Группирование или сводка строк
В Power Query можно группировать значения в разных строках в одно значение, группируя строки в соответствии со значениями в одном или нескольких столбцах. Вы можете выбрать один из двух типов операций группирования:
Группировки столбцов.
Группировки строк.
В этом руководстве вы используете следующую примерную таблицу.
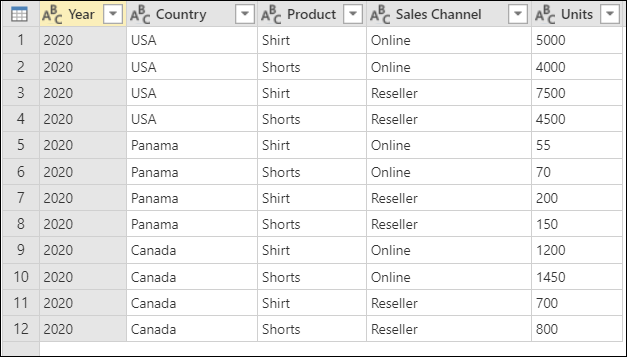
Снимок экрана: таблица со столбцами, показывающими Год (2020), Страна (США, Панама или Канада), Продукт (рубашка или шорты), Канал продаж (онлайн или торговый посредник) и Единицы (различные значения от 55 до 7500)
Где найти группу по кнопке
Группу можно найти, нажав кнопку в трех местах:
На вкладке Главная в группе Преобразования.

На вкладке Преобразования в группе таблицы.
В контекстном меню, щелкнув правой кнопкой мыши, выберите столбцы.
Использование статистической функции для группировки по одному или нескольким столбцам
В этом примере цель состоит в том, чтобы суммировать общее количество проданных единиц на уровне страны и канала продаж. Вы используете столбцы Country и Sales Channel для выполнения группы по операции.
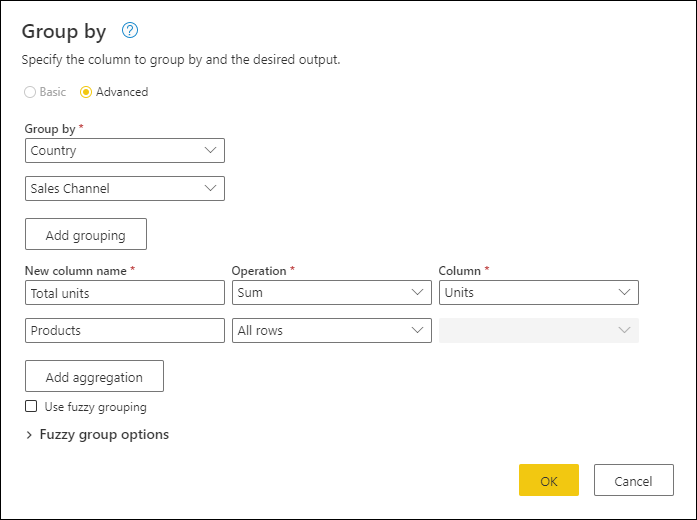
- Выберите группировать по на вкладке "Главная".
- Выберите параметр Advanced, чтобы выбрать несколько столбцов для группировки.
- Выберите столбец Страна.
- Выберите Добавить группирование.
- Выберите столбец канала продаж.
- В Новый столбец имявведите Общий объем, в операциявыберите Суммаи в столбецвыберите Единицы.
- Нажмите кнопку ОК
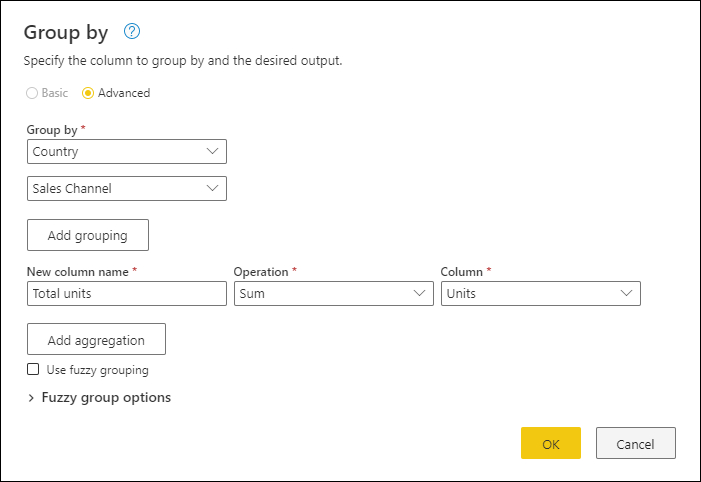
Эта операция предоставляет следующую таблицу.

