Azure AI Search'te arama sonuçlarını şekillendirme veya arama sonuçları oluşturmayı değiştirme
Bu makalede, arama sonuçlarının bileşimi ve arama sonuçlarını senaryolarınıza uyacak şekilde şekillendirme açıklanmaktadır. Arama sonuçları sorgu yanıtında döndürülür. Yanıtın şekli, sorgunun kendisindeki parametreler tarafından belirlenir. Bu parametreler şunlardır:
- Dizinde bulunan eşleşme sayısı (
count) - Yanıtta döndürülen eşleşme sayısı (varsayılan olarak 50, ile
topyapılandırılabilir) veya sayfa başına (skipvetop) - Derecelendirme için kullanılan her sonuç için bir arama puanı (
@search.score) - Arama sonuçlarına dahil edilen alanlar (
select) - Sıralama mantığı (
orderby) - Sonuç içindeki terimlerin vurgulanması, gövdedeki tüm veya kısmi terimle eşleşme
- Semantik dereceleyiciden isteğe bağlı öğeler (
answersher eşleşme için en üsttecaptions)
Arama sonuçları en üst düzey alanları içerebilir, ancak yanıtın çoğu dizideki eşleşen belgelerden oluşur.
Sorgu yanıtını tanımlamak için istemciler ve API'ler
Sorgu yanıtını yapılandırmak için aşağıdaki istemcileri kullanabilirsiniz:
- Desteklenen herhangi bir parametreyi belirtebilmeniz için JSON görünümünü kullanarak Azure portalında Arama Gezgini
- Belgeler - POST (REST API'leri)
- SearchClient.Search Yöntemi (.NET için Azure SDK)
- SearchClient.Search Yöntemi (Python için Azure SDK)
- SearchClient.Search Yöntemi (JavaScript için Azure)
- SearchClient.Search Yöntemi (Java için Azure)
Sonuç bileşimi
Sonuçlar çoğunlukla tablosaldır, tüm retrievable alanların alanlarından oluşur veya yalnızca parametresinde select belirtilen alanlarla sınırlıdır. Sorgu mantığınız ilgi derecelendirmesini kapsamadığı sürece satırlar, genellikle ilgi sırasına göre sıralanmış eşleşen belgelerdir.
Arama sonuçlarında hangi alanların olduğunu seçebilirsiniz. Bir arama belgesinde çok fazla sayıda alan olsa da, her belgeyi sonuçlarda temsil etmek için genellikle yalnızca birkaçı gerekir. Sorgu isteğinde, yanıtta hangi retrievable alanların görüneceğini belirtmek için ekleyinselect=<field list>.
Belgeler arasında karşıtlık ve farklılaşma sunan alanları seçerek kullanıcının bir tıklama yanıtını davet etmek için yeterli bilgi sağlayın. Bir e-ticaret sitesinde ürün adı, açıklaması, markası, rengi, boyutu, fiyatı ve derecelendirmesi olabilir. Yerleşik hotels-sample dizini için, aşağıdaki örnekteki "select" alanları olabilir:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Beklenmeyen sonuçlar için ipuçları
Bazen, görmeyi beklediğiniz şey sorgu çıktısı değildir. Örneğin, bazı sonuçların yinelenen sonuçlar gibi göründüğünü veya üst kısımda görünmesi gereken bir sonucun sonuçlarda daha düşük bir konuma getirildiğini fark edebilirsiniz. Sorgu sonuçları beklenmedik olduğunda, sonuçların iyileşip iyileşmediğini görmek için şu sorgu değişikliklerini deneyebilirsiniz:
Ölçütlerden herhangi biri yerine tüm ölçütlerde eşleşme gerektirecek şekilde (varsayılan)
searchMode=allolarak değiştirinsearchMode=any. Bu durum özellikle boole işleçleri sorguya eklendiğinde geçerlidir.Sorgu sonucunu değiştirip değiştirmediğini görmek için farklı sözcük temelli çözümleyicilerle veya özel çözümleyicilerle denemeler yapın. Varsayılan çözümleyici, hecelenmiş sözcükleri ayırır ve sözcükleri kök formlara küçültür ve bu da genellikle sorgu yanıtının sağlamlığını artırır. Ancak, kısa çizgileri korumanız gerekiyorsa veya dizeler özel karakterler içeriyorsa, dizinin doğru biçimde belirteçler içerdiğinden emin olmak için özel çözümleyiciler yapılandırmanız gerekebilir. Daha fazla bilgi için bkz . Kısmi terim araması ve özel karakterler içeren desenler (kısa çizgi, joker karakter, regex, desenler).
Eşleşmeleri sayma
parametresi, count dizindeki sorguyla eşleşme olarak kabul edilen belge sayısını döndürür. Sayıyı döndürmek için sorgu isteğine ekleyin count=true . Arama hizmeti tarafından uygulanan maksimum değer yoktur. Sorgunuza ve belgelerinizin içeriğine bağlı olarak, sayı dizindeki her belge kadar yüksek olabilir.
