Doğal dil işleme (NLP) yaklaşım analizi, konu algılama, dil algılama, anahtar ifade ayıklama ve belge kategorilere ayırma gibi birçok uygulamaya sahiptir.
Özellikle, NLP kullanarak şunları yapabilirsiniz:
- Örneğin, belgeleri hassas veya istenmeyen posta olarak etiketleyerek sınıflandırabilirsiniz.
- NLP çıkışlarıyla sonraki işlemleri veya aramaları gerçekleştirin.
- Belgedeki varlıkları tanımlayarak metni özetleyin.
- Tanımlanan varlıkları kullanarak belgeleri anahtar sözcüklerle etiketleyin.
- Etiketleme yoluyla içerik tabanlı arama ve alma işlemleri gerçekleştirin.
- Tanımlanan varlıkları kullanarak belgenin önemli konularını özetleyin.
- Algılanan konuları kullanarak belgeleri gezinti için kategorilere ayırın.
- Seçili konuya göre ilgili belgeleri numaralandır.
- Metin yaklaşımını değerlendirerek olumlu veya negatif tonunu anlayın.
Teknolojideki ilerlemelerle NLP yalnızca metin verilerini kategorilere ayırmak ve analiz etmek için değil, aynı zamanda farklı etki alanlarında yorumlanabilir yapay zeka işlevlerini geliştirmek için de kullanılabilir. Büyük Dil Modellerinin (LLM) tümleştirilmesi, NLP'nin özelliklerini önemli ölçüde artırır. GPT ve BERT gibi LLM'ler, karmaşık dil işleme görevleri için son derece etkili olmalarını sağlayarak insan benzeri, bağlamsal olarak duyarlı metinler oluşturabilir. Bunlar, özellikle Databricks'in Dolly 2.0gibi modellerle konuşma sistemlerini ve müşteri etkileşimlerini geliştiren daha geniş bilişsel görevleri işleyerek mevcut NLP tekniklerini tamamlar.
Dil modelleri ile NLP arasındaki ilişki ve farklar
NLP, insan dilini işlemeye yönelik çeşitli teknikleri kapsayan kapsamlı bir alandır. Buna karşılık, dil modelleri NLP içinde belirli bir alt kümedir ve üst düzey dil görevlerini gerçekleştirmek için derin öğrenmeye odaklanır. Dil modelleri gelişmiş metin oluşturma ve anlama özellikleri sağlayarak NLP'yi geliştirirken, NLP ile eş anlamlı değildir. Bunun yerine, daha geniş NLP etki alanında güçlü araçlar olarak görev yaparak daha gelişmiş dil işleme olanağı sağlar.
Not
Bu makale NLP'ye odaklanır. NLP ve dil modelleri arasındaki ilişki, dil modellerinin üstün dil anlama ve oluşturma özellikleriyle NLP işlemlerini geliştirdiğini gösterir.
Apache®, Apache Spark ve alev logosu, Apache Software Foundation'ın Birleşik Devletler ve/veya diğer ülkelerdeki kayıtlı ticari markaları veya ticari markalarıdır. Bu işaretlerin kullanılması Apache Software Foundation tarafından onaylanmamaktadır.
Olası kullanım örnekleri
Özel NLP'den yararlanabilecek iş senaryoları şunlardır:
- Finans, sağlık, perakende, kamu ve diğer sektörlerde el yazısı veya makine tarafından oluşturulan belgeler için Belge Zekası.
- Ad varlığı tanıma (NER), sınıflandırma, özetleme ve ilişki ayıklama gibi metin işleme için endüstriden bağımsız NLP görevleri. Bu görevler metin ve yapılandırılmamış veriler gibi belge bilgilerini alma, tanımlama ve analiz etme sürecini otomatikleştirir. Bu görevlere örnek olarak risk katmanlama modelleri, ontoloji sınıflandırması ve perakende özetlemeleri verilebilir.
