Azure OpenAI-utvärdering (förhandsversion)
Utvärderingen av stora språkmodeller är ett viktigt steg för att mäta deras prestanda i olika uppgifter och dimensioner. Detta är särskilt viktigt för finjusterade modeller, där bedömning av prestandavinster (eller förluster) från träning är avgörande. Noggranna utvärderingar kan hjälpa dig att förstå hur olika versioner av modellen kan påverka ditt program eller scenario.
Azure OpenAI-utvärdering gör det möjligt för utvecklare att skapa utvärderingskörningar för att testa mot förväntade indata-/utdatapar och utvärdera modellens prestanda för viktiga mått, till exempel noggrannhet, tillförlitlighet och övergripande prestanda.
Stöd för utvärderingar
Regional tillgänglighet
- USA, östra 2
- Norra centrala USA
- Sverige, centrala
- Schweiz, västra
Distributionstyper som stöds
- Standard
- Etablerad
Utvärderingspipeline
Testdata
Du måste sätta ihop en datauppsättning för grundsanning som du vill testa mot. Skapande av datauppsättning är vanligtvis en iterativ process som säkerställer att dina utvärderingar förblir relevanta för dina scenarier över tid. Den här datamängden för grundsanning är vanligtvis handgjord och representerar det förväntade beteendet från din modell. Datamängden är också märkt och innehåller de förväntade svaren.
Kommentar
Vissa utvärderingstester som Sentiment och giltig JSON eller XML kräver inte grund sanningsdata.
Datakällan måste vara i JSONL-format. Nedan visas två exempel på JSONL-utvärderingsdatauppsättningar:
Utvärderingsformat
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
När du laddar upp och väljer utvärderingsfilen returneras en förhandsgranskning av de tre första raderna:


Du kan välja alla befintliga tidigare uppladdade datauppsättningar eller ladda upp en ny datauppsättning.
Generera svar (valfritt)
Uppmaningen som du använder i utvärderingen ska matcha uppmaningen som du planerar att använda i produktion. De här anvisningarna innehåller instruktioner för modellen som ska följas. På samma sätt som på lekplatsen kan du skapa flera indata för att ta med exempel med några bilder i prompten. Mer information finns i prompt engineering techniques for details on some advanced techniques in prompt design and prompt engineering (Fråga tekniska tekniker) för mer information om vissa avancerade tekniker inom snabb design och prompt-teknik.
Du kan referera till dina indata i prompterna med hjälp {{input.column_name}} av formatet, där column_name motsvarar namnen på kolumnerna i indatafilen.
Utdata som genereras under utvärderingen refereras i efterföljande steg med formatet {{sample.output_text}} .
Kommentar
Du måste använda dubbla klammerparenteser för att se till att du refererar till dina data korrekt.
Modelldistribution
Som en del av att skapa utvärderingar väljer du vilka modeller som ska användas när du genererar svar (valfritt) samt vilka modeller som ska användas vid klassificering av modeller med specifika testkriterier.
I Azure OpenAI tilldelar du specifika modelldistributioner som ska användas som en del av dina utvärderingar. Du kan jämföra flera distributioner genom att skapa en separat utvärderingskonfiguration för varje modell. På så sätt kan du definiera specifika frågor för varje utvärdering, vilket ger bättre kontroll över de variationer som krävs av olika modeller.
Du kan utvärdera antingen en bas- eller en finjusterad modelldistribution. Vilka distributioner som är tillgängliga i listan beror på de som du har skapat i din Azure OpenAI-resurs. Om du inte hittar den önskade distributionen kan du skapa en ny från sidan Azure OpenAI-utvärdering.
Testvillkor
Testkriterier används för att utvärdera effektiviteten för varje utdata som genereras av målmodellen. Dessa tester jämför indata med utdata för att säkerställa konsekvens. Du har flexibiliteten att konfigurera olika kriterier för att testa och mäta kvaliteten och relevansen av utdata på olika nivåer.

Komma igång
Välj Azure OpenAI Evaluation (PREVIEW) i Azure AI Foundry-portalen. Om du vill se den här vyn som ett alternativ kan du först behöva välja en befintlig Azure OpenAI-resurs i en region som stöds.
Välj Ny utvärdering

Ange ett namn på utvärderingen. Som standard genereras ett slumpmässigt namn automatiskt om du inte redigerar och ersätter det. > välj Ladda upp ny datauppsättning.
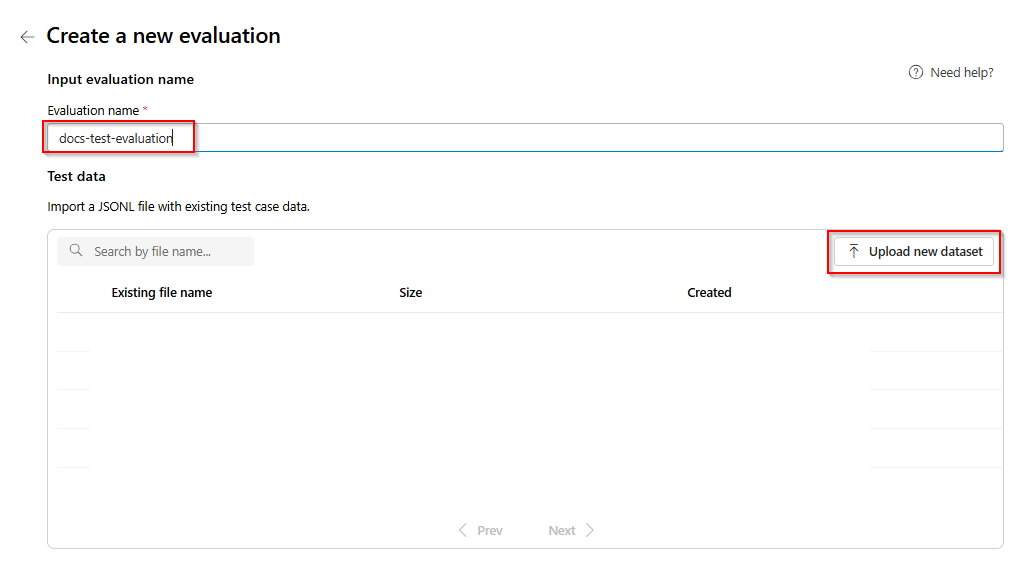
Välj din utvärdering som ska vara i
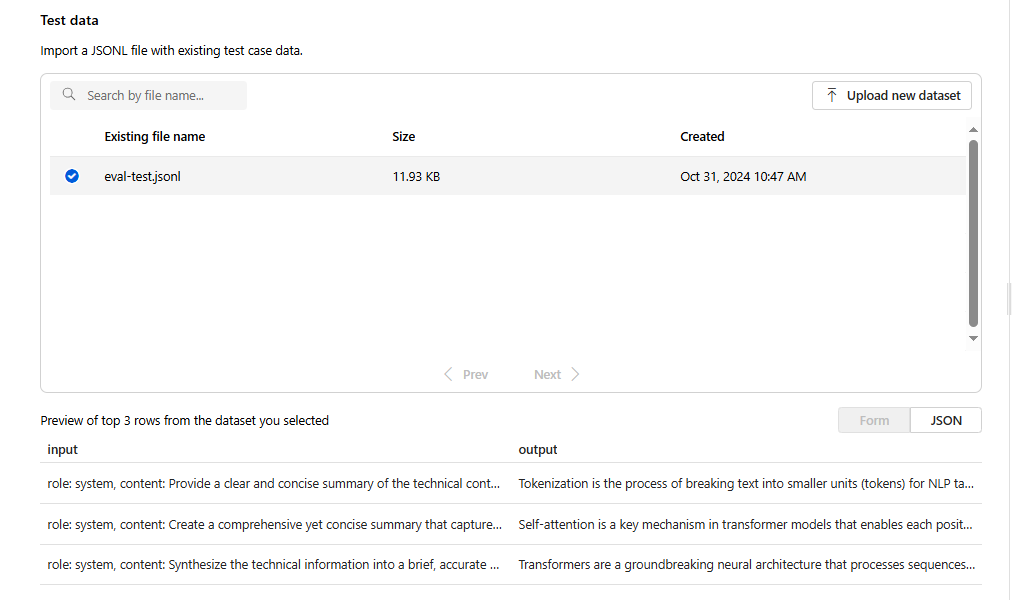
.jsonlformat. Om du behöver en exempeltestfil kan du spara dessa 10 rader i en fil med namneteval-test.jsonl:{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}Du ser de tre första raderna i filen som en förhandsversion:
Välj växlingsknappen för Generera svar. Välj
{{item.input}}i listrutan. Detta matar in indatafälten från vår utvärderingsfil i enskilda frågor om en ny modellkörning som vi vill kunna jämföra med vår utvärderingsdatauppsättning. Modellen tar indata och genererar sina egna unika utdata som i det här fallet lagras i en variabel med namnet{{sample.output_text}}. Vi använder sedan den exempelutdatatexten senare som en del av våra testkriterier. Du kan också ange ett eget anpassat systemmeddelande och enskilda meddelandeexempel manuellt.Välj vilken modell du vill generera svar baserat på din utvärdering. Om du inte har någon modell kan du skapa en. I det här exemplet använder vi en standarddistribution av
gpt-4o-mini.
Symbolen settings/sprocket styr de grundläggande parametrar som skickas till modellen. Endast följande parametrar stöds just nu:




- Temperatur
- Maxlängden
- Övre P
Maximal längd är för närvarande begränsad till 2048 oavsett vilken modell du väljer.
Välj Lägg till testvillkor och välj Lägg till.
Välj semantisk likhet> under Jämför lägg till
{{item.output}}under Med lägg till{{sample.output_text}}. Detta tar de ursprungliga referensutdata från utvärderingsfilen.jsonloch jämför den med utdata som genereras genom att ge modellprompterna baserat på din{{item.input}}.
Välj Lägg till> nu du kan antingen lägga till ytterligare testvillkor eller så väljer du Skapa för att initiera utvärderingsjobbkörningen.
När du har valt Skapa kommer du till en statussida för utvärderingsjobbet.

När utvärderingsjobbet har skapats kan du välja jobbet för att visa fullständig information om jobbet:

För semantisk likhet visar visa utdata information innehåller en JSON-representation som du kan kopiera/klistra in av dina klara tester.





Information om testvillkor
Azure OpenAI Evaluation erbjuder flera alternativ för testvillkor. Avsnittet nedan innehåller ytterligare information om varje alternativ.
Fakta
Utvärderar riktigheten i ett inlämnat svar genom att jämföra det med ett expertsvar.
Factity utvärderar den faktiska noggrannheten i ett inlämnat svar genom att jämföra det med ett expertsvar. Med hjälp av en detaljerad kedjefråga (CoT) avgör väghyveln om det inskickade svaret är konsekvent med, en delmängd av, en supermängd av eller i konflikt med expertsvaret. Det bortser från skillnader i stil, grammatik eller skiljetecken, med fokus enbart på faktainnehåll. Fakta kan vara användbara i många scenarier, inklusive men inte begränsat till innehållsverifiering och utbildningsverktyg som säkerställer att svaren från AI är korrekta.

Du kan visa den prompttext som används som en del av det här testvillkoren genom att välja listrutan bredvid prompten. Den aktuella prompttexten är:
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
Semantisk likhet
Mäter graden av likhet mellan modellens svar och referensen. Grades: 1 (completely different) - 5 (very similar).

Sentiment
Försöker identifiera den känslomässiga tonen i utdata.

Du kan visa den prompttext som används som en del av det här testvillkoren genom att välja listrutan bredvid prompten. Den aktuella prompttexten är:
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
Strängkontroll
Verifierar om utdata matchar den förväntade strängen exakt.

Strängkontrollen utför olika binära åtgärder på två strängvariabler som möjliggör olika utvärderingskriterier. Det hjälper dig att verifiera olika strängrelationer, inklusive likhet, inneslutning och specifika mönster. Den här utvärderaren möjliggör skiftlägeskänsliga eller skiftlägesokänsliga jämförelser. Det ger också angivna betyg för sanna eller falska resultat, vilket möjliggör anpassade utvärderingsresultat baserat på jämförelseresultatet. Här är typen av åtgärder som stöds:
equals: Kontrollerar om utdatasträngen är exakt lika med utvärderingssträngen.contains: Kontrollerar om utvärderingssträngen är en delsträng av utdatasträngen.starts-with: Kontrollerar om utdatasträngen börjar med utvärderingssträngen.ends-with: Kontrollerar om utdatasträngen slutar med utvärderingssträngen.
Kommentar
När du ställer in vissa parametrar i testvillkoren kan du välja mellan variabeln och mallen. Välj variabel om du vill referera till en kolumn i dina indata. Välj mall om du vill ange en fast sträng.
Giltig JSON eller XML
Verifierar om utdata är giltiga JSON eller XML.

Matchar schema
Säkerställer att utdata följer den angivna strukturen.

Villkorsmatchning
Utvärdera om modellens svar matchar dina kriterier. Betyg: Godkänd eller misslyckad.

Du kan visa den prompttext som används som en del av det här testvillkoren genom att välja listrutan bredvid prompten. Den aktuella prompttexten är:
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
Textkvalitet
Utvärdera textkvaliteten genom att jämföra med referenstext.

Sammanfattning:
- BLEU-poäng: Utvärderar kvaliteten på genererad text genom att jämföra den med en eller flera referensöversättningar av hög kvalitet med hjälp av BLEU-poängen.
- ROUGE-poäng: Utvärderar kvaliteten på genererad text genom att jämföra den med referenssammanfattningar med hjälp av ROUGE-poäng.
- Cosinin: Kallas även cosinnalikhet mäter hur nära två textinbäddningar– till exempel modellutdata och referenstexter – överensstämmer i betydelse, vilket hjälper till att bedöma semantisk likhet mellan dem. Detta görs genom att mäta avståndet i vektorutrymmet.
Detaljer:
BLEU-poäng (BiLingual Evaluation Understudy) används ofta vid bearbetning av naturligt språk (NLP) och maskinöversättning. Den används ofta i användningsfall för textsammanfattning och textgenerering. Den utvärderar hur nära den genererade texten matchar referenstexten. BLEU-poängen varierar från 0 till 1, med högre poäng som indikerar bättre kvalitet.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) är en uppsättning mått som används för att utvärdera automatisk sammanfattning och maskinöversättning. Den mäter överlappningen mellan genererad text och referenssammanfattningar. ROUGE fokuserar på återkallningsorienterade åtgärder för att bedöma hur väl den genererade texten täcker referenstexten. ROUGE-poängen innehåller olika mått, bland annat: • ROUGE-1: Överlappning av unigram (enkla ord) mellan genererad text och referenstext. • ROUGE-2: Överlappning av bigrams (två på varandra följande ord) mellan genererad och referenstext. • ROUGE-3: Överlappning av trigram (tre på varandra följande ord) mellan genererad text och referenstext. • ROUGE-4: Överlappning av fyra gram (fyra på varandra följande ord) mellan genererad text och referenstext. • ROUGE-5: Överlappning av fem gram (fem på varandra följande ord) mellan genererad text och referenstext. • ROUGE-L: Överlappning av L-gram (L på varandra följande ord) mellan genererad text och referenstext. Textsammanfattning och dokumentjämförelse är bland optimala användningsfall för ROUGE, särskilt i scenarier där textsammanhållning och relevans är kritiska.
Cosinélikhet mäter hur nära två textinbäddningar , till exempel modellutdata och referenstexter, överensstämmer i betydelse, vilket hjälper till att bedöma den semantiska likheten mellan dem. På samma sätt som andra modellbaserade utvärderare måste du tillhandahålla en modelldistribution med hjälp av för utvärdering.
Viktigt!
Endast inbäddningsmodeller stöds för den här utvärderaren:
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
Anpassad fråga
Använder modellen för att klassificera utdata till en uppsättning angivna etiketter. Den här utvärderaren använder en anpassad uppmaning som du måste definiera.