Доступные операции
С помощью функции Group by доступные операции можно классифицировать двумя способами:
- Операция уровня строк
- Операция уровня столбца
В следующей таблице описывается каждая из этих операций.
| Имя операции | Категория | Описание |
|---|---|---|
| Сумма | Операция столбца | Суммирует все значения из столбца |
| среднее | Операции с колонками | Вычисляет среднее значение из столбца |
| Медиана | Операция с столбцом | Вычисляет медиану из столбца |
| мин | Операция с колонками | Вычисляет минимальное значение из столбца |
| Max | Операция со столбцом | Вычисляет максимальное значение из столбца |
| процентиль | Операции с колонкой | Вычисляет процентиль, используя входное значение от 0 до 100 из столбца. |
| Подсчет уникальных значений | Операция с колонкой | Вычисляет количество отдельных значений из столбца |
| Подсчет строк | Операция со строками | Вычисляет общее количество строк из заданной группы |
| Число отдельных строк | Строковая операция | Вычисляет количество отдельных строк из заданной группы. |
| все строки | Операция над строками | Выводит все сгруппированные строки в табличном значении без агрегирования |
Заметка
Операции Count уникальных значений и Percentile доступны только в Power Query Online.
Выполните операцию группировки по одному или нескольким столбцам
Начиная от исходного образца, в этом примере создается столбец с общим количеством единиц и двумя другими столбцами, которые предоставляют имя и количество проданных единиц для продукта с наилучшими показателями, обобщенные на уровне страны и канала продаж.

Используйте следующие столбцы для группировки по столбцам:
- Страна
- Канал продаж
Создайте два новых столбца, выполнив следующие действия.
- Агрегируйте столбец единиц, используя операцию суммы . Присвойте этому столбцу имя Всего единиц.
- Добавьте новый столбец продуктов с помощью операции все строки.
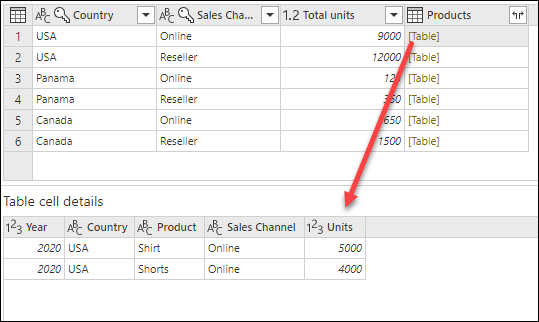
После завершения операции обратите внимание, что столбец Products имеет значения [Table] в каждой ячейке. Каждое значение [Таблица] содержит все строки, сгруппированные по столбцам Country и Sales Channel из исходной таблицы. Вы можете выбрать пустое пространство внутри ячейки, чтобы просмотреть содержимое таблицы в нижней части диалогового окна.
Заметка
Панель предварительного просмотра сведений может не отображать все строки, которые использовались для операции с группировкой. Вы можете выбрать значение [Таблица], чтобы просмотреть все строки, относящиеся к соответствующей операции по группе.
Затем вам необходимо извлечь строку с наибольшим значением в столбце единиц в новой колонке Products и назвать эту новую колонку Лучший продукт.
Извлеките информацию о продукте с наилучшими характеристиками
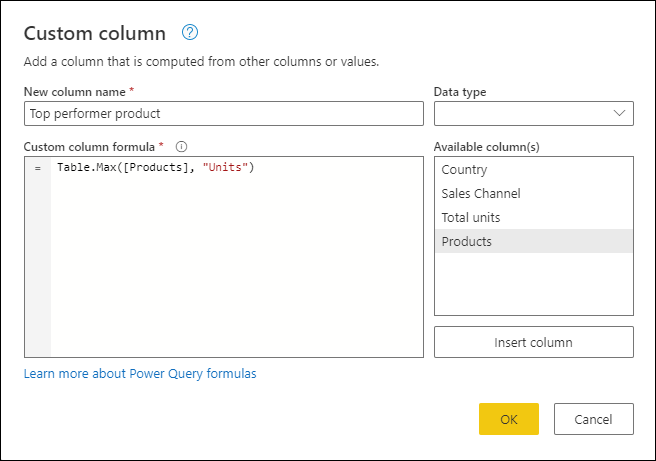
При использовании нового столбца Products со значениями [Таблица] создайте новый настраиваемый столбец, перейдя на вкладку Добавить столбец на ленте и выбрав Настраиваемый столбец из группы Общие.
![]()
Присвойте новому столбцу продукт лучшего исполнителя. Введите формулу Table.Max([Products], "Units" ) в разделе Формула настраиваемого столбца.
Результат этой формулы создает новый столбец со значениями [Record]. Эти значения записей по сути являются таблицей с одной строкой. Эти записи содержат строку с максимальным значением столбца единиц
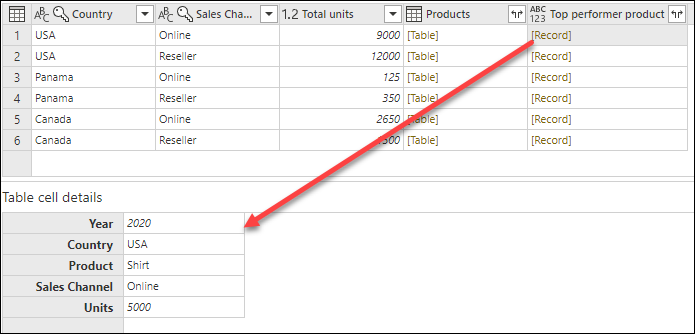
С помощью этого нового столбца продукта
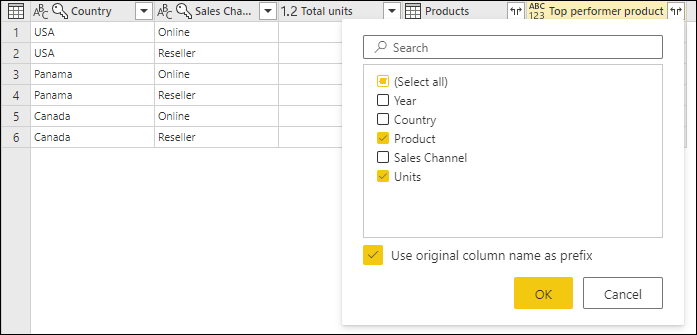
После удаления столбца Products и задания типа данных для обоих недавно развернутых столбцов результат будет выглядеть следующим образом.

Нечеткое группирование
Заметка
Следующая функция доступна только в Power Query Online.
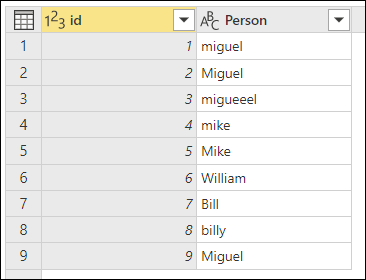
Чтобы продемонстрировать, как выполнить "нечеткое группирование", рассмотрим пример таблицы, показанной на следующем рисунке.
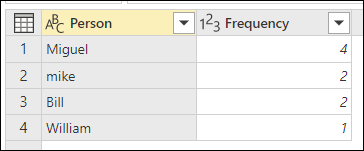
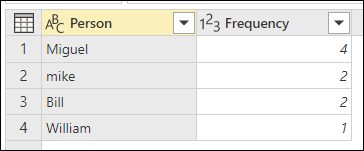
Цель нечеткой группировки — выполнить операцию по группе, которая использует приблизительный алгоритм сопоставления для текстовых строк. Power Query использует алгоритм сходства Jaccard для измерения сходства между парами экземпляров. Затем она применяет агломеративную иерархическую кластеризацию для объединения экземпляров. На следующем рисунке показаны ожидаемые выходные данные, в которых таблица сгруппирована по столбцу Person.
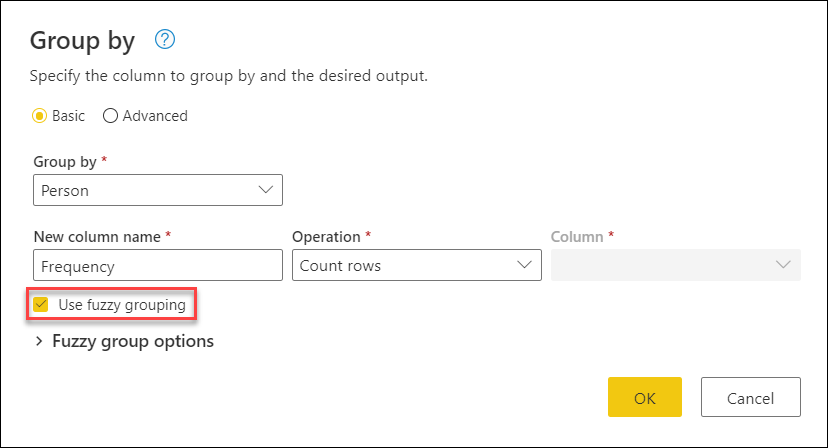
Чтобы выполнить нечеткое группирование, выполните те же действия, которые ранее описаны в этой статье. Единственное различие заключается в том, что на этот раз в диалоговом окне "Группа по" вы выбираете флажок Использовать нечеткое группирование.
Для каждой группы строк Power Query выбирает наиболее частый экземпляр в качестве канонического экземпляра. Если несколько экземпляров встречаются с одинаковой частотой, Power Query выбирает первый. После нажатия ОК в диалоговом окне "Группировать по" вы получите ожидаемый результат.
Однако у вас больше контроля над операцией нечеткой группировки путем расширения опций нечеткой группы.
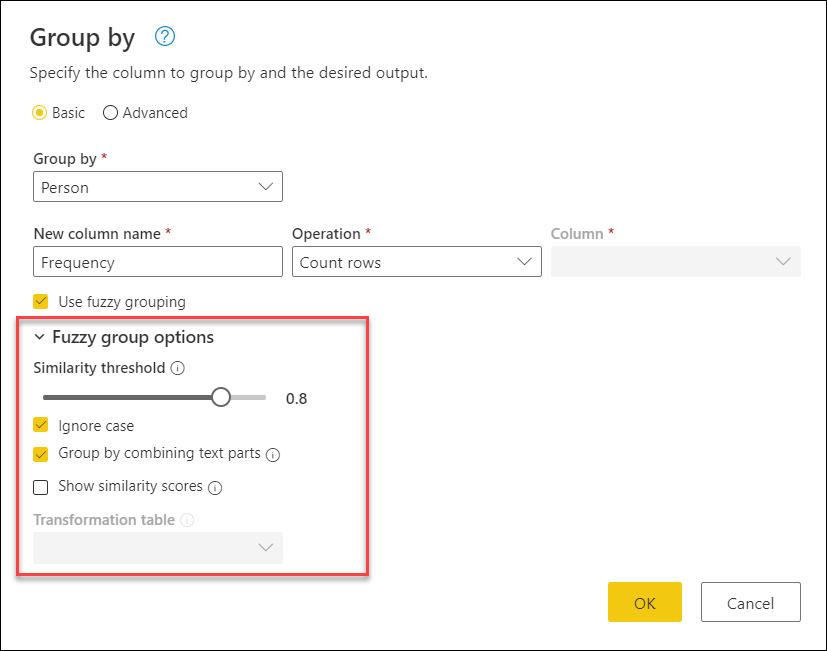
Для нечеткой группировки доступны следующие параметры:
- порог сходства (необязательно): этот параметр указывает, как должны быть сгруппированы два аналогичных значения. Минимальный параметр нуля (0) приводит к группировке всех значений. Максимальное значение 1 позволяет сгруппировать только значения, которые совпадают точно. Значение по умолчанию — 0.8.
- Игнорировать регистр: Когда текстовые строки сравниваются, регистр игнорируется. Этот параметр включен по умолчанию.
- Сгруппировать , объединив текстовые части: алгоритм пытается объединить текстовые части (например, объединение Micro и Soft в Microsoft) для группировки значений.
- Показать оценки сходства: отображение показателей сходства между входными значениями и вычисляемых репрезентативных значений после нечеткой группировки. Требуется добавление операции, такой как все строки, для демонстрации этой информации на уровне каждой строки.
- таблица преобразования (необязательно): можно выбрать таблицу преобразования, которая сопоставляет значения (например, сопоставление MSFT с Microsoft) для группировки их вместе.
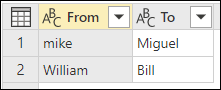
В этом примере таблица преобразования используется для демонстрации того, как можно сопоставить значения. Таблица преобразования содержит два столбца:
- из: текстовая строка для поиска в вашей таблице.
- Для: текстовая строка, используемая для замены текстовой строки в столбце из столбца.
На следующем рисунке показана таблица преобразования, используемая в этом примере.
Важный
Важно, чтобы в таблице преобразования были одинаковые столбцы и имена столбцов, как показано на предыдущем изображении (они должны быть помечены как "From" и "To"). В противном случае Power Query не распознает таблицу как таблицу преобразования.
Вернитесь в диалоговое окно "Группа ", разверните параметры группы Fuzzy, измените операцию из "Count rows" на "All rows", включите опцию "Показать оценки сходства", а затем выберите раскрывающееся меню "Таблица преобразования".
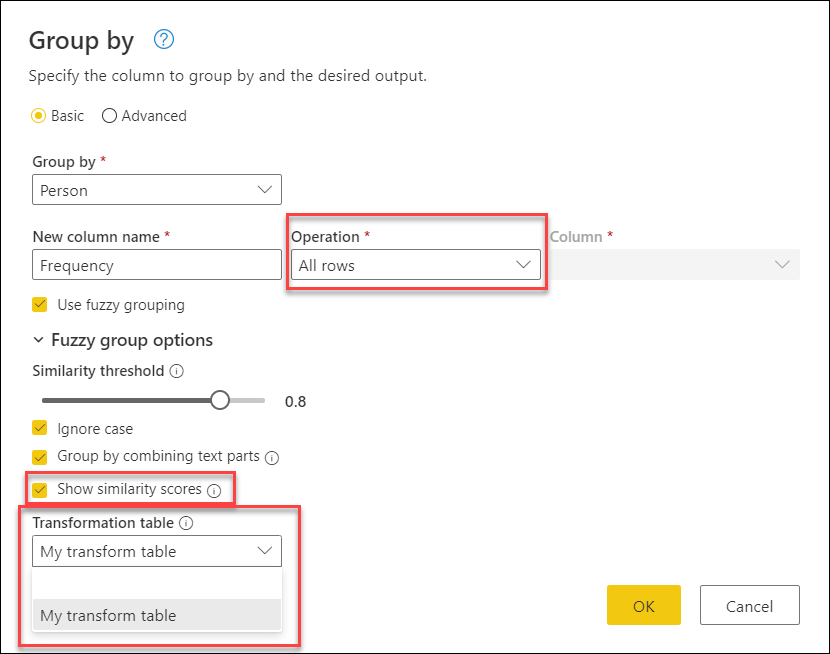
После выбора таблицы преобразования нажмите кнопку ОК. Результат этой операции дает следующие сведения:
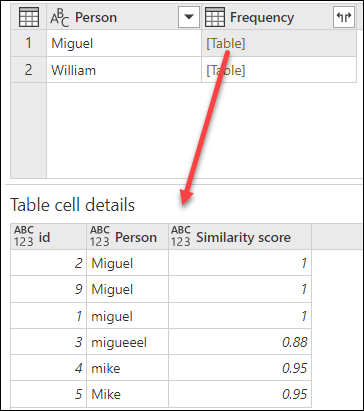
В этом примере включен параметр
Оценка сходства также отображается в табличном значении рядом с столбцом person, который отражает точное группирование значений и их соответствующие оценки сходства. Этот столбец можно развернуть при необходимости или использовать значения из новых столбцов частоты для других типов преобразований.
Заметка
При группировке по нескольким столбцам таблица преобразования выполняет операцию замены во всех столбцах, если при замене значения увеличивается оценка сходства.
Дополнительные сведения о том, как работают таблицы преобразования, см. в принципах таблиц преобразования.