Finjustera program och databaser för prestanda i Azure SQL Database
gäller för:![]() Azure SQL Database
Azure SQL Database![]() SQL-databas i Fabric
SQL-databas i Fabric
När du har identifierat ett prestandaproblem med Azure SQL Database eller Fabric SQL Database är den här artikeln utformad för att hjälpa dig:
- Finjustera ditt program och tillämpa några metodtips som kan förbättra prestandan.
- Justera databasen genom att ändra index och frågor så att den fungerar mer effektivt med data.
Den här artikeln förutsätter att du redan har gått igenom databasrådgivarens rekommendationer och automatiska justeringsrekommendationer , om tillämpligt. Det förutsätter också att du har granskat översikt över övervakning och justering, Övervaka prestanda med hjälp av Query Store-och relaterade artiklar som rör felsökning av prestandaproblem. Dessutom förutsätter den här artikeln att du inte har något prestandaproblem som rör processorresursanvändning som kan lösas genom att öka beräkningsstorleken eller tjänstnivån för att tillhandahålla fler resurser till databasen.
Not
Liknande vägledning i Azure SQL Managed Instance finns i Finjustera program och databaser för prestanda i Azure SQL Managed Instance.
Justera applikationen
I traditionell lokal SQL Server separeras ofta processen för inledande kapacitetsplanering från processen för att köra ett program i produktion. Maskinvaru- och produktlicenser köps först och prestandajustering görs efteråt. När du använder Azure SQL är det en bra idé att sammanlänka processen med att köra ett program och justera det. Med modellen för att betala för kapacitet på begäran kan du justera programmet så att det använder de minsta resurser som behövs nu, i stället för överetablering på maskinvara baserat på gissningar om framtida tillväxtplaner för ett program, vilket ofta är felaktigt.
Vissa kunder kan välja att inte finjustera ett program och i stället välja att överetablera maskinvaruresurser. Den här metoden kan vara en bra idé om du inte vill ändra ett nyckelprogram under en upptagen period. Men om du justerar ett program kan du minimera resurskraven och sänka månatliga fakturor.
Metodtips och antimönster i programdesign för Azure SQL Database
Även om Tjänstnivåerna i Azure SQL Database är utformade för att förbättra prestandastabiliteten och förutsägbarheten för ett program, kan vissa metodtips hjälpa dig att finjustera ditt program för att bättre dra nytta av resurserna med en beräkningsstorlek. Även om många program har betydande prestandavinster genom att växla till en högre beräkningsstorlek eller tjänstnivå, behöver vissa program ytterligare justering för att dra nytta av en högre tjänstnivå. För ökad prestanda bör du överväga ytterligare programjustering för program som har följande egenskaper:
program som har långsamma prestanda på grund av "chattigt" beteende
Chattiga applikationer utför överdriven dataåtkomst som är känslig för nätverksfördröjning. Du kan behöva ändra den här typen av program för att minska antalet dataåtkomståtgärder till databasen. Du kan till exempel förbättra programmets prestanda med hjälp av tekniker som att batcha ad hoc-frågor eller flytta frågorna till lagrade procedurer. Mer information finns i Batch-frågor.
databaser med en intensiv arbetsbelastning som inte kan stödjas av en hel enskild dator
Databaser som överskrider resurserna med den högsta Premium-beräkningsstorleken kan ha nytta av att skala ut arbetsbelastningen. Mer information finns i Cross-database sharding och Funktionell partitionering.
Applikationer som har suboptimala sökfrågor
Program som har dåligt anpassade frågor kanske inte drar nytta av en större beräkningskapacitet. Detta inkluderar frågor som saknar en WHERE-sats, saknar index eller har inaktuell statistik. Dessa program drar nytta av standardtekniker för frågeprestandajustering. Mer information finns i Saknade index och Frågeoptimering och ledtrådar.
program som har en underoptimal design för dataåtkomst
Program som har problem med samtidighet i dataåtkomst, till exempel dödläge, kanske inte drar nytta av en högre beräkningsstorlek. Överväg att minska antalet turer mot databasen genom att cachelagra data på klientsidan med Azure Caching-tjänsten eller någon annan cachelagringsteknik. Se cachelagring på applikationsnivå.
Information om hur du förhindrar att dödlägen upprepas i Azure SQL Database finns i Analysera och förhindra dödlägen i Azure SQL Database och Fabric SQL Database.
Optimera databasen
I det här avsnittet tittar vi på några tekniker som du kan använda för att finjustera databasen för att få bästa prestanda för ditt program och köra den med lägsta möjliga beräkningsstorlek. Vissa av dessa tekniker matchar traditionella metodtips för SQL Server-justering, men andra är specifika för Azure SQL Database. I vissa fall kan du undersöka de förbrukade resurserna för en databas för att hitta områden för att finjustera och utöka traditionella SQL Server-tekniker så att de fungerar i Azure SQL Database.
Identifiera och lägga till saknade index
Ett vanligt problem i OLTP-databasprestanda är relaterat till den fysiska databasdesignen. Ofta utformas och levereras databasscheman utan testning i stor skala (antingen i belastning eller i datavolym). Tyvärr kan prestandan för en frågeplan vara acceptabel i liten skala men försämras avsevärt under datavolymer på produktionsnivå. Den vanligaste källan till det här problemet är bristen på lämpliga index för att uppfylla filter eller andra begränsningar i en fråga. Ofta visas saknade index som en tabellgenomsökning när en indexsökning kan räcka.
I det här exemplet använder den valda frågeplanen en genomsökning när en sökning räcker:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
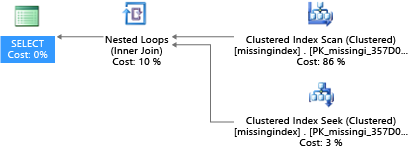
Azure SQL Database kan hjälpa dig att hitta och åtgärda vanliga indexvillkor som saknas. DMV:er som är inbyggda i Azure SQL Database tittar på frågekompileringar där ett index avsevärt skulle minska den uppskattade kostnaden för att köra en fråga. Under frågekörningen spårar databasmotorn hur ofta varje frågeplan körs och spårar det uppskattade avståndet mellan den körande frågeplanen och den inbillade där indexet fanns. Du kan använda dessa DMV:er för att snabbt gissa vilka ändringar i din fysiska databasdesign som kan förbättra den totala arbetsbelastningskostnaden för en databas och dess verkliga arbetsbelastning.
Du kan använda den här frågan för att utvärdera potentiella index som saknas:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
I det här exemplet resulterade frågan i det här förslaget:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
När den har skapats väljer samma SELECT-instruktion en annan plan, som använder en sökning i stället för en genomsökning och sedan kör planen mer effektivt:
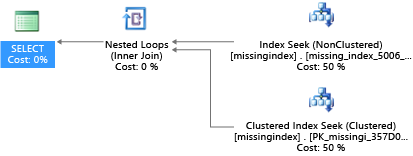
Den viktigaste insikten är att I/O-kapaciteten för ett delat råvarusystem är mer begränsad än för en dedikerad serverdator. Det finns en premie för att minimera onödig I/O för att dra största möjliga nytta av systemet i resurserna för varje beräkningsstorlek på tjänstnivåerna. Lämpliga designval för fysiska databaser kan avsevärt förbättra svarstiden för enskilda frågor, förbättra dataflödet för samtidiga begäranden som hanteras per skalningsenhet och minimera de kostnader som krävs för att uppfylla frågan.
Mer information om hur du justerar index med hjälp av begäran om saknade index finns i Finjustera icke-klustrade index med förslag på saknade index.
Frågeoptimering och hintning
Frågeoptimeraren i Azure SQL Database liknar den traditionella SQL Server-frågeoptimeraren. De flesta metodtipsen för att justera frågor och förstå begränsningarna i resonemangsmodellen för frågeoptimeraren gäller även för Azure SQL Database. Om du finjusterar frågor i Azure SQL Database kan du få ytterligare fördelar med att minska de aggregerade resursbehoven. Ditt program kanske kan köras till en lägre kostnad än en otunnad motsvarighet eftersom det kan köras med en lägre beräkningsstorlek.
Ett exempel som är vanligt i SQL Server och som även gäller för Azure SQL Database är hur frågeoptimeraren "sniffar" parametrar. Under kompileringen utvärderar frågeoptimeraren det aktuella värdet för en parameter för att avgöra om den kan generera en mer optimal frågeplan. Även om den här strategin ofta kan leda till en frågeplan som är betydligt snabbare än en plan som kompilerats utan kända parametervärden, fungerar den för närvarande ofullständigt både i Azure SQL Database. (En ny intelligent frågeprestandafunktion som introducerades med SQL Server 2022 med namnet optimering av parameterkänslighetsplan behandlar scenariot där en enda cachelagrad plan för en parametriserad fråga inte är optimal för alla möjliga inkommande parametervärden. För närvarande är optimering av parameterkänslighetsplan inte tillgängligt i Azure SQL Database.)
Databasmotorn stöder frågetips (direktiv) så att du kan ange avsikt mer avsiktligt och åsidosätta standardbeteendet för parametersniffning. Du kan välja att använda tips när standardbeteendet är ofullkomligt för en viss arbetsbelastning.
Nästa exempel visar hur frågeprocessorn kan generera en plan som är suboptimal för både prestanda- och resurskrav. Det här exemplet visar också att om du använder ett frågetips kan du minska frågekörningstiden och resurskraven för databasen:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Installationskoden skapar skeva (eller oregelbundet distribuerade) data i tabellen t1. Den optimala frågeplanen skiljer sig åt beroende på vilken parameter som väljs. Tyvärr omkompilerar cache-ningsbeteendet för planen inte alltid frågan baserat på det vanligaste parametervärdet. Så det är möjligt att en suboptimal plan cachelagras och används för många värden, även om en annan plan kan vara ett bättre val av plan i genomsnitt. Sedan skapar frågeplanen två lagrade procedurer som är identiska, förutom att den ena har ett särskilt frågetips.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Vi rekommenderar att du väntar minst 10 minuter innan du börjar del 2 i exemplet, så att resultaten skiljer sig åt i resulterande telemetridata.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
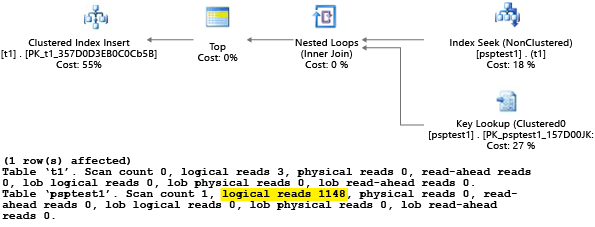
Varje del av det här exemplet försöker köra en parameteriserad insert-instruktion 1 000 gånger (för att generera en tillräcklig belastning för att kunna använda som en testdatauppsättning). När den kör lagrade procedurer undersöker frågeprocessorn parametervärdet som skickas till proceduren under den första kompileringen (parametern "sniffing"). Processorn cachelagrar den resulterande planen och använder den för senare anrop, även om parametervärdet är annorlunda. Den optimala planen kanske inte används i alla fall. Ibland måste du vägleda optimeraren att välja en plan som är bättre för det genomsnittliga fallet i stället för det specifika fallet från när frågan först kompilerades. I det här exemplet genererar den första planen en "genomsökningsplan" som läser alla rader för att hitta varje värde som matchar parametern:

Eftersom vi utförde proceduren med hjälp av värdet 1var den resulterande planen optimal för värdet 1 men var suboptimal för alla andra värden i tabellen. Resultatet är förmodligen inte vad du skulle vilja om du skulle välja varje plan slumpmässigt, eftersom planen går långsammare och använder fler resurser.
Om du kör testet med SET STATISTICS IO inställt på ONutförs det logiska genomsökningsarbetet i det här exemplet i bakgrunden. Du kan se att planen gör 1 148 läsningar (vilket är ineffektivt om man i genomsnitt bara returnerar en rad).

