Apache Kafka'dan Azure Veri Gezgini'a veri alma
Apache Kafka , sistemler veya uygulamalar arasında güvenilir bir şekilde veri taşınan gerçek zamanlı akış veri işlem hatları oluşturmaya yönelik bir dağıtılmış akış platformudur. Kafka Connect , Apache Kafka ve diğer veri sistemleri arasında ölçeklenebilir ve güvenilir veri akışı sağlayan bir araçtır. Kusto Kafka Havuzu, Kafka'dan bağlayıcı görevi görür ve kod kullanılmasını gerektirmez. Git deposundan veya Confluent Connector Hub'dan havuz bağlayıcısı jar dosyasını indirin.
Bu makalede, Kafka kümesi ve Kafka bağlayıcı kümesi kurulumunu basitleştirmek için bağımsız docker kurulumu kullanılarak Kafka ile veri alımı gösterilmektedir.
Daha fazla bilgi için bkz. Bağlayıcı Git deposu ve sürüm ayrıntıları.
Önkoşullar
- Azure aboneliği. Ücretsiz bir Azure hesabı oluşturun.
- Varsayılan önbellek ve bekletme ilkelerine sahip bir Azure Veri Gezgini kümesi ve veritabanı.
- Azure CLI.
- Docker ve Docker Compose.
Microsoft Entra hizmet sorumlusu oluşturma
Microsoft Entra hizmet sorumlusu, aşağıdaki örnekte olduğu gibi Azure portalı aracılığıyla veya program aracılığıyla oluşturulabilir.
Bu hizmet sorumlusu, kusto'da tablonuza veri yazmak için bağlayıcı tarafından kullanılan kimliktir. Bu hizmet sorumlusuna Kusto kaynaklarına erişmek için izinler verirsiniz.
Azure CLI aracılığıyla Azure aboneliğinizde oturum açın. Ardından tarayıcıda kimlik doğrulaması yapın.
az loginSorumluyu barındırmak için aboneliği seçin. Bu adım, birden çok aboneliğiniz olduğunda gereklidir.
az account set --subscription YOUR_SUBSCRIPTION_GUIDHizmet sorumlusunu oluşturun. Bu örnekte hizmet sorumlusu olarak adlandırılır
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Döndürülen JSON verilerinden, gelecekte kullanmak üzere ,
passwordvetenantdeğerini kopyalayınappId.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Microsoft Entra uygulamanızı ve hizmet sorumlunuzu oluşturdunuz.
Hedef tablo oluşturma
Sorgu ortamınızdan aşağıdaki komutu kullanarak adlı
Stormsbir tablo oluşturun:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Aşağıdaki komutu kullanarak alınan veriler için karşılık gelen tablo eşlemesini
Storms_CSV_Mappingoluşturun:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Yapılandırılabilir kuyruğa alınmış alım gecikme süresi için tabloda bir alma toplu işlemi ilkesi oluşturun.
İpucu
Alma toplu işlemi ilkesi bir performans iyileştiricidir ve üç parametre içerir. İlk koşul karşılandı, tabloya alımı tetikler.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Veritabanıyla çalışma izni vermek için Microsoft Entra hizmet sorumlusu oluşturma bölümünden hizmet sorumlusunu kullanın.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Laboratuvarı çalıştırma
Aşağıdaki laboratuvar, veri oluşturmaya başlama, Kafka bağlayıcısını ayarlama ve bu verileri akışla aktarma deneyimi sunmak için tasarlanmıştır. Daha sonra alınan verilere bakabilirsiniz.
Git deposunu kopyalama
Laboratuvarın git deposunu kopyalayın.
Makinenizde yerel bir dizin oluşturun.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holDepoyu kopyalayın.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Kopyalanan deponun içeriği
Kopyalanan deponun içeriğini listelemek için aşağıdaki komutu çalıştırın:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Bu aramanın sonucu şudur:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Kopyalanan depodaki dosyaları gözden geçirme
Aşağıdaki bölümlerde dosya ağacındaki dosyaların önemli bölümleri açıklanmaktadır.
adx-sink-config.json
Bu dosya, belirli yapılandırma ayrıntılarını güncelleştirdiğiniz Kusto havuz özellikleri dosyasını içerir:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Kurulumunuza göre aşağıdaki özniteliklerin değerlerini değiştirin: , , , kusto.tables.topics.mapping (veritabanı adı), kusto.ingestion.urlve kusto.query.url. aad.auth.appkeyaad.auth.appidaad.auth.authority
Bağlayıcı - Dockerfile
Bu dosya, bağlayıcı örneği için docker görüntüsünü oluşturmaya yönelik komutlara sahiptir. Git deposu yayın dizininden bağlayıcı indirmeyi içerir.
Storm-events-producer dizini
Bu dizinde yerel bir "StormEvents.csv" dosyasını okuyan ve verileri kafka konusuna yayımlayan bir Go programı vardır.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Kapsayıcıları başlatma
Terminalde kapsayıcıları başlatın:
docker-compose upÜretici uygulaması konu başlığına olay göndermeye
storm-eventsbaşlar. Aşağıdaki günlüklere benzer günlükler görmeniz gerekir:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Günlükleri denetlemek için aşağıdaki komutu ayrı bir terminalde çalıştırın:
docker-compose logs -f | grep kusto-connect
Bağlayıcıyı başlatma
Bağlayıcıyı başlatmak için Kafka Connect REST çağrısı kullanın.
Ayrı bir terminalde aşağıdaki komutla havuz görevini başlatın:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsDurumu denetlemek için aşağıdaki komutu ayrı bir terminalde çalıştırın:
curl http://localhost:8083/connectors/storm/status
Bağlayıcı, alma işlemlerini kuyruğa alma işlemini başlatır.
Not
Günlük bağlayıcısı sorunlarınız varsa bir sorun oluşturun.
Yönetilen kimlik
Varsayılan olarak, Kafka bağlayıcısı alma sırasında kimlik doğrulaması için uygulama yöntemini kullanır. Yönetilen kimlik kullanarak kimlik doğrulaması yapmak için:
Kümenize yönetilen bir kimlik atayın ve depolama hesabınıza okuma izinleri verin. Daha fazla bilgi için bkz . Yönetilen kimlik kimlik doğrulamasını kullanarak veri alma.
adx-sink-config.json dosyanızda olarak ayarlayın
managed_identityaad.auth.strategyve bunun yönetilen kimlik istemcisi (uygulama) kimliğine ayarlandığından emin olunaad.auth.appid.Microsoft Entra hizmet sorumlusu yerine özel örnek meta veri hizmeti belirteci kullanın.
Not
Yönetilen kimlik kullanılırken ve appId tenant çağrı sitesinin bağlamından çıkarılır ve password gerekli değildir.
Verileri sorgulama ve gözden geçirme
Veri alımını onaylama
Veriler tabloya
Stormsgeldikten sonra, satır sayısını denetleyerek veri aktarımını onaylayın:Storms | countAlma işleminde hata olmadığını onaylayın:
.show ingestion failuresVerileri gördüğünüzde birkaç sorgu deneyin.
Verileri sorgulama
Tüm kayıtları görmek için aşağıdaki sorguyu çalıştırın:
Storms | take 10Belirli verileri filtrelemek için ve
projectkullanınwhere:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdşu işleci
summarizekullanın:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart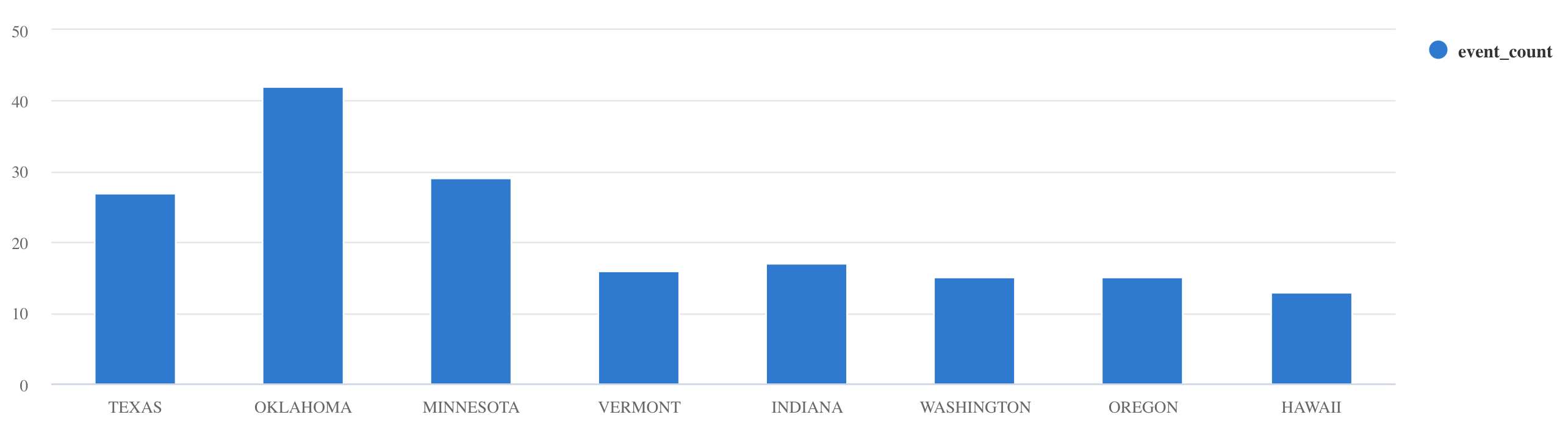
Daha fazla sorgu örneği ve kılavuz için bkz. KQL'de sorgu yazma ve Kusto Sorgu Dili belgeleri.
Reset
Sıfırlamak için aşağıdaki adımları uygulayın:
- Kapsayıcıları durdurma (
docker-compose down -v) - Sil (
drop table Storms) - Tabloyu yeniden oluşturma
Storms - Tablo eşlemesini yeniden oluşturma
- Kapsayıcıları yeniden başlatma (
docker-compose up)
Kaynakları temizleme
Azure Veri Gezgini kaynaklarını silmek için az kusto cluster delete (kusto extension) veya az kusto database delete (kusto extension) kullanın:
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
Kümenizi ve veritabanınızı Azure portalı üzerinden de silebilirsiniz. Daha fazla bilgi için bkz. Azure Veri Gezgini kümesini silme ve Azure Veri Gezgini veritabanını silme.
Kafka Havuz bağlayıcısını ayarlama
Kafka Havuzu bağlayıcısını alma toplu işlemi ilkesiyle çalışacak şekilde ayarlayın:
- Kafka Havuzu
flush.size.bytesboyut sınırını 1 MB'tan başlayarak 10 MB veya 100 MB artışlarla ayarlayın. - Kafka Havuzu kullanılırken veriler iki kez toplanır. Bağlayıcı tarafındaki veriler temizleme ayarlarına ve hizmet tarafında toplu işleme ilkesine göre toplanır. Toplu işlem süresi çok kısaysa ve bu nedenle veriler hem bağlayıcı hem de hizmet tarafından alınamıyorsa, toplu işlem süresi artırılmalıdır. Toplu işlem boyutunu 1 GB olarak ayarlayın ve gerektiğinde 100 MB artış artırın veya azaltın. Örneğin, temizleme boyutu 1 MB ve toplu işlem ilkesi boyutu 100 MB ise, Kafka Havuzu bağlayıcısı verileri 100 MB toplu iş olarak toplar. Bu toplu iş daha sonra hizmet tarafından alır. Toplu işlem ilkesi süresi 20 saniyeyse ve Kafka Havuzu bağlayıcısı 20 saniyelik bir süre içinde 50 MB boşaltıyorsa, hizmet 50 MB toplu işlemi alır.
- Örnekleri ve Kafka bölümlerini ekleyerek ölçeklendirme yapabilirsiniz. Bölüm sayısına kadar artırın
tasks.max. Ayarın boyutundaflush.size.bytesbir blob oluşturmak için yeterli veriniz varsa bir bölüm oluşturun. Blob daha küçükse, toplu iş zaman sınırına ulaştığında işlenir, bu nedenle bölüm yeterli aktarım hızı almaz. Çok sayıda bölüm daha fazla işlem yükü anlamına gelir.
İlgili içerik
- Büyük veri mimarisi hakkında daha fazla bilgi edinin.
- JSON biçimli örnek verileri Azure Veri Gezgini'a nasıl alacağınızı öğrenin.
- Kafka laboratuvarları ile daha fazla bilgi edinin: