Arkitektur för Azure Managed Redis (förhandsversion)
Azure Managed Redis (förhandsversion) körs på Redis Enterprise-stacken, vilket ger betydande fördelar jämfört med communityversionen av Redis. Följande information innehåller mer information om hur Azure Managed Redis är konstruerat, inklusive information som kan vara användbar för användare.
Viktigt!
Azure Managed Redis är för närvarande i förhandsversion. Juridiska villkor för Azure-funktioner i betaversion, förhandsversion eller som av någon annan anledning inte har gjorts allmänt tillgängliga ännu finns i kompletterande användningsvillkor för Microsoft Azure-förhandsversioner.
Jämförelse med Azure Cache for Redis
Nivåerna Basic, Standard och Premium i Azure Cache for Redis byggdes på communityversionen av Redis. Den här versionen av Redis har flera betydande begränsningar, inklusive att vara enkeltrådad av design. Detta minskar prestanda avsevärt och gör skalning mindre effektivt eftersom fler vCPU:er inte utnyttjas fullt ut av tjänsten. En typisk Azure Cache for Redis-instans använder en arkitektur som den här:
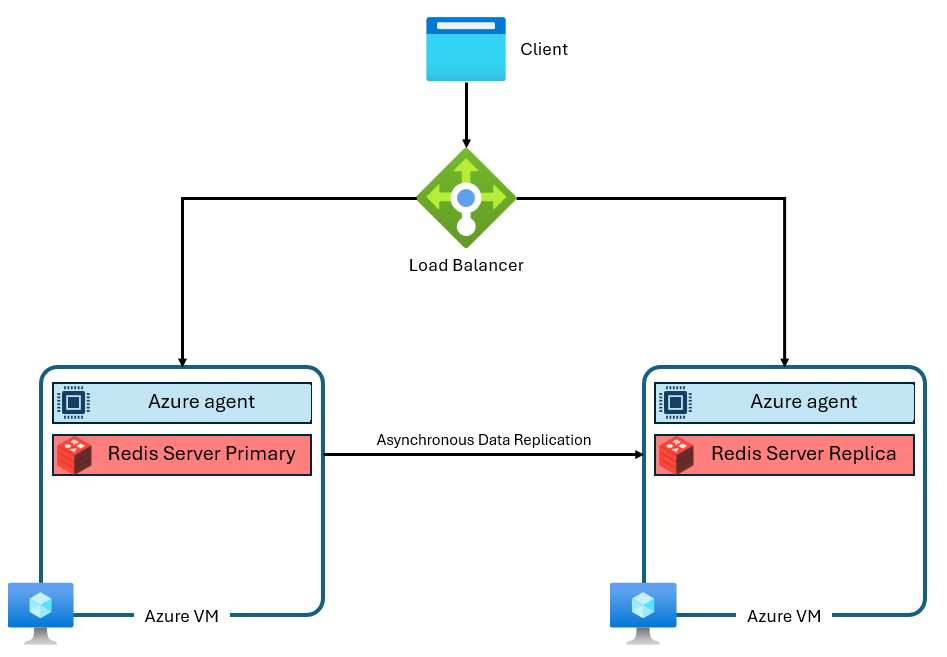
Observera att två virtuella datorer används – en primär och en replik. Dessa virtuella datorer kallas även "noder". Den primära noden innehåller den huvudsakliga Redis-processen och accepterar alla skrivningar. Replikeringen utförs asynkront till repliknoden för att tillhandahålla en säkerhetskopieringskopia under underhåll, skalning eller oväntat fel. Varje nod kan bara köra en enskild Redis-serverprocess på grund av den enkeltrådade designen av communityn Redis.
Arkitektoniska förbättringar av Azure Managed Redis
Azure Managed Redis använder en mer avancerad arkitektur som ser ut ungefär så här:
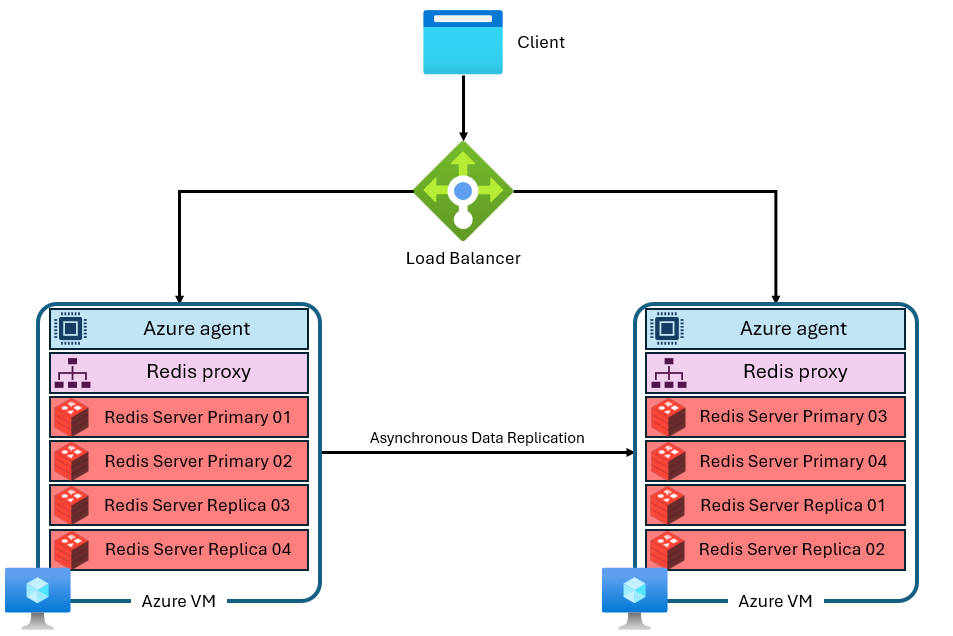
Det finns flera skillnader:
- Varje virtuell dator (eller "nod") kör flera Redis-serverprocesser (kallas "shards") parallellt. Flera shards möjliggör effektivare användning av vCPU:er på varje virtuell dator och högre prestanda.
- Alla primära Redis-shards finns inte på samma virtuella dator/nod. I stället distribueras primära fragment och replikskärvor över båda noderna. Eftersom primära shards använder fler CPU-resurser än replikskärvor gör den här metoden att fler primära shards kan köras parallellt.
- Varje nod har en proxyprocess med höga prestanda för att hantera shards, hantera anslutningshantering och utlösa självåterställning.
Den här arkitekturen ger både högre prestanda och även avancerade funktioner som aktiv geo-replikering
Klustring
Eftersom Redis Enterprise kan använda flera shards per nod är varje Azure Managed Redis-instans internt konfigurerad för att använda klustring på alla nivåer och SKU:er. Det inkluderar mindre instanser som bara har konfigurerats för att använda en enda shard. Klustring är ett sätt att dela upp data i Redis-instansen mellan flera Redis-processer, även kallade "horisontell partitionering". Azure Managed Redis erbjuder två klusterprinciper som avgör vilket protokoll som är tillgängligt för Redis-klienter för anslutning till cacheinstansen.
Klusterprinciper
Azure Managed Redis erbjuder två alternativ för klustringsprincip: OSS och Enterprise. OSS-klusterprincip rekommenderas för de flesta program eftersom den stöder högre maximalt dataflöde, men det finns fördelar och nackdelar med varje version.
OSS-klustringsprincipen implementerar samma Redis-kluster-API som Community Edition Redis. Redis-kluster-API:et gör att Redis-klienten kan ansluta direkt till shards på varje Redis-nod, vilket minimerar svarstiden och optimerar nätverkets dataflöde, vilket gör att dataflödet kan skalas nästan linjärt när antalet shards och vCPU:er ökar. OSS-klustringsprincipen ger vanligtvis bästa svarstid och dataflödesprestanda. OSS-klusterprincipen kräver dock att klientbiblioteket stöder Redis-kluster-API:et. I dag stöder nästan alla Redis-klienter Redis-kluster-API:et, men kompatibilitet kan vara ett problem för äldre klientversioner eller specialiserade bibliotek. OSS-klustringsprincipen kan inte heller användas med RediSearch-modulen.
Enterprise-klustringsprincipen är en enklare konfiguration som använder en enda slutpunkt för alla klientanslutningar. Med hjälp av enterprise-klustringsprincipen dirigeras alla begäranden till en enda Redis-nod som sedan används som proxy och som internt dirigerar begäranden till rätt nod i klustret. Fördelen med den här metoden är att den gör att Azure Managed Redis inte ser ut som användare. Det innebär att Redis-klientbibliotek inte behöver stöd för Redis-klustring för att få några av prestandafördelarna med Redis Enterprise, öka bakåtkompatibiliteten och göra anslutningen enklare. Nackdelen är att proxyn för en nod kan vara en flaskhals, antingen i beräkningsanvändningen eller nätverkets dataflöde. Enterprise-klustringsprincipen är den enda som kan användas med RediSearch-modulen. Även om enterprise-klusterprincipen gör att en Azure Managed Redis-instans verkar vara icke-illustrerad för användare, har den fortfarande vissa begränsningar med kommandon med flera nycklar.
Skala ut eller lägga till noder
Redis Enterprise-kärnprogramvaran kan antingen skala upp (med större virtuella datorer) eller skala ut (genom att lägga till fler noder/virtuella datorer). I slutändan utför antingen skalningsåtgärden samma sak – att lägga till mer minne, fler vCPU:er och fler shards. På grund av den här redundansen erbjuder Azure Managed Redis inte möjlighet att styra det specifika antalet noder som används i varje konfiguration. Den här implementeringsinformationen är abstrakt för användaren för att undvika förvirring, komplexitet och suboptimala konfigurationer. I stället är varje SKU utformad med en nodkonfiguration för att maximera vCPU:er och minne. Vissa SKU:er för Azure Managed Redis använder bara två noder, medan vissa använder fler.
Kommandon med flera nycklar
Eftersom Azure Managed Redis-instanser är utformade med en klustrad konfiguration kan du se CROSSSLOT undantag för kommandon som körs på flera nycklar. Beteendet varierar beroende på vilken klustringsprincip som används. Om du använder OSS-klustringsprincipen kräver kommandon med flera nycklar att alla nycklar mappas till samma hash-plats.
Du kan också se CROSSSLOT-fel med Enterprise-klustringsprincipen. Endast följande kommandon med flera nycklar tillåts mellan platser med Enterprise-klustring: DEL, MSET, MGET, EXISTS, UNLINK och TOUCH.
I Active-Active-databaser kan skrivkommandon med flera nycklar (DEL, MSET, UNLINK) endast köras på nycklar som finns på samma plats. Följande kommandon med flera nycklar tillåts dock mellan platser i Active-Active-databaser: MGET, EXISTS och TOUCH. Mer information finns i Databasklustring.
Partitioneringskonfiguration
Varje SKU för Azure Managed Redis är konfigurerad för att köra ett visst antal Redis-serverprocesser, shards parallellt. Relationen mellan dataflödesprestanda, antalet shards och antalet tillgängliga vCPU:er för varje instans är komplicerad. Om du lägger till shards ökar vanligtvis prestandan eftersom Redis-åtgärder kan köras parallellt. Men om shards inte kan köra kommandon eftersom inga vCPU:er är tillgängliga för att köra kommandon kan prestandan faktiskt sjunka. I följande tabell visas partitioneringskonfigurationen för varje Azure Managed Redis SKU. Dessa shards mappas för att optimera användningen av varje vCPU medan du reserverar vCPU-cykler för Redis Enterprise-proxy, hanteringsagent och OS-systemuppgifter som också påverkar prestanda.
Kommentar
Antalet shards och vCPU:er som används på varje SKU kan ändras med tiden eftersom prestanda optimeras av Azure Managed Redis-teamet.
| Nivåer | Flash-optimerad | Minnesoptimerad | Balanserad | Beräkningsoptimerad |
|---|---|---|---|---|
| Storlek (GB) | vCPU:er/primära shards | vCPU:er/primära shards | vCPU:er/primära shards | vCPU:er/primära shards |
| 0,5 | - | - | 2/2 | - |
| 1 | - | - | 2/2 | - |
| 3 | - | - | 2/2 | 4/2 |
| 6 | - | - | 2/2 | 4/2 |
| 12 | - | 2/2 | 4/2 | 8/6 |
| 24 | - | 4/2 | 8/6 | 16/12 |
| 60 | - | 8/6 | 16/12 | 32/24 |
| 120 | - | 16/12 | 32/24 | 64/48 |
| 180 | - | 24/24 | 48/48 | 96/96 |
| 240 | 8/6 | 32/24 | 64/48 | 128/96 |
| 360 | - | 48/48 | 96/96 | 192/192 |
| 480 | 16/12 | 64/48 | 128/96 | 256/192 |
| 720 | 24/24 | 96/96 | 192/192 | 384/384 |
| 960 | 32/24 | 128/192 | 256/192 | - |
| 1440 | 48/48 | 192/192 | - | - |
| 1920 | 64/48 | 256/192 | - | - |
| 4 500 | 144/96 | - | - | - |
Körs utan aktiverat läge för hög tillgänglighet
Det går att köra utan hög tillgänglighet (HA) aktiverat. Det innebär att Redis-instansen inte har replikering aktiverad och inte har åtkomst till tillgänglighetsavtalet. Vi rekommenderar inte att du kör i icke-HA-läge utanför utvecklings-/testscenarier. Du kan inte inaktivera hög tillgänglighet i en instans som redan har skapats. Du kan dock aktivera hög tillgänglighet i en instans som inte har den. Eftersom en instans som körs utan hög tillgänglighet använder färre virtuella datorer/noder kan vCPU:er inte användas lika effektivt, så prestandan kan vara lägre.
Reserverat minne
På varje Azure Managed Redis-instans reserveras cirka 20 % av det tillgängliga minnet som en buffert för icke-cacheåtgärder, till exempel replikering under redundansväxling och aktiv geo-replikeringsbuffert. Den här bufferten hjälper till att förbättra cacheprestanda och förhindra minnessvält.
Skala ned
Nedskalning stöds för närvarande inte på Azure Managed Redis. Mer information finns i Krav/begränsningar för skalning av Azure Managed Redis.
Flash-optimerad nivå
Nivån Flash Optimized använder både NVMe Flash Storage och RAM. Eftersom Flash Storage är en lägre kostnad kan du med hjälp av Nivån Flash-optimerad kompromissa med vissa prestanda för priseffektivitet.
På Flash Optimized-instanser finns 20 % av cacheutrymmet på RAM-minne, medan de andra 80 % använder Flash Storage. Alla nycklar lagras på RAM-minnet, medan värdena kan lagras antingen i Flash Storage eller RAM. Redis-programvaran avgör intelligent platsen för värdena. Frekventa värden som används ofta lagras på RAM-minnet, medan kalla värden som används mindre ofta sparas på Flash. Innan data läse eller skrivs måste de flyttas till RAM-minne och bli frekventa data.
Eftersom Redis optimerar för bästa prestanda fyller instansen först upp det tillgängliga RAM-minnet innan objekt läggs till i Flash Storage. Att fylla RAM-minnet först har några konsekvenser för prestanda:
- Bättre prestanda och kortare svarstid kan inträffa vid testning med låg minnesanvändning. Testning med en fullständig cacheinstans kan ge lägre prestanda eftersom endast RAM-minne används i testfasen med låg minnesanvändning.
- När du skriver mer data till cacheminnet minskar andelen data i RAM-minnet jämfört med Flash Storage, vilket vanligtvis gör att även svarstid och dataflödesprestanda minskar.
Arbetsbelastningar som passar bra för Flash Optimized-nivån
Arbetsbelastningar som sannolikt kommer att köras bra på flashoptimerad nivå har ofta följande egenskaper:
- Läsintensivt, med ett högt förhållande mellan läskommandon och skrivkommandon.
- Åtkomst fokuserar på en delmängd nycklar som används mycket oftare än resten av datamängden.
- Relativt stora värden jämfört med nyckelnamn. (Eftersom nyckelnamn alltid lagras i RAM kan stora värden bli en flaskhals för minnestillväxt.)
Arbetsbelastningar som inte passar bra för Flash Optimized-nivån
Vissa arbetsbelastningar har åtkomstegenskaper som är mindre optimerade för utformningen av flashoptimerad nivå:
- Skriva tunga arbetsbelastningar.
- Slumpmässiga eller enhetliga dataåtkomstmönster i de flesta datamängder.
- Långa nyckelnamn med relativt små värdestorlekar.