Den andra delen av exemplet använder ett frågetips för att instruera optimeraren att använda ett specifikt värde under kompileringsprocessen. I det här fallet tvingar det frågeprocessorn att ignorera det värde som skickas som parametern och i stället anta UNKNOWN. Detta refererar till ett värde som har den genomsnittliga frekvensen i tabellen (ignorerar skevhet). Den resulterande planen är en sökbaserad plan som är snabbare och använder färre resurser i genomsnitt än planen i del 1 av det här exemplet:
Du kan se effekten i sys.resource_stats systemvyn, som är specifik för Azure SQL Database. Det finns en fördröjning från den tid då du kör testet och när data fyller i tabellen. I det här exemplet körs del 1 under tidsperioden 22:25:00 och del 2 körs kl. 22:35:00. I det tidigare tidsfönstret användes fler resurser i det tidsfönstret än det senare (på grund av förbättringar av planeffektiviteten).
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

Not
Även om volymen i det här exemplet är avsiktligt liten kan effekten av suboptimala parametrar vara betydande, särskilt på större databaser. Skillnaden kan i extrema fall vara mellan sekunder för snabba fall och timmar för långsamma fall.
Du kan undersöka sys.resource_stats för att avgöra om resursen för ett test använder mer eller färre resurser än ett annat test. När du jämför data separerar du tidpunkten för testerna så att de inte befinner sig i samma 5-minutersfönster i sys.resource_stats-vyn. Målet med övningen är att minimera den totala mängden resurser som används och inte minimera de högsta resurserna. I allmänhet minskar även resursförbrukningen genom att optimera en kod för svarstid. Kontrollera att de ändringar du gör i ett program är nödvändiga och att ändringarna inte påverkar kundupplevelsen negativt för någon som kanske använder frågetips i programmet.
Om en arbetsbelastning har en uppsättning upprepade frågor är det ofta klokt att samla in och verifiera optimaliteten för dina planval eftersom den styr den minsta resursstorleksenhet som krävs för att vara värd för databasen. När du har verifierat det, ska du ibland ompröva planerna för att se till att de inte har blivit sämre. Du kan lära dig mer om frågetips (Transact-SQL).
Optimera anslutningsmöjligheter och anslutningspool
För att minska kostnaderna för att skapa frekventa programanslutningar i Azure SQL Database är anslutningspooler tillgängliga i dataprovidrar. Anslutningspooler är aktiverade i ADO.NET som standard, till exempel. Med anslutningspooler kan ett program återanvända anslutningar och minimera kostnaderna för att etablera nya.
Anslutningspooler kan förbättra dataflödet, minska svarstiden och förbättra den övergripande prestandan för dina databasarbetsbelastningar. När du använder inbyggda autentiseringsmekanismer hanterar drivrutiner token och tokenförnyelse internt. Tänk på följande metodtips:
Konfigurera inställningar för anslutningspoolen, till exempel maximala anslutningar, tidsgränser för anslutningar eller anslutningslivslängd, baserat på arbetsbelastningens krav på samtidighet och svarstid. Mer information finns i dokumentationen för dataprovidern.
Molnapplikationer bör implementera omförsökslogik för att hantera tillfälliga anslutningsfel på ett korrekt sätt. Läs mer om hur du utformar omförsökslogik för tillfälliga fel.
Tokenbaserade autentiseringsmekanismer, till exempel Microsoft Entra-ID-autentisering, måste generera nya token när de upphör att gälla. De fysiska anslutningarna i pooler med föråldrade token måste stängas och nya fysiska anslutningar skapas. Så här optimerar du den tid det tar att skapa fysiska anslutningar som använder tokenbaserad autentisering:
-
Implementera proaktiv, asynkron tokenförnyelse: Den första anslutningen
Open()för att hämta en ny token kan kräva en kort fördröjning för att hämta en ny Entra-ID-token. För många program är den här fördröjningen försumbar och ingen omkonfiguration krävs. Om du väljer att låta ditt program hantera token hämtar du nya åtkomsttoken innan förfallodatum och ser till att de cachelagras. Detta kan minimera fördröjningen av tokenförvärvet när den fysiska anslutningen skapas. Att proaktivt förnya token flyttar den korta fördröjningen till en process som inte är användarrelaterad. - Justera tokenlivslängd:Konfigurera principer för förfallodatum för token i Microsoft Entra ID så att de är minst den förväntade livslängden för logiska anslutningar i din applikation. Om du inte behöver justera tokens förfallotid kan du balansera säkerheten med prestandakostnaderna för att återskapa fysiska anslutningar.
-
Implementera proaktiv, asynkron tokenförnyelse: Den första anslutningen
Övervaka Azure SQL Database anslutningsprestanda och resursanvändning för att identifiera flaskhalsar, till exempel överdrivna inaktiva anslutningar eller otillräckliga poolgränser, och justera konfigurationerna i enlighet med detta. Använd Microsoft Entra-ID-loggar för att spåra tokenutgångsfel och se till att tokenens livslängd är korrekt konfigurerad. Överväg att använda Database Watcher eller Azure Monitor- i tillämpliga fall.
Metodtips för mycket stora databasarkitekturer i Azure SQL Database
Före släppet av tjänstnivån Hyperskala för enskilda databaser i Azure SQL Database kunde kunderna stöta på kapacitetsbegränsningar för enskilda databaser. Även om elastiska hyperskalapooler erbjuder betydligt högre lagringsgränser, kan elastiska pooler och pooldatabaser på andra tjänstnivåer fortfarande begränsas av dessa lagringskapacitetsgränser på tjänstnivåerna för icke-Hyperskala.
I följande två avsnitt beskrivs två alternativ för att lösa problem med mycket stora databaser i Azure SQL Database när du inte kan använda tjänstnivån Hyperskala.
Not
Elastiska pooler är inte tillgängliga för Azure SQL Managed Instance, SQL Server-instanser lokalt, SQL Server på virtuella Azure-datorer eller Azure Synapse Analytics.
Horisontell partitionering mellan databaser
Eftersom Azure SQL Database körs på vanlig maskinvara är kapacitetsgränserna för en enskild databas lägre än för en traditionell lokal SQL Server-installation. Vissa kunder använder horisontell partitioneringstekniker för att sprida databasåtgärder över flera databaser när åtgärderna inte passar inom gränserna för en enskild databas i Azure SQL Database. De flesta kunder som använder horisontell partitioneringstekniker i Azure SQL Database delar upp sina data på en enda dimension i flera databaser. För den här metoden måste du förstå att OLTP-program ofta utför transaktioner som endast gäller för en rad eller för en liten grupp rader i schemat.
Not
Azure SQL Database tillhandahåller nu ett bibliotek som hjälper till med horisontell partitionering. Mer information finns i översikt över Elastic Database-klientbiblioteket.
Om en databas till exempel har kundnamn, order- och orderinformation (till exempel i AdventureWorks databas) kan du dela upp dessa data i flera databaser genom att gruppera en kund med den relaterade beställnings- och orderinformationsinformationen. Du kan garantera att kundens data finns kvar i en enskild databas. Programmet skulle dela upp olika kunder mellan databaser och effektivt sprida belastningen över flera databaser. Med horisontell partitionering kan kunderna inte bara undvika den maximala databasstorleksgränsen, utan Azure SQL Database kan också bearbeta arbetsbelastningar som är betydligt större än gränserna för de olika beräkningsstorlekarna, så länge varje enskild databas passar in i tjänstnivågränserna.
Även om databassharding inte minskar den aggregerade resurskapaciteten för en lösning är det mycket effektivt att stödja mycket stora lösningar som är spridda över flera databaser. Varje databas kan köras med olika beräkningsstorlek för att stödja mycket stora, "effektiva" databaser med höga resurskrav.
Funktionell partitionering
Användare kombinerar ofta många funktioner i en enskild databas. Om ett program till exempel har logik för att hantera lager för ett lager kan databasen ha logik associerad med inventering, spårning av inköpsorder, lagrade procedurer och indexerade eller materialiserade vyer som hanterar rapportering i slutet av månaden. Den här tekniken gör det enklare att administrera databasen för åtgärder som säkerhetskopiering, men du måste också ändra storleken på maskinvaran för att hantera den högsta belastningen för alla funktioner i ett program.
Om du använder en skalbar arkitektur i Azure SQL Database är det en bra idé att dela upp olika funktioner i ett program i olika databaser. Om du använder den här tekniken skalas varje program separat. När ett program blir mer omfattande (och belastningen på databasen ökar) kan administratören välja oberoende beräkningsstorlekar för varje funktion i programmet. Med den här arkitekturen kan ett program vara större än vad en enskild råvarudator kan hantera eftersom belastningen är spridd över flera datorer.
Batch-frågor
För program som har åtkomst till data med hög volym, frekventa, ad hoc-frågor, spenderas en betydande mängd svarstid på nätverkskommunikation mellan programnivån och databasnivån. Även om både programmet och databasen finns i samma datacenter kan nätverksfördröjningen mellan de två förstoras av ett stort antal dataåtkomståtgärder. Om du vill minska nätverksresorna för dataåtkomståtgärder kan du överväga att använda alternativet för att antingen batcha ad hoc-frågorna eller kompilera dem som lagrade procedurer. Om du batchar ad hoc-frågorna kan du skicka flera frågor som en stor batch i en enda resa till databasen. Om du kompilerar ad hoc-frågor i en lagrad procedur kan du uppnå samma resultat som om du batchar dem. Genom att använda en lagrad procedur kan du också öka risken för cachelagring av frågeplaner i databasen så att du kan använda den lagrade proceduren igen.
Vissa program är skrivintensiva. Ibland kan du minska den totala I/O-belastningen på en databas genom att överväga hur du batchar skrivningar tillsammans. Detta är ofta så enkelt som att använda explicita transaktioner i stället för att automatiskt återuppta transaktioner i lagrade procedurer och ad hoc-batchar. En utvärdering av olika tekniker som du kan använda finns i Batching-tekniker för databasprogram i Azure. Experimentera med din egen arbetsbelastning för att hitta rätt modell för batchbearbetning. Se till att förstå att en modell kan ha lite olika garantier för transaktionskonsekvens. Att hitta rätt arbetsbelastning som minimerar resursanvändningen kräver att du hittar rätt kombination av konsekvens- och prestandavägningar.
Cachelagring på programnivå
Vissa databasprogram har läsintensiva arbetsbelastningar. Cachelagringslager kan minska belastningen på databasen och potentiellt minska den beräkningsstorlek som krävs för att stödja en databas med hjälp av Azure SQL Database. Med Azure Cache for Rediskan du, om du har en läsintensiv arbetsbelastning, läsa data en gång (eller kanske en gång per dator på programnivå, beroende på hur de konfigureras) och sedan lagra dessa data utanför databasen. Det här är ett sätt att minska databasbelastningen (CPU och läs-I/O), men det påverkar transaktionskonsekvensen eftersom data som läses från cacheminnet kan vara osynkroniserade med data i databasen. Även om viss inkonsekvens är acceptabel i många program är det inte sant för alla arbetsbelastningar. Du bör förstå alla programkrav innan du implementerar en cachelagringsstrategi på programnivå.
Få konfigurations- och designtips
Om du använder Azure SQL Database kan du köra ett T-SQL-med öppen källkod för att förbättra databaskonfigurationen och designen i Azure SQL Database. Skriptet analyserar databasen på begäran och ger tips för att förbättra databasens prestanda och hälsa. Vissa tips föreslår konfiguration och driftsändringar baserat på bästa praxis, medan andra tips rekommenderar designändringar som passar din arbetsbelastning, till exempel att aktivera avancerade databasmotorfunktioner.
Mer information om skriptet och kom igång finns på wiki-sidan Azure SQL Tips.
Information om hur du håller dig uppdaterad om de senaste funktionerna och uppdateringarna i Azure SQL Database finns i Nyheter i Azure SQL Database?
Relaterat innehåll
- Övervaka Azure SQL Database-
- Query Performance Insight för Azure SQL Database
- Övervaka prestanda med hjälp av dynamiska hanteringsvyer
- Databasövervakare
- Diagnostisera och felsöka hög CPU på Azure SQL Database
- Justera icke-klustrade index med förslag på saknade index
- Video: Metodtips för datainläsning i Azure SQL Database