Fakturamodell för dokumentinformation
Det här innehållet gäller för: ![]() v4.0 (GA) | Tidigare versioner:
v4.0 (GA) | Tidigare versioner: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Det här innehållet gäller för: ![]() v3.1 (GA) | Senaste version:
v3.1 (GA) | Senaste version:![]() v4.0 (GA) | Tidigare versioner:
v4.0 (GA) | Tidigare versioner: ![]() v3.0
v3.0![]() v2.1
v2.1
Det här innehållet gäller för: ![]() v3.0 (GA) | Senaste versioner:
v3.0 (GA) | Senaste versioner: ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 | Föregående version:
v3.1 | Föregående version: ![]() v2.1
v2.1
Det här innehållet gäller för: ![]() v2.1 | Senaste version:
v2.1 | Senaste version: ![]() v4.0 (GA)
v4.0 (GA)
Fakturamodellen för dokumentinformation använder kraftfulla OCR-funktioner (Optisk teckenigenkänning) för att analysera och extrahera nyckelfält och radobjekt från försäljningsfakturor, verktygsräkningar och inköpsorder. Fakturor kan ha olika format och kvalitet, inklusive telefonbilder, skannade dokument och digitala PDF-filer. API:et analyserar fakturatext; extraherar viktig information som kundnamn, faktureringsadress, förfallodatum och förfallodatum. och returnerar en strukturerad JSON-datarepresentation. Modellen stöder för närvarande fakturor på 27 språk.
Dokumenttyper som stöds:
- Fakturor
- Fakturor för verktyg
- Försäljningsorder
- Inköpsorder
Automatiserad fakturabearbetning
Automatiserad fakturabearbetning är processen för att extrahera nyckelfält accounts payable från faktureringskontodokument. Extraherade data innehåller radobjekt från fakturor som är integrerade med dina arbetsflöden för leverantörsreskontra (AP) för granskningar och betalningar. Tidigare utförs leverantörsreskontraprocessen manuellt och därmed mycket tidskrävande. Korrekt extrahering av viktiga data från fakturor är vanligtvis det första och ett av de mest kritiska stegen i processen för fakturaautomatisering.
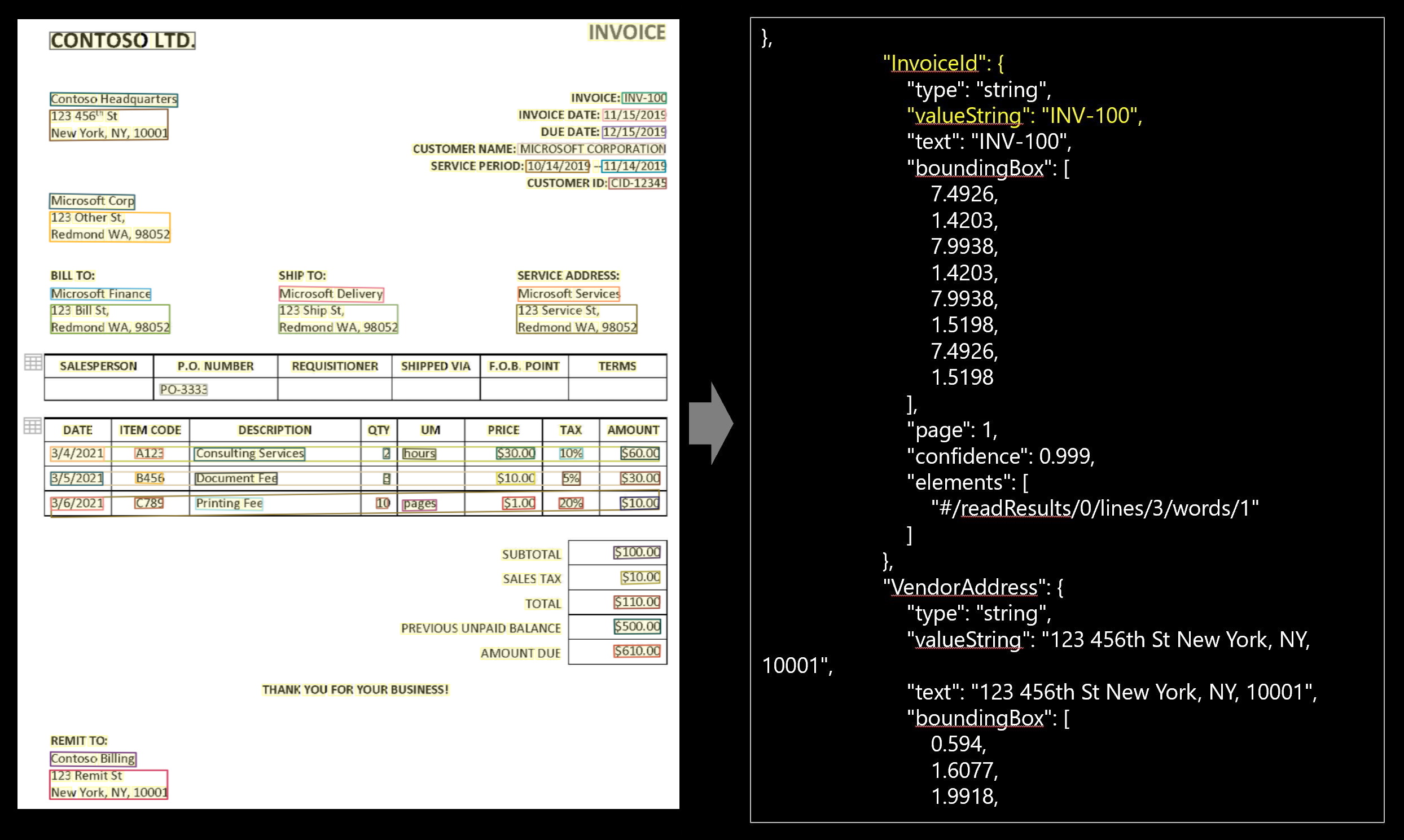
Exempelfaktura som bearbetas med Document Intelligence Studio:

Exempelfaktura som bearbetas med exempeletikettverktyget för dokumentinformation:
Utvecklingsalternativ
Document Intelligence v4.0: 2024-11-30 (GA) stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Fakturamodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
fördefinierad faktura |
Document Intelligence v3.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Fakturamodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
fördefinierad faktura |
Document Intelligence v3.0 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Fakturamodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
fördefinierad faktura |
Document Intelligence v2.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser |
|---|---|
| Fakturamodell | • Etikettverktyg för dokumentinformation• REST API • Klientbiblioteks-SDK • Docker-container för dokumentinformation |
Indatakrav
Filformat som stöds:
Modell PDF Bild: JPEG/JPG,PNG,BMP, ,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLästa ✔ ✔ ✔ Layout ✔ ✔ ✔ Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för betald (S0) nivå och
4MB för den kostnadsfria nivån (F0).Bilddimensioner måste vara mellan 50 bildpunkter x 50 bildpunkter och 10 000 bildpunkter x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar om
8punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och
1GB för den neurala modellen.För anpassad klassificeringsmodellträning är
1den totala storleken på träningsdata GB med högst 10 000 sidor. För 2024-11-30 (GA) är2den totala storleken på träningsdata GB med högst 10 000 sidor.
- Filformat som stöds: JPEG, PNG, PDF och TIFF.
- PDF och TIFF som stöds, upp till 2 000 sidor bearbetas. För prenumeranter på den kostnadsfria nivån bearbetas endast de två första sidorna.
- Filstorleken som stöds måste vara mindre än 50 MB och dimensionerna minst 50 x 50 bildpunkter och högst 10 000 x 10 000 bildpunkter.
Extrahering av fakturamodelldata
Se hur data, inklusive kundinformation, leverantörsinformation och radobjekt, extraheras från fakturor. Du behöver följande resurser:
En Azure-prenumeration – du kan skapa en kostnadsfritt.
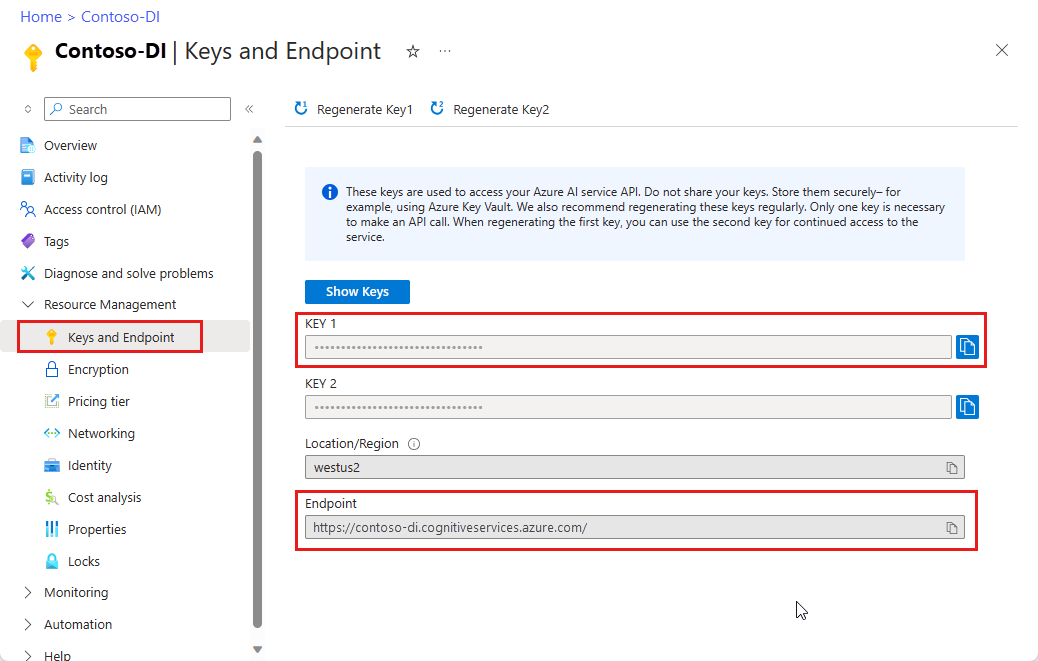
En instans av dokumentinformation i Azure Portal. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten. När resursen har distribuerats väljer du Gå till resurs för att hämta din nyckel och slutpunkt.
På startsidan för Document Intelligence Studio väljer du Fakturor.
Du kan analysera exempelfakturan eller ladda upp dina egna filer.
Välj knappen Kör analys och konfigurera vid behov alternativen Analysera :

Exempeletikettverktyg för dokumentinformation
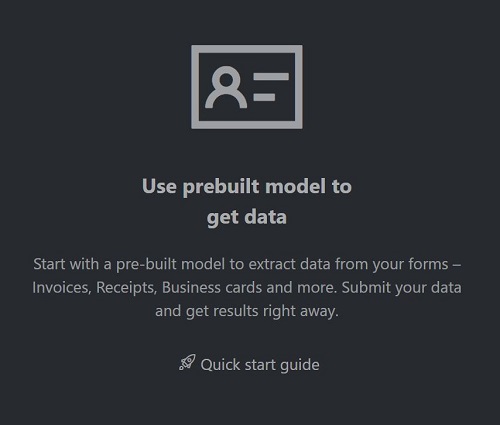
Gå till exempelverktyget för dokumentinformation.
På exempelverktygets startsida väljer du panelen Använd fördefinierad modell för att hämta data .
Välj den formulärtyp som ska analyseras från den nedrullningsbara menyn.
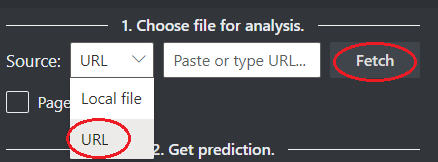
Välj en URL för filen som du vill analysera från alternativen nedan:
I fältet Källa väljer du URL på den nedrullningsbara menyn, klistrar in den valda URL:en och väljer knappen Hämta .
I fältet För dokumentinformationstjänstens slutpunkt klistrar du in slutpunkten som du fick med din Document Intelligence-prenumeration.
I nyckelfältet klistrar du in den nyckel som du fick från dokumentinformationsresursen.

Välj Kör analys. Verktyget Exempeletiketter för dokumentinformation anropar API:et Analysera fördefinierat och analyserar dokumentet.
Visa resultaten – se nyckel/värde-par extraherade, radobjekt, markerad text som extraherats och tabeller har identifierats.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Språk och nationella inställningar som stöds
En fullständig lista över språk som stöds finns på vår fördefinierade supportsida för modellspråk.
Fältextrahering
För dokumentextraheringsfält som stöds, se schemasidan för fakturamodell i vår GitHub-exempellagringsplats.
De nyckel/värde-fakturapar och radobjekt som extraheras finns i
documentResultsavsnittet i JSON-utdata.
Nyckel/värde-par
Den fördefinierade fakturamodellen stöder valfri retur av nyckel/värde-par. Som standard inaktiveras returen av nyckel/värde-par. Nyckel/värde-par är specifika intervall i fakturan som identifierar en etikett eller nyckel och dess associerade svar eller värde. På en faktura kan dessa par vara etiketten och värdet som användaren angav för fältet eller telefonnumret. AI-modellen tränas för att extrahera identifierbara nycklar och värden baserat på en mängd olika dokumenttyper, format och strukturer.
Nycklar kan också finnas isolerat när modellen upptäcker att en nyckel finns, utan associerat värde eller när valfria fält bearbetas. Ett mellannamnsfält kan till exempel lämnas tomt i ett formulär i vissa fall. Nyckel/värde-par är alltid textintervall som finns i dokumentet. För dokument där samma värde beskrivs på olika sätt, till exempel kund/användare, är den associerade nyckeln antingen kund eller användare (baserat på kontext).
JSON-utdata
JSON-utdata har tre delar:
"readResults"noden innehåller alla identifierade text- och markeringsmarkeringar. Text ordnas via sida, sedan efter rad och sedan efter enskilda ord."pageResults"noden innehåller tabeller och celler som extraherats med sina avgränsningsrutor, konfidens och en referens till raderna och orden i readResults."documentResults"noden innehåller de fakturaspecifika värden och radobjekt som modellen identifierade. Det är här du hittar alla fält från fakturan, till exempel faktura-ID, leverans till, faktura till, kund, summa, radobjekt och mycket mer.
Migreringsguide
- Följ migreringsguiden för Document Intelligence v3.1 för att lära dig hur du använder v3.0-versionen i dina program och arbetsflöden.
::: moniker-end
Nästa steg
Prova att bearbeta dina egna formulär och dokument med Document Intelligence Studio.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.
Prova att bearbeta dina egna formulär och dokument med verktyget Exempeletiketter för dokumentinformation.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.