Snabbstart: Skapa och poängsätta en förutsägelsemodell i R med SQL-maskininlärning
gäller för:![]() SQL Server 2016 (13.x) och senare
SQL Server 2016 (13.x) och senare ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
I den här snabbstarten skapar och tränar du en förutsägelsemodell med hjälp av T. Du sparar modellen i en tabell i SQL Server-instansen och använder sedan modellen för att förutsäga värden från nya data med hjälp av SQL Server Machine Learning Services eller på Stordatakluster.
I den här snabbstarten skapar och tränar du en förutsägelsemodell med hjälp av T. Du sparar modellen i en tabell i SQL Server-instansen och använder sedan modellen för att förutsäga värden från nya data med hjälp av SQL Server Machine Learning Services-.
I den här snabbstarten skapar och tränar du en förutsägelsemodell med hjälp av T. Du sparar modellen i en tabell i SQL Server-instansen och använder sedan modellen för att förutsäga värden från nya data med hjälp av SQL Server R Services-.
I den här snabbstarten skapar och tränar du en förutsägelsemodell med hjälp av T. Du sparar modellen i en tabell i SQL Server-instansen och använder sedan modellen för att förutsäga värden från nya data med hjälp av Azure SQL Managed Instance Machine Learning Services.
Du skapar och kör två lagrade procedurer som körs i SQL. Den första använder mtcars datamängd som ingår i R och genererar en enkel generaliserad linjär modell (GLM) som förutsäger sannolikheten för att ett fordon har utrustats med en manuell överföring. Den andra proceduren är för bedömning – den anropar modellen som genererades i den första proceduren för att mata ut en uppsättning förutsägelser baserat på nya data. Genom att placera R-kod i en SQL-lagrad procedur finns åtgärder i SQL, kan återanvändas och kan anropas av andra lagrade procedurer och klientprogram.
Tips
Om du behöver en genomgång av linjära modeller kan du prova den här självstudien som beskriver processen med att anpassa en modell med rxLinMod: Anpassning av linjära modeller
Genom att slutföra den här snabbstarten får du lära dig:
- Bädda in R-kod i en lagrad procedur
- För att överföra indata till din kod via parametrar i den lagrade proceduren
- Hur lagrade procedurer används för att operationalisera modeller
Förutsättningar
Du behöver följande förutsättningar för att köra den här snabbstarten.
- SQL Server Machine Learning Services. Information om hur du installerar Machine Learning Services finns i installationsguiden för Windows eller installationsguiden för Linux. Du kan också aktivera maskininlärningstjänster på SQL Server Big Data Clusters.
- SQL Server Machine Learning Services. Information om hur du installerar Machine Learning Services finns i installationsguiden för Windows.
- SQL Server 2016 R Services. Information om hur du installerar R Services finns i installationsguiden för Windows.
- Azure SQL Managed Instance Machine Learning Services. Mer information finns i översikten över Azure SQL Managed Instance Machine Learning Services.
- Ett verktyg för att köra SQL-frågor som innehåller R-skript. Den här snabbstarten använder Azure Data Studio.
Skapa modellen
För att skapa modellen skapar du källdata för träning, skapar modellen och tränar den med hjälp av data och lagrar sedan modellen i en databas där den kan användas för att generera förutsägelser med nya data.
Skapa källdata
Öppna Azure Data Studio, anslut till din instans och öppna ett nytt frågefönster.
Skapa en tabell för att spara träningsdata.
CREATE TABLE dbo.MTCars( mpg decimal(10, 1) NOT NULL, cyl int NOT NULL, disp decimal(10, 1) NOT NULL, hp int NOT NULL, drat decimal(10, 2) NOT NULL, wt decimal(10, 3) NOT NULL, qsec decimal(10, 2) NOT NULL, vs int NOT NULL, am int NOT NULL, gear int NOT NULL, carb int NOT NULL );Infoga data från den inbyggda datauppsättningen
mtcars.INSERT INTO dbo.MTCars EXEC sp_execute_external_script @language = N'R' , @script = N'MTCars <- mtcars;' , @input_data_1 = N'' , @output_data_1_name = N'MTCars';Tips
Många datauppsättningar, både små och stora, ingår i R-miljön. Om du vill få en lista över datauppsättningar installerade med R skriver du
library(help="datasets")från en R-kommandotolk.
Skapa och träna modellen
Bilens hastighetsdata innehåller två kolumner, både numeriska: hästkrafter (hp) och vikt (wt). Utifrån dessa data skapar du en generaliserad linjär modell (GLM) som uppskattar sannolikheten för att ett fordon har utrustats med en manuell växellåda.
För att skapa modellen definierar du formeln i R-koden och skickar data som en indataparameter.
DROP PROCEDURE IF EXISTS generate_GLM;
GO
CREATE PROCEDURE generate_GLM
AS
BEGIN
EXEC sp_execute_external_script
@language = N'R'
, @script = N'carsModel <- glm(formula = am ~ hp + wt, data = MTCarsData, family = binomial);
trained_model <- data.frame(payload = as.raw(serialize(carsModel, connection=NULL)));'
, @input_data_1 = N'SELECT hp, wt, am FROM MTCars'
, @input_data_1_name = N'MTCarsData'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model VARBINARY(max)));
END;
GO
- Det första argumentet för att
glmär formeln parameter, som definieraramsom beroende avhp + wt. - Indata lagras i variabeln
MTCarsData, som fylls i av SQL-frågan. Om du inte tilldelar ett specifikt namn till dina indata är standardvariabelnamnet InputDataSet.
Lagra modellen i databasen
Lagra sedan modellen i en databas så att du kan använda den för förutsägelse eller träna om den.
Skapa en tabell för att lagra modellen.
Utdata från ett R-paket som skapar en modell är vanligtvis ett binärt objekt. Därför måste tabellen där du lagrar modellen ange en kolumn med varbinary(max) typ.
CREATE TABLE GLM_models ( model_name varchar(30) not null default('default model') primary key, model varbinary(max) not null );Kör följande Transact-SQL-instruktion för att anropa den lagrade proceduren, generera modellen och spara den i tabellen du skapade.
INSERT INTO GLM_models(model) EXEC generate_GLM;Tips
Om du kör den här koden en andra gång får du det här felet: "Överträdelse av BEGRÄNSNING AV PRIMÄRNYCKEL... Det går inte att infoga dubblettnyckeln i objektet dbo.stopping_distance_models". Ett alternativ för att undvika det här felet är att uppdatera namnet på varje ny modell. Du kan till exempel ändra namnet till något mer beskrivande och inkludera modelltypen, dagen då du skapade det och så vidare.
UPDATE GLM_models SET model_name = 'GLM_' + format(getdate(), 'yyyy.MM.HH.mm', 'en-gb') WHERE model_name = 'default model'
Poängsätta nya data med hjälp av den tränade modellen
Scoring är en term som används i datavetenskap för att generera förutsägelser, sannolikheter eller andra värden baserat på nya data som matas in i en tränad modell. Du använder den modell som du skapade i föregående avsnitt för att poängsätta förutsägelser mot nya data.
Skapa en tabell med nya data
Skapa först en tabell med nya data.
CREATE TABLE dbo.NewMTCars(
hp INT NOT NULL
, wt DECIMAL(10,3) NOT NULL
, am INT NULL
)
GO
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (110, 2.634)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (72, 3.435)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (220, 5.220)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (120, 2.800)
GO
Förutsäga manuell överföring
Om du vill få förutsägelser baserat på din modell skriver du ett SQL-skript som gör följande:
- Hämtar den modell du vill ha
- Hämtar nya indata
- Anropar en R-förutsägelsefunktion som är kompatibel med den modellen
Med tiden kan tabellen innehålla flera R-modeller, alla byggda med olika parametrar eller algoritmer, eller tränas på olika delmängder av data. I det här exemplet använder vi modellen med namnet default model.
DECLARE @glmmodel varbinary(max) =
(SELECT model FROM dbo.GLM_models WHERE model_name = 'default model');
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(glmmodel));
new <- data.frame(NewMTCars);
predicted.am <- predict(current_model, new, type = "response");
str(predicted.am);
OutputDataSet <- cbind(new, predicted.am);
'
, @input_data_1 = N'SELECT hp, wt FROM dbo.NewMTCars'
, @input_data_1_name = N'NewMTCars'
, @params = N'@glmmodel varbinary(max)'
, @glmmodel = @glmmodel
WITH RESULT SETS ((new_hp INT, new_wt DECIMAL(10,3), predicted_am DECIMAL(10,3)));
Skriptet ovan utför följande steg:
Använd en SELECT-instruktion för att hämta en enskild modell från tabellen och skicka den som en indataparameter.
När du har hämtat modellen från tabellen anropar du funktionen
unserializepå modellen.Använd funktionen
predictmed lämpliga argument för modellen och ange nya indata.
Anteckning
I exemplet läggs funktionen str till under testfasen för att kontrollera schemat för data som returneras från R. Du kan ta bort instruktionen senare.
Kolumnnamnen som används i R-skriptet skickas inte nödvändigtvis till utdata från den lagrade proceduren. Här används WITH RESULTS-satsen för att definiera några nya kolumnnamn.
Resultat
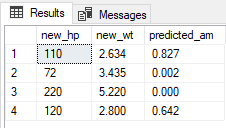
Du kan också använda instruktionen PREDICT (Transact-SQL) för att generera ett förutsagt värde eller poäng baserat på en lagrad modell.
Nästa steg
Mer information om självstudier för R med SQL-maskininlärning finns i: