Distribuera ett Java-program manuellt med JBoss EAP i ett Azure Red Hat OpenShift-kluster
Den här artikeln visar hur du distribuerar ett Red Hat JBoss Enterprise Application Platform-program (EAP) till ett Azure Red Hat OpenShift-kluster. Exemplet är ett Java-program som backas upp av en SQL-databas. Appen distribueras med JBoss EAP Helm-diagram.
I den här guiden lär du dig att:
- Förbered ett JBoss EAP-program för OpenShift.
- Skapa en enskild databasinstans av Azure SQL Database.
- Eftersom Azure Workload Identity ännu inte stöds av Azure OpenShift använder den här artikeln fortfarande användarnamn och lösenord för databasautentisering i stället för att använda lösenordslösa databasanslutningar.
- Distribuera programmet i ett Azure Red Hat OpenShift-kluster med hjälp av JBoss Helm Charts och OpenShift-webbkonsolen
Exempelprogrammet är ett tillståndskänsligt program som lagrar information i en HTTP-session. Den använder JBoss EAP-klustringsfunktionerna och använder följande Jakarta EE- och MicroProfile-tekniker:
- Jakarta Server-ansikten
- Jakarta Enterprise-bönor
- Jakarta Persistence
- MicroProfile Health
Den här artikeln är stegvis manuell vägledning för att köra JBoss EAP-appen i ett Azure Red Hat OpenShift-kluster. En mer automatiserad lösning som påskyndar din resa till Azure Red Hat OpenShift-klustret finns i Snabbstart: Distribuera JBoss EAP på Azure Red Hat OpenShift med hjälp av Azure Portal.
Om du är intresserad av att ge feedback eller arbeta nära ditt migreringsscenario med teknikteamet som utvecklar JBoss EAP för Azure-lösningar, fyller du i den här korta undersökningen om JBoss EAP-migrering och inkluderar din kontaktinformation. Teamet med programchefer, arkitekter och ingenjörer kommer snabbt att kontakta dig för att initiera ett nära samarbete.
Viktigt!
Den här artikeln distribuerar ett program med hjälp av JBoss EAP Helm-diagram. I skrivande stund erbjuds den här funktionen fortfarande som en förhandsversion av teknik. Innan du väljer att distribuera program med JBoss EAP Helm Charts i produktionsmiljöer kontrollerar du att den här funktionen är en funktion som stöds för din JBoss EAP/XP-produktversion.
Viktigt!
Medan Red Hat och Microsoft Azure tillsammans skapar, driver och stöder Azure Red Hat OpenShift för att tillhandahålla en integrerad supportupplevelse, omfattas programvaran som du kör ovanpå Azure Red Hat OpenShift, inklusive den som beskrivs i den här artikeln, av sina egna support- och licensvillkor. Mer information om stöd för Azure Red Hat OpenShift finns i Supportlivscykel för Azure Red Hat OpenShift 4. Mer information om stöd för programvaran som beskrivs i den här artikeln finns på huvudsidorna för programvaran enligt beskrivningen i artikeln.
Förutsättningar
Kommentar
Azure Red Hat OpenShift kräver minst 40 kärnor för att kunna skapa och köra ett OpenShift-kluster. Standardkvoten för Azure-resurser för en ny Azure-prenumeration uppfyller inte det här kravet. Information om hur du begär en ökning av resursgränsen finns i Standardkvot: Öka gränserna per VM-serie. Den kostnadsfria utvärderingsprenumerationen är inte berättigad till en kvotökning, uppgradera till en betala perYou-Go-prenumeration innan du begär en kvotökning.
Förbered en lokal dator med ett Unix-liknande operativsystem som stöds av de olika installerade produkterna, till exempel Ubuntu, macOS eller Windows-undersystem för Linux.
Installera en Java Standard Edition-implementering (SE). De lokala utvecklingsstegen i den här artikeln testades med Java Development Kit (JDK) 17 från Microsoft-versionen av OpenJDK.
Installera Maven 3.8.6 eller senare.
Installera Azure CLI 2.40 eller senare.
Klona koden för det här demoprogrammet (att göra-listan) till ditt lokala system. Demoprogrammet finns på GitHub.
Följ anvisningarna i Skapa ett Azure Red Hat OpenShift 4-kluster.
Även om steget "Hämta en Red Hat-pullhemlighet" är märkt som valfritt, krävs det för den här artikeln. Med pull-hemligheten kan ditt Azure Red Hat OpenShift-kluster hitta JBoss EAP-programavbildningarna.
Om du planerar att köra minnesintensiva program i klustret anger du rätt storlek på den virtuella datorn för arbetsnoderna med hjälp av parametern
--worker-vm-size. Mer information finns i:Anslut till klustret genom att följa stegen i Ansluta till ett Azure Red Hat OpenShift 4-kluster.
- Följ stegen i "Installera OpenShift CLI"
- Ansluta till ett Azure Red Hat OpenShift-kluster med hjälp av OpenShift CLI med användaren
kubeadmin
Kör följande kommando för att skapa OpenShift-projektet för det här demoprogrammet:
oc new-project eap-demoKör följande kommando för att lägga till vyrollen i standardtjänstkontot. Den här rollen behövs så att programmet kan identifiera andra poddar och konfigurera ett kluster med dem:
oc policy add-role-to-user view system:serviceaccount:$(oc project -q):default -n $(oc project -q)
Förbereda programmet
Klona exempelprogrammet med följande kommando:
git clone https://github.com/Azure-Samples/jboss-on-aro-jakartaee
Du klonade Todo-list- demoprogram och din lokala lagringsplats finns på huvudgrenen. Demoprogrammet är en enkel Java-app som skapar, läser, uppdaterar och tar bort poster i Azure SQL. Du kan distribuera det här programmet som det är på en JBoss EAP-server som är installerad på den lokala datorn. Du behöver bara konfigurera servern med den databasdrivrutin och datakälla som krävs. Du behöver också en databasserver som är tillgänglig från din lokala miljö.
Men när du riktar in dig på OpenShift kanske du vill trimma funktionerna i din JBoss EAP-server. Du kanske till exempel vill minska säkerhetsexponeringen för den etablerade servern och minska det totala fotavtrycket. Du kanske också vill ta med några MicroProfile-specifikationer för att göra ditt program mer lämpligt för att köras i en OpenShift-miljö. När du använder JBoss EAP är ett sätt att utföra den här uppgiften genom att paketera programmet och servern i en enda distributionsenhet som kallas startbar JAR. Vi gör det genom att lägga till nödvändiga ändringar i vårt demoprogram.
Gå till din lokala lagringsplats för demoprogrammet och ändra grenen till startbar jar-:
## cd jboss-on-aro-jakartaee
git checkout bootable-jar
Nu ska vi göra en snabb genomgång av vad vi har ändrat i den här grenen:
- Vi har lagt till
wildfly-jar-mavenplugin-programmet för att etablera servern och programmet i en enda körbar JAR-fil. OpenShift-distributionsenheten är vår server med vårt program. - I Plugin-programmet Maven angav vi en uppsättning Galleon-lager. Med den här konfigurationen kan vi bara trimma serverfunktionerna till det vi behöver. Fullständig dokumentation om Galleon finns i WildFly-dokumentationen.
- Vårt program använder Jakarta Faces med Ajax-begäranden, vilket innebär att det finns information som lagras i HTTP-sessionen. Vi vill inte förlora sådan information om en podd tas bort. Vi kan spara den här informationen på klienten och skicka tillbaka den på varje begäran. Det finns dock fall där du kan besluta att inte distribuera viss information till klienterna. För den här demonstrationen valde vi att replikera sessionen över alla poddrepliker. För att göra det har vi lagt till
<distributable />i web.xml. Detta tillsammans med funktionerna för serverkluster gör ATT HTTP-sessionen kan distribueras mellan alla poddar. - Vi har lagt till två MicroProfile-hälsokontroller som gör att du kan identifiera när programmet är live och redo att ta emot begäranden.
Köra appen lokalt
Innan vi distribuerar programmet på OpenShift ska vi köra det lokalt för att kontrollera hur det fungerar. Följande steg förutsätter att du har Azure SQL igång och tillgängligt från din lokala miljö.
Om du vill skapa databasen följer du stegen i Snabbstart: Skapa en enkel Azure SQL Database-databas, men använd följande ersättningar.
- För Resursgrupp använder du den resursgrupp som du skapade tidigare.
- För Databasnamn använder du
todos_db. - För serveradministratörsinloggning använder du
azureuser. - För lösenordsanvändning
Passw0rd!. - I avsnittet Brandväggsregler växlar du tillåt att Azure-tjänster och resurser får åtkomst till den här servern till Ja.
Alla andra inställningar kan användas på ett säkert sätt från den länkade artikeln.
På sidan Ytterligare inställningar behöver du inte välja alternativet att fylla i databasen i förväg med exempeldata, men det skadar inte att göra det.
När du har skapat databasen hämtar du värdet för servernamnet från översiktssidan. Hovra musen över värdet i fältet Servernamn och välj den kopieringsikon som visas bredvid värdet. Spara det här värdet åt sidan för användning senare (vi anger en variabel med namnet MSSQLSERVER_HOST till det här värdet).
Kommentar
Snabbstarten instruerar läsaren att välja den serverlösa beräkningsnivån för att hålla nere de ekonomiska kostnaderna. Den här nivån skalas till noll när det inte finns någon aktivitet. När detta händer svarar inte databasen omedelbart. Om du vid något tillfälle när du utför stegen i den här artikeln upptäcker databasproblem bör du överväga att inaktivera Automatisk paus. Om du vill veta hur du söker efter automatisk paus i Azure SQL Database serverlös. I skrivande stund inaktiverar följande Azure CLI-kommando Automatisk paus för databasen som konfigureras i den här artikeln: az sql db update --resource-group $RESOURCEGROUP --server <Server name, without the .database.windows.net part> --name todos_db --auto-pause-delay -1
Följ nästa steg för att skapa och köra programmet lokalt.
Skapa den startbara JAR-filen. Eftersom vi använder
eap-datasources-galleon-packmed MS SQL Server-databasen måste vi ange den databasdrivrutinsversion som vi vill använda med den här specifika miljövariabeln. Mer information omeap-datasources-galleon-packoch MS SQL Server finns i dokumentationen från Red Hatexport MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 mvn clean packageStarta startbar JAR med hjälp av följande kommandon.
Du måste se till att Azure SQL-databasen tillåter nätverkstrafik från värden som servern körs på. Eftersom du har valt Lägg till aktuell klient-IP-adress när du utför stegen i Snabbstart: Skapa en enkel Azure SQL Database-databas, bör nätverkstrafiken tillåtas om värden där servern körs är samma värd som webbläsaren ansluter till Azure Portal. Om värden där servern körs är en annan värd måste du läsa Använda Azure Portal för att hantera IP-brandväggsregler på servernivå.
När vi startar programmet måste vi skicka de miljövariabler som krävs för att konfigurera datakällan:
export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:runOm du vill lära dig mer om den underliggande körning som används av den här demonstrationen har Galleon-funktionspaketet för integrering av dokumentationen för datakällor en fullständig lista över tillgängliga miljövariabler. Mer information om begreppet funktionspaket finns i WildFly-dokumentationen.
Om du får ett fel med text som liknar följande exempel:
Cannot open server '<your prefix>mysqlserver' requested by the login. Client with IP address 'XXX.XXX.XXX.XXX' is not allowed to access the server.Det här meddelandet anger att dina steg för att säkerställa att nätverkstrafiken är tillåten inte fungerade. Kontrollera att IP-adressen från felmeddelandet ingår i brandväggsreglerna.
Om du får ett meddelande med text som liknar följande exempel:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: There is already an object named 'TODOS' in the database.Det här meddelandet anger att exempeldata redan finns i databasen. Du kan ignorera det här meddelandet.
(Valfritt) Om du vill verifiera klustringsfunktionerna kan du även starta fler instanser av samma program genom att skicka argumentet till den startbara JAR-filen
jboss.node.nameoch, för att undvika konflikter med portnumren, flytta portnumren med hjälpjboss.socket.binding.port-offsetav . Om du till exempel vill starta en andra instans som representerar en ny podd i OpenShift kan du köra följande kommando i ett nytt terminalfönster:export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:run -Dwildfly.bootable.arguments="-Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000"Om klustret fungerar kan du se en spårning som liknar följande i serverkonsolloggen:
INFO [org.infinispan.CLUSTER] (thread-6,ejb,node) ISPN000094: Received new cluster view for channel ejbKommentar
Som standard konfigurerar startbar JAR JGroups-undersystemet för att använda UDP-protokollet och skickar meddelanden för att identifiera andra klustermedlemmar till multicast-adressen 230.0.0.4. För att verifiera klustringsfunktionerna på den lokala datorn korrekt bör operativsystemet kunna skicka och ta emot multicast-datagram och dirigera dem till IP-adressen 230.0.0.4 via ethernet-gränssnittet. Om du ser varningar relaterade till klustret i serverloggarna kontrollerar du nätverkskonfigurationen och kontrollerar att den stöder multicast på den adressen.
Öppna http://localhost:8080/ i webbläsaren för att besöka programmets startsida. Om du har skapat fler instanser kan du komma åt dem genom att flytta portnumret, till exempel http://localhost:9080/. Programmet bör se ut ungefär så här:
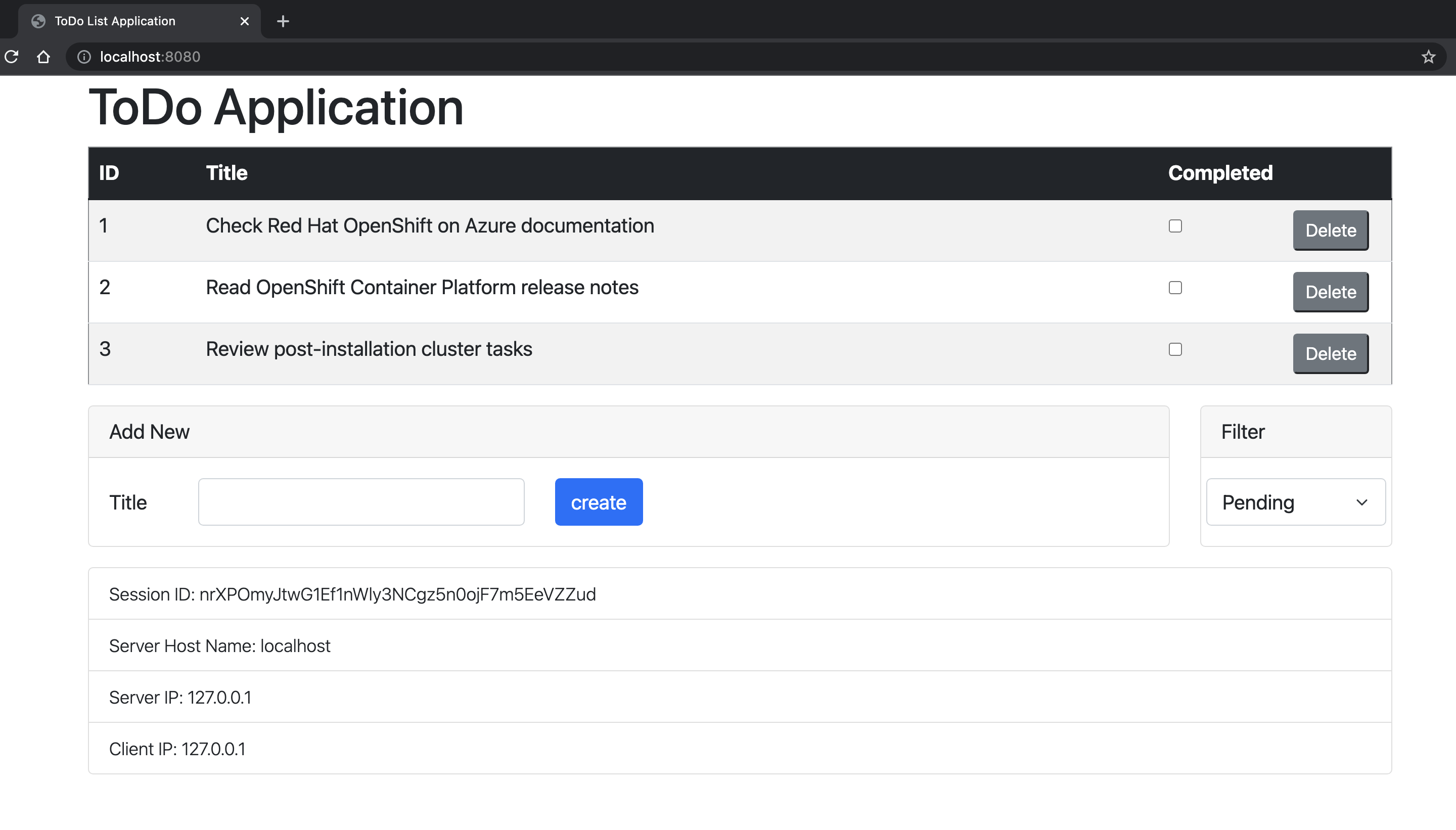
Kontrollera programmets liveness- och beredskapsavsökningar. OpenShift använder dessa slutpunkter för att verifiera när din podd är live och redo att ta emot användarbegäranden.
Om du vill kontrollera status för liveness kör du:
curl http://localhost:9990/health/liveDu bör se dessa utdata:
{"status":"UP","checks":[{"name":"SuccessfulCheck","status":"UP"}]}Om du vill kontrollera beredskapens status kör du:
curl http://localhost:9990/health/readyDu bör se dessa utdata:
{"status":"UP","checks":[{"name":"deployments-status","status":"UP","data":{"todo-list.war":"OK"}},{"name":"server-state","status":"UP","data":{"value":"running"}},{"name":"boot-errors","status":"UP"},{"name":"DBConnectionHealthCheck","status":"UP"}]}Tryck på Ctrl+C för att stoppa programmet.
Distribuera till OpenShift
För att distribuera programmet använder vi JBoss EAP Helm-diagram som redan är tillgängliga i Azure Red Hat OpenShift. Vi måste också ange önskad konfiguration, till exempel databasanvändaren, databaslösenordet, drivrutinsversionen som vi vill använda och anslutningsinformationen som används av datakällan. Följande steg förutsätter att du har Azure SQL som körs och är tillgängligt från ditt OpenShift-kluster och att du har lagrat databasens användarnamn, lösenord, värdnamn, port och databasnamn i ett OpenShift OpenShift Secret-objekt med namnet mssqlserver-secret.
Gå till din lokala lagringsplats för demoprogrammet och ändra den aktuella grenen till bootable-jar-openshift-:
git checkout bootable-jar-openshift
Nu ska vi göra en snabb genomgång av vad vi har ändrat i den här grenen:
- Vi har lagt till en ny Maven-profil med namnet
bootable-jar-openshiftsom förbereder startbar JAR med en specifik konfiguration för att köra servern i molnet. Det gör till exempel att JGroups-undersystemet kan använda nätverksbegäranden för att identifiera andra poddar med hjälp av KUBE_PING protokollet. - Vi har lagt till en uppsättning konfigurationsfiler i katalogen jboss-on-aro-jakartaee/deployment . I den här katalogen hittar du konfigurationsfilerna för att distribuera programmet.
Distribuera programmet på OpenShift
I nästa steg förklaras hur du kan distribuera programmet med ett Helm-diagram med hjälp av OpenShift-webbkonsolen. Undvik hårdkodning av känsliga värden i Helm-diagrammet med hjälp av en funktion som kallas "hemligheter". En hemlighet är helt enkelt en samling namn/värde-par, där värdena anges på någon känd plats innan de behövs. I vårt fall använder Helm-diagrammet två hemligheter, med följande namn/värde-par från var och en.
mssqlserver-secret-
db-hostförmedlar värdet förMSSQLSERVER_HOST. -
db-nameförmedlar värdet avMSSQLSERVER_DATABASE -
db-passwordförmedlar värdet avMSSQLSERVER_PASSWORD -
db-portförmedlar värdet förMSSQLSERVER_PORT. -
db-userförmedlar värdet förMSSQLSERVER_USER.
-
todo-list-secret-
app-cluster-passwordförmedlar ett godtyckligt, användardefingivet lösenord så att klusternoder kan bildas säkrare. -
app-driver-versionförmedlar värdet förMSSQLSERVER_DRIVER_VERSION. -
app-ds-jndiförmedlar värdet förMSSQLSERVER_JNDI.
-
Skapa
mssqlserver-secret.oc create secret generic mssqlserver-secret \ --from-literal db-host=${MSSQLSERVER_HOST} \ --from-literal db-name=${MSSQLSERVER_DATABASE} \ --from-literal db-password=${MSSQLSERVER_PASSWORD} \ --from-literal db-port=${MSSQLSERVER_PORT} \ --from-literal db-user=${MSSQLSERVER_USER}Skapa
todo-list-secret.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 oc create secret generic todo-list-secret \ --from-literal app-cluster-password=mut2UTG6gDwNDcVW \ --from-literal app-driver-version=${MSSQLSERVER_DRIVER_VERSION} \ --from-literal app-ds-jndi=${MSSQLSERVER_JNDI}Öppna OpenShift-konsolen och gå till utvecklarvyn. Du kan identifiera konsol-URL:en för ditt OpenShift-kluster genom att köra det här kommandot. Logga in med
kubeadminuserid och lösenord som du fick från föregående steg.az aro show \ --name $CLUSTER \ --resource-group $RESOURCEGROUP \ --query "consoleProfile.url" \ --output tsvVälj perspektivet </> Utvecklare i den nedrullningsbara menyn överst i navigeringsfönstret.
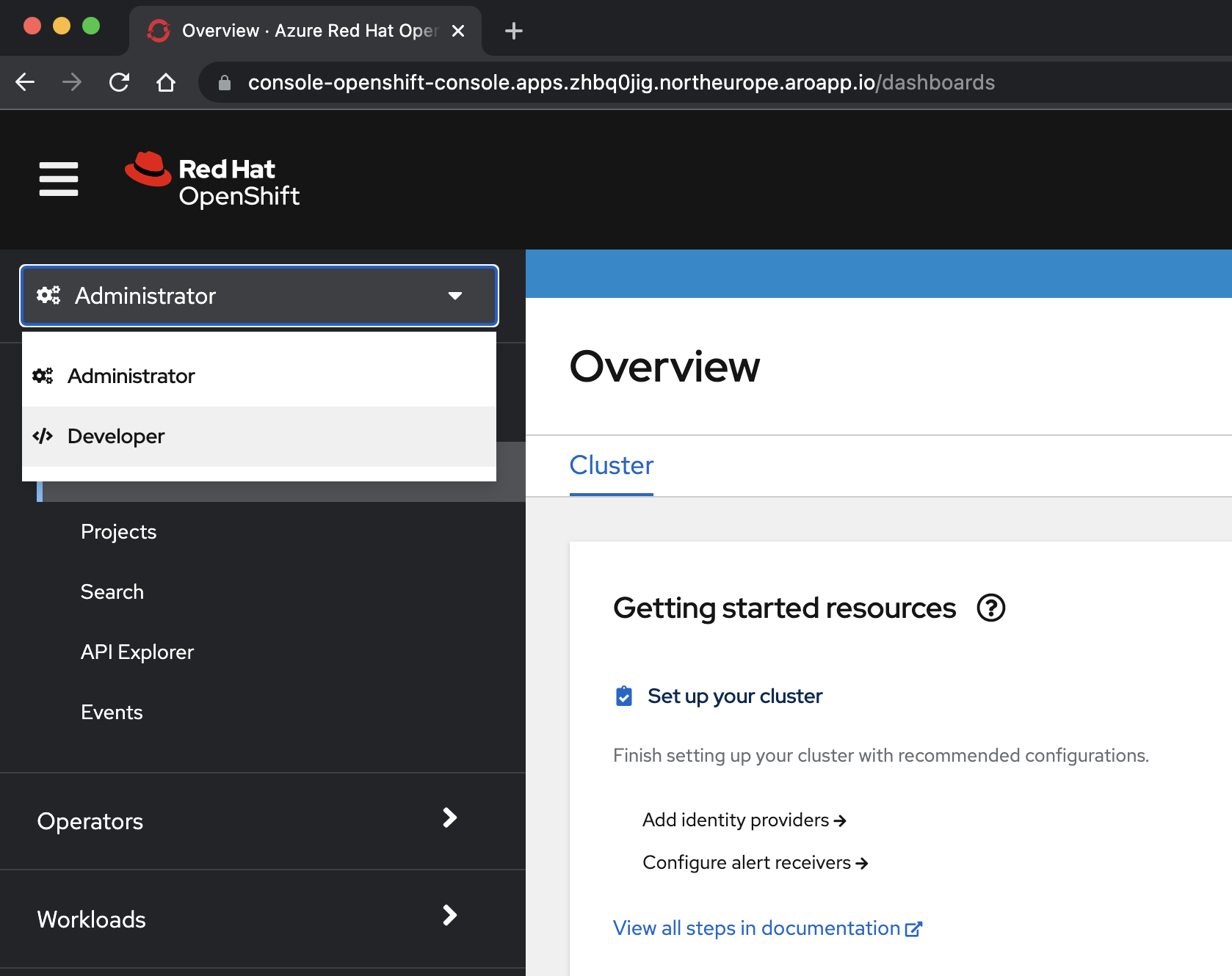
I perspektivet /Utvecklare väljer du < på den >.
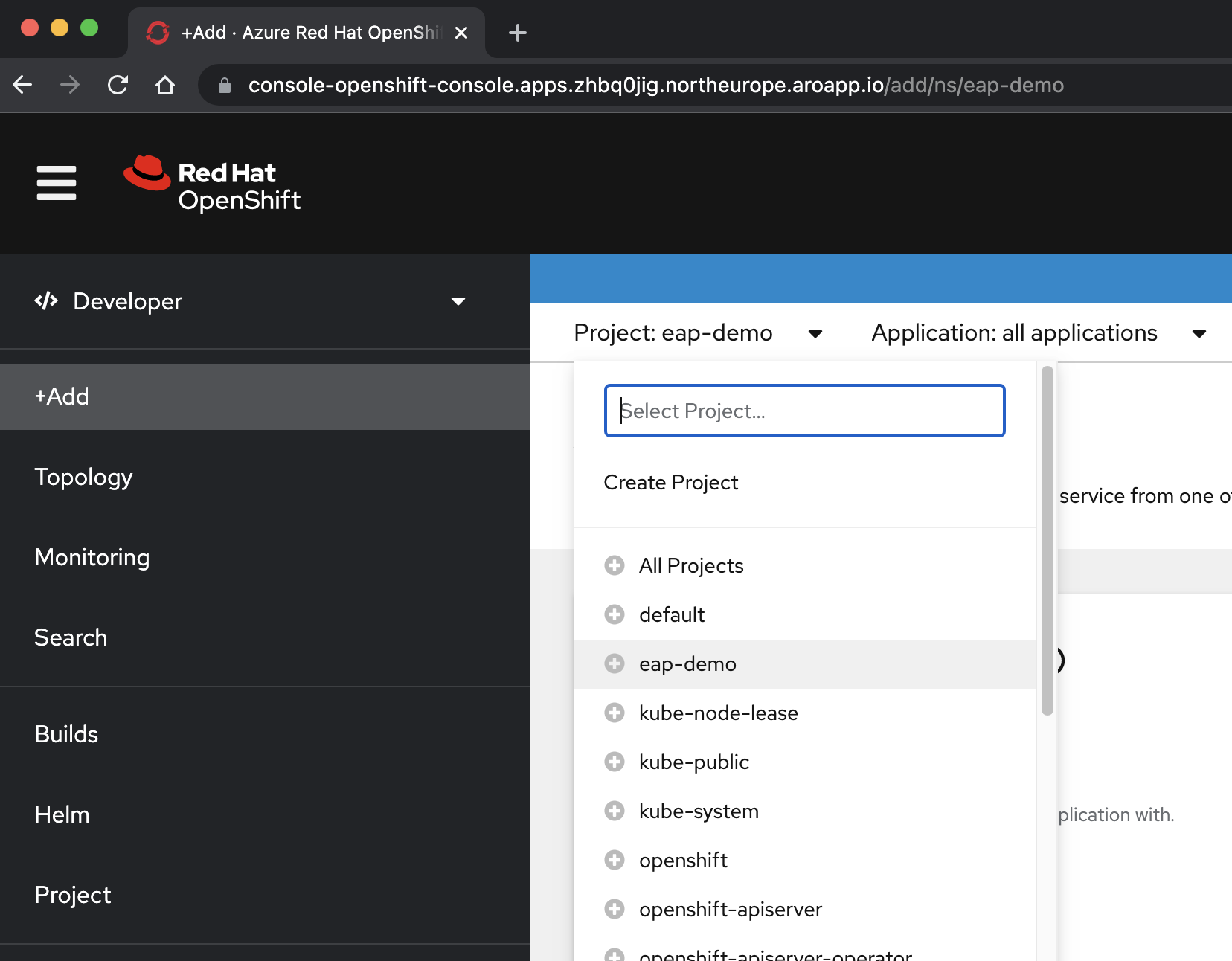
Välj +Lägg till. I avsnittet Utvecklarkatalog väljer du Helm-diagram. Du kommer till Helm Chart-katalogen som är tillgänglig i ditt Azure Red Hat OpenShift-kluster. I rutan Filtrera efter nyckelord skriver du eap. Du bör se flera alternativ, som du ser här:
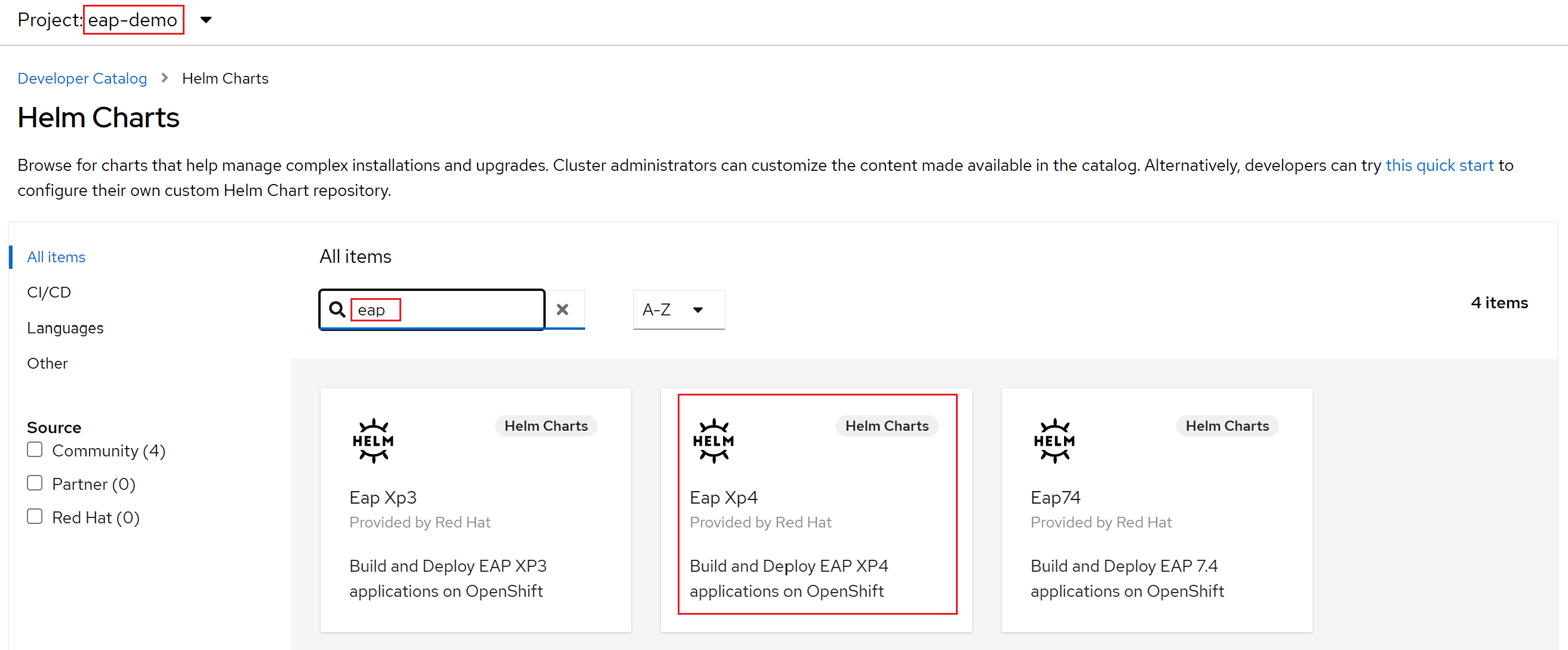
Eftersom vårt program använder MicroProfile-funktioner väljer vi Helm-diagrammet för EAP Xp. "Xp" står för Expansion Pack. Med expansionspaketet JBoss Enterprise Application Platform kan utvecklare använda API:er (Eclipse MicroProfile Application Programming Interfaces) för att skapa och distribuera mikrotjänstbaserade program.
Välj Helm-diagrammet JBoss EAP XP 4 och välj sedan Installera Helm-diagram.
Nu måste vi konfigurera diagrammet för att skapa och distribuera programmet:
Ändra namnet på versionen till eap-todo-list-demo.
Vi kan konfigurera Helm-diagrammet antingen med hjälp av en formulärvy eller en YAML-vy. I avsnittet Konfigurera via väljer du YAML-vy.
Ändra YAML-innehållet för att konfigurera Helm-diagrammet genom att kopiera och klistra in innehållet i Helm Chart-filen som är tillgänglig vid distribution/program/todo-list-helm-chart.yaml i stället för det befintliga innehållet:

Det här innehållet refererar till de hemligheter som du angav tidigare.
Välj slutligen Installera för att starta programdistributionen. Den här åtgärden öppnar topologivyn med en grafisk representation av Helm-versionen (med namnet eap-todo-list-demo) och dess associerade resurser.
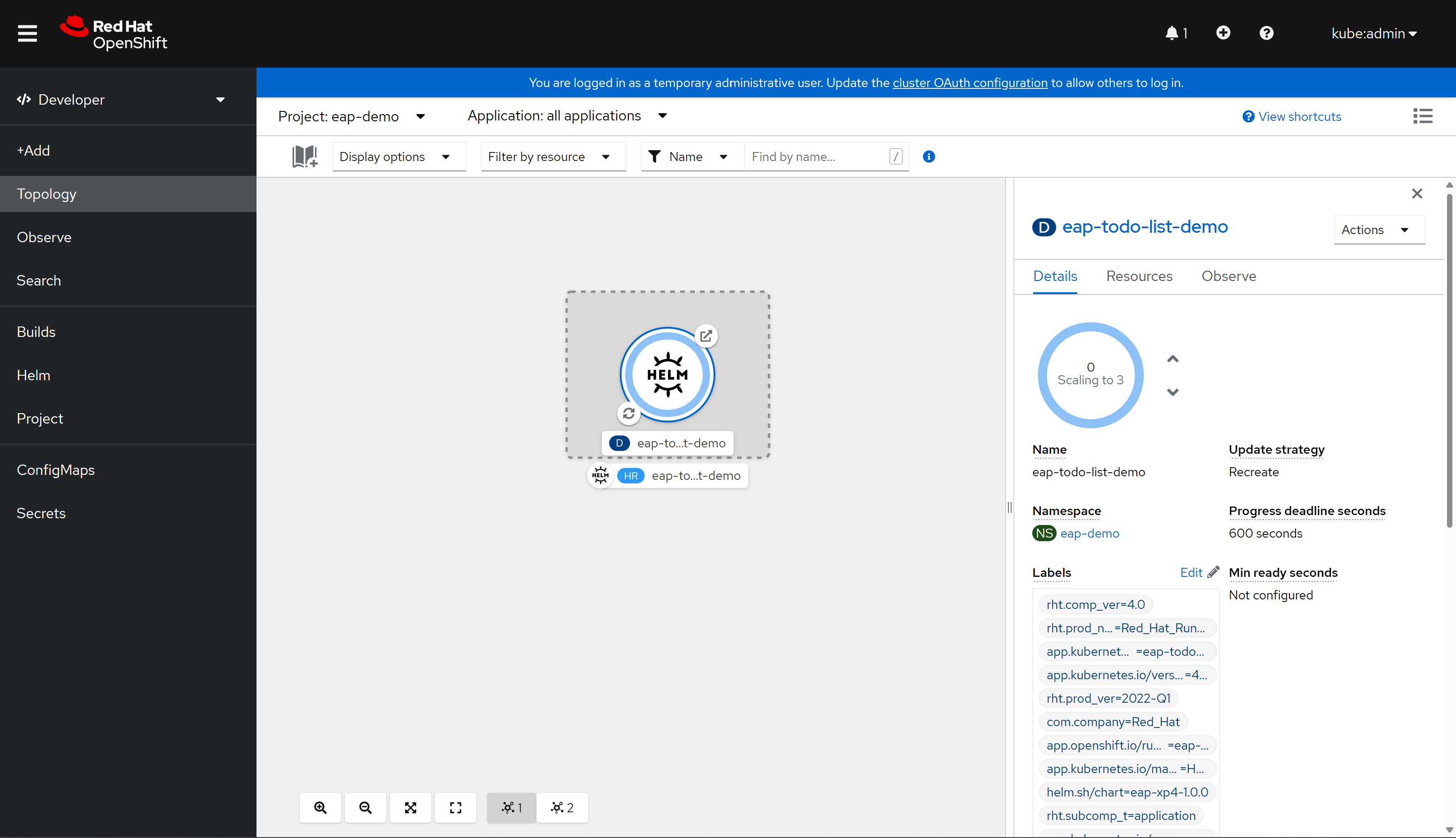
Helm-versionen (förkortad HR) heter eap-todo-list-demo. Den innehåller en distributionsresurs (förkortad D) med namnet eap-todo-list-demo.
Om du väljer ikonen med två pilar i en cirkel längst ned till vänster i rutan D tas du till fönstret Loggar . Här kan du se förloppet för bygget. Om du vill återgå till topologivyn väljer du Topologi i det vänstra navigeringsfönstret.
När bygget är klart visar ikonen längst ned till vänster en grön kontroll.
När distributionen är klar är cirkeldispositionen mörkblå. Om du håller muspekaren över den mörkblå bör du se ett meddelande som anger något som liknar
3 Running. När du ser meddelandet kan du gå till programmet url:en (med hjälp av ikonen längst upp till höger) från den väg som är associerad med distributionen.
Programmet öppnas i webbläsaren och liknar följande bild som är redo att användas:
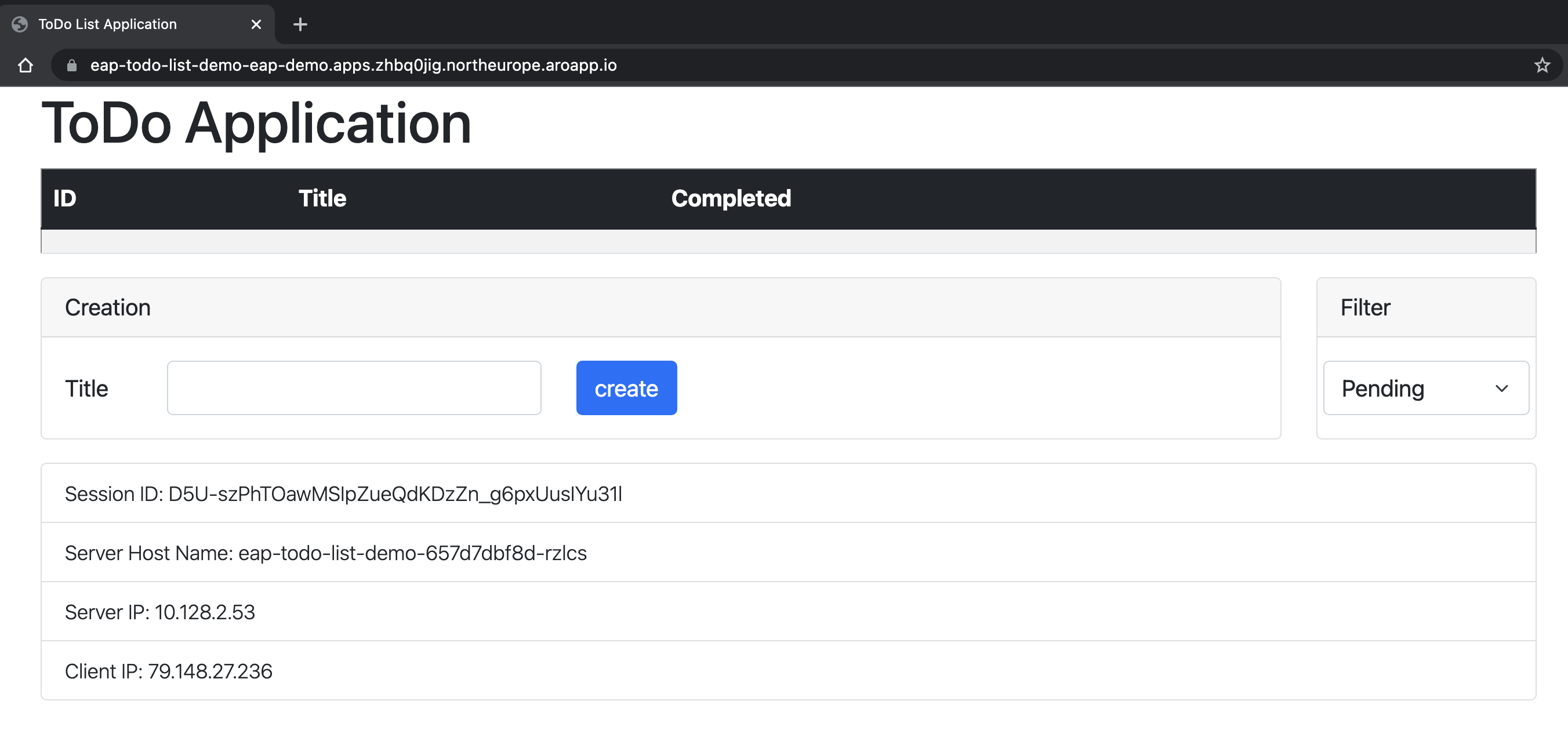
Programmet visar namnet på podden som hanterar informationen. Om du vill verifiera klustringsfunktionerna kan du lägga till några Todo- objekt. Ta sedan bort podden med det namn som anges i fältet Servervärdnamn som visas i programmet med hjälp
oc delete pod <pod-name>av . När du har raderat podden skapar du en ny Todo i samma programfönster. Du kan se att den nya Todo läggs till via en Ajax-begäran och fältet servervärdnamn visar nu ett annat namn. I bakgrunden skickade OpenShift-lastbalanseraren den nya begäran och levererade den till en tillgänglig podd. Vyn Jakarta Faces återställs från HTTP-sessionskopian som lagras i podden som bearbetar begäran. Du kan faktiskt se att fältet Sessions-ID inte har ändrats. Om sessionen inte replikeras mellan dina poddar får du ett Jakarta-ansiktenViewExpiredExceptionoch programmet fungerar inte som förväntat.

Rensa resurser
Ta bort programmet
Om du bara vill ta bort ditt program kan du öppna OpenShift-konsolen och gå till menyalternativet Helm i utvecklarvyn. På den här menyn kan du se alla Helm Chart-versioner installerade i klustret.

Leta upp eap-todo-list-demo Helm Chart. I slutet av raden väljer du de lodräta trädpunkterna för att öppna snabbmenyposten för åtgärden.
Välj Avinstallera Helm-versionen för att ta bort programmet. Observera att det hemliga objekt som används för att ange programkonfigurationen inte ingår i diagrammet. Du måste ta bort den separat om du inte längre behöver den.
Kör följande kommando om du vill ta bort hemligheten som innehåller programkonfigurationen:
$ oc delete secrets/todo-list-secret
# secret "todo-list-secret" deleted
Ta bort OpenShift-projektet
Du kan också ta bort all konfiguration som skapats för den här demonstrationen eap-demo genom att ta bort projektet. Kör följande kommando för att göra det:
$ oc delete project eap-demo
# project.project.openshift.io "eap-demo" deleted
Ta bort Azure Red Hat OpenShift-klustret
Ta bort Azure Red Hat OpenShift-klustret genom att följa stegen i Självstudie: Ta bort ett Azure Red Hat OpenShift 4-kluster.
Ta bort resursgruppen
Om du vill ta bort alla resurser som skapades i föregående steg tar du bort resursgruppen som du skapade för Azure Red Hat OpenShift-klustret.
Nästa steg
Du kan lära dig mer från referenser som används i den här guiden:
- Red Hat JBoss Enterprise Application Platform
- Azure Red Hat OpenShift
- JBoss EAP Helm-diagram
- JBoss EAP Startbar JAR
Fortsätt att utforska alternativ för att köra JBoss EAP på Azure.