queryinsights.long_running_queries (Transact-SQL)
- Возвращает сведения о запросах по времени выполнения запроса.
queryinsights.frequently_run_queries (Transact-SQL)
- Возвращает сведения о часто выполняемых запросах.
Где можно просмотреть аналитические сведения о запросах?
Автоматически созданные представления находятся в схеме в конечной queryinsights точке аналитики SQL и хранилище. Например, в обозревателе Fabric хранилища найдите представления аналитики запросов в разделах "Схемы", "Запросы", "Представления".
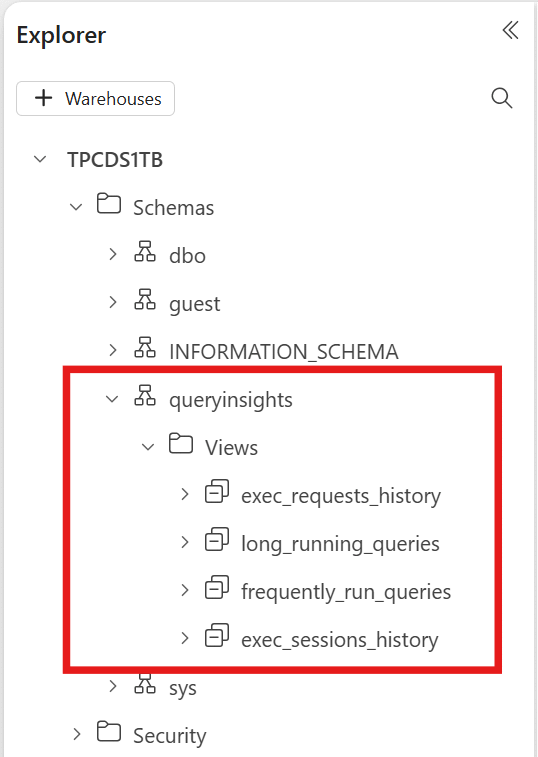
После завершения выполнения запроса вы увидите данные о выполнении в queryinsights представлениях конечной точки хранилища или аналитики SQL, к которому вы подключились. При выполнении запроса между базами данных в контексте WH_2запроса запрос отображается в аналитических сведениях о запросах WH_2. Завершенные запросы могут отображаться до 15 минут в аналитике запросов в зависимости от выполняемой параллельной рабочей нагрузки. Время, затраченное на появление запросов в аналитике запросов, увеличивается с увеличением числа одновременных запросов, выполняемых.
Как аналогичные запросы агрегируются для создания аналитических сведений?
Запросы считаются одинаковыми в аналитике запросов, если запросы имеют одну и ту же форму, даже если предикаты могут отличаться.
Столбец в представлениях можно использовать query hash для анализа аналогичных запросов и детализации до каждого выполнения.
Например, следующие запросы считаются одинаковыми после параметризации их предикатов:
SELECT * FROM Orders
WHERE OrderDate BETWEEN '1996-07-01' AND '1996-07-31';
и
SELECT * FROM Orders
WHERE OrderDate BETWEEN '2000-07-01' AND '2006-07-31';
Примеры
Определение запросов, выполняемых вами за последние 30 минут
Следующий запрос использует queryinsights.exec_requests_history и встроенную USER_NAME() функцию, которая возвращает текущее имя пользователя сеанса.
SELECT * FROM queryinsights.exec_requests_history
WHERE start_time >= DATEADD(MINUTE, -30, GETUTCDATE())
AND login_name = USER_NAME();
Определение наиболее потребляющих ЦП запросов по времени ЦП
Следующий запрос возвращает первые 100 запросов по выделенному времени ЦП.
SELECT TOP 100 distributed_statement_id, query_hash, allocated_cpu_time_ms, label, command
FROM queryinsights.exec_requests_history
ORDER BY allocated_cpu_time_ms DESC;
Определение того, какие запросы сканируют большинство данных из удаленного, а не кэша
Вы можете определить, замедляется ли сканирование больших данных во время выполнения запроса и принятия решений по настройке кода запроса соответствующим образом. Этот анализ позволяет сравнить различные выполнения запросов и определить, является ли дисперсию в количестве сканированных данных причиной изменений производительности.
Кроме того, вы можете оценить использование кэша, проверив сумму data_scanned_memory_mb и data_scanned_disk_mbсравнивая его с data_scanned_remote_storage_mb прошлыми выполнениями.
Примечание.
Данные, сканированные значения, могут не учитывать данные, перемещаемые на промежуточных этапах выполнения запроса. В некоторых случаях размер перемещаемых данных и ЦП, необходимых для обработки, может быть больше, чем указывает сканированное значение данных.
SELECT distributed_statement_id, query_hash, data_scanned_remote_storage_mb, data_scanned_memory_mb, data_scanned_disk_mb, label, command
FROM queryinsights.exec_requests_history
ORDER BY data_scanned_remote_storage_mb DESC;
Определение наиболее часто выполняемых запросов с помощью подстроки в тексте запроса
Следующий запрос возвращает последние запросы, соответствующие определенной строке, упорядоченные по количеству успешных выполнений по убыванию.
SELECT * FROM queryinsights.frequently_run_queries
WHERE last_run_command LIKE '%<some_label>%'
ORDER BY number_of_successful_runs DESC;
Определение длительных запросов с помощью подстроки в тексте запроса
Следующий запрос возвращает запросы, соответствующие определенной строке, упорядоченные по времени выполнения медианного запроса по убыванию.
SELECT * FROM queryinsights.long_running_queries
WHERE last_run_command LIKE '%<some_label>%'
ORDER BY median_total_elapsed_time_ms DESC;