Delta Live Tables ile verileri dönüştürme
Bu makalede, delta Live Tables kullanarak veri kümelerinde dönüşümleri bildirme ve kayıtların sorgu mantığı aracılığıyla nasıl işleneceğini belirtme işlemleri açıklanmaktadır. Ayrıca Delta Live Tables işlem hatları oluşturmaya yönelik yaygın dönüştürme desenlerine örnekler içerir.
DataFrame döndüren herhangi bir sorguda bir veri kümesi tanımlayabilirsiniz. Apache Spark yerleşik işlemlerini, UDF'leri, özel mantığı ve MLflow modellerini Delta Live Tables işlem hattınızda dönüşüm olarak kullanabilirsiniz. Delta Live Tables işlem hattınıza veri alındıktan sonra, yukarı akış kaynaklarına karşı yeni veri kümeleri tanımlayarak yeni akış tables, materyalize edilmiş viewsve viewsoluşturabilirsiniz.
Delta Live
viewsne zaman kullanılır, gerçekleştirilmiş viewsne zaman kullanılır, ve akış tables ne zaman kullanılır
İşlem hattı sorgularınızı uygularken verimli ve sürdürülebilir olduklarından emin olmak için en iyi veri kümesi türünü seçin.
Aşağıdakileri yapmak için bir görünüm kullanmayı göz önünde bulundurun:
- İstediğiniz büyük veya karmaşık bir sorguyu daha kolay yönetilebilir sorgulara bölün.
- Beklentileri kullanarak ara sonuçları doğrulayın.
- Kalıcı olması gerekmeyen sonuçlar için depolama ve işlem maliyetlerini azaltın. tables somutlaştırıldıkları için ek hesaplama ve depolama kaynaklarına ihtiyaç duyar.
Aşağıdaki durumlarda gerçekleştirilmiş bir görünüm kullanmayı göz önünde bulundurun:
- Birden çok alt akış sorgusu table'ı tüketir. views isteğe bağlı olarak hesaplandığından, görünüm sorgulandığında görünüm yeniden hesaplanır.
- Diğer işlem hatları, görevler veya sorgular table'i kullanır. views somutlaştırılmadığından, bunları yalnızca aynı işlem hattında kullanabilirsiniz.
- Geliştirme sırasında sorgunun sonuçlarını görüntülemek istiyorsunuz. tables gerçekleştirilmiş olduğundan ve işlem hattı dışında görüntülenebildiği ve sorgulanabildiği için geliştirme sırasında tables kullanmak hesaplamaların doğruluğunu doğrulamaya yardımcı olabilir. Doğruladıktan sonra, gerçekleştirme gerektirmeyen sorguları views'e dönüştürün.
Aşağıdaki durumlarda akış table kullanmayı göz önünde bulundurun:
- Sürekli veya artımlı olarak büyüyen bir veri kaynağında sorgu tanımlanır.
- Sorgu sonuçları artımlı olarak hesaplanmalıdır.
- İşlem hattı için yüksek aktarım hızı ve düşük gecikme süresi gerekir.
Not
Akış tables her zaman akış kaynaklarına göre tanımlanır. CdC akışlarından güncelleştirmeleri uygulamak için ile APPLY CHANGES INTO akış kaynaklarını da kullanabilirsiniz. Bkz. DEĞIŞIKLIKLERI UYGULA API'leri: Delta Live Tablesile değişiklik verilerini yakalamayı basitleştirme.
tables'ı schema hedefinden çıkar
Dış tüketime yönelik olmayan ara tables hesaplamanız gerekiyorsa, schema anahtar sözcüğünü kullanarak bunların bir TEMPORARY'e yayımlanmalarını engelleyebilirsiniz. Geçici tables verileri Delta Live Tables semantiğine göre depolamaya ve işlemeye devam eder ancak geçerli işlem hattı dışından erişilmemelidir. Geçici bir table, bunu oluşturan işlem hattının ömrü boyunca kalıcı olur. Geçici tablesbildirmek için aşağıdaki söz dizimini kullanın:
SQL
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
Python
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Akış tables ve malzemeleşmiş views'i tek bir işlem hattında birleştir
Akış tables, Apache Spark Yapılandırılmış Akışı'nın işlem güvencelerini devralır ve sadece ekleme veri kaynaklarından sorgu işlemek için yapılandırılır. where yeni satırlar her zaman değiştirilmek yerine kaynak table'e eklenir.
Not
Varsayılan olarak, akış
Yaygın bir akış düzeni, bir işlem hattında ilk veri kümelerini oluşturmak için kaynak verilerin alımını içerir. Bu ilk veri kümeleri genellikle bronz tables olarak adlandırılır ve genellikle basit dönüştürmeler gerçekleştirir.
Buna karşılık, genellikle altın tablesolarak adlandırılan bir işlem hattındaki nihai tables, karmaşık toplamalar yapmayı veya bir APPLY CHANGES INTO işleminin hedeflerinden okumayı gerektirir. Doğal olarak bu işlemler eklemeler yerine güncelleştirmeler oluşturduğundan, veri akışı tablesgirdi olarak desteklenmez. Bu dönüşümler, malzemeleşmiş viewsiçin daha uygundur.
Akış tables ve gerçekleştirilmiş views'i tek bir işlem hattında birleştirerek, işlem hattınızı basitleştirebilir, ham verilerin yüksek maliyetli bir şekilde yeniden alımını veya yeniden işlenmesini önleyebilir ve etkili bir şekilde kodlanmış ve filtrelenmiş bir veri kümesi üzerinde karmaşık toplamaları hesaplamak için SQL'in tüm imkanlarını kullanabilirsiniz. Aşağıdaki örnekte bu tür bir karma işleme gösterilmektedir:
Not
Bu örneklerde, bulut depolamadan dosya yüklemek için Otomatik Yükleyici kullanılır. Unity
Python
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("LIVE.streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("LIVE.streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM read_files(
"abfss://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(LIVE.streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM LIVE.streaming_silver GROUP BY user_id
JSON dosyalarını Azure depolama alanından artımlı olarak almak için Otomatik Yükleyici'yi kullanma hakkında daha fazla bilgi edinin.
Akış statik birleşimleri
Yalnızca ekleme verilerinin sürekli akışını, öncelikli olarak statik boyut tablenormalleştirildiğinde akış statik birleşimleri iyi bir seçimdir.
Her bir işlem hattı updateile, akıştan gelen yeni kayıtlar statik table'in en güncel anlık görüntüsüyle birleştirilir. Eğer akış table'e ait karşılık gelen veriler işlendikten sonra statik table'a kayıtlar eklenip güncellenirse, bu kayıtlar ancak tam bir refresh gerçekleştirildiğinde yeniden hesaplanır.
Tetiklenen yürütme için yapılandırılmış işlem hatlarında statik table, update başladığı anda sonuçları döndürür. Sürekli yürütme için yapılandırılmış işlem hatlarında, table her bir table'yi işlediğinde, statik update'ın en son sürümü sorgulanır.
Aşağıda bir akış statik joinörneği verilmiştir:
Python
@dlt.table
def customer_sales():
return spark.readStream.table("LIVE.sales").join(spark.readStream.table("LIVE.customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(LIVE.sales)
INNER JOIN LEFT LIVE.customers USING (customer_id)
Toplamaları verimli bir şekilde hesaplama
Akış tables'yi kullanarak adet, min, maks veya toplam gibi basit dağıtıcı toplamaları ve ortalama veya standart sapma gibi cebirsel toplamaları artımlı olarak hesaplayabilirsiniz. Databricks, yan tümcesi olan bir sorgu gibi sınırlı sayıda gruba sahip sorgular GROUP BY country için artımlı toplama önerir. Yalnızca her updateile yeni giriş verileri okunur.
Kademeli toplamalar gerçekleştiren Delta Live Tables sorguları yazmayı öğrenmek için, Filigranlarla Pencereli Toplamaları Gerçekleştirmebaşlığına bakın.
Delta Live Tables işlem hattında MLflow modellerini kullanma
Not
Unity Catalogözellikli bir işlem hattında MLflow modellerini kullanmak için işlem hattınızın preview kanalını kullanacak şekilde yapılandırılması gerekir. Kanalı kullanmak current için işlem hattınızı Hive meta veri deposunda yayımlayacak şekilde yapılandırmanız gerekir.
Delta Live Tables işlem hatlarında MLflow tarafından eğitilen modelleri kullanabilirsiniz. MLflow modelleri, Azure Databricks'te dönüşüm olarak değerlendirilir; bu da spark DataFrame girişi üzerine hareket ettikleri ve sonuçları Spark DataFrame olarak döndürdikleri anlamına gelir. Delta Live Tables veri kümelerini DataFrame'lerde tanımladığından, MLflow kullanan Apache Spark iş yüklerini yalnızca birkaç kod satırıyla Delta Live Tables dönüştürebilirsiniz. MLflow hakkında daha fazla bilgi için bkz. MLflow for gen AI agent and ML model lifecycle.
Eğer bir MLflow modelini çağıran bir Python not defteriniz varsa, işlevlerin dönüştürme sonuçları döndürecek şekilde tanımlandığından emin olarak ve Tables dekoratörünü kullanarak bu kodu Delta Live @dlt.table'ye uyarlayabilirsiniz. Delta Live Tables, MLflow'u varsayılan olarak yüklemez, bu nedenle %pip install mlflow ile MLflow kütüphanelerini yüklediğinizden ve defterinizin en üstünde mlflow ile dlt'ü import ettiğinizden emin olun. Delta Live
Delta Live Tables'da MLflow modellerini kullanmak için aşağıdaki adımları tamamlayın:
- MLflow modelinin çalıştırma kimliğini ve model adını alın. Çalıştırma kimliği ve model adı, MLflow modelinin URI'sini oluşturmak için kullanılır.
- MLflow modelini yüklemek üzere Spark UDF tanımlamak için URI'yi kullanın.
- MLflow modelini kullanmak için table tanımlarınızdaki UDF'yi çağırın.
Aşağıdaki örnekte bu desen için temel söz dizimi gösterilmektedir:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Tam bir örnek olarak aşağıdaki kod, kredi riski verileri üzerinde eğitilmiş bir MLflow modelini yükleyen adlı loaded_model_udf bir Spark UDF tanımlar. Tahmin yapmak için kullanılan veriler columns, UDF'ye bir bağımsız değişken olarak iletilir.
table
loan_risk_predictions, loan_risk_input_dataiçindeki her satır için tahminleri hesaplar.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
El ile silmeleri veya güncelleştirmeleri koruma
Delta Live Tables, bir update'deki kayıtları el ile silmenize veya table yapmanıza ve aşağı akıştaki refresh'i yeniden hesaplamak için tables operasyonunu gerçekleştirmenize olanak tanır.
Varsayılan olarak Delta Live Tables, bir işlem hattı her güncelleştirildiğinde giriş verilerine göre table sonuçları yeniden derler, bu nedenle silinen kaydın kaynak verilerden yeniden yüklenmediğinden emin olmanız gerekir.
pipelines.reset.allowed
table özelliğinin false olarak ayarlanması, table'ün yenilenmesini önler, ancak tables'e artımlı yazmaların yapılmasını veya yeni verilerin table'e akmasını engellemez.
Aşağıdaki diyagram, iki akış tableskullanılarak yapılan bir örneği göstermektedir.
-
raw_user_tablebir kaynaktan ham kullanıcı verilerini alır. -
bmi_table, ağırlık ve boyraw_user_tabledeğerlerini kullanarak BMI puanlarını artımlı olarak hesaplar.
update'den kullanıcı kayıtlarını el ile silmek veya raw_user_table ve bmi_table'yi yeniden hesaplamak istiyorsunuz.
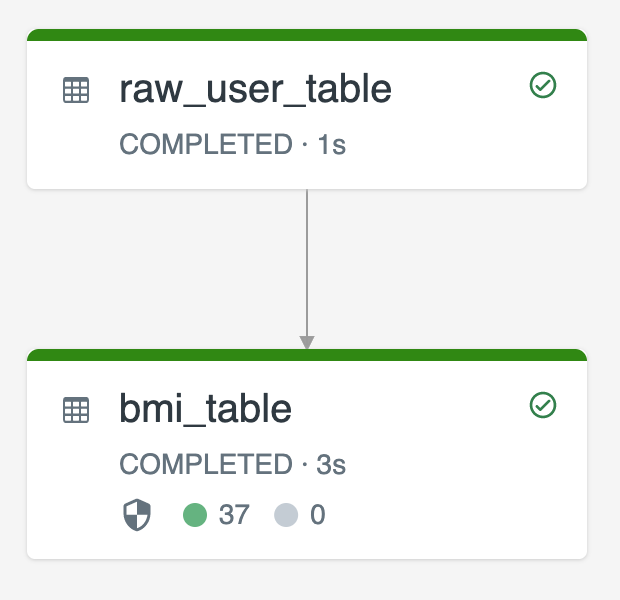
Aşağıdaki kodda, pipelines.reset.allowed için tam table devre dışı bırakılacak şekilde falserefresh özelliğinin raw_user_table olarak ayarlanması gösterilmektedir; böylece hedeflenen değişiklikler zaman içinde korunur, ancak bir işlem hattı tables çalıştırıldığında aşağı akış update yeniden derlenir:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM read_files("/databricks-datasets/iot-stream/data-user", "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(LIVE.raw_user_table);