Använda Azure Data Factory kommandoaktivitet för att köra Azure Data Explorer-hanteringskommandon
Azure Data Factory (ADF) är en molnbaserad dataintegreringstjänst som gör att du kan utföra en kombination av aktiviteter på data. Använd ADF för att skapa datadrivna arbetsflöden för orkestrering och automatisering av dataförflyttning och datatransformering. Med Azure Data Explorer Command-aktiviteten i Azure Data Factory kan du köra Azure Data Explorer-hanteringskommandon i ett ADF-arbetsflöde. I den här artikeln får du lära dig hur du skapar en pipeline med en uppslagsaktivitet och En ForEach-aktivitet som innehåller en Azure-Data Explorer kommandoaktivitet.
Förutsättningar
- En Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto.
- Ett Azure Data Explorer-kluster och en databas. Skapa ett kluster och en databas.
- En datakälla.
- En datafabrik. Skapa en datafabrik.
Skapa en ny pipeline
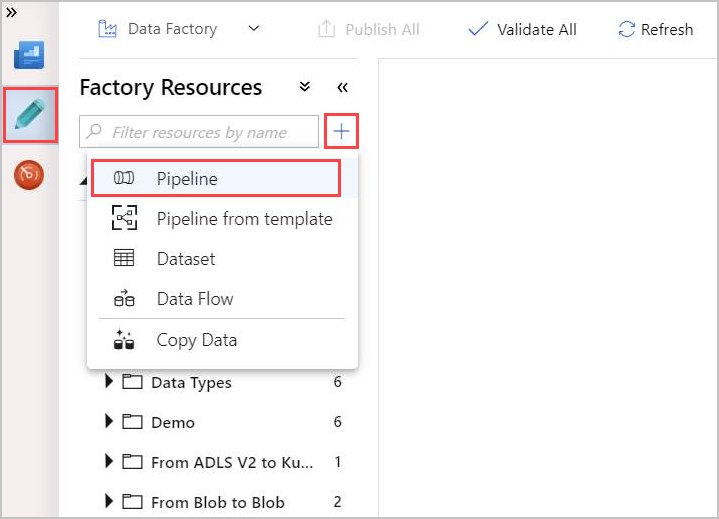
Välj pennverktyget Författare .
Skapa en ny pipeline genom att + välja och välj sedan Pipeline i listrutan.
Skapa en sökningsaktivitet
En uppslagsaktivitet kan hämta en datauppsättning från alla Azure Data Factory datakällor som stöds. Utdata från uppslagsaktiviteten kan användas i en ForEach eller annan aktivitet.
I fönstret Aktiviteter under Allmänt väljer du uppslagsaktiviteten . Dra och släpp den i huvudarbetsytan till höger.
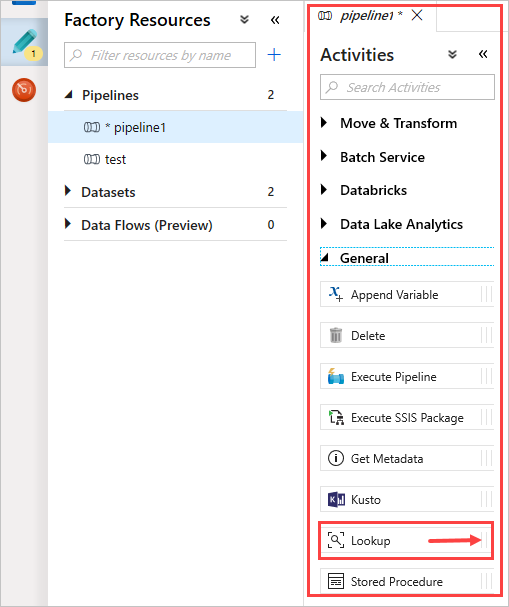
Arbetsytan innehåller nu uppslagsaktiviteten som du skapade. Använd flikarna under arbetsytan för att ändra relevanta parametrar. I Allmänt byter du namn på aktiviteten.
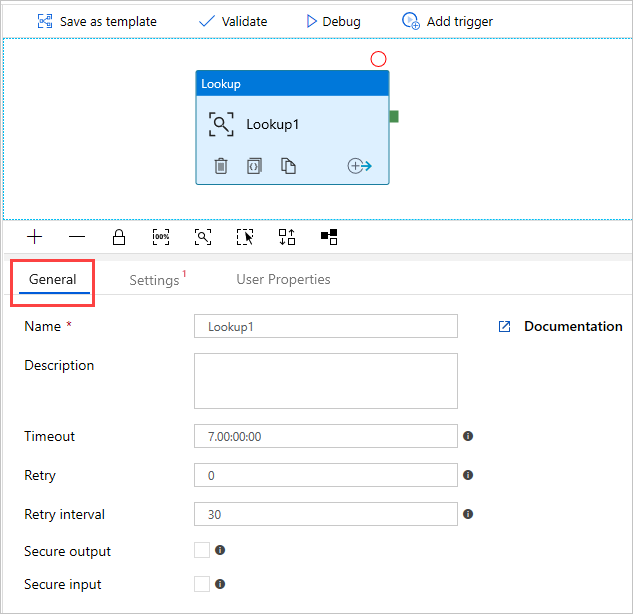
Tips
Klicka på det tomma arbetsytan för att visa pipelineegenskaperna. Använd fliken Allmänt för att byta namn på pipelinen. Vår pipeline heter pipeline-4-docs.
Skapa en Azure Data Explorer-datauppsättning i uppslagsaktivitet
I Inställningar väljer du din förskapade Azure Data Explorer Källdatauppsättning eller väljer + Ny för att skapa en ny datauppsättning.
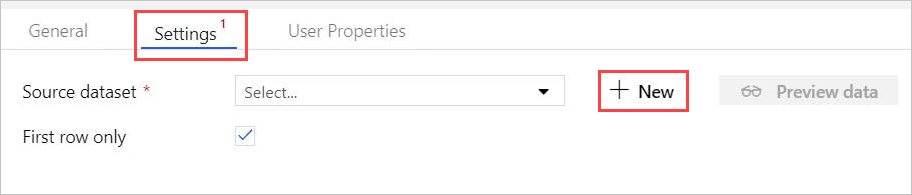
Välj datauppsättningen Azure Data Explorer (Kusto) från fönstret Ny datauppsättning. Välj Fortsätt för att lägga till den nya datauppsättningen.
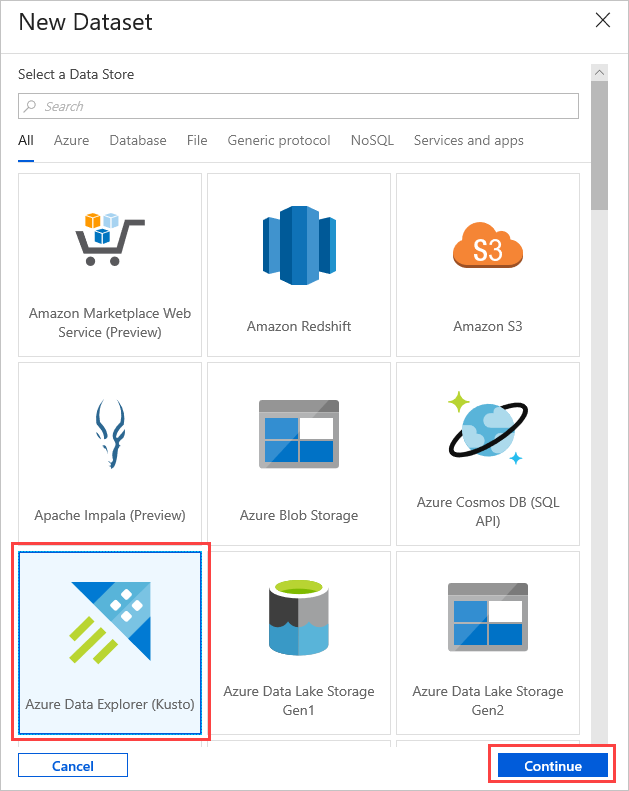
De nya Azure Data Explorer-datauppsättningsparametrarna visas i Inställningar. Om du vill uppdatera parametrarna väljer du Redigera.
