Observerbarhetsmönster
Dricks
Det här innehållet är ett utdrag från eBook, Architecting Cloud Native .NET Applications for Azure, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Precis som mönster har utvecklats för att underlätta layouten av kod i program, finns det mönster för att använda program på ett tillförlitligt sätt. Tre användbara mönster för att underhålla program har dykt upp: loggning, övervakning och aviseringar.
När du ska använda loggning
Oavsett hur försiktiga vi är beter sig program nästan alltid på oväntade sätt i produktionen. När användare rapporterar problem med ett program är det användbart att kunna se vad som pågick med appen när problemet uppstod. Ett av de mest beprövade sätten att samla in information om vad ett program gör när det körs är att låta programmet skriva ned vad det gör. Den här processen kallas loggning. När fel eller problem uppstår i produktionen bör målet vara att återskapa de förhållanden under vilka felen inträffade i en icke-produktionsmiljö. Att ha bra loggning på plats ger en översikt som utvecklare kan följa för att duplicera problem i en miljö som kan testas och experimenteras med.
Utmaningar vid loggning med molnbaserade program
I traditionella program lagras loggfiler vanligtvis på den lokala datorn. I Unix-liknande operativsystem finns det faktiskt en mappstruktur som har definierats för att lagra alla loggar, vanligtvis under /var/log.
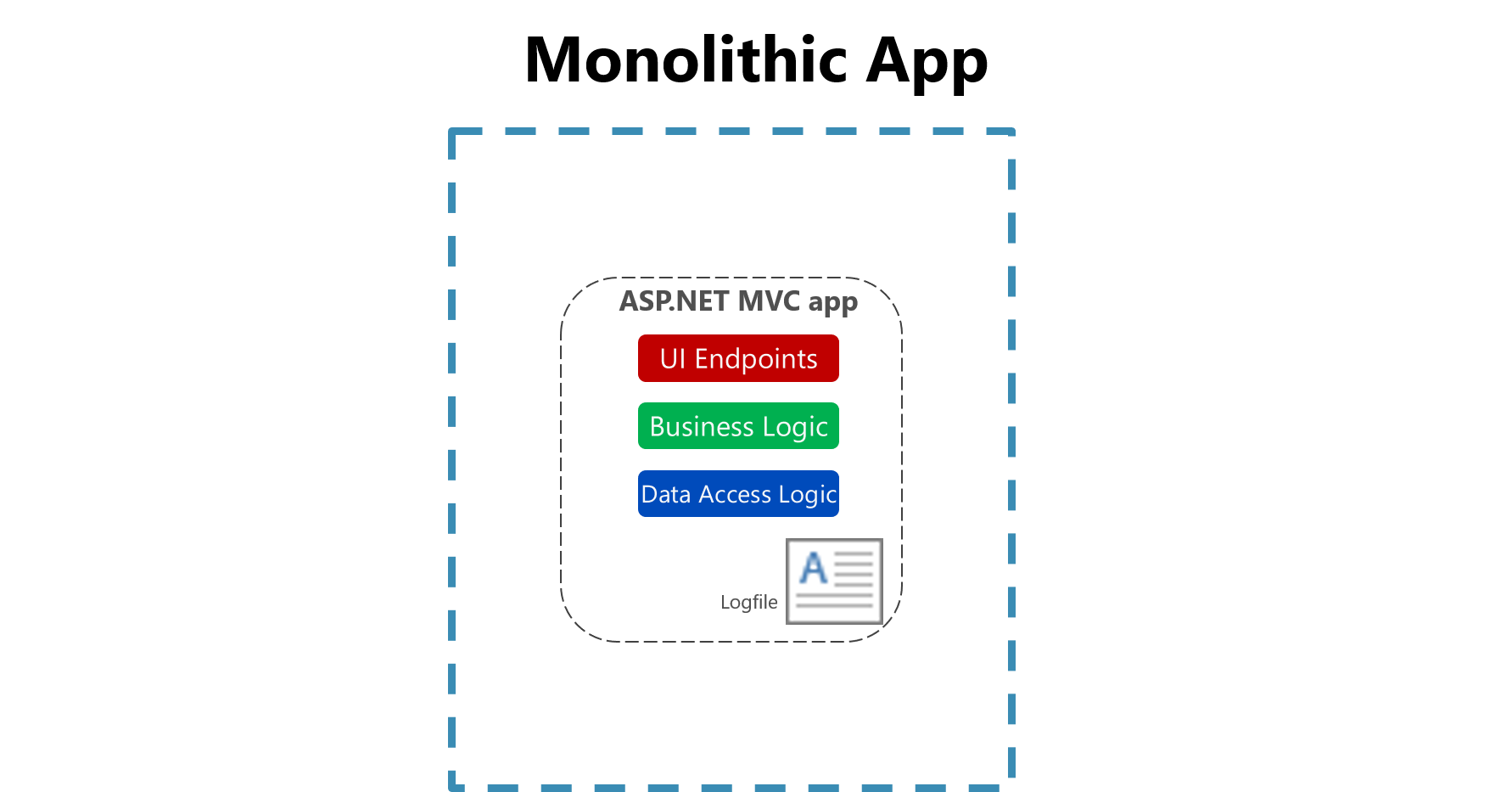 Bild 7-1. Logga till en fil i en monolitisk app.
Bild 7-1. Logga till en fil i en monolitisk app.
Nyttan av att logga till en flat fil på en enda dator minskar avsevärt i en molnmiljö. Program som producerar loggar kanske inte har åtkomst till den lokala disken eller så kan den lokala disken vara mycket övergående eftersom containrar blandas runt fysiska datorer. Även enkel skalning av monolitiska program över flera noder kan göra det svårt att hitta rätt filbaserad loggfil.
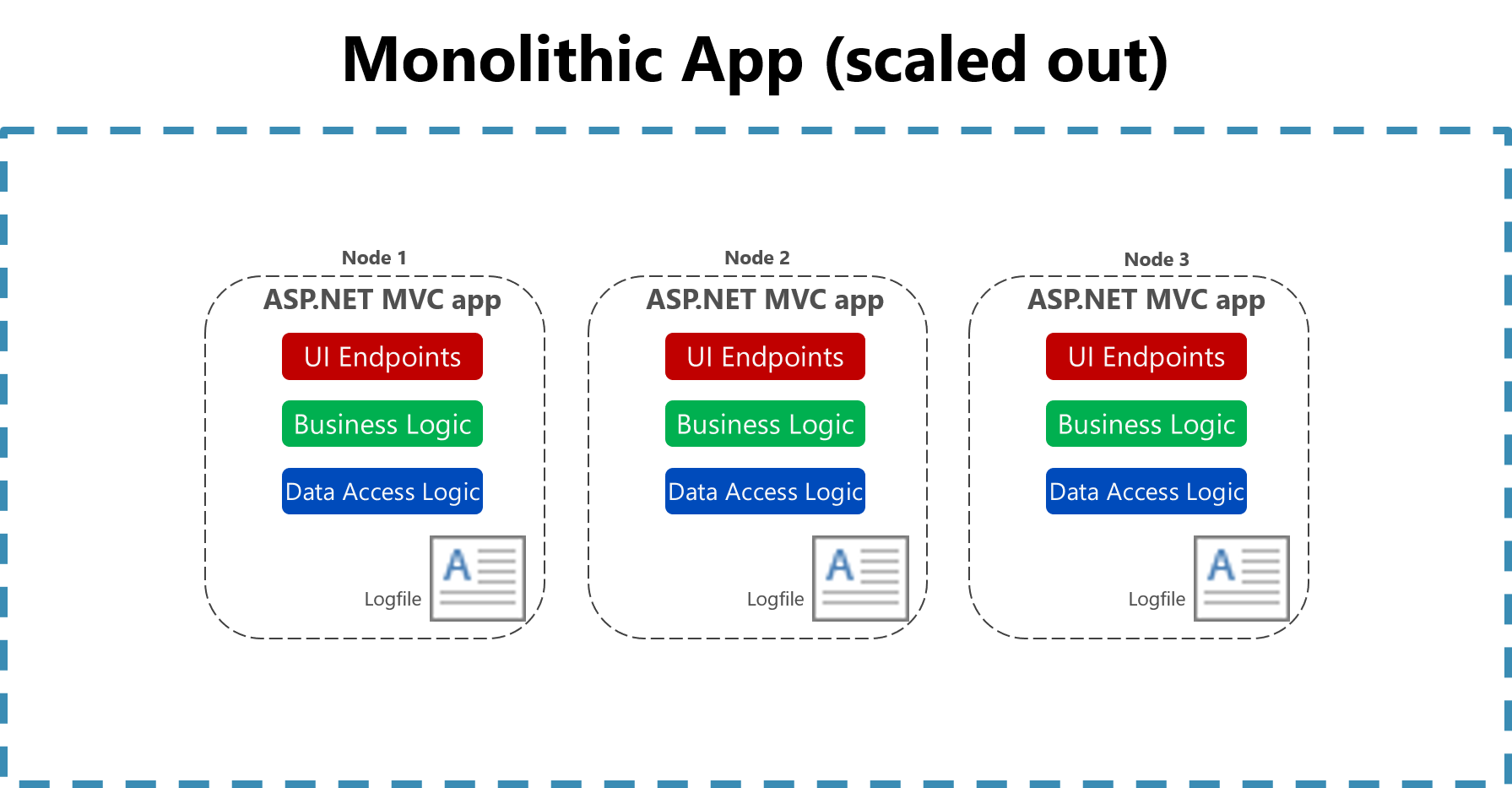 Bild 7-2. Logga till filer i en skalad monolitisk app.
Bild 7-2. Logga till filer i en skalad monolitisk app.
Molnbaserade program som utvecklats med hjälp av en mikrotjänstarkitektur innebär också vissa utmaningar för filbaserade loggare. Användarbegäranden kan nu omfatta flera tjänster som körs på olika datorer och kan innehålla serverlösa funktioner utan åtkomst till ett lokalt filsystem alls. Det skulle vara mycket svårt att korrelera loggarna från en användare eller en session över dessa många tjänster och datorer.
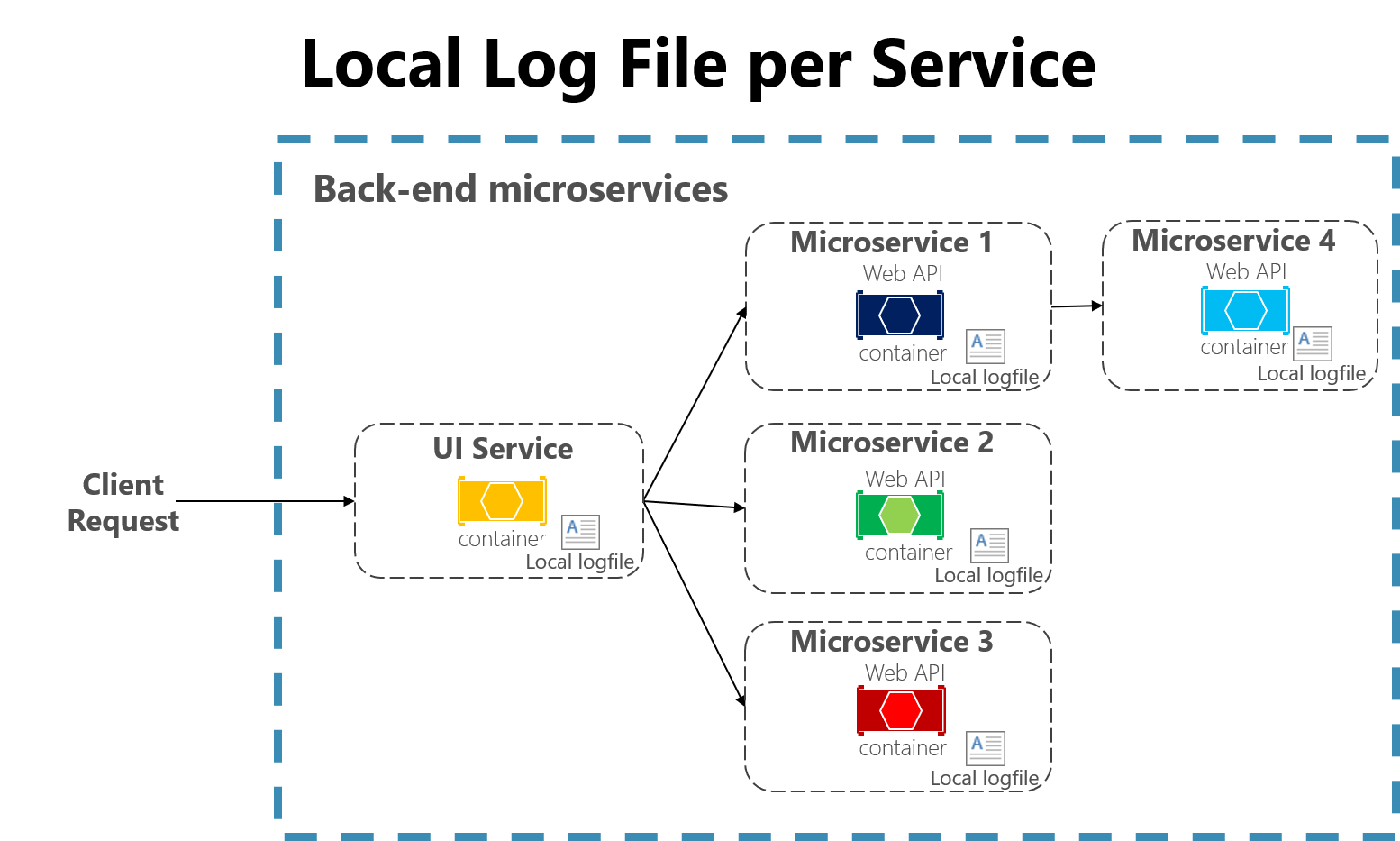 Bild 7-3. Logga till lokala filer i en mikrotjänstapp.
Bild 7-3. Logga till lokala filer i en mikrotjänstapp.
Slutligen är antalet användare i vissa molnbaserade program stort. Anta att varje användare genererar hundra rader med loggmeddelanden när de loggar in på ett program. Isolerat är det hanterbart, men multiplicera att över 100 000 användare och mängden loggar blir tillräckligt stora för att specialiserade verktyg behövs för att stödja effektiv användning av loggarna.
Loggning i molnbaserade program
Varje programmeringsspråk har verktyg som tillåter att loggar skrivs, och vanligtvis är kostnaderna för att skriva dessa loggar låga. Många av loggningsbiblioteken tillhandahåller loggning av olika typer av kritiskheter, som kan justeras vid körning. Serilog-biblioteket är till exempel ett populärt strukturerat loggningsbibliotek för .NET som tillhandahåller följande loggningsnivåer:
- Utförlig
- Felsöka
- Information
- Varning
- Fel
- Dödlig
Dessa olika loggnivåer ger kornighet i loggning. När programmet fungerar korrekt i produktion kan det konfigureras att endast logga viktiga meddelanden. När programmet beter sig felaktigt kan loggnivån ökas så att fler utförliga loggar samlas in. Detta balanserar prestanda mot enkel felsökning.
Den höga prestandan för loggningsverktyg och tunability of verbosity bör uppmuntra utvecklare att logga ofta. Många föredrar ett mönster för att logga in- och avslut för varje metod. Den här metoden kan låta som overkill, men det är ovanligt att utvecklare vill ha mindre loggning. I själva verket är det inte ovanligt att utföra distributioner enbart i syfte att lägga till loggning runt en problematisk metod. Fel på sidan av för mycket loggning och inte på för lite. Vissa verktyg kan användas för att automatiskt tillhandahålla den här typen av loggning.
På grund av utmaningarna med att använda filbaserade loggar i molnbaserade appar är centraliserade loggar att föredra. Loggar samlas in av programmen och skickas till ett centralt loggningsprogram som indexerar och lagrar loggarna. Den här systemklassen kan mata in tiotals gigabyte loggar varje dag.
Det är också bra att följa vissa standardmetoder när du skapar loggning som omfattar många tjänster. Om du till exempel genererar ett korrelations-ID i början av en lång interaktion och sedan loggar det i varje meddelande som är relaterat till den interaktionen blir det enklare att söka efter alla relaterade meddelanden. Man behöver bara hitta ett enda meddelande och extrahera korrelations-ID:t för att hitta alla relaterade meddelanden. Ett annat exempel är att se till att loggformatet är detsamma för varje tjänst, oavsett vilket språk eller loggningsbibliotek det använder. Den här standardiseringen gör läsningsloggarna mycket enklare. Bild 7–4 visar hur en mikrotjänstarkitektur kan utnyttja centraliserad loggning som en del av arbetsflödet.
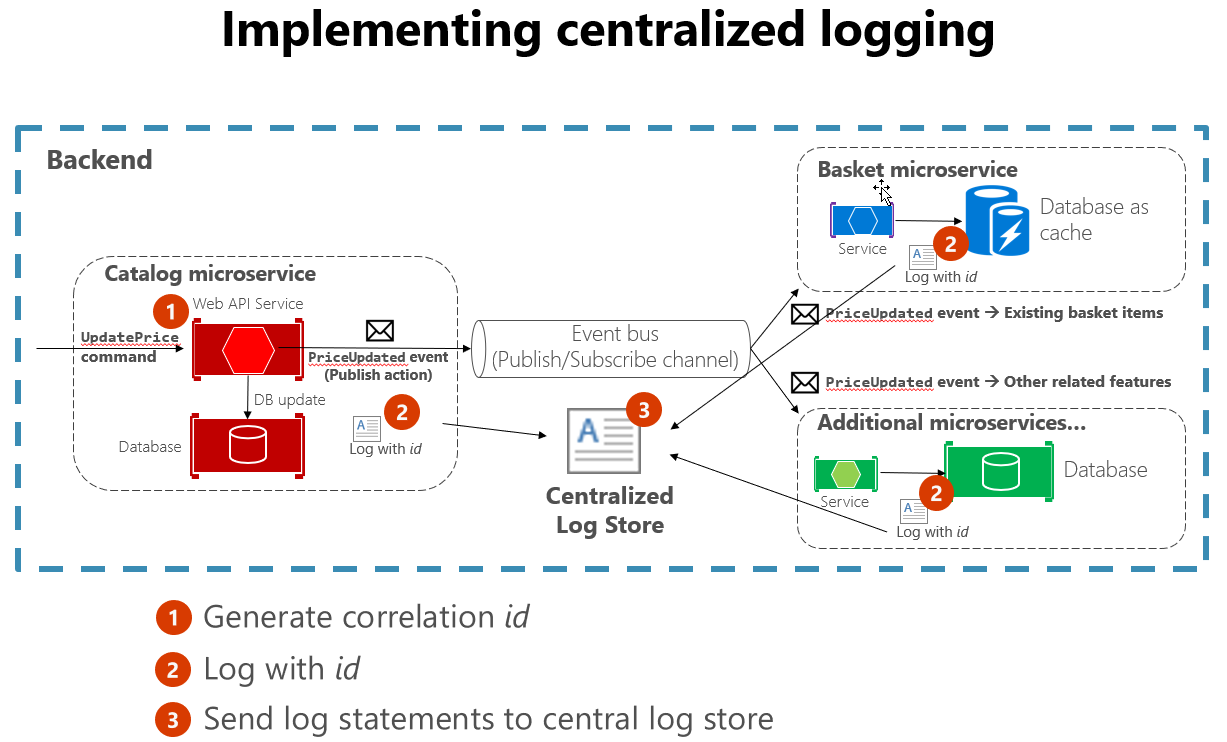 Bild 7-4. Loggar från olika källor matas in i ett centraliserat loggarkiv.
Bild 7-4. Loggar från olika källor matas in i ett centraliserat loggarkiv.
Utmaningar med att identifiera och svara på potentiella problem med appens hälsotillstånd
Vissa program är inte verksamhetskritiska. De kanske bara används internt, och när ett problem uppstår kan användaren kontakta det ansvariga teamet och programmet kan startas om. Kunder har dock ofta högre förväntningar på de program de använder. Du bör veta när problem uppstår med ditt program innan användarna gör det, eller innan användarna meddelar dig. Annars kan det första du känner till om ett problem vara när du märker en arg störtflod av inlägg på sociala medier som hånar ditt program eller till och med din organisation.
Några scenarier som du kan behöva överväga är:
- En tjänst i ditt program fortsätter att misslyckas och startas om, vilket resulterar i tillfälliga långsamma svar.
- Vid vissa tidpunkter på dagen är programmets svarstid långsam.
- Efter en distribution nyligen har belastningen på databasen tredubblats.
Övervakningen är korrekt implementerad och kan informera dig om villkor som leder till problem, så att du kan hantera underliggande villkor innan de resulterar i någon betydande användarpåverkan.
Övervaka molnbaserade appar
Vissa centraliserade loggningssystem får en extra roll när det gäller att samla in telemetri utanför rena loggar. De kan samla in mått, till exempel tid för att köra en databasfråga, genomsnittlig svarstid från en webbserver och till och med cpu-belastningsgenomsnitt och minnestryck enligt operativsystemets rapporter. Tillsammans med loggarna kan dessa system ge en holistisk vy över hälsotillståndet för noder i systemet och programmet som helhet.
Övervakningsverktygens funktioner för måttinsamling kan också matas manuellt inifrån programmet. Affärsflöden som är av särskilt intresse, till exempel nya användare som registrerar sig eller beställningar som görs, kan instrumenteras så att de ökar en räknare i det centrala övervakningssystemet. Den här aspekten låser upp övervakningsverktygen för att inte bara övervaka programmets hälsa utan även verksamhetens hälsa.
Frågor kan konstrueras i loggaggregeringsverktygen för att söka efter viss statistik eller mönster, som sedan kan visas i grafisk form, på anpassade instrumentpaneler. Ofta investerar team i stora, väggmonterade skärmar som roterar genom statistiken som är relaterad till ett program. På så sätt är det enkelt att se problemen när de uppstår.
Molnbaserade övervakningsverktyg ger realtidstelemetri och insikt i appar oavsett om de är monolitiska program med en enda process eller distribuerade mikrotjänstarkitekturer. De innehåller verktyg som tillåter insamling av data från appen samt verktyg för att fråga och visa information om appens hälsa.
Utmaningar med att reagera på kritiska problem i molnbaserade appar
Om du behöver reagera på problem med ditt program behöver du något sätt att varna rätt personal. Detta är det tredje molnbaserade programmets observerbarhetsmönster och beror på loggning och övervakning. Ditt program måste ha loggning på plats så att problem kan diagnostiseras och i vissa fall matas in i övervakningsverktyg. Den behöver övervakning för att aggregera programmått och hälsodata på ett och samma ställe. När detta har upprättats kan regler skapas som utlöser aviseringar när vissa mått hamnar utanför acceptabla nivåer.
I allmänhet läggs aviseringar ovanpå övervakningen så att vissa villkor utlöser lämpliga aviseringar för att meddela gruppmedlemmar om brådskande problem. Några scenarier som kan kräva aviseringar är:
- En av programmets tjänster svarar inte efter 1 minuts stilleståndstid.
- Programmet returnerar misslyckade HTTP-svar till mer än 1 % av begäranden.
- Programmets genomsnittliga svarstid för nyckelslutpunkter överskrider 2 000 ms.
Aviseringar i molnbaserade appar
Du kan skapa frågor mot övervakningsverktygen för att söka efter kända feltillstånd. Till exempel kan frågor söka igenom inkommande loggar efter indikationer på HTTP-statuskod 500, vilket indikerar ett problem på en webbserver. Så snart en av dessa identifieras kan ett e-postmeddelande eller ett SMS skickas till ägaren av den ursprungliga tjänsten som kan börja undersöka.
Normalt räcker det dock inte med ett enda 500-fel för att fastställa att ett problem har uppstått. Det kan innebära att en användare felaktigt skrev in sitt lösenord eller angav felaktiga data. Aviseringsfrågorna kan endast skapas för att utlösas när ett större än genomsnittligt antal 500 fel identifieras.
Ett av de mest skadliga mönstren i aviseringar är att avfyra för många aviseringar för människor att undersöka. Tjänstägare kommer snabbt att desensitiseras till fel som de tidigare har undersökt och visat sig vara godartade. När sanna fel inträffar går de sedan förlorade i bruset från hundratals falska positiva identifieringar. Liknelse av Boy Vem Cried Wolf uppmanas ofta till barn att varna dem för just denna fara. Det är viktigt att se till att aviseringarna som utlöses tyder på ett verkligt problem.