- Anlamsal arama için bilgi alma ve bilgi grafı oluşturma. Bu işlevsellik, ilaç bulmayı ve klinik denemeleri destekleyen tıbbi bilgi grafları oluşturmayı mümkün kılar.
- Perakende, finans, seyahat ve diğer sektörlerde müşteriye yönelik uygulamalarda konuşma yapay zekası sistemleri için metin çevirisi.
- Özellikle marka algısını ve müşteri geri bildirim analizini izlemek için analizde yaklaşım ve gelişmiş duygusal zeka.
- Otomatik rapor oluşturma. Ayrıntılı belgelerin gerekli olduğu durumlarda finans ve uyumluluk gibi sektörlere yardımcı olan yapılandırılmış veri girişlerinden kapsamlı metinsel raporlar sentezleyin ve oluşturun.
- Ses tanıma ve doğal konuşma özellikleri için NLP'yi tümleştirerek IoT ve akıllı cihaz uygulamalarında kullanıcı etkileşimlerini geliştirmek için sesle etkinleştirilen arabirimler.
- Dil çıkışını çeşitli hedef kitle kavrama düzeylerine uyacak şekilde dinamik olarak ayarlamak için uyarlayıcı dil modelleri, eğitim içeriği ve erişilebilirlik geliştirmeleri için çok önemlidir.
- Dijital iletişimdeki olası güvenlik tehditlerini belirlemek için iletişim düzenlerini ve dil kullanımını gerçek zamanlı olarak analiz etmek için siber güvenlik metin analizi, kimlik avı girişimlerinin veya yanlış bilgilerin tespitini geliştirir.
Özelleştirilmiş NLP çerçevesi olarak Apache Spark
Apache Spark, bellek içi işleme aracılığıyla büyük veri analizi uygulamalarının performansını geliştiren güçlü bir paralel işleme çerçevesidir. Azure Synapse Analytics,
Özelleştirilmiş NLP iş yükleri için Spark NLP, geniş hacimli metinleri işleyebilen verimli bir çerçeve olmaya devam eder. Bu açık kaynak kitaplık, spaCy ve NLTK gibi önemli NLP kitaplıklarında bulunan gelişmişliği sunan Python, Java ve Scala kitaplıkları aracılığıyla kapsamlı işlevler sağlar. Spark NLP, yazım denetimi, yaklaşım analizi ve belge sınıflandırması gibi gelişmiş özellikleri içerir ve tutarlı olarak en son teknoloji doğruluğu ve ölçeklenebilirliği sağlar.
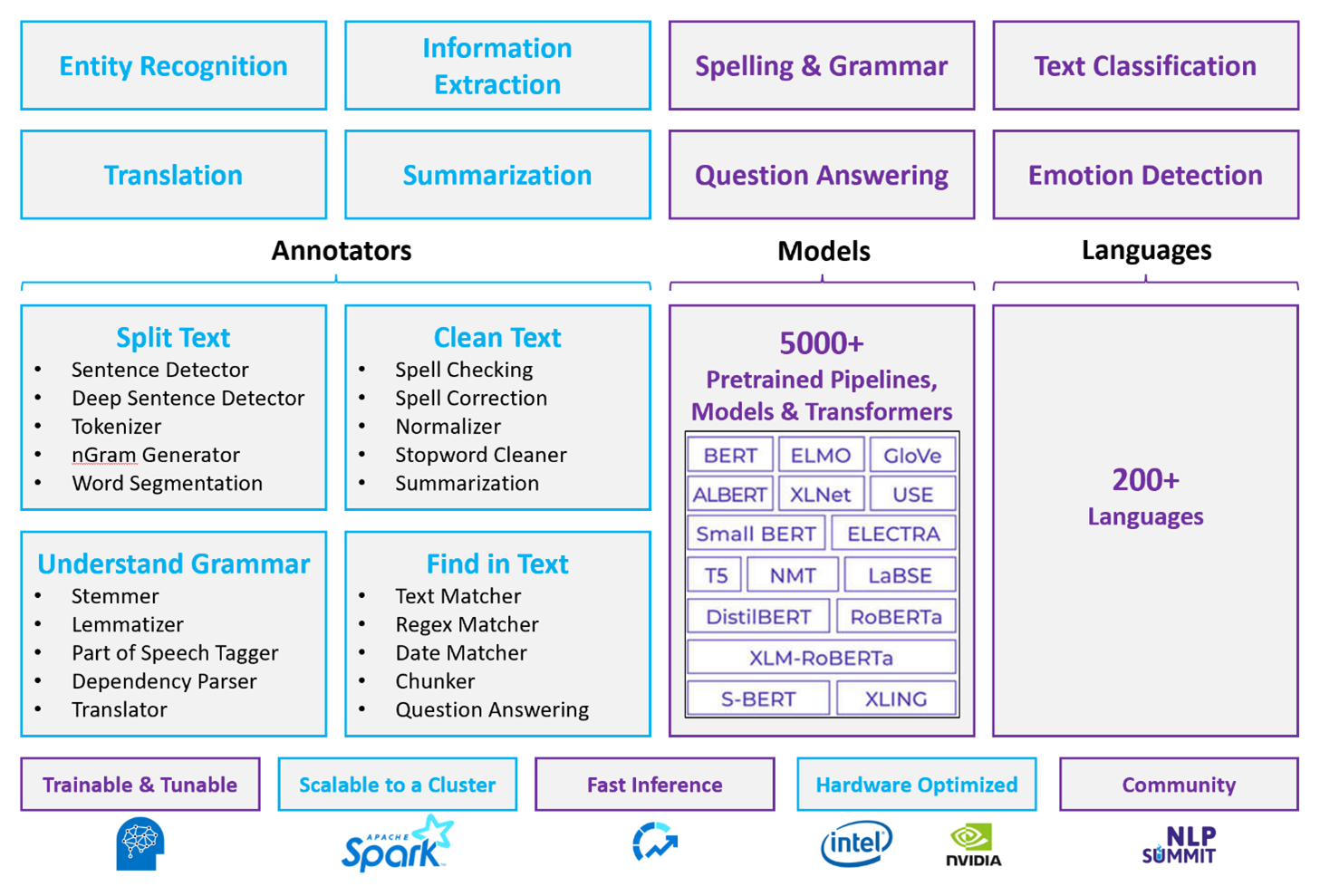
Son genel karşılaştırmalar Spark NLP'nin performansını vurgular ve özel modelleri eğitirken karşılaştırılabilir doğruluğu korurken diğer kitaplıklara göre önemli hız iyileştirmeleri gösterir. Özellikle, Llama-2 modellerinin ve OpenAI Fısıltısının tümleştirilmesi konuşma arabirimlerini ve çok dilli konuşma tanımayı geliştirerek iyileştirilmiş işleme özelliklerinde önemli ilerlemeleri işaret eder.
Spark NLP, spark ml'nin doğrudan veri çerçeveleri üzerinde çalışan yerel bir uzantısı olarak çalışan dağıtılmış bir Spark kümesini etkili bir şekilde kullanır. Bu tümleştirme, belge sınıflandırması ve risk tahmini gibi görevler için birleşik NLP ve makine öğrenmesi işlem hatlarının oluşturulmasını kolaylaştırarak kümelerde gelişmiş performans kazanımlarını destekler. MPNet eklemelerinin ve kapsamlı ONNX desteğinin kullanıma sunulması, bu özellikleri daha da zenginleştirerek hassas ve bağlama duyarlı işleme olanağı sağlar.
Spark NLP, performans avantajlarının ötesinde, genişleyen NLP görev dizisinde son derece yüksek doğruluk sunar. Kitaplık, adlandırılmış varlık tanıma, belge sınıflandırması, yaklaşım algılama ve daha fazlası için önceden oluşturulmuş derin öğrenme modelleriyle birlikte gelir. Zengin özelliklere sahip tasarımı, sözcük, öbek, cümle ve belge eklemelerini destekleyen önceden eğitilmiş dil modellerini içerir.
CPU'lar, GPU'lar ve en son Intel Xeon yongaları için iyileştirilmiş derlemelerle Spark NLP'nin altyapısı ölçeklenebilirlik için tasarlanmıştır ve Spark kümelerini tam olarak kullanmak için eğitim ve çıkarım işlemlerini etkinleştirir. Bu, NLP görevlerinin farklı ortamlar ve uygulamalar arasında verimli bir şekilde işlenmesini sağlar ve NLP yeniliklerinin ön saflarında yer alan konumunu korur.
Zorluklar
kaynakları işleme: Serbest biçimli metin belgelerinden oluşan bir koleksiyonun işlenmesi için önemli miktarda hesaplama kaynağı gerekir ve işleme de yoğun zaman alır. Bu tür işlemler genellikle GPU işlem dağıtımını içerir. Llama-2 gibi nicelemesi destekleyen Spark NLP mimarilerindeki iyileştirmeler gibi son gelişmeler bu yoğun görevleri kolaylaştırmaya yardımcı olur ve kaynak ayırmayı daha verimli hale getirir.
Standardization sorunları: Standartlaştırılmış belge biçimi olmadan, bir belgeden belirli olguları ayıklamak için serbest biçimli metin işleme kullandığınızda tutarlı olarak doğru sonuçlar elde etmek zor olabilir. Örneğin, çeşitli faturalardan fatura numarasını ve tarihi ayıklamak zorluklar doğurabilir. M2M100 gibi uyarlanabilir NLP modellerinin birden çok dil ve biçim arasında geliştirilmiş işleme doğruluğu ile tümleştirilmesi, sonuçlarda daha fazla tutarlılığı kolaylaştırır.
Veri çeşitliliği ve karmaşıklığı: Çeşitli belge yapılarını ve dilsel nüansları ele almak karmaşık kalır. MPNet eklemeleri gibi yenilikler, çeşitli metin biçimlerinin daha sezgisel bir şekilde işlenmesini ve genel veri işleme güvenilirliğinin artırılmasını sağlayan gelişmiş bağlamsal anlayış sağlar.
Anahtar seçim ölçütleri
Azure'da Azure Databricks, Microsoft Fabric ve Azure HDInsight gibi Spark hizmetleri Spark NLP ile kullanıldığında NLP işlevselliği sağlar. Azure AI hizmetleri, NLP işlevselliği için bir diğer seçenek dedir. Hangi hizmetin kullanılacağına karar vermek için şu soruları göz önünde bulundurun:
Önceden oluşturulmuş veya önceden eğitilmiş modeller kullanmak istiyor musunuz? Evet ise, Azure AI hizmetlerinin sunduğu API'leri kullanmayı göz önünde bulundurun veya spark NLP aracılığıyla tercih edilen modelinizi indirebilirsiniz. Bu, gelişmiş özellikler için Llama-2 ve MPNet gibi gelişmiş modelleri içerir.
Özel modelleri büyük bir metin verisi kümesine karşı eğitmek zorunda mısınız? Evet ise Spark NLP ile Azure Databricks, Microsoft Fabric veya Azure HDInsight kullanmayı göz önünde bulundurun. Bu platformlar, kapsamlı model eğitimi için gereken hesaplama gücünü ve esnekliği sağlar.
Belirteç oluşturma, kök oluşturma, lemmatizasyon ve terim sıklığı/ters belge sıklığı (TF/IDF) gibi düşük düzey NLP özelliklerine mi ihtiyacınız var? Evet ise Spark NLP ile Azure Databricks, Microsoft Fabric veya Azure HDInsight kullanmayı göz önünde bulundurun. Alternatif olarak, seçtiğiniz işleme aracında bir açık kaynak yazılım kitaplığı kullanın.
Varlık ve amaç belirleme, konu algılama, yazım denetimi veya yaklaşım analizi gibi basit, üst düzey NLP özelliklerine mi ihtiyacınız var? Evet ise, Azure AI hizmetlerinin sunduğu API'leri kullanmayı göz önünde bulundurun. Alternatif olarak, bu görevler için önceden oluşturulmuş işlevlerden yararlanmak için Spark NLP aracılığıyla istediğiniz modeli indirin.
Yetenek matrisi
Aşağıdaki tablolarda NLP hizmetlerinin özelliklerindeki temel farklar özetlenmektedir.
Genel özellikler
| Özellik | Spark NLP ile Spark hizmeti (Azure Databricks, Microsoft Fabric, Azure HDInsight) | Azure Yapay Zeka Hizmetleri |
|---|---|---|
| Hizmet olarak önceden eğitilmiş modeller sağlar | Yes | Yes |
| REST API | Yes | Yes |
| Programlanabilirlik | Python, Scala | Desteklenen diller için bkz. Ek Kaynaklar |
| Büyük veri kümelerinin ve büyük belgelerin işlenmesini destekler | Yes | Hayır |
Alt düzey NLP özellikleri
Annotator'ların Özelliği
| Özellik | Spark NLP ile Spark hizmeti (Azure Databricks, Microsoft Fabric, Azure HDInsight) | Azure Yapay Zeka Hizmetleri |
|---|---|---|
| Cümle algılayıcısı | Yes | Hayır |
| Derin cümle algılayıcısı | Yes | Yes |
| Belirteç Oluşturucu | Yes | Yes |
| N-gram oluşturucu | Yes | Hayır |
| Sözcük segmentasyonu | Yes | Yes |
| Stemmer | Yes | Hayır |
| Lemmatizer | Yes | Hayır |
| Konuşma bölümü etiketleme | Yes | Hayır |
| Bağımlılık ayrıştırıcısı | Yes | Hayır |
| Çeviri | Yes | Hayır |
| Stopword temizleyici | Yes | Hayır |
| Yazım düzeltmesi | Yes | Hayır |
| Normalizer | Yes | Yes |
| Metin eşleştirici | Yes | Hayır |
| TF/IDF | Yes | Hayır |
| Normal ifade eşleştiricisi | Yes | Konuşma Dili Anlama 'ya (CLU) eklenmiş |
| Tarih eşleştirici | Yes | DateTime tanıyıcıları aracılığıyla CLU'da mümkün |
| Öbekleyici | Yes | Hayır |
Not
Microsoft Language Understanding (LUIS), 1 Ekim 2025'te kullanımdan kaldırılacaktır. Mevcut LUIS uygulamalarının, Dil için Azure AI Services'ın dil anlama özelliklerini geliştiren ve yeni özellikler sunan Konuşma Dili Anlama (CLU) özelliğine geçirilmesi teşvik edilir.
Üst düzey NLP özellikleri
| Özellik | Spark NLP ile Spark hizmeti (Azure Databricks, Microsoft Fabric, Azure HDInsight) | Azure Yapay Zeka Hizmetleri |
|---|---|---|
| Yazım denetimi | Yes | Hayır |
| Özetleme | Yes | Yes |
| Soru cevaplama | Yes | Yes |
| Yaklaşım algılama | Yes | Yes |
| Duygu algılama | Yes | Fikir madenciliği destekler |
| Belirteç sınıflandırması | Yes | Evet, özel modeller aracılığıyla |
| Metin sınıflandırması | Yes | Evet, özel modeller aracılığıyla |
| Metin gösterimi | Yes | Hayır |
| NER | Yes | Evet, metin analizi bir dizi NER sağlar ve özel modeller varlık tanımadadır |
| Varlık tanıma | Yes | Evet, özel modeller aracılığıyla |
| Dil algılama | Yes | Yes |
| İngilizcenin yanı sıra dilleri destekler | Evet, 200'den fazla dili destekler | Evet, 97'den fazla dili destekler |
Azure'da Spark NLP'lerini ayarlama
Spark NLP'yi yüklemek için aşağıdaki kodu kullanın, ancak değerini en son sürüm numarasıyla değiştirin <version> . Daha fazla bilgi için Spark NLP belgelerine bakın.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
NLP işlem hatları geliştirme
Bir NLP işlem hattının yürütme sırası için Spark NLP, özel NLP teknikleri uygulayarak geleneksel Spark ML makine öğrenmesi modelleriyle aynı geliştirme kavramını izler.