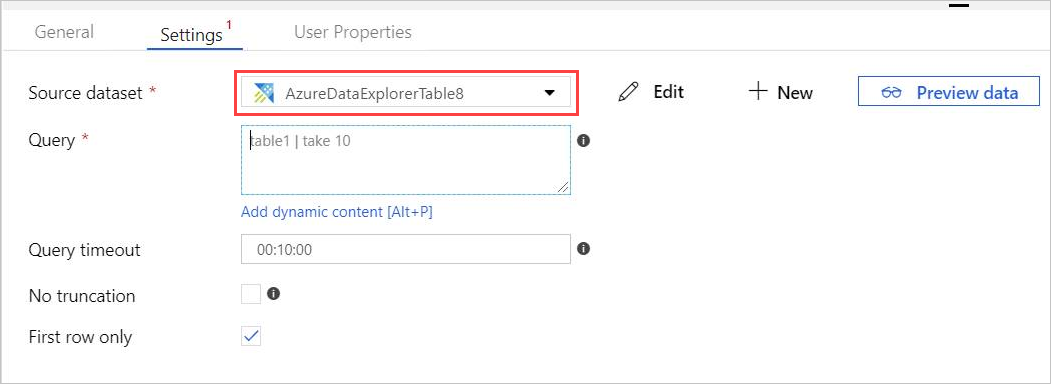
Den nya fliken AzureDataExplorerTable öppnas på huvudarbetsytan.
- Välj Allmänt och redigera datauppsättningens namn.
- Välj Anslutning för att redigera datauppsättningsegenskaperna.
- Välj den länkade tjänsten i listrutan eller välj + Ny för att skapa en ny länkad tjänst.
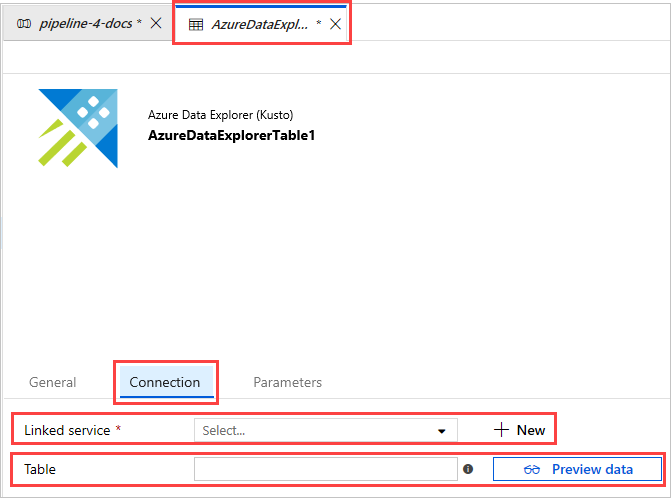
När du skapar en ny länkad tjänst öppnas sidan Ny länkad tjänst (Azure Data Explorer):
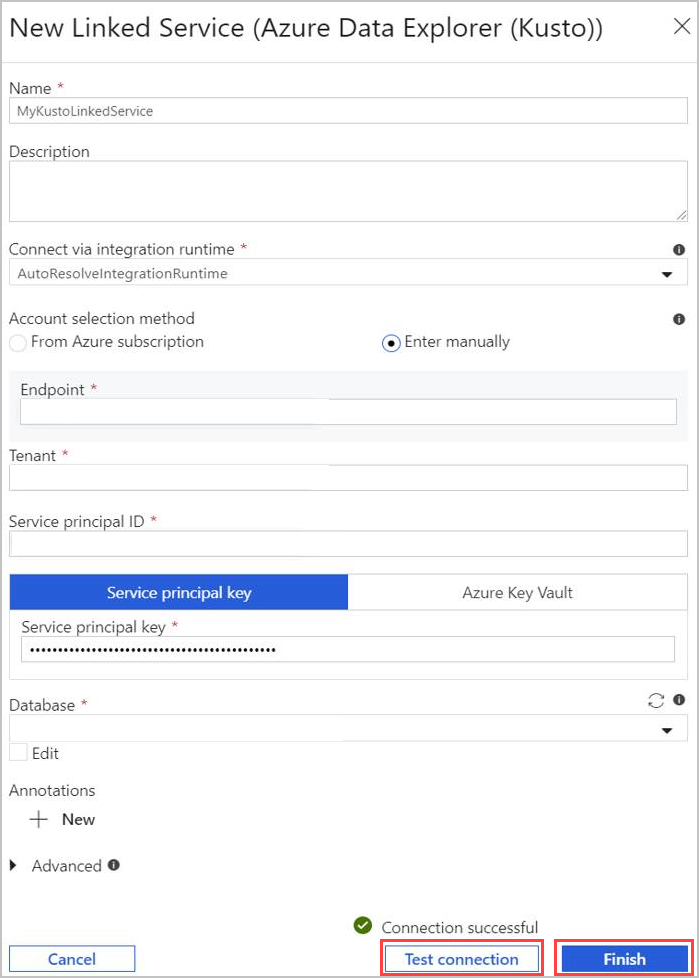
- Välj Namn för Azure Data Explorer länkade tjänsten. Lägg till Beskrivning om det behövs.
- I Anslut via integrationskörning ändrar du aktuella inställningar om det behövs.
- I Kontovalsmetod väljer du klustret med någon av två metoder:
- Välj alternativknappen Från Azure-prenumeration och välj ditt Azure-prenumerationskonto . Välj sedan ditt kluster. Observera att listrutan endast visar kluster som tillhör användaren.
- Välj i stället Knappen Ange manuellt alternativ och ange slutpunkten (kluster-URL).
- Ange klientorganisationen.
- Ange tjänstens huvudnamns-ID. Det här värdet finns i Azure Portal under Program-ID för appregistreringar>>översiktsprogram (klient). Huvudkontot måste ha tillräckliga behörigheter enligt den behörighetsnivå som krävs av kommandot som används.
- Välj knappen För tjänstens huvudnamn och ange tjänstens huvudnamnnyckel.
- Välj din databas på den nedrullningsbara menyn. Du kan också markera kryssrutan Redigera och ange ditt databasnamn.
- Välj Testa anslutning för att testa den länkade tjänstanslutning som du skapade. Om du kan ansluta till konfigurationen visas en grön bockmarkering Anslutning lyckades .
- Välj Slutför för att slutföra skapandet av länkad tjänst.
När du har konfigurerat en länkad tjänst lägger du till Tabellnamn i AzureDataExplorerTable-anslutning>. Välj Förhandsgranska data för att se till att data visas korrekt.
Datauppsättningen är nu klar och du kan fortsätta redigera din pipeline.
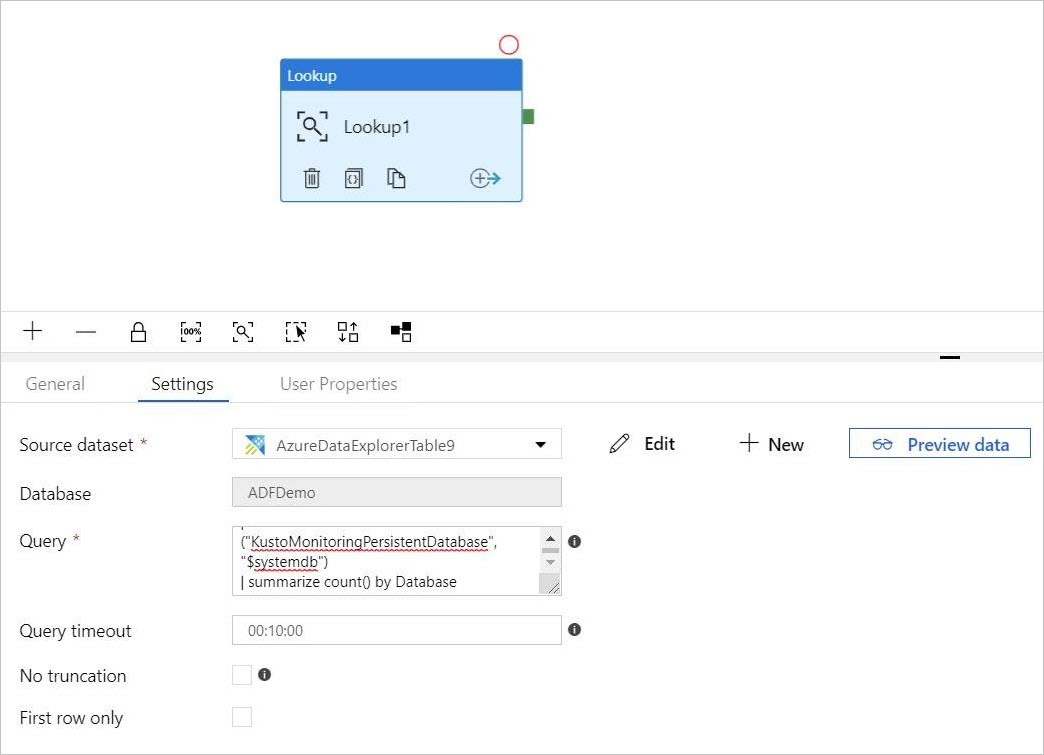
Lägga till en fråga i uppslagsaktiviteten
I pipeline-4-docs-inställningar> lägger du till en fråga i textrutan Fråga, till exempel:
ClusterQueries | where Database !in ("KustoMonitoringPersistentDatabase", "$systemdb") | summarize count() by DatabaseÄndra egenskaperna Frågetimeout eller Ingen trunkering och Endast första raden efter behov. I det här flödet behåller vi standardtimeouten för frågor och avmarkerar kryssrutorna.
