Visual Studio için Data Lake araçlarını kullanarak Apache Hive sorgularını çalıştırma
Visual Studio için Data Lake araçlarını kullanarak Apache Hive'ı sorgulamayı öğrenin. Data Lake araçları, Azure HDInsight üzerinde Apache Hadoop'a Hive sorgularını kolayca oluşturmanıza, göndermenize ve izlemenize olanak sağlar.
Önkoşullar
HDInsight üzerinde bir Apache Hadoop kümesi. Bu öğeyi oluşturma hakkında bilgi için bkz . Resource Manager şablonunu kullanarak Azure HDInsight'ta Apache Hadoop kümesi oluşturma.
Visual Studio. Bu makaledeki adımlarda Visual Studio 2019 kullanılır.
Visual Studio için HDInsight araçları veya Visual Studio için Azure Data Lake araçları. Araçları yükleme ve yapılandırma hakkında bilgi için bkz . Visual Studio için Data Lake Araçları'nı yükleme.
Visual Studio kullanarak Apache Hive sorguları çalıştırma
Hive sorguları oluşturmak ve çalıştırmak için iki seçeneğiniz vardır:
- Geçici sorgular oluşturun.
- Hive uygulaması oluşturun.
Geçici Hive sorgusu oluşturma
Geçici sorgular Batch veya Etkileşimli modda yürütülebilir.
Visual Studio'yu başlatın ve Kod olmadan devam et'i seçin.
Sunucu Gezgini'nde Azure'a sağ tıklayın, Microsoft Azure Aboneliğine Bağlan... öğesini seçin ve oturum açma işlemini tamamlayın.
HDInsight'ı genişletin, sorguyu çalıştırmak istediğiniz kümeye sağ tıklayın ve ardından Hive Sorgusu Yaz'ı seçin.
Aşağıdaki hive sorgusunu girin:
SELECT * FROM hivesampletable;Yürüt'ü seçin. Yürütme modu varsayılan olarak Etkileşimli'yi kullanır.
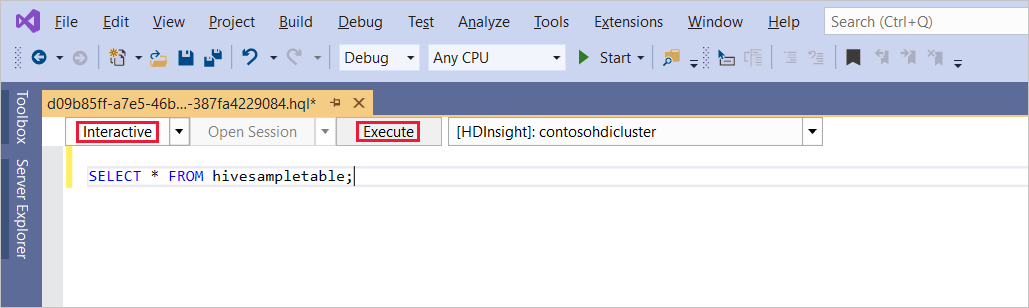
Aynı sorguyu Batch modunda çalıştırmak için, açılan listeyi Etkileşimli'den Batch'e geçirin. Yürütme düğmesi Yürüt'ten Gönder'e değişir.

Hive düzenleyicisi IntelliSense’i destekler. Visual Studio için Data Lake Araçları, Hive betiğinizi düzenlerken uzak meta verilerin yüklenmesini destekler. Örneğin, yazarsanız
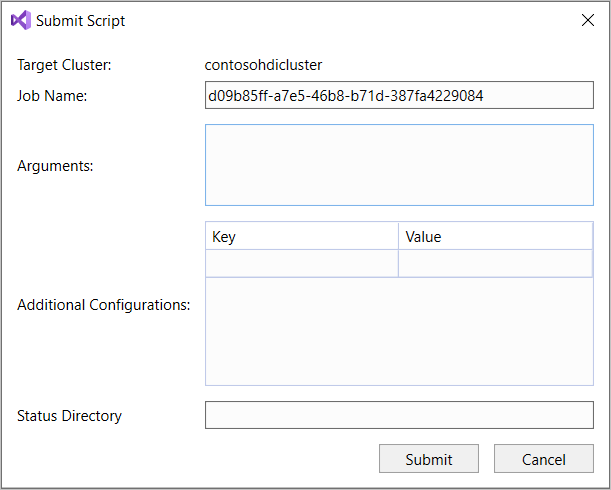
SELECT * FROMIntelliSense önerilen tüm tablo adlarını listeler. Bir tablo adı belirtildiğinde, IntelliSense sütun adlarını listeler. Araçlar çoğu Hive DML deyimlerini, alt sorguları ve yerleşik UDF'leri destekler. IntelliSense yalnızca HDInsight araç çubuğunda seçilen kümelerin meta verilerini önerir.Sorgu araç çubuğunda (sorgu sekmesinin altındaki ve sorgu metninin üstündeki alan) Gönder'i seçin veya Gönder'in yanındaki aşağı açılan oku seçin ve açılan listeden Gelişmiş'i seçin. İkinci seçeneği seçerseniz,
Gelişmiş gönderme seçeneğini belirlediyseniz, Betiği Gönder iletişim kutusunda İş Adı, Bağımsız Değişkenler, Ek Yapılandırmalar ve Durum Dizini'ni yapılandırın. Ardından Gönder'i seçin.
Hive uygulaması oluşturma
Hive uygulaması oluşturarak hive sorgusu çalıştırmak için şu adımları izleyin:
Visual Studio'yu açın.
Başlangıç penceresinde Yeni proje oluştur'u seçin.
Yeni proje oluştur penceresindeki Şablon ara kutusuna Hive yazın. Ardından Hive Uygulaması'nı ve ardından İleri'yi seçin.
Yeni projenizi yapılandırın penceresinde bir Proje adı girin, yeni proje için bir Konum seçin veya oluşturun ve ardından Oluştur'u seçin.
Bu projeyle oluşturulan Script.hql dosyasını açın ve aşağıdaki HiveQL deyimlerine yapıştırın:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Bu deyimler aşağıdaki eylemleri gerçekleştirir:
DROP TABLE: Varsa tabloyu siler.CREATE EXTERNAL TABLE: Hive'da yeni bir 'dış' tablo oluşturur. Dış tablolar tablo tanımını yalnızca Hive'da depolar. (Veriler özgün konumda bırakılır.)Not
Temel alınan verilerin MapReduce işi veya Azure hizmeti gibi bir dış kaynak tarafından güncelleştirilmesini beklediğiniz durumlarda dış tablolar kullanılmalıdır.
Dış tablo bırakılıyorsa veriler silinmez, yalnızca tablo tanımı silinir.
ROW FORMAT: Hive'a verilerin nasıl biçimlendirildiğini bildirir. Bu durumda, her günlükteki alanlar bir boşlukla ayrılır.STORED AS TEXTFILE LOCATION: Hive'a verilerin örnek/veri dizininde depolandığını ve metin olarak depolandığını bildirir.SELECT: sütunununt4değerini[ERROR]içerdiği tüm satırların sayısını seçer. Bu deyim, üç satır bu değeri içerdiğinden3değerini döndürür.INPUT__FILE__NAME LIKE '%.log': Hive'a yalnızca .log ile biten dosyalardan veri döndürmesini söyler. Bu yan tümce, aramayı verileri içeren sample.log dosyasıyla kısıtlar.
Sorgu dosyası araç çubuğundan (geçici sorgu araç çubuğuna benzer bir görünüme sahip), bu sorgu için kullanmak istediğiniz HDInsight kümesini seçin. Ardından, Deyimleri Hive işi olarak çalıştırmak için Etkileşimli'yi Batch (gerekirse) olarak değiştirin ve Gönder'i seçin.
Hive İşi Özeti görüntülenir ve çalışan iş hakkındaki bilgileri görüntüler. İş Durumu Tamamlandı olarak değişene kadar iş bilgilerini yenilemek için Yenile bağlantısını kullanın.
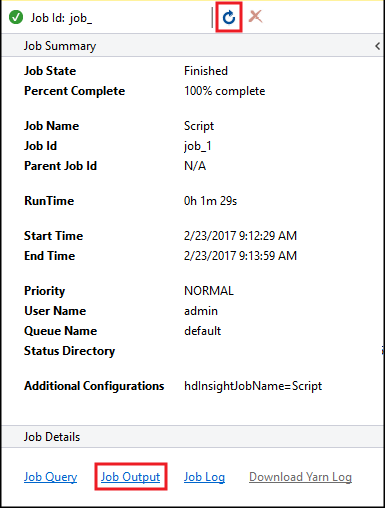
Bu işin çıkışını görüntülemek için İş Çıktısı'nı seçin. Bu sorgu tarafından döndürülen değer olan değerini görüntüler
[ERROR] 3.
Ek örnek
Aşağıdaki örneklog4jLogs, hive uygulaması oluşturma adlı önceki yordamda oluşturulan tabloyu temel alır.
Sunucu Gezgini'nden kümenize sağ tıklayın ve Hive Sorgusu Yaz'ı seçin.
Aşağıdaki hive sorgusunu girin:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Bu deyimler aşağıdaki eylemleri gerçekleştirir:
CREATE TABLE IF NOT EXISTS: Henüz yoksa bir tablo oluşturur.EXTERNALAnahtar sözcük kullanılmadığından, bu deyim bir iç tablo oluşturur. İç tablolar Hive veri ambarında depolanır ve Hive tarafından yönetilir.Not
Tablolardan farklı olarak
EXTERNAL, iç tablo bırakılıyorsa temel alınan veriler de silinir.STORED AS ORC: Verileri iyileştirilmiş satır sütunlu (ORC) biçiminde depolar. ORC, Hive verilerini depolamak için yüksek oranda iyileştirilmiş ve verimli bir biçimdir.INSERT OVERWRITE ... SELECT: içeren[ERROR]tablodanlog4jLogssatırları seçer ve ardından verileri tabloyaerrorLogsekler.
Gerekirse Etkileşimli'yi Batch olarak değiştirin ve gönder'i seçin.
İşin tabloyu oluşturduğunu doğrulamak için Sunucu Gezgini'ne gidin ve Azure>HDInsight'ı genişletin. HDInsight kümenizi genişletin ve ardından Hive Veritabanları>varsayılan'ı genişletin. errorLogs tablosu ve Log4jLogs tablosu listelenir.
Sonraki adımlar
Gördüğünüz gibi, Visual Studio için HDInsight araçları HDInsight üzerinde Hive sorguları ile çalışmak için kolay bir yol sağlar.
HDInsight'ta Hive hakkında genel bilgi için bkz. Azure HDInsight'ta Apache Hive ve HiveQL nedir?
HDInsight üzerinde Hadoop ile çalışmanın diğer yolları hakkında bilgi için bkz . HDInsight üzerinde Apache Hadoop'ta MapReduce kullanma
Visual Studio için HDInsight araçları hakkında daha fazla bilgi için bkz . Azure HDInsight'a bağlanmak ve Apache Hive sorguları çalıştırmak için Visual Studio için Data Lake Araçları'nı kullanma