Kom igång: Fråga efter och visualisera data från en notebook-fil
Den här kom igång-artikeln beskriver hur du använder en Azure Databricks-notebook-fil för att köra frågor mot exempeldata som lagras i Unity Catalog med hjälp av SQL, Python, Scala och R och sedan visualisera frågeresultaten i notebook-filen.
Krav
För att slutföra uppgifterna i den här artikeln måste du uppfylla följande krav:
- Unity Catalog måste vara aktiverat på arbetsytan. Information om hur du kommer igång med Unity Catalog finns i Konfigurera och hantera Unity Catalog.
- Du måste ha behörighet att använda en befintlig beräkningsresurs eller skapa en ny beräkningsresurs. Se Kom igång: Konfiguration av konto och arbetsyta eller kontakta Databricks-administratören.
Steg 1: Skapa en ny notebook-fil
Om du vill skapa en notebook-fil på arbetsytan klickar du på ![]() Nytt i sidofältet och klickar sedan på Notebook. En tom anteckningsbok öppnas på arbetsytan.
Nytt i sidofältet och klickar sedan på Notebook. En tom anteckningsbok öppnas på arbetsytan.
Mer information om hur du skapar och hanterar notebook-filer finns i Hantera notebook-filer.
Steg 2: Fråga en tabell
Fråga tabellen samples.nyctaxi.trips i Unity Catalog med det språk du väljer.
Kopiera och klistra in följande kod i den nya tomma notebook-cellen. Den här koden visar resultatet från att köra frågor mot
samples.nyctaxi.tripstabellen i Unity Catalog.SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Tryck
Shift+Enterför att köra cellen och flytta sedan till nästa cell.Frågeresultatet visas i notebook-filen.
Steg 3: Visa data
Visa det genomsnittliga prisbeloppet efter reseavstånd, grupperat efter postnummer för upphämtning.
Bredvid fliken Tabell klickar du på + och klickar sedan på Visualisering.
Visualiseringsredigeraren visas.
I listrutan Visualiseringstyp kontrollerar du att Fältet är markerat.
Välj
fare_amountför X-kolumnen.Välj
trip_distanceför kolumnen Y.Välj
Averagesom sammansättningstyp.Välj
pickup_zipsom grupp efter kolumn.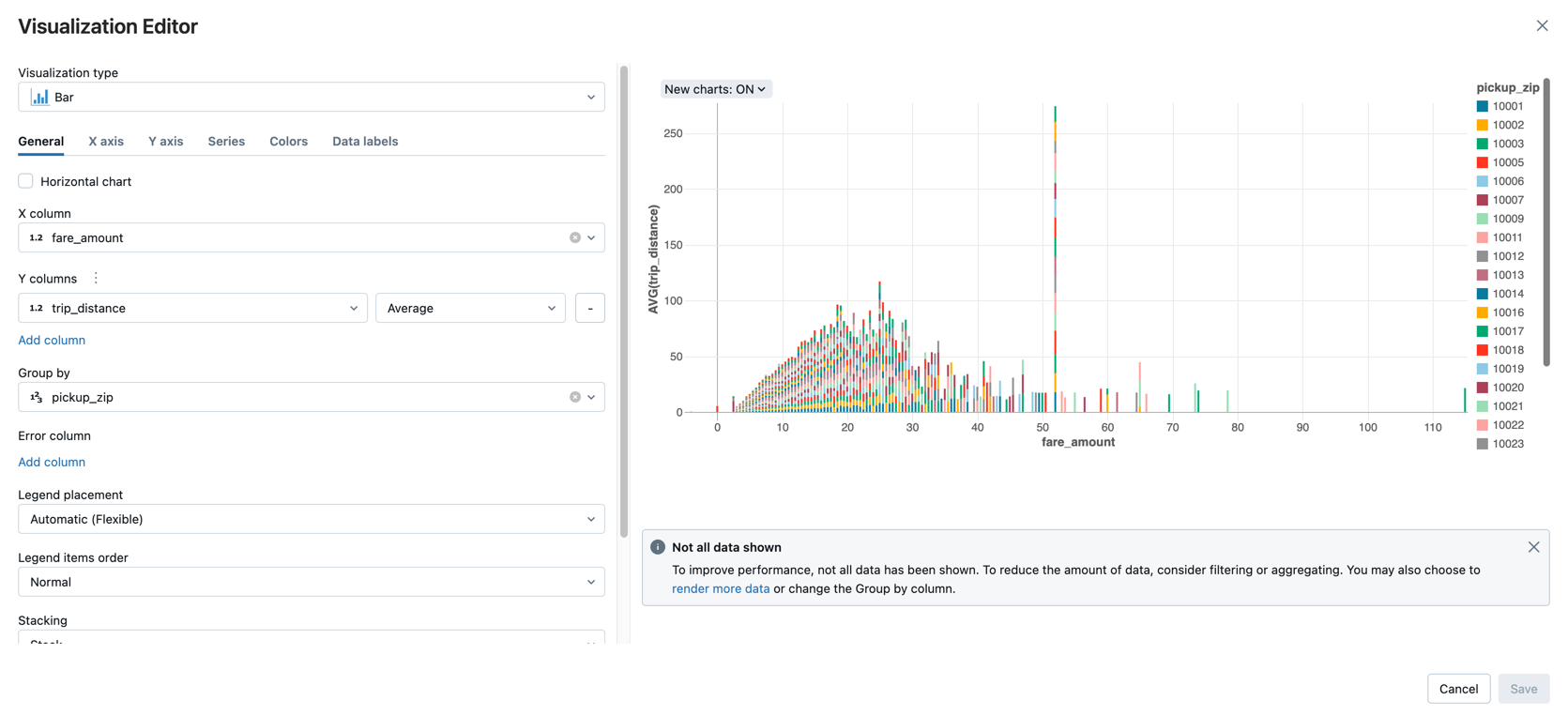
Klicka på Spara.
Nästa steg
- Mer information om hur du lägger till data från CSV-filen i Unity Catalog och visualiserar data finns i Kom igång: Importera och visualisera CSV-data från en notebook-fil.
- Information om hur du läser in data i Databricks med Apache Spark finns i Självstudie: Läsa in och transformera data med Apache Spark DataFrames.
- Mer information om hur du matar in data i Databricks finns i Mata in data i ett Databricks lakehouse.
- Mer information om hur du frågar efter data med Databricks finns i Frågedata.
- Mer information om visualiseringar finns i Visualiseringar i Databricks Notebooks.