OutOfMemoryError-undantag för Apache Spark i Azure HDInsight
Den här artikeln beskriver felsökningssteg och möjliga lösningar på problem när du använder Apache Spark-komponenter i Azure HDInsight-kluster.
Scenario: OutOfMemoryError-undantag för Apache Spark
Problem
Apache Spark-programmet misslyckades med ett ohanterat Undantag från OutOfMemoryError. Du kan få ett felmeddelande som liknar:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Orsak
Den troligaste orsaken till det här undantaget är att inte tillräckligt med heapminne allokeras till de virtuella Java-datorerna (JVM). Dessa JVM:er startas som köre eller drivrutiner som en del av Apache Spark-programmet.
Åtgärd
Fastställa den maximala storleken på de data som Spark-programmet hanterar. Gör en uppskattning av storleken baserat på den maximala storleken för indata, mellanliggande data som skapas genom att transformera indata och utdata som skapas genom ytterligare transformering av mellanliggande data. Om den första uppskattningen inte är tillräcklig ökar du storleken något och itererar tills minnesfelen avtar.
Se till att HDInsight-klustret som ska användas har tillräckligt med resurser när det gäller minne och tillräckligt med kärnor för Spark-programmet. Detta kan fastställas genom att visa avsnittet Klustermått i YARN-användargränssnittet i klustret för värdena för Minnesanvändning jämfört med Total minnesanvändning och Antal virtuella kärnor som används jämfört med totalt antal virtuella kärnor.

Ange lämpliga värden för följande Spark-konfigurationer. Balansera programkraven med tillgängliga resurser i klustret. Dessa värden får inte överstiga 90 % av det tillgängliga minnet och kärnorna enligt YARN och bör även uppfylla minimikraven för minne i Spark-programmet:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Totalt minne som används av alla köre =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Totalt minne som används av drivrutinen =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Scenario: Fel med Java-heaputrymme vid försök att öppna Apache Spark-historikservern
Problem
Du får följande fel när du öppnar händelser i Spark-historikservern:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Orsak
Det här problemet orsakas ofta av brist på resurser när du öppnar stora spark-event-filer. Spark-heapstorleken är inställd på 1 GB som standard, men stora Spark-händelsefiler kan kräva mer än så.
Om du vill kontrollera storleken på de filer som du försöker läsa in kan du utföra följande kommandon:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Åtgärd
Du kan öka Spark History Server-minnet genom att redigera SPARK_DAEMON_MEMORY egenskapen i Spark-konfigurationen och starta om alla tjänster.
Du kan göra detta inifrån Ambari-webbläsarens användargränssnitt genom att välja avsnittet Spark2/Config/Advanced spark2-env.
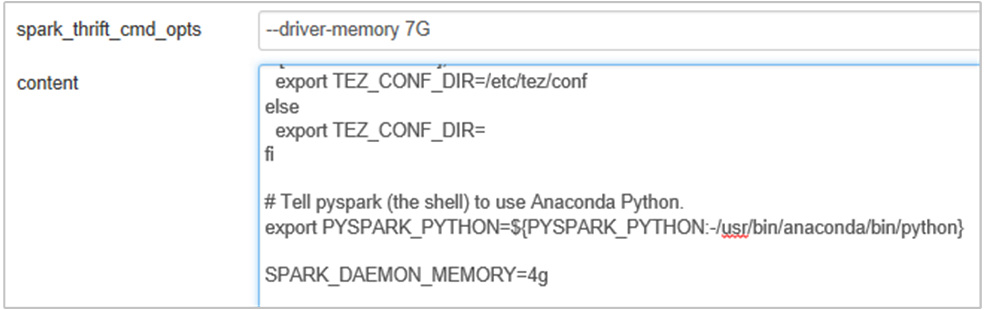
Lägg till följande egenskap för att ändra Spark History Server-minnet från 1g till 4g: SPARK_DAEMON_MEMORY=4g.
Se till att starta om alla berörda tjänster från Ambari.
Scenario: Livy Server kan inte starta i Apache Spark-kluster
Problem
Livy Server kan inte startas på en Apache Spark [(Spark 2.1 på Linux (HDI 3.6)]. Försök att starta om resulterar i följande felstack från Livy-loggarna:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Orsak
java.lang.OutOfMemoryError: unable to create new native thread highlights OS kan inte tilldela fler interna trådar till JVM:er. Bekräftat att det här undantaget orsakas av brott mot gränsen för antal trådar per process.
När Livy Server avslutas oväntat avslutas även alla anslutningar till Spark-kluster, vilket innebär att alla jobb och relaterade data går förlorade. I HDP 2.6-sessionsåterställningsmekanismen introducerades lagrar Livy sessionsinformationen i Zookeeper som ska återställas efter att Livy Server är tillbaka.
När så många jobb skickas via Livy, som en del av Hög tillgänglighet för Livy Server, lagrar dessa sessionstillstånd i ZK (på HDInsight-kluster) och återställer dessa sessioner när Livy-tjänsten startas om. Vid omstart efter oväntad avslutning skapar Livy en tråd per session och detta ackumulerar några att återställa sessioner som orsakar för många trådar som skapas.
Åtgärd
Ta bort alla poster med hjälp av följande steg.
Hämta IP-adressen för zookeeper-noderna med hjälp av
grep -R zk /etc/hadoop/confOvanstående kommando listade alla zookeepers för ett kluster
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Hämta alla IP-adresser för zookeeper-noderna med ping eller så kan du även ansluta till zookeeper från huvudnod med zookeepernamn
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181När du är ansluten kör zookeeper följande kommando för att visa en lista över alla sessioner som försöker starta om.
De flesta av fallen kan vara en lista över fler än 8 000 sessioner ####
ls /livy/v1/batchFöljande kommando är att ta bort alla sessioner som ska återställas. #####
rmr /livy/v1/batch
Vänta tills kommandot ovan har slutförts och markören returnerar kommandotolken och startar sedan om Livy-tjänsten från Ambari, vilket ska lyckas.
Kommentar
DELETE den liviga sessionen när den har slutfört sin körning. Livy-batchsessionerna tas inte bort automatiskt så snart spark-appen har slutförts, vilket är avsiktligt. En Livy-session är en entitet som skapats av en POST-begäran mot Livy REST-servern. Ett DELETE anrop krävs för att ta bort entiteten. Eller så borde vi vänta tills GC börjar.
Nästa steg
Om du inte ser problemet eller inte kan lösa problemet går du till någon av följande kanaler för mer support:
Översikt över Spark-minneshantering.
Få svar från Azure-experter via Azure Community Support.
Anslut med @AzureSupport – det officiella Microsoft Azure-kontot för att förbättra kundupplevelsen. Ansluta Azure-communityn till rätt resurser: svar, support och experter.
Om du behöver mer hjälp kan du skicka en supportbegäran från Azure Portal. Välj Support i menyraden eller öppna hubben Hjälp + support . Mer detaljerad information finns i Skapa en Azure Support begäran. Tillgång till support för prenumerationshantering och fakturering ingår i din Microsoft Azure-prenumeration och teknisk support ges via ett supportavtal för Azure.