Självstudie: Skicka data från en OPC UA-server till Azure Data Lake Storage Gen 2
I snabbstarten skapade du ett dataflöde som skickar data från Azure IoT Operations till Event Hubs och sedan till Microsoft Fabric via EventStreams.
Men det går också att skicka data direkt till en lagringsslutpunkt utan att använda Event Hubs. Den här metoden kräver att du skapar ett Delta Lake-schema som representerar data, laddar upp schemat till Azure IoT Operations och sedan skapar ett dataflöde som läser data från OPC UA-servern och skriver det till lagringsslutpunkten.
Den här självstudien bygger på snabbstartskonfigurationen och visar hur du bifurcate data till Azure Data Lake Storage Gen 2. Med den här metoden kan du lagra data direkt i en skalbar och säker datasjö, som kan användas för ytterligare analys och bearbetning.
Förutsättningar
Slutför det andra steget i snabbstarten som hämtar data från OPC UA-servern till Azure IoT Operations MQTT-koordinatorn. Se till att du kan se data i Event Hubs.
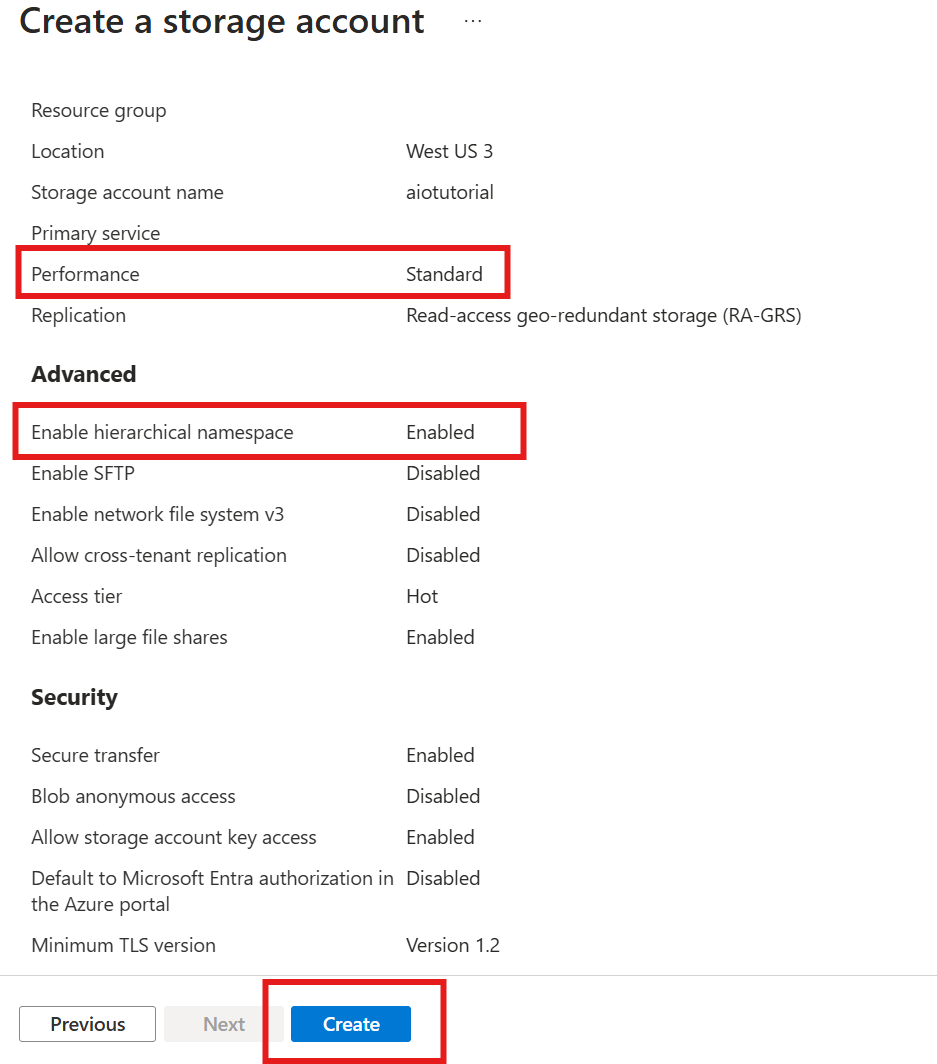
Skapa ett lagringskonto med Data Lake Storage-kapacitet
Följ först stegen för att skapa ett lagringskonto med Data Lake Storage Gen 2-kapacitet.
- Välj ett minnesvärt men unikt namn för lagringskontot eftersom det behövs i nästa steg.
- För bästa resultat använder du en plats som ligger nära Kubernetes-klustret där Azure IoT Operations körs.
- Aktivera inställningen Hierarkisk namnrymd under skapandeprocessen. Den här inställningen krävs för att Azure IoT Operations ska kunna skriva till lagringskontot.
- Du kan lämna andra inställningar som standard.
I steget Granska kontrollerar du inställningarna och väljer Skapa för att skapa lagringskontot.
Hämta tilläggsnamnet för Azure IoT Operations
I Azure Portal hittar du den Azure IoT Operations-instans som du skapade i snabbstarten. På bladet Översikt hittar du avsnittet Arc-tillägg och ser namnet på tillägget. Det bör se ut som azure-iot-operations-xxxxx.
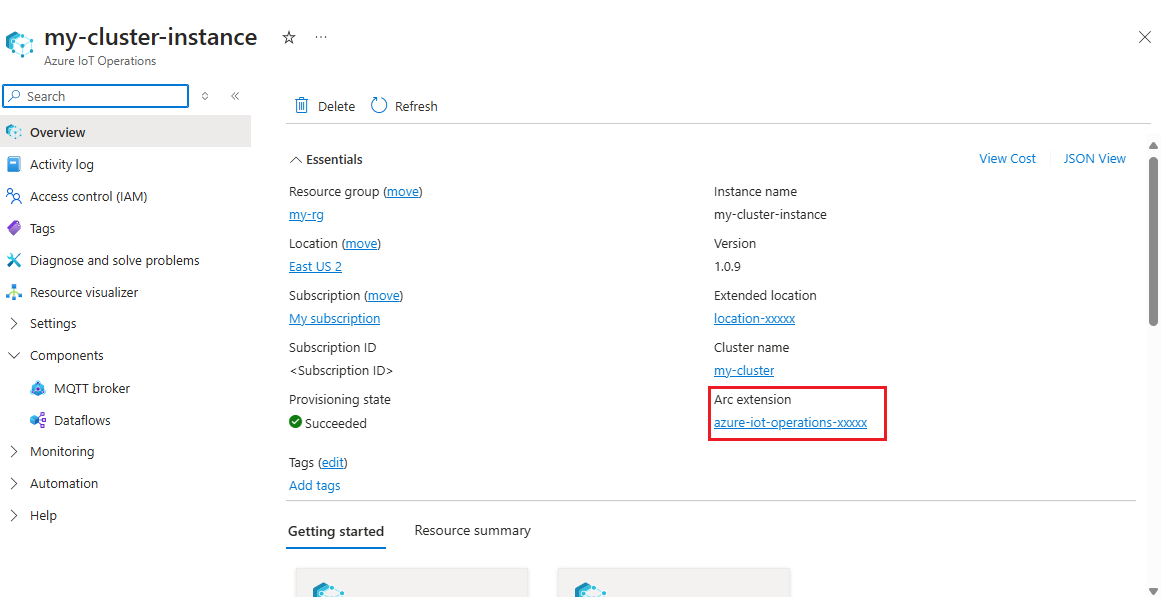
Det här tilläggsnamnet används i nästa steg för att tilldela behörigheter till lagringskontot.
Tilldela behörighet till Azure IoT Operations för att skriva till lagringskontot
Gå först till bladet Åtkomstkontroll (IAM) i lagringskontot och välj + Lägg till rolltilldelning. På bladet Lägg till rolltilldelning söker du efter rollen Storage Blob Data-deltagare och väljer den.
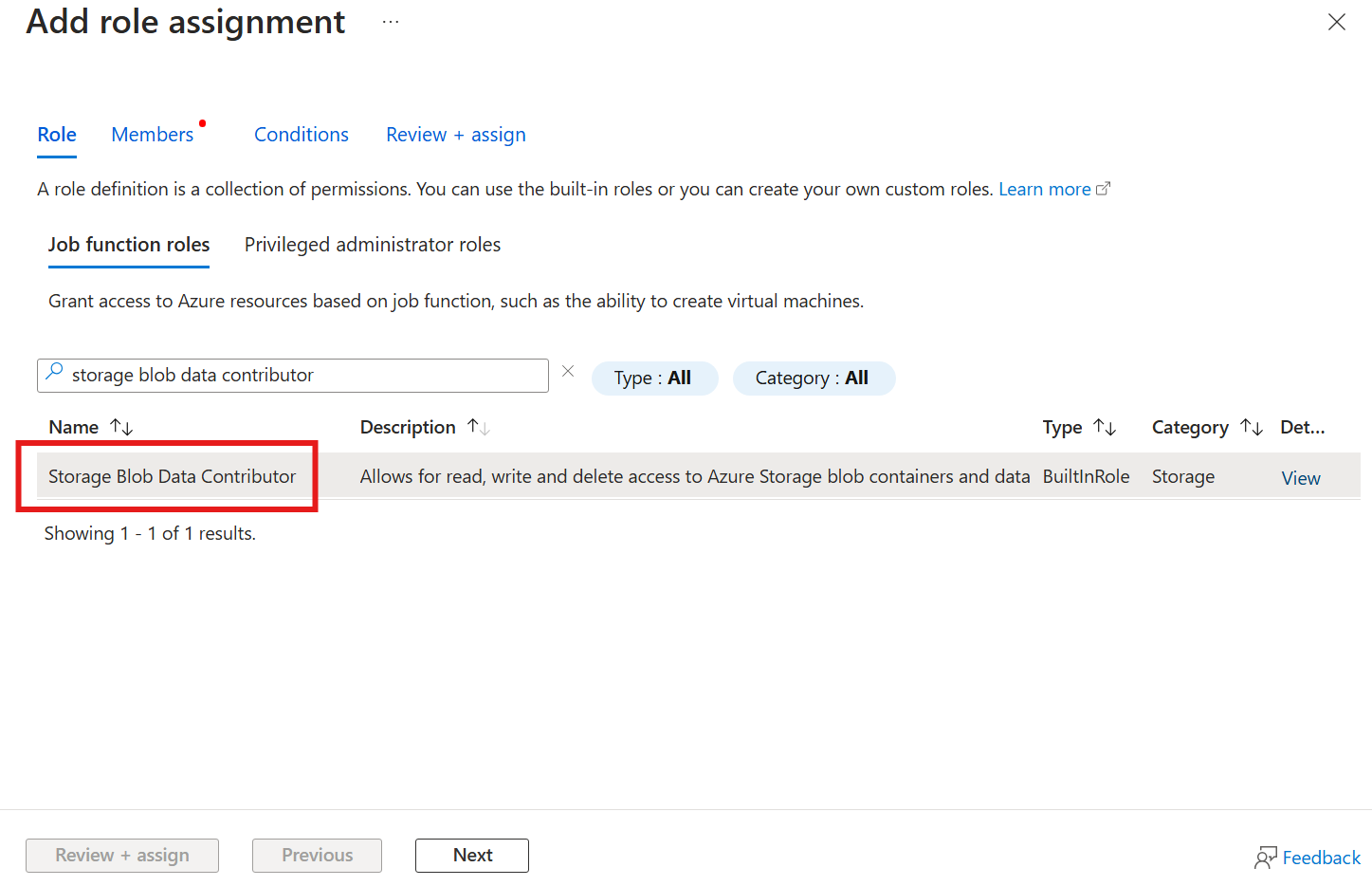
Välj sedan Nästa för att gå till avsnittet Medlemmar .
Välj sedan Välj medlemmar och i rutan Välj söker du efter den hanterade identiteten för Azure IoT Operations Arc-tillägget med namnet azure-iot-operations-xxxxx och väljer det.
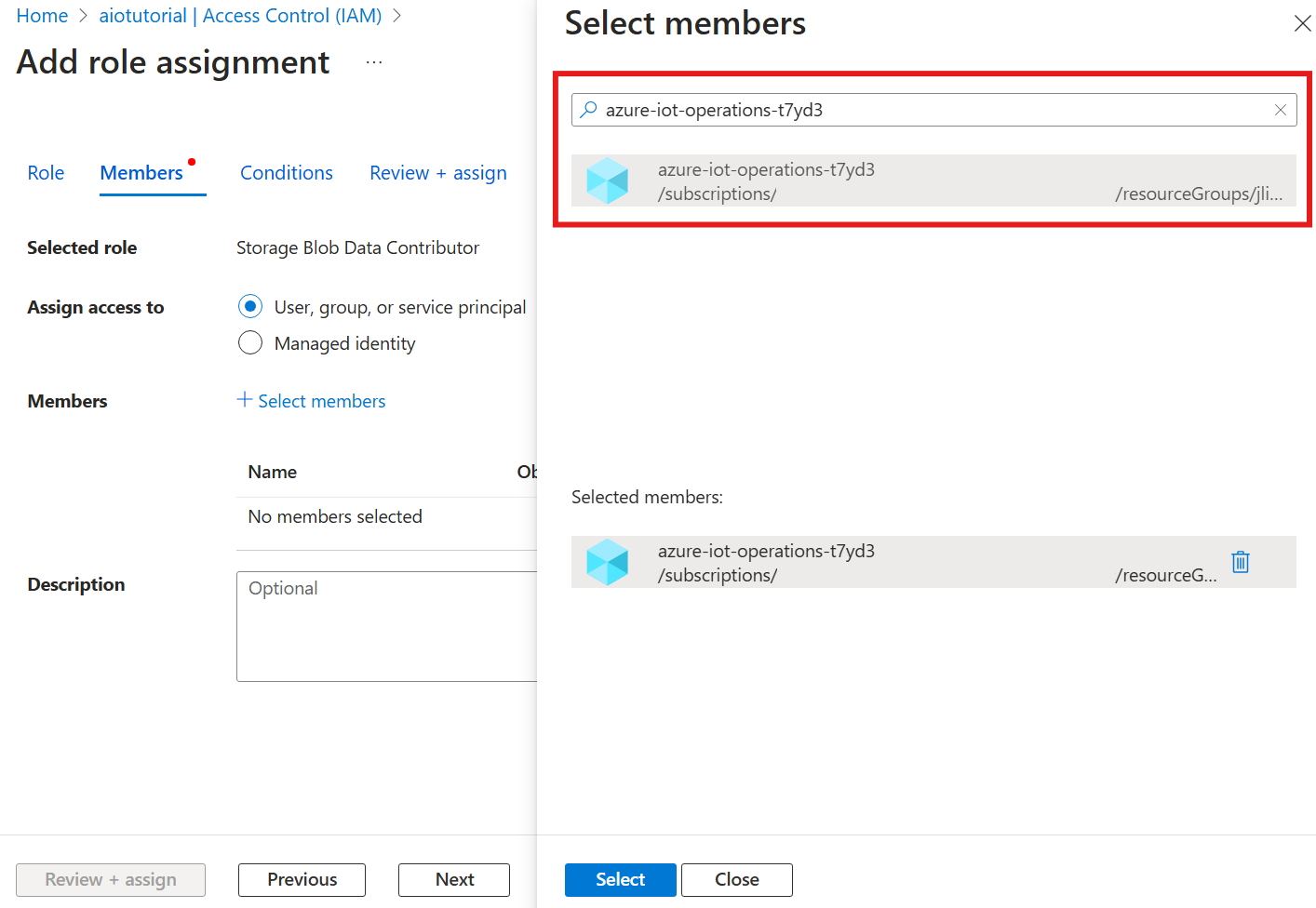
Slutför tilldelningen med Granska + tilldela.
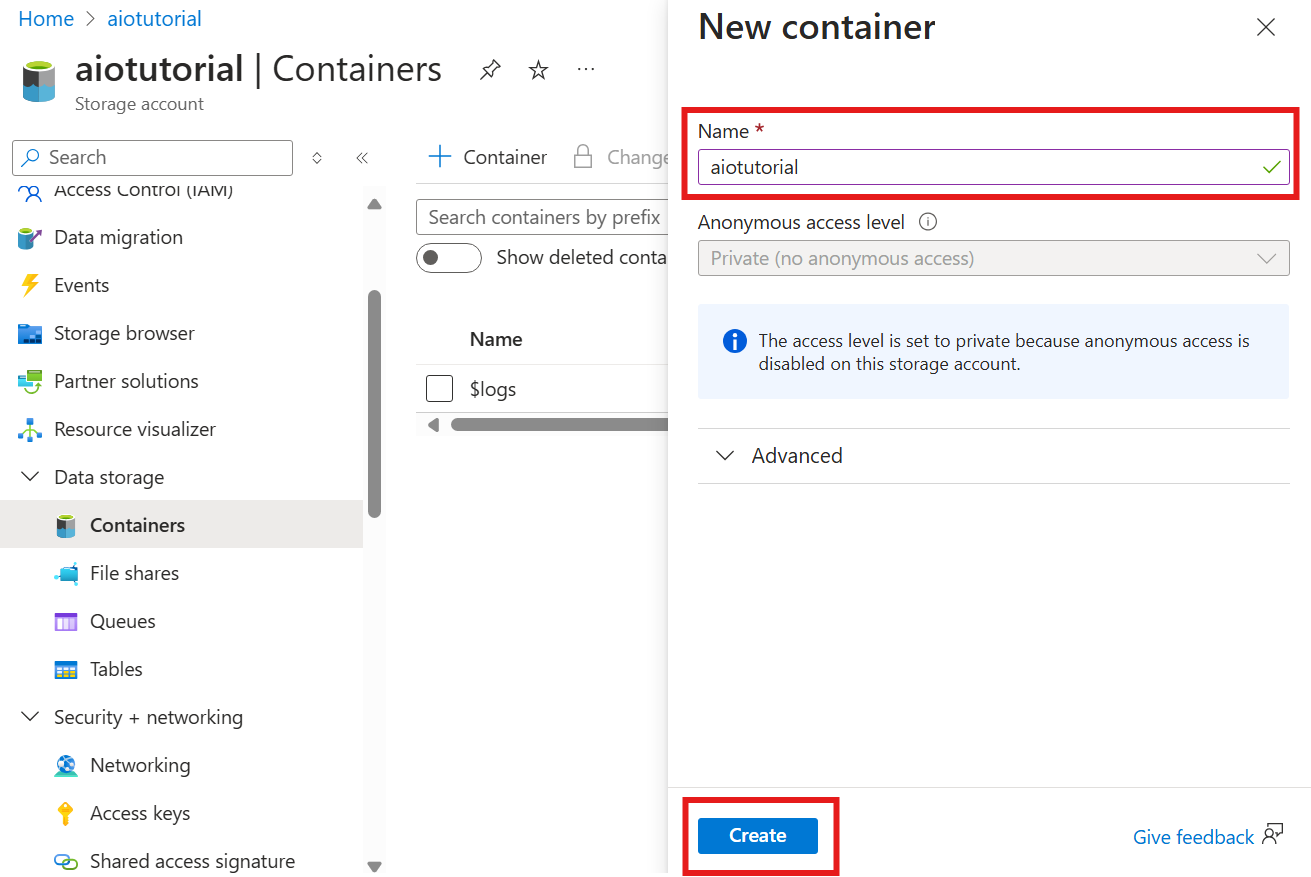
Skapa en container i lagringskontot
I lagringskontot går du till bladet Containrar och väljer + Container. I den här självstudien namnger du containern aiotutorial. Välj Skapa för att skapa containern.
Hämta schemaregistrets namn och namnområde
Om du vill ladda upp schemat till Azure IoT Operations behöver du känna till schemaregistrets namn och namnområde. Du kan hämta den här informationen med hjälp av Azure CLI.
Kör följande kommando för att hämta schemaregistrets namn och namnområde. Ersätt platshållarna med värdena.
az iot ops schema registry list -g <RESOURCE_GROUP> --query "[0].{name: name, namespace: properties.namespace}" -o tsv
Resultatet bör se ut så här:
<REGISTRY_NAME> <SCHEMA_NAMESPACE>
Spara värdena för nästa steg.
Ladda upp schema till Azure IoT Operations
I snabbstarten ser data som kommer från ugnstillgången ut så här:
{
"Temperature": {
"SourceTimestamp": "2024-11-15T21:40:28.5062427Z",
"Value": 6416
},
"FillWeight": {
"SourceTimestamp": "2024-11-15T21:40:28.5063811Z",
"Value": 6416
},
"EnergyUse": {
"SourceTimestamp": "2024-11-15T21:40:28.506383Z",
"Value": 6416
}
}
Det obligatoriska schemaformatet för Delta Lake är ett JSON-objekt som följer Delta Lake-schemats serialiseringsformat. Schemat bör definiera datastrukturen, inklusive typerna och egenskaperna för varje fält. Mer information om schemaformatet finns i dokumentationen om schemaserialiseringsformatet i Delta Lake.
Dricks
Om du vill generera schemat från en exempeldatafil använder du schemagenhjälpen.
I den här självstudien ser schemat för data ut så här:
{
"$schema": "Delta/1.0",
"type": "object",
"properties": {
"type": "struct",
"fields": [
{
"name": "Temperature",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
},
{
"name": "FillWeight",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
},
{
"name": "EnergyUse",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
}
]
}
}
Spara den som en fil med namnet opcua-schema.json.
Ladda sedan upp schemat till Azure IoT Operations med hjälp av Azure CLI. Ersätt platshållarna med värdena.
az iot ops schema create -n opcua-schema -g <RESOURCE_GROUP> --registry <REGISTRY_NAME> --format delta --type message --version-content opcua-schema.json --ver 1
Detta skapar ett schema med namnet opcua-schema i Azure IoT Operations-registret med version 1.
Kontrollera att schemat har laddats upp genom att lista schemaversionerna med hjälp av Azure CLI.
az iot ops schema version list -g <RESOURCE_GROUP> --schema opcua-schema --registry <REGISTRY_NAME>
Skapa dataflödesslutpunkt
Dataflödesslutpunkten är målet där data skickas. I det här fallet skickas data till Azure Data Lake Storage Gen 2. Autentiseringsmetoden är systemtilldelad hanterad identitet, som du har konfigurerat för att ha rätt behörighet att skriva till lagringskontot.
Skapa en dataflödesslutpunkt med Bicep. Ersätt platshållarna med värdena.
// Replace with your values
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
// Tutorial specific values
param endpointName string = 'adls-gen2-endpoint'
param host string = 'https://<ACCOUNT>.blob.core.windows.net'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
resource adlsGen2Endpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' = {
parent: aioInstance
name: endpointName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
endpointType: 'DataLakeStorage'
dataLakeStorageSettings: {
host: host
authentication: {
method: 'SystemAssignedManagedIdentity'
systemAssignedManagedIdentitySettings: {}
}
}
}
}
Spara filen som adls-gen2-endpoint.bicep och distribuera den med hjälp av Azure CLI
az deployment group create -g <RESOURCE_GROUP> --template-file adls-gen2-endpoint.bicep
Skapa ett dataflöde
Om du vill skicka data till Azure Data Lake Storage Gen 2 måste du skapa ett dataflöde som läser data från OPC UA-servern och skriver dem till lagringskontot. Ingen transformering krävs i det här fallet, så data skrivs som de är.
Skapa ett dataflöde med Bicep. Ersätt platshållarna med värdena.
// Replace with your values
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
param schemaNamespace string = '<SCHEMA_NAMESPACE>'
// Tutorial specific values
param schema string = 'opcua-schema'
param schemaVersion string = '1'
param dataflowName string = 'tutorial-adls-gen2'
param assetName string = 'oven'
param endpointName string = 'adls-gen2-endpoint'
param containerName string = 'aiotutorial'
param serialFormat string = 'Delta'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
// Pointer to the default dataflow profile
resource defaultDataflowProfile 'Microsoft.IoTOperations/instances/dataflowProfiles@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource adlsEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: endpointName
}
resource defaultDataflowEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource asset 'Microsoft.DeviceRegistry/assets@2024-11-01' existing = {
name: assetName
}
resource dataflow 'Microsoft.IoTOperations/instances/dataflowProfiles/dataflows@2024-11-01' = {
// Reference to the parent dataflow profile, the default profile in this case
// Same usage as profileRef in Kubernetes YAML
parent: defaultDataflowProfile
name: dataflowName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
mode: 'Enabled'
operations: [
{
operationType: 'Source'
sourceSettings: {
endpointRef: defaultDataflowEndpoint.name
assetRef: asset.name
dataSources: ['azure-iot-operations/data/${assetName}']
}
}
// Transformation optional
{
operationType: 'BuiltInTransformation'
builtInTransformationSettings: {
serializationFormat: serialFormat
schemaRef: 'aio-sr://${schemaNamespace}/${schema}:${schemaVersion}'
map: [
{
type: 'PassThrough'
inputs: [
'*'
]
output: '*'
}
]
}
}
{
operationType: 'Destination'
destinationSettings: {
endpointRef: adlsEndpoint.name
dataDestination: containerName
}
}
]
}
}
Spara filen som adls-gen2-dataflow.bicep och distribuera den med hjälp av Azure CLI
az deployment group create -g <RESOURCE_GROUP> --template-file adls-gen2-dataflow.bicep
Verifiera data i Azure Data Lake Storage Gen 2
I lagringskontot går du till bladet Containrar och väljer den container aiotutorial som du skapade. Du bör se en mapp med namnet aiotutorial och inuti den bör du se Parquet-filer med data från OPC UA-servern. Filnamnen är i formatet part-00001-44686130-347f-4c2c-81c8-eb891601ef98-c000.snappy.parquet.
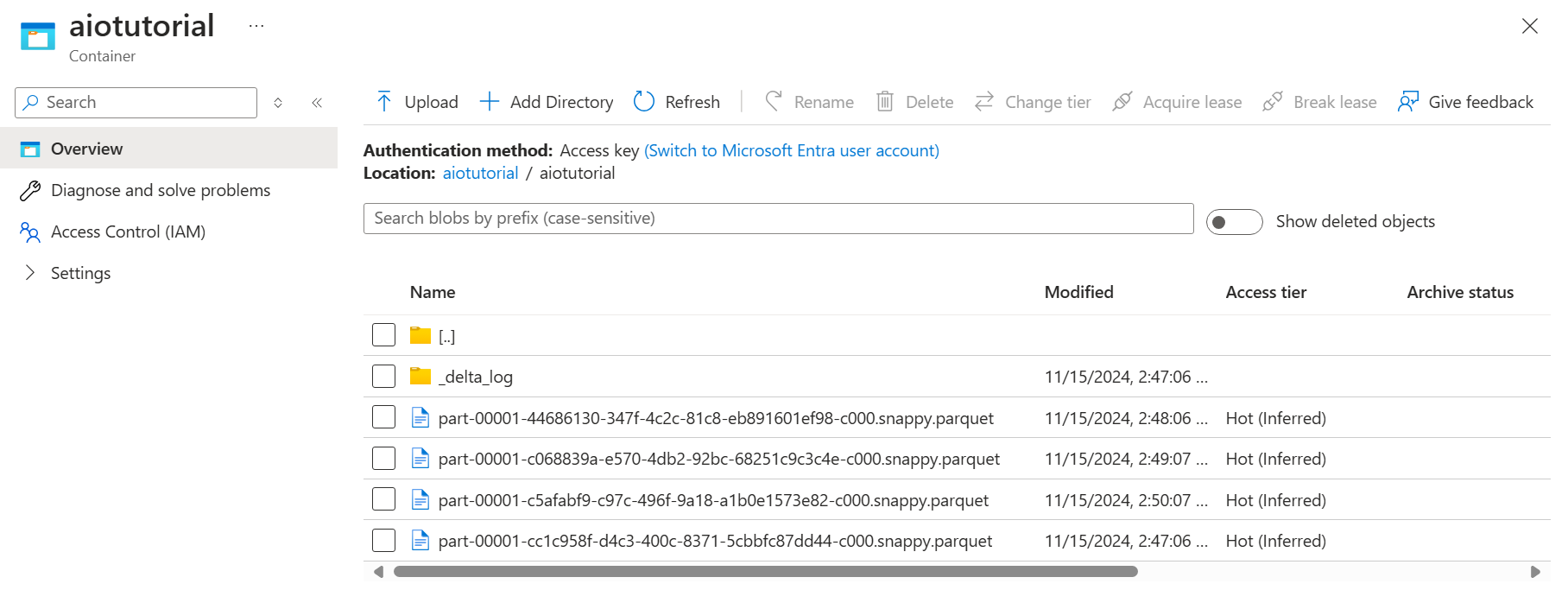
Om du vill se innehållet i filerna väljer du varje fil och väljer Redigera.
Innehållet återges inte korrekt i Azure Portal, men du kan ladda ned filen och öppna den i ett verktyg som Parquet Viewer.