Använda Apache Kafka® i HDInsight med Apache Flink® i HDInsight på AKS
Kommentar
Vi drar tillbaka Azure HDInsight på AKS den 31 januari 2025. Före den 31 januari 2025 måste du migrera dina arbetsbelastningar till Microsoft Fabric eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar. Återstående kluster i din prenumeration stoppas och tas bort från värden.
Endast grundläggande stöd kommer att vara tillgängligt fram till datumet för pensionering.
Viktigt!
Den här funktionen finns i förhandsgranskning. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. Om du vill ha frågor eller funktionsförslag skickar du en begäran på AskHDInsight med informationen och följer oss för fler uppdateringar i Azure HDInsight Community.
Ett välkänt användningsfall för Apache Flink är stream analytics. Det populära valet av många användare att använda dataströmmarna, som matas in med Apache Kafka. Typiska installationer av Flink och Kafka börjar med händelseströmmar som skickas till Kafka, som kan användas av Flink-jobb.
I det här exemplet används HDInsight i AKS-kluster som kör Flink 1.17.0 för att bearbeta strömningsdata som förbrukar och producerar Kafka-ämnet.
Kommentar
FlinkKafkaConsumer är inaktuell och tas bort med Flink 1.17. Använd KafkaSource i stället. FlinkKafkaProducer är inaktuell och tas bort med Flink 1.15, använd KafkaSink i stället.
Förutsättningar
Både Kafka och Flink måste finnas i samma virtuella nätverk eller så bör det finnas vnet-peering mellan de två klustren.
Skapa ett Kafka-kluster i samma virtuella nätverk. Du kan välja Kafka 3.2 eller 2.4 i HDInsight baserat på din aktuella användning.
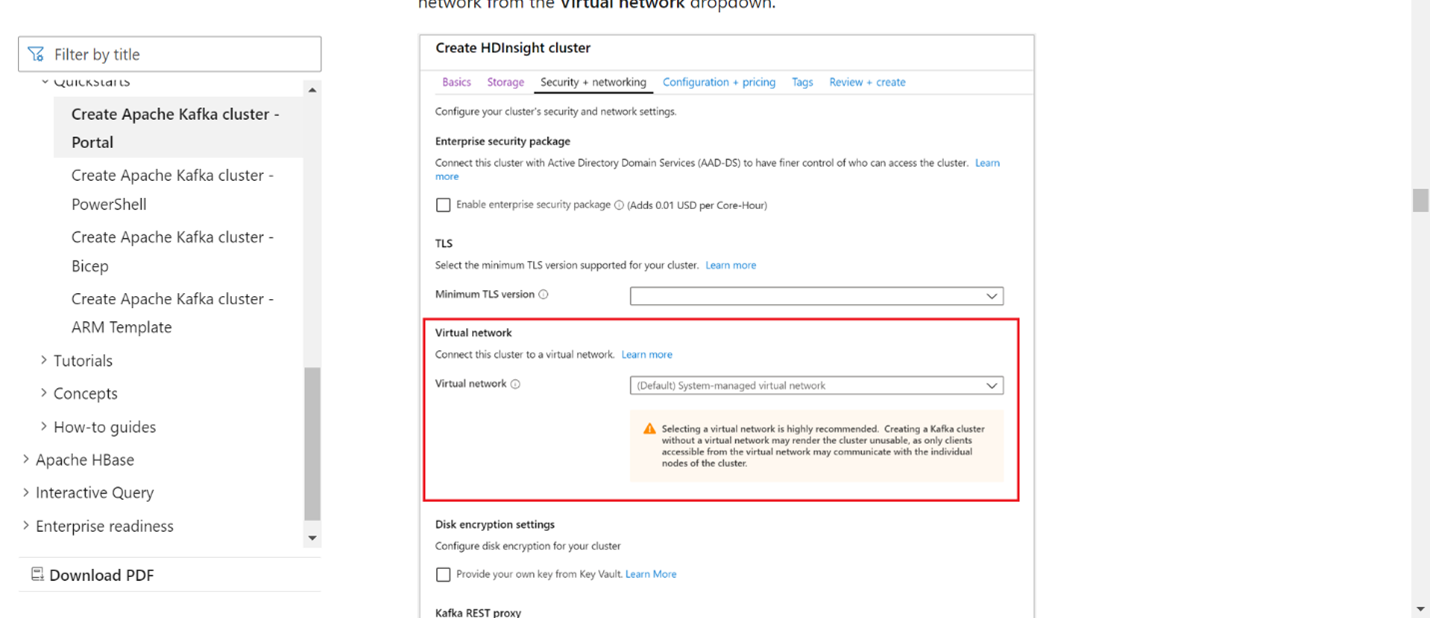
Lägg till VNet-information i avsnittet virtuellt nätverk.
Skapa en HDInsight på AKS-klusterpoolen med samma virtuella nätverk.
Skapa ett Flink-kluster till klusterpoolen som skapats.

Apache Kafka-anslutningsprogram
Flink tillhandahåller en Apache Kafka Connector för att läsa data från och skriva data till Kafka-ämnen med exakt en gång garantier.
Maven-beroende
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Skapa Kafka-mottagare
Kafka-mottagare tillhandahåller en builder-klass för att konstruera en instans av en KafkaSink. Vi använder samma för att konstruera vår mottagare och använda den tillsammans med Flink-kluster som körs på HDInsight på AKS
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Skriva ett Java-program Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Paketera jar-filen och skicka jobbet till Flink
Ladda upp jar-filen på Webssh och skicka jar-filen

Användargränssnitt för Flink-instrumentpanel

Skapa ämnet – klickar på Kafka

Använda ämnet – händelser på Kafka

Referens
- Apache Kafka-anslutningsprogram
- Apache, Apache Kafka, Kafka, Apache Flink, Flink och associerade öppen källkod projektnamn är varumärken som tillhör Apache Software Foundation (ASF).