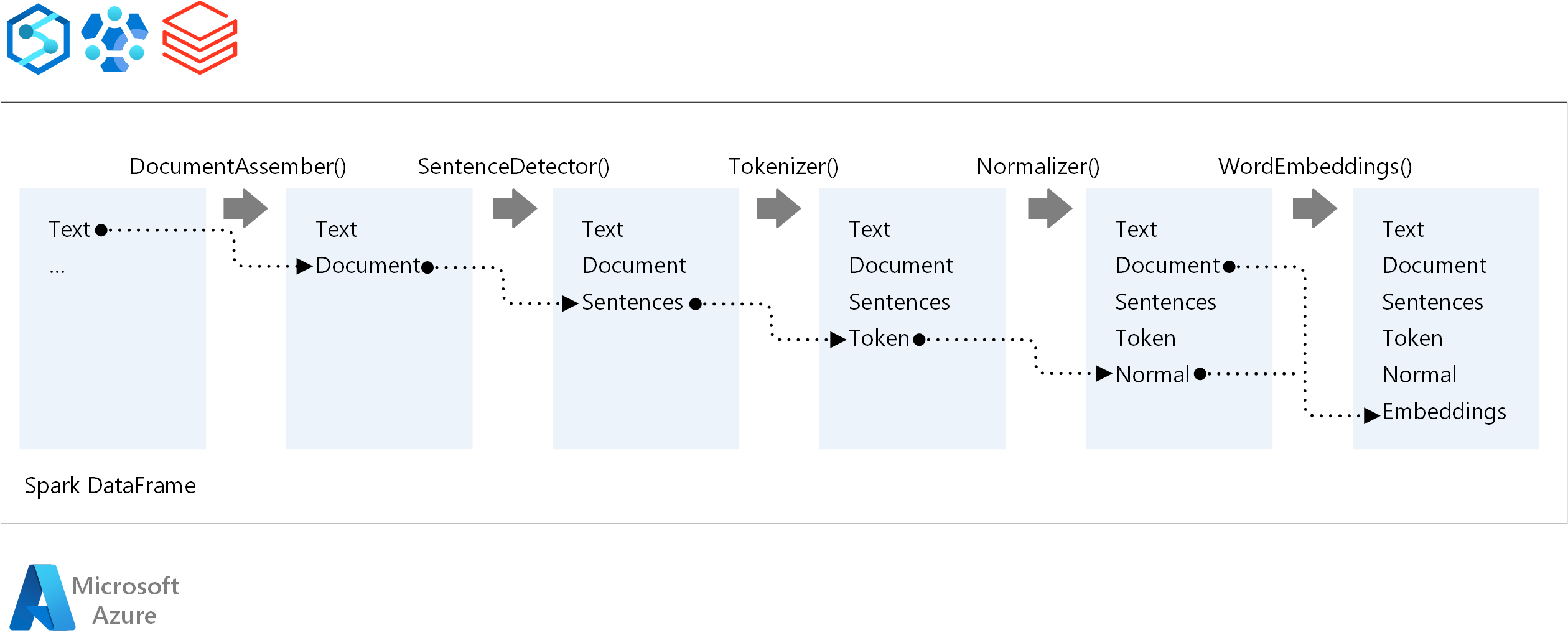
Spark NLP işlem hattının temel bileşenleri şunlardır:
DocumentAssembler: Verileri Spark NLP'nin işleyebileceği bir biçime dönüştürerek hazırlayan bir dönüştürücü. Bu aşama, her Spark NLP işlem hattının giriş noktasıdır. DocumentAssembler, varsayılan olarak kapalı olan
Stringkullanarak metni ön işleme seçenekleriyle birlikte birArray[String]sütununu veyasetCleanupModeokur.SentenceDetector: Önceden tanımlanmış yaklaşımları kullanarak cümle sınırlarını tanımlayan bir açıklama. Algılanan her tümceyi bir
Arrayiçinde veyaexplodeSentencestrue olarak ayarlandığında ayrı satırlarda döndürebilir.Belirteci: Ham metni
TokenizedSentenceolarak veren ayrık belirteçlere (sözcükler, sayılar ve simgeler) bölen bir açıklama ekleyici. Belirteç Oluşturucu uygun değildir ve belirteç oluşturma kuralları oluşturmak içinRuleFactoryiçindeki giriş yapılandırmasını kullanır. Varsayılanlar yetersiz olduğunda özel kurallar eklenebilir.Normalleştirici: Belirteçleri iyileştirme görevine sahip bir açıklama. Normalleştirici, metni temizlemek ve gereksiz karakterleri kaldırmak için normal ifadeler ve sözlük dönüştürmeleri uygular.
WordEmbeddings: Belirteçleri vektörlerle eşleyen açıklama ek açıklamalarını arama ve anlamsal işlemeyi kolaylaştırma. her satırın boşluklarla ayrılmış bir belirteç ve vektör içerdiği
setStoragePathkullanarak özel bir ekleme sözlüğü belirtebilirsiniz. Çözümlenmemiş belirteçler varsayılan olarak sıfır vektör olarak ayarlanır.
Spark NLP, makine öğrenmesi yaşam döngüsünü yöneten açık kaynak bir platform olan MLflowyerel desteğiyle Spark MLlib işlem hatlarından yararlanır. MLflow'un temel bileşenleri şunlardır:
MLflow İzleme: Deneysel çalıştırmaları kaydeder ve sonuçları analiz etmek için güçlü sorgulama özellikleri sağlar.
MLflow Projeleri: Veri bilimi kodunun farklı platformlarda yürütülmesini sağlayarak taşınabilirliği ve yeniden üretilebilirliği geliştirir.
MLflow Modelleri: Tutarlı bir çerçeve aracılığıyla farklı ortamlarda çok yönlü model dağıtımlarını destekler.
Model Kayıt Defteri: Kapsamlı model yönetimi sağlar, kolaylaştırılmış erişim ve dağıtım için sürümleri merkezi olarak depolar ve üretime hazır olma durumunu kolaylaştırır.
MLflow, Azure Databricks gibi platformlarla tümleşiktir ancak denemelerinizi yönetmek ve izlemek için diğer Spark tabanlı ortamlara da yüklenebilir. Bu tümleştirme, modelleri üretim amacıyla kullanılabilir hale getirmek için MLflow Model Kayıt Defteri'nin kullanılmasına olanak tanır, böylece dağıtım işleminin akışını sağlama ve model idaresini koruma.
Spark NLP'nin yanı sıra MLflow kullanarak, NLP işlem hatlarının verimli bir şekilde yönetilmesini ve dağıtılmasını sağlayabilir, ölçeklenebilirlik ve tümleştirme için modern gereksinimleri karşılayabilir ve sözcük eklemeleri ve büyük dil modeli uyarlamaları gibi gelişmiş teknikleri destekleyebilirsiniz.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazarlar:
- Freddy Ayala | Bulut Çözümü Mimarı
- Moritz Steller | Üst Düzey Bulut Çözümü Mimarı
Sonraki adımlar
Spark NLP belgeleri:
Azure bileşenleri:
- Microsoft Fabric
- Azure HDInsight
- Azure Databricks
- Bilişsel Hizmetler
- Microsoft Fabric
Kaynakları öğrenin: