Сериализация модели данных в разные хранилища (предварительная версия)
Чтобы модель данных хранилась в базе данных, ее необходимо преобразовать в формат, который может понять база данных. Для разных баз данных требуются разные схемы и форматы хранилища. Некоторые из них имеют строгую схему, которая должна соответствовать, а другие позволяют пользователю определять схему.
Параметры сопоставления
Соединители хранилища векторов, предоставляемые семантическим ядром, предлагают различные способы достижения этого сопоставления.
Встроенные карты
Соединители хранилища векторов, предоставляемые Семантическим ядром, имеют встроенные мапперы, которые сопоставляют модель данных со схемами базы данных и обратно. Для получения дополнительной информации о том, как встроенные мапперы сопоставляют данные для каждой базы данных, см. страницу для каждого соединителя.
Пользовательские мапперы
Соединители хранилища векторов, предоставляемые семантическим ядром, поддерживают возможность настройки пользовательских мапперов в сочетании с VectorStoreRecordDefinition. В этом случае VectorStoreRecordDefinition может отличаться от предоставленной модели данных.
VectorStoreRecordDefinition используется для определения схемы базы данных, а модель данных используется разработчиком для взаимодействия с хранилищем векторов.
В этом случае для сопоставления из модели данных с пользовательской схемой базы данных, определенной VectorStoreRecordDefinition, требуется настраиваемое средство сопоставления.
Совет
См. , как создать настраиваемую схему для соединителя Vector Store пример создания собственного пользовательского сопоставителя.
Чтобы модель данных была определена как класс или определение , хранящееся в базе данных, ее необходимо сериализовать в формате, который может понять база данных.
Можно выполнить два способа, используя встроенную сериализацию, предоставляемую семантической ядром, или предоставив собственную логику сериализации.
На следующих двух схемах показаны потоки, связанные с процессами сериализации и десериализации моделей данных в модель хранения и из нее.
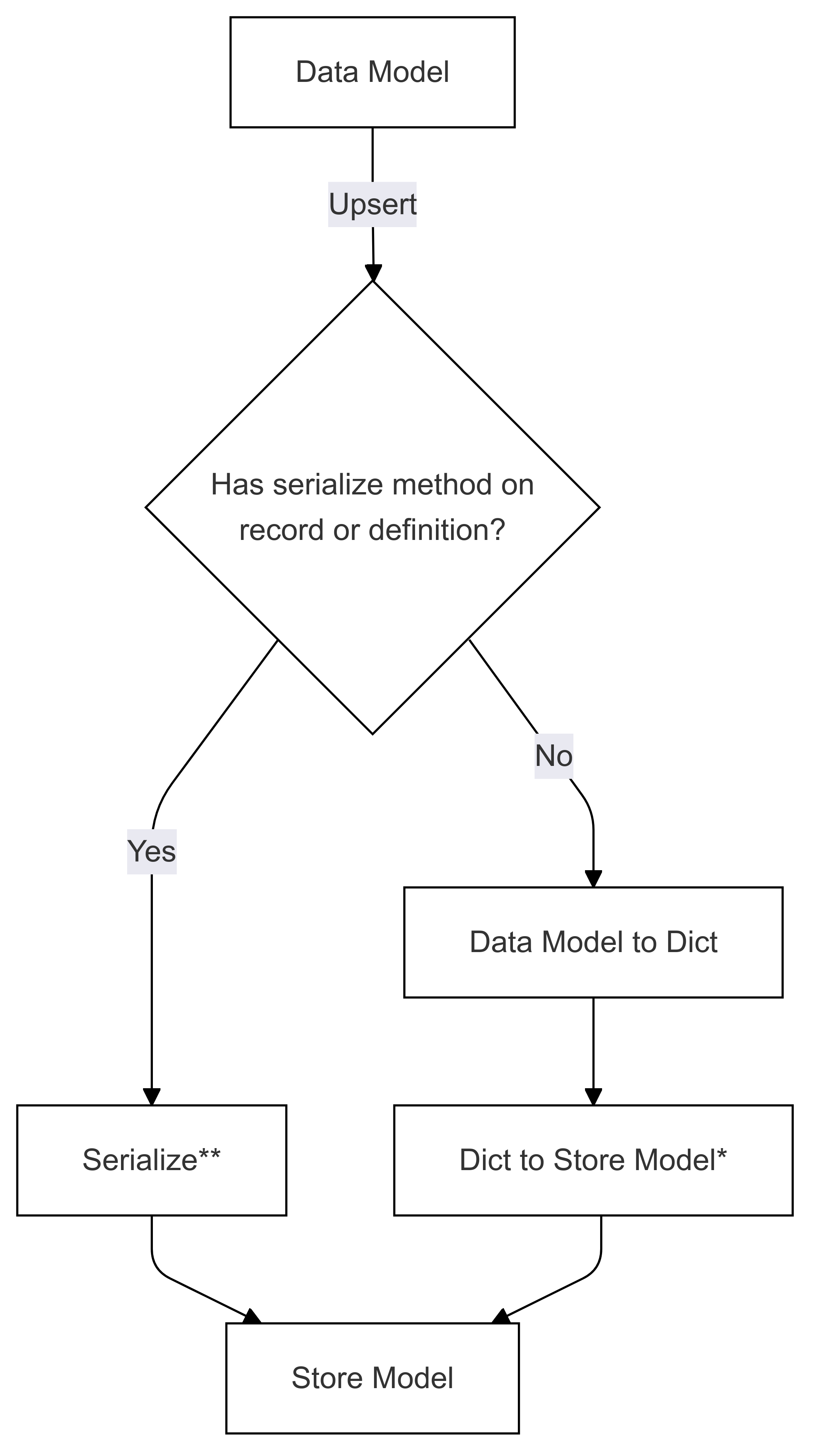
Поток сериализации (используется в Upsert)
Поток десериализации (используется в Get и Search)
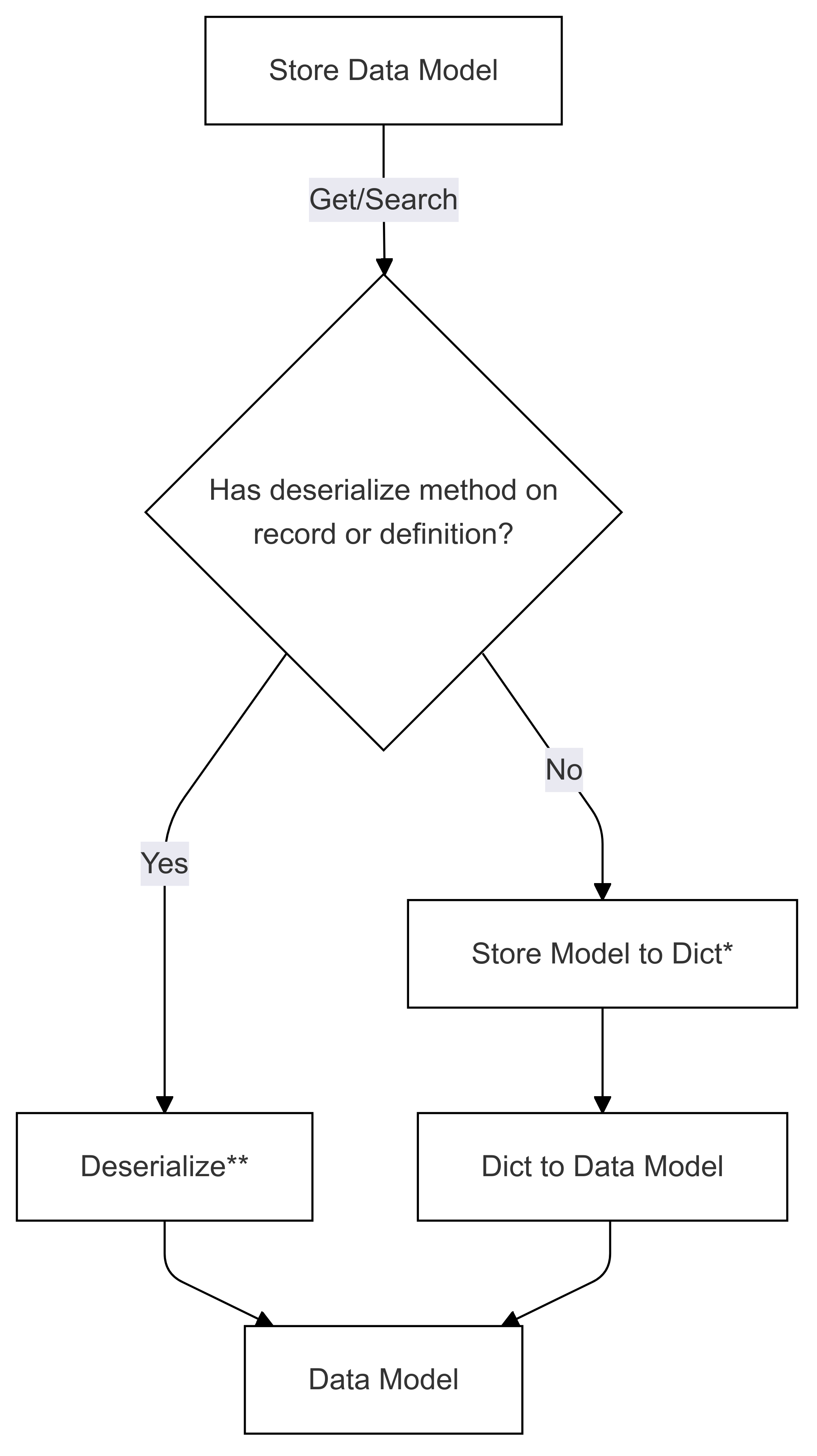
Шаги, помеченные как * (на обеих схемах), реализуются разработчиком определенного соединителя и отличаются для каждого хранилища. Шаги, помеченные как ** (на обеих схемах), предоставляются в виде метода записи или как часть определения записи, при этом это всегда выполняется пользователем, см. Direct Serialization для получения более подробной информации.
(Де)сериализация: подходы
Прямая сериализация (модель данных в модель хранилища)
Прямая сериализация — лучший способ обеспечить полный контроль над сериализацией моделей и оптимизацией производительности. Недостатком является то, что это относится к хранилищу данных, и поэтому при использовании этого не так просто переключаться между различными хранилищами с одной и той же моделью данных.
Это можно использовать, реализуя метод, который следует протоколу SerializeMethodProtocol в модели данных, или добавив функции, которые соответствуют определению записи SerializeFunctionProtocol, их можно найти в semantic_kernel/data/vector_store_model_protocols.py.
При наличии одной из этих функций она будет использоваться для непосредственной сериализации модели данных в модель хранилища.
Вы можете даже реализовать только один из двух методов и использовать встроенную (де)сериализацию для противоположного направления. Это может быть полезно, например, при работе с коллекцией, созданной вне вашего контроля, когда вам нужно настроить процесс ее десериализации (и вы все равно не можете сделать upsert).
Встроенная сериализация (de)сериализация (модель данных для диктовки и дикта для хранения модели и наоборот)
Встроенная сериализация выполняется путем преобразования модели данных в словарь, а затем сериализации ее в модель, которая понимает, для каждого хранилища, которое отличается и определяется как часть встроенного соединителя. Десериализация выполняется в обратном порядке.
Шаг сериализации 1. Модель данных в диктовку
В зависимости от того, какая модель данных у вас есть, действия выполняются разными способами. Существует четыре способа сериализации модели данных в словарь:
- метод
to_dictдля определения (соответствует атрибуту to_dict в модели данных, следуяToDictFunctionProtocol) - Проверьте, является ли запись
ToDictMethodProtocolи используйте методto_dict - Проверьте, является ли запись моделью Pydantic, и воспользуйтесь
model_dumpэтой модели. Более подробную информацию см. в примечании ниже. - прокрутить поля в определении и создать словарь
Шаг сериализации 2. Дикт для хранения модели
Метод должен быть предоставлен коннектором для преобразования словаря в модель хранилища. Это делается разработчиком соединителя и отличается для каждого магазина.
Шаг 1 десериализации. Хранение модели в диктовку
Метод должен быть предоставлен соединителем для преобразования модели хранилища в словарь. Это делается разработчиком соединителя и отличается для каждого магазина.
Шаг 2 десериализации. Дикт в модель данных
Десериализация выполняется в обратном порядке и пробует следующие варианты:
- метод
from_dictопределения (соответствует атрибуту from_dict модели данных, следуяFromDictFunctionProtocol) - Проверьте, является ли запись типа
FromDictMethodProtocol, и используйте методfrom_dict - Проверьте, является ли запись моделью Pydantic и используйте
model_validateэтой модели, см. примечание ниже для получения дополнительной информации. - прокрутите поля в определении и задайте значения, затем этот дикт передается в конструктор модели данных в качестве именованных аргументов (если модель данных не является диктовкой, в этом случае возвращается как есть)
Заметка
Использование Pydantic с встроенной сериализацией
При определении модели с помощью Pydantic BaseModel он будет использовать model_dump методы и model_validate методы для сериализации и десериализации модели данных в диктовку и из него. Это делается с помощью метода model_dump без каких-либо параметров; если вы хотите это контролировать, рассмотрите возможность внедрения ToDictMethodProtocol в модель данных, поскольку это проверяется первым.
Сериализация векторов
Если у вас есть вектор в модели данных, он должен быть списком с плавающей запятой или списком ints, так как это то, что большинство магазинов требуется, если вы хотите, чтобы класс сохранял вектор в другом формате, можно использовать serialize_function и deserialize_function определить в заметке VectorStoreRecordVectorField . Например, для массива numpy можно использовать следующую заметку:
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
Если вы используете векторное хранилище, которое может обрабатывать собственные массивы numpy, и вы не хотите преобразовывать их туда и обратно, следует настроить методы прямой сериализации и десериализации для модели и этого хранилища.
Заметка
Это используется только при использовании встроенной сериализации; при использовании прямой сериализации вектор можно обрабатывать любым желаемым способом.
Скоро
Дополнительные сведения в ближайшее время.