Hızlı Başlangıç: Apache Zeppelin ile Azure HDInsight'ta Apache Hive sorguları yürütme
Bu hızlı başlangıçta, Apache Zeppelin kullanarak Azure HDInsight'ta Apache Hive sorguları çalıştırmayı öğreneceksiniz. HDInsight Etkileşimli Sorgu kümeleri, etkileşimli Hive sorguları çalıştırmak için kullanabileceğiniz Apache Zeppelin not defterlerini içerir.
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Önkoşullar
HDInsight Etkileşimli Sorgu kümesi. Bkz. HDInsight kümesi oluşturmak için küme oluşturma. Etkileşimli Sorgu küme türünü seçtiğinizden emin olun.
Apache Zeppelin Notu oluşturma
değerini aşağıdaki URL'deki
https://CLUSTERNAME.azurehdinsight.net/zeppelinkümenizin adıyla değiştirinCLUSTERNAME. Ardından URL'yi bir web tarayıcısına girin.Küme oturum açma kullanıcı adınızı ve parolanızı girin. Zeppelin sayfasından yeni bir not oluşturabilir veya mevcut notları açabilirsiniz. HiveSample bazı örnek Hive sorguları içerir.
Yeni not oluştur'u seçin.
Yeni not oluştur iletişim kutusunda aşağıdaki değerleri yazın veya seçin:
- Not Adı: Not için bir ad girin.
- Varsayılan yorumlayıcı: Açılan listeden jdbc'yi seçin.
Not Oluştur'u seçin.
Kod bölümüne aşağıdaki Hive sorgusunu girin ve Shift + Enter tuşlarına basın:
%jdbc(hive) show tables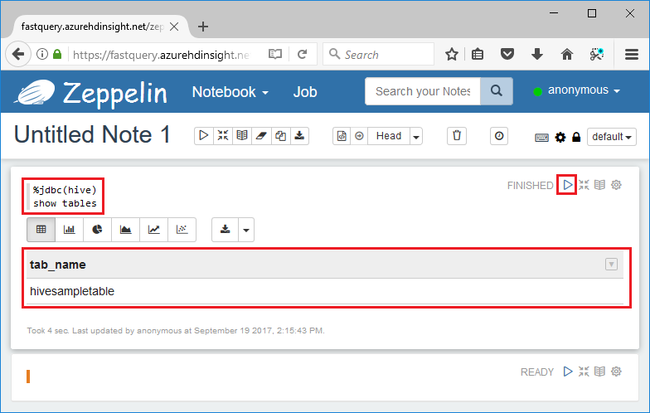
%jdbc(hive)İlk satırdaki deyimi not defterine Hive JDBC yorumlayıcısını kullanmasını söyler.Sorgu hivesampletable adlı bir Hive tablosu döndürecektir.
Hivesampletable için çalıştırabileceğiniz iki Hive sorgusu daha aşağıdadır:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Geleneksel Hive ile karşılaştırıldığında sorgu sonuçları çok daha hızlı bir şekilde geri gelir.
Daha fazla örnek
Bir tablo oluşturun. Zeppelin Not Defteri'nde kodu yürütür:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Yeni tabloya veri yükleyin. Zeppelin Not Defteri'nde kodu yürütür:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Tek bir kayıt ekleyin. Zeppelin Not Defteri'nde kodu yürütür:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Daha fazla söz dizimi için Hive dil kılavuzunu gözden geçirin.
Kaynakları temizleme
Hızlı başlangıcı tamamladıktan sonra kümeyi silmek isteyebilirsiniz. HDInsight ile verileriniz Azure Depolama'de depolanır, böylece kullanılmadığında kümeyi güvenle silebilirsiniz. Kullanımda olmasa bile HDInsight kümesi için de ücretlendirilirsiniz. Küme ücretleri depolama ücretlerinden çok daha fazla olduğundan, kullanımda olmayan kümeleri silmek ekonomik bir anlam ifade eder.
Kümeyi silmek için bkz . Tarayıcınızı, PowerShell'i veya Azure CLI'yı kullanarak HDInsight kümesini silme.
Sonraki adımlar
Bu hızlı başlangıçta, Apache Zeppelin kullanarak Azure HDInsight'ta Apache Hive sorguları çalıştırmayı öğrendiniz. Hive sorguları hakkında daha fazla bilgi edinmek için, sonraki makalede Visual Studio ile sorguların nasıl yürütüleceği gösterilir.