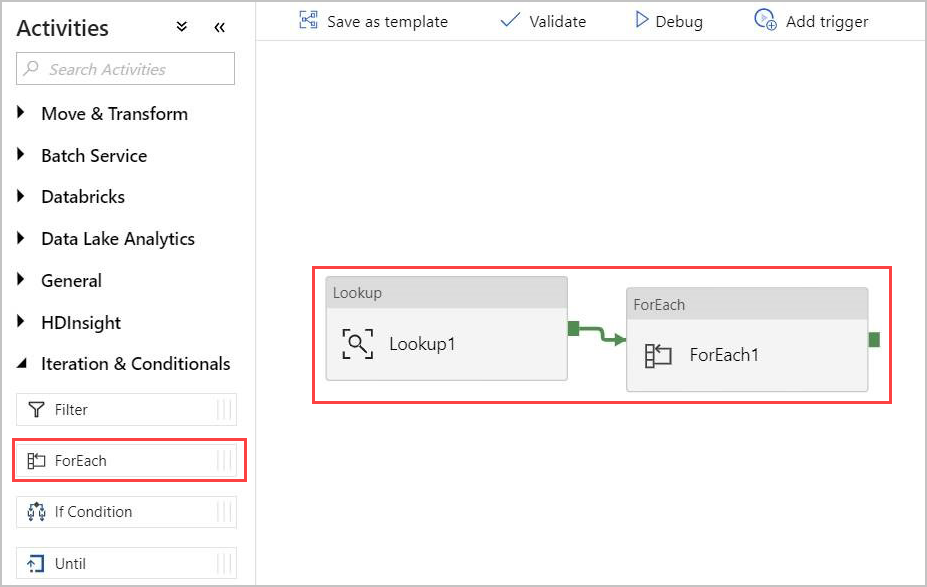
Skapa en For-Each aktivitet
Aktiviteten For-Each används för att iterera över en samling och köra angivna aktiviteter i en loop.
Nu lägger du till en For-Each aktivitet i pipelinen. Den här aktiviteten bearbetar data som returneras från uppslagsaktiviteten.
I fönstret Aktiviteter , under Iteration & Villkorsstyrda, väljer du Aktiviteten ForEach och drar och släpper den i arbetsytan.
Rita en linje mellan utdata från uppslagsaktiviteten och indata för ForEach-aktiviteten på arbetsytan för att ansluta dem.
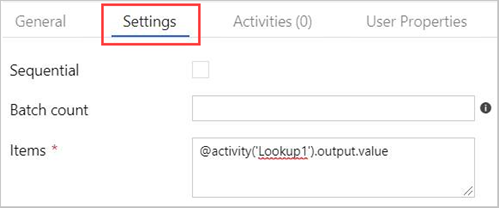
Välj aktiviteten ForEach på arbetsytan. På fliken Inställningar nedan:
Markera kryssrutan Sekventiell för sekventiell bearbetning av sökningsresultaten eller lämna den avmarkerad för att skapa parallell bearbetning.
Ange Antal batchar.
I Objekt anger du följande referens till utdatavärdet: @activity('Lookup1').output.value
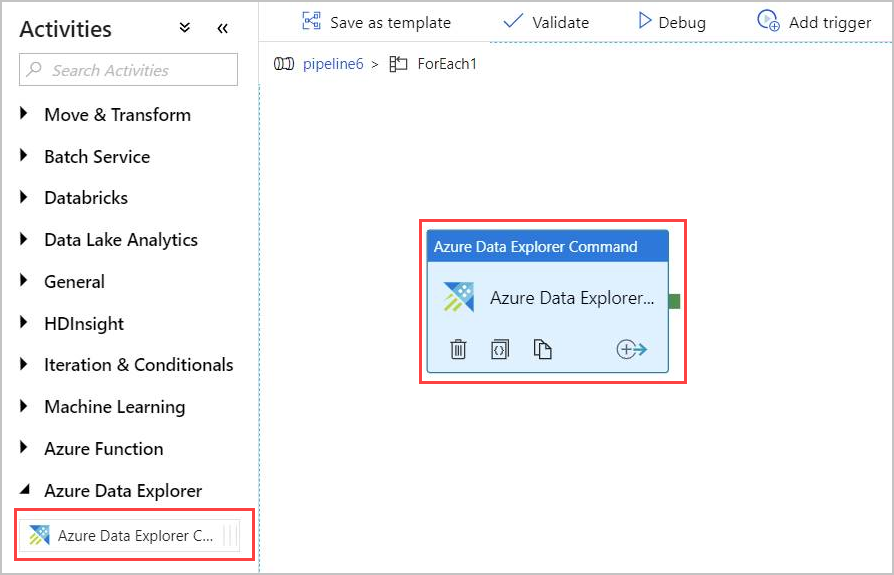
Skapa en Azure Data Explorer-kommandoaktivitet i ForEach-aktiviteten
Dubbelklicka på ForEach-aktiviteten på arbetsytan för att öppna den på en ny arbetsyta för att ange aktiviteterna i ForEach.
I fönstret Aktiviteter under Azure Data Explorer väljer du aktiviteten Azure Data Explorer Command och drar och släpper den på arbetsytan.
På fliken Anslutning väljer du samma länkade tjänst som du skapade tidigare.
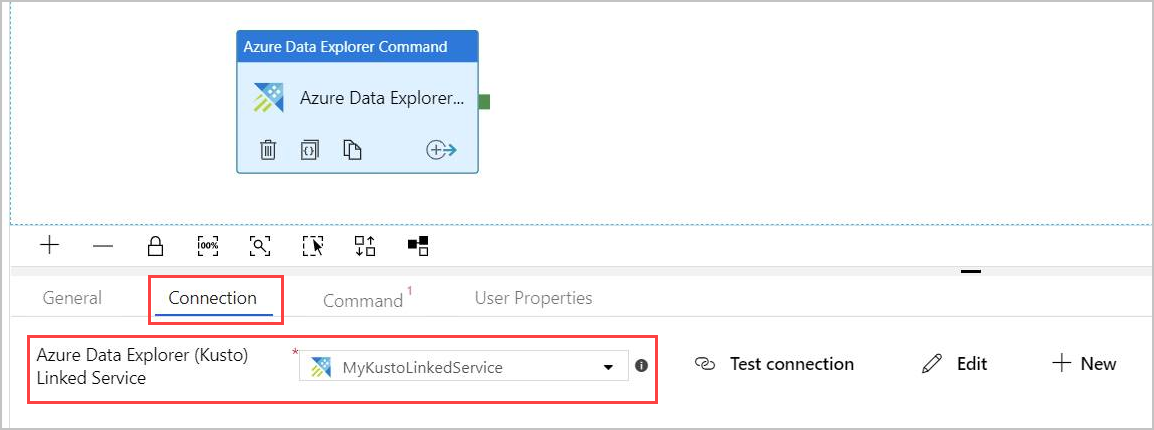
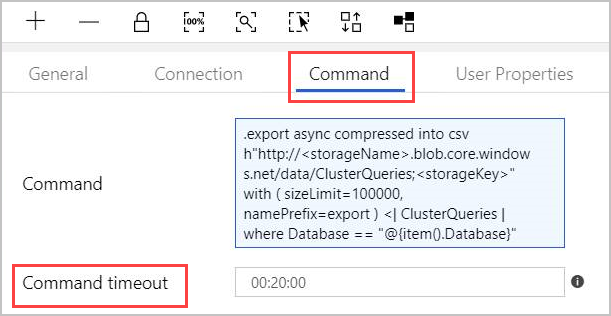
På fliken Kommando anger du följande kommando:
.export async compressed into csv h"http://<storageName>.blob.core.windows.net/data/ClusterQueries;<storageKey>" with ( sizeLimit=100000, namePrefix=export ) <| ClusterQueries | where Database == "@{item().Database}"Kommandot instruerar Azure Data Explorer att exportera resultatet av en viss fråga till en bloblagring i komprimerat format. Den körs asynkront (med asynkron modifierare). Frågan adresserar databaskolumnen för varje rad i sökningsaktivitetsresultatet. Tidsgränsen för kommandot kan lämnas oförändrad.
Anteckning
Kommandoaktiviteten har följande gränser:
- Storleksgräns: 1 MB svarsstorlek
- Tidsgräns: 20 minuter (standard), 1 timme (max).
- Om det behövs kan du lägga till en fråga i resultatet med hjälp av AdminThenQuery för att minska den resulterande storleken/tiden.
Nu är pipelinen klar. Du kan gå tillbaka till huvudpipelinevyn genom att klicka på pipelinenamnet.

Välj Felsök innan du publicerar pipelinen. Pipeline-förloppet kan övervakas på fliken Utdata .
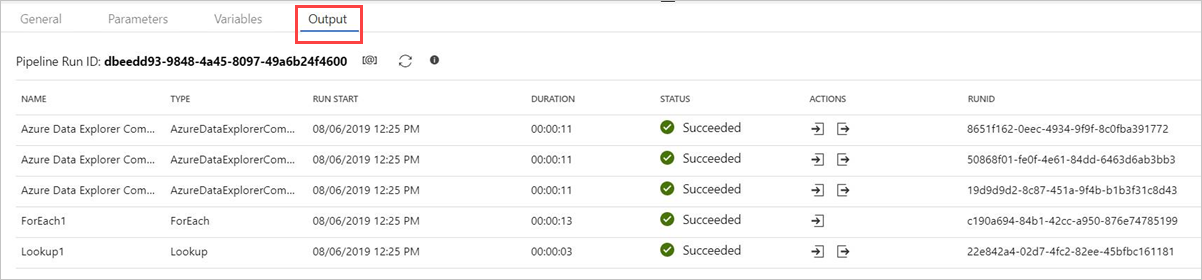
Du kan publicera alla och sedan lägga till utlösare för att köra pipelinen.
Utdata för hanteringskommandon
Strukturen för kommandoaktivitetens utdata beskrivs nedan. Dessa utdata kan användas av nästa aktivitet i pipelinen.
Returnerat värde för ett icke-asynkront hanteringskommando
I ett icke-asynkront hanteringskommando liknar strukturen för det returnerade värdet strukturen för sökningsaktivitetsresultatet. Fältet count anger antalet returnerade poster. Ett fast matrisfält value innehåller en lista med poster.
{
"count": "2",
"value": [
{
"ExtentId": "1b9977fe-e6cf-4cda-84f3-4a7c61f28ecd",
"ExtentSize": 1214.0,
"CompressedSize": 520.0
},
{
"ExtentId": "b897f5a3-62b0-441d-95ca-bf7a88952974",
"ExtentSize": 1114.0,
"CompressedSize": 504.0
}
]
}
Returnerat värde för ett asynkront hanteringskommando
I ett asynkront hanteringskommando avsöker aktiviteten åtgärdstabellen i bakgrunden tills asynkroniseringsåtgärden har slutförts eller tidsgränsen uppnås. Därför innehåller det returnerade värdet resultatet av .show operations OperationId för den angivna Egenskapen OperationId . Kontrollera värdena för egenskaper för tillstånd och status för att kontrollera att åtgärden har slutförts.
{
"count": "1",
"value": [
{
"OperationId": "910deeae-dd79-44a4-a3a2-087a90d4bb42",
"Operation": "TableSetOrAppend",
"NodeId": "",
"StartedOn": "2019-06-23T10:12:44.0371419Z",
"LastUpdatedOn": "2019-06-23T10:12:46.7871468Z",
"Duration": "00:00:02.7500049",
"State": "Completed",
"Status": "",
"RootActivityId": "f7c5aaaf-197b-4593-8ba0-e864c94c3c6f",
"ShouldRetry": false,
"Database": "MyDatabase",
"Principal": "<some principal id>",
"User": "<some User id>"
}
]
}