Dizin kararlı olduğunda sayı doğrudur. Sistem belgeleri etkin bir şekilde ekliyor, güncelleştiriyor veya siliyorsa, tam olarak dizine eklenmemiş belgeler hariç olmak üzere yaklaşık sayıdır.
Count, arama hizmetindeki rutin bakımlardan veya diğer iş yüklerinden etkilenmez. Ancak, birden çok bölümünüz ve tek bir çoğaltmanız varsa, bölümler yeniden başlatıldıktan sonra belge sayısı (birkaç dakika) içinde kısa süreli dalgalanmalarla karşılaşabilirsiniz.
İpucu
Dizin oluşturma işlemlerini denetlemek için boş bir arama search=* sorgusuna ekleyerek count=true dizinin beklenen sayıda belge içerip içermediğini onaylayabilirsiniz. Sonuç, dizininizdeki belgelerin tam sayısıdır.
Sorgu söz dizimini test ederken, count=true değişikliklerinizin daha büyük veya daha az sonuç döndürerek yararlı geri bildirimde bulunup bulunmayacağını hızlıca söyleyebilir.
Yanıttaki sonuç sayısı
Azure AI Search, sorguların aynı anda çok fazla belge almasını önlemek için sunucu tarafı sayfalama kullanır. Yanıttaki sonuç sayısını belirleyen sorgu parametreleri ve skipolurtop. top bir sayfadaki arama sonuçlarının sayısını ifade eder. skip bir aralığıdır topve arama motoruna bir sonraki kümeyi almadan önce kaç sonuç atlanacağına ilişkin bilgi sağlar.
Varsayılan sayfa boyutu 50,en büyük sayfa boyutu ise 1.000'dir. 1.000'den büyük bir değer belirtirseniz ve dizininizde 1.000'den fazla sonuç bulunursa, yalnızca ilk 1.000 sonuç döndürülür. Eşleşme sayısı sayfa boyutunu aşarsa yanıt, sonraki sonuç sayfasını almaya yönelik bilgiler içerir. Örneğin:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
Sorgunun tam metin araması veya anlamsal olduğu varsayılarak en üstteki eşleşmeler arama puanına göre belirlenir. Aksi takdirde, en üst eşleşmeler tam eşleşme sorguları için rastgele bir sıradır (tekdüzen @search.score=1.0 rastgele derecelendirmeyi gösterir).
Varsayılan 50'yi geçersiz kılmak için ayarlayın top . Daha yeni önizleme API'lerinde karma sorgu kullanıyorsanız en fazla 10.000 belge döndürmek için maxTextRecallSize belirtebilirsiniz.
Sonuç kümesinde döndürülen tüm belgelerin disk belleğini denetlemek için ve skip değerlerini birlikte kullanıntop. Bu sorgu, ilk 15 eşleşen belge kümesini ve toplam eşleşme sayısını döndürür.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Bu sorgu ikinci kümeyi döndürür ve sonraki 15'i (16 ile 30) almak için ilk 15'i atlar:
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Temel alınan dizin değişiyorsa sayfalandırılmış sorguların sonuçlarının kararlı olacağı garanti edilmez. Sayfalama, her sayfanın değerini skip değiştirir, ancak her sorgu bağımsızdır ve sorgu zamanında dizinde mevcut olan verilerin geçerli görünümünde çalışır (başka bir deyişle, genel amaçlı veritabanında bulunanlar gibi sonuçların önbelleğe alınmaması veya anlık görüntüsü yoktur).
Aşağıda yinelenenleri nasıl alabileceğinize bir örnek verilmiştir. Dört belge içeren bir dizin varsayma:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Şimdi sonuçların derecelendirmeye göre sıralanmış şekilde aynı anda iki tane döndürülmesini istediğinizi varsayalım. Sonuçların ilk sayfasını almak için şu sorguyu yürütebilirsiniz: $top=2&$skip=0&$orderby=rating desc, aşağıdaki sonuçları üretir:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
Hizmette, sorgu çağrıları arasında dizinine beşinci bir belge eklendiğini varsayalım: { "id": "5", "rating": 4 }. Kısa bir süre sonra ikinci sayfayı $top=2&$skip=2&$orderby=rating descgetirmek için bir sorgu yürütür ve şu sonuçları alırsınız:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
2. belgenin iki kez getirildiğini unutmayın. Bunun nedeni, yeni belge 5'in derecelendirme için daha büyük bir değere sahip olmasıdır, bu nedenle belge 2'den önce sıralanır ve ilk sayfaya iner. Bu davranış beklenmeyen bir davranış olsa da, arama altyapısının davranışı tipiktir.
Çok sayıda sonuç üzerinden sayfalama
Disk belleği için alternatif bir teknik, için skipgeçici bir çözüm olarak bir sıralama düzeni ve aralık filtresi kullanmaktır.
Bu geçici çözümde, bir belge kimliği alanına veya her belge için benzersiz olan başka bir alana sıralama ve filtreleme uygulanır. Benzersiz alanın arama dizininde ve sortable ilişkilendirmesi olmalıdırfilterable.
Sıralanmış sonuçların tam sayfasını döndürmek için bir sorgu gönderin.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Arama sorgusu tarafından döndürülen son sonucu seçin. Burada yalnızca kimlik değerine sahip örnek bir sonuç gösterilmiştir.
{ "id": "50" }Bir sonraki sonuç sayfasını getirmek için bir aralık sorgusunda bu kimlik değerini kullanın. Bu kimlik alanı benzersiz değerlere sahip olmalıdır, aksi takdirde sayfalandırma yinelenen sonuçlar içerebilir.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Sayfalandırma, sorgu sıfır sonuç döndürdüğünde sona erer.
Not
filterable ve sortable öznitelikleri yalnızca bir alan bir dizine ilk eklendiğinde etkinleştirilebilir, var olan bir alanda etkinleştirilemez.
Sonuçları sıralama
Tam metin arama sorgusunda sonuçlar şu şekilde sıralanabilir:
- arama puanı
- anlamsal reranker puanı
- alanda sıralama düzeni
sortable
Puanlama profili ekleyerek belirli alanlarda bulunan eşleşmeleri de artırabilirsiniz.
Arama puanına göre sırala
Tam metin arama sorguları için sonuçlar, bm25 algoritması kullanılarak otomatik olarak arama puanına göre sıralanır ve terim sıklığı, belge uzunluğu ve ortalama belge uzunluğu temel alınarak hesaplanır.
Aralık @search.score sınırsızdır veya eski hizmetlerde 1,00'a kadar (ancak dahil değildir) 0'dır.
Her iki algoritma @search.score için de 1,00'a eşit bir değer, tüm sonuçlarda 1,0 puanının tekdüzen olduğu, puanlanmamış veya kaydedilmemiş bir sonuç kümesini gösterir. Sorgu formu belirsiz arama, joker karakter veya regex sorguları ya da boş bir arama (search=* ) olduğunda, puanlanmamış sonuçlar oluşur. Puanlanmamış sonuçlara göre bir derecelendirme yapısı uygulamanız gerekiyorsa, bu hedefe ulaşmak için bir orderby ifadeyi göz önünde bulundurun.
Semantik reranker tarafından sipariş
Semantik dereceleyici kullanıyorsanız, @search.rerankerScore sonuçlarınızın sıralama düzenini belirler.
Aralık @search.rerankerScore 1 ile 4,00 arasındadır ve daha yüksek bir puan daha güçlü bir anlamsal eşleşmeyi gösterir.
Orderby ile sipariş
Tutarlı sıralama bir uygulama gereksinimiyse, alanda bir orderby ifade tanımlayabilirsiniz. Sonuçları sıralamak için yalnızca "sıralanabilir" olarak dizine alınan alanlar kullanılabilir.
Derecelendirme, tarih ve konum dahil olmak üzere yaygın olarak kullanılan orderby alanlar. Konuma göre filtreleme, filtre ifadesinin alan adına ek olarak işlevi çağırmasını geo.distance() gerektirir.
Sayısal alanlar (Edm.Double, Edm.Int32, Edm.Int64) sayısal düzende sıralanır (örneğin, 1, 2, 10, 11, 20).
Dize alanları (Edm.Stringalt Edm.ComplexType alanlar), dile bağlı olarak ASCII sıralama düzeninde veya Unicode sıralama düzeninde sıralanır.
Dize alanlarındaki sayısal içerik alfabetik olarak sıralanır (1, 10, 11, 2, 20).
Büyük harf dizeleri küçük harflerden önce sıralanır (APPLE, Apple, BANANA, Muz, elma, muz). Bu davranışı değiştirmek için sıralamadan önce metni önceden işlemek için bir metin normalleştiricisi atayabilirsiniz. Azure AI Search alanın analizsiz bir kopyasına göre sıralandığından, alanda küçük harf belirteci kullanmanın sıralama davranışı üzerinde hiçbir etkisi yoktur.
Aksanlarla sonuç veren dizeler en son görünür (Äpfel, Öffnen, Üben)
Puanlama profili kullanarak ilgi düzeyini artırma
Sipariş tutarlılığını yükselten bir diğer yaklaşım da özel puanlama profili kullanmaktır. Puanlama profilleri, belirli alanlarda bulunan eşleşmeleri artırma özelliğiyle arama sonuçlarındaki öğelerin derecelendirmesi üzerinde daha fazla denetim sahibi olmanıza olanak sağlar. Ek puanlama mantığı, her belgenin arama puanları birbirinden daha uzak olduğundan çoğaltmalar arasındaki küçük farkları geçersiz kılmaya yardımcı olabilir. Bu yaklaşım için derecelendirme algoritmasını öneririz.
İsabet vurgulama
İsabet vurgulama, sonuç olarak eşleşen terimlere uygulanan metin biçimlendirmesini (kalın veya sarı vurgular gibi) ifade eder ve bu da eşleşmeyi belirlemeyi kolaylaştırır. Vurgulama, eşleşmenin hemen belirgin olmadığı bir açıklama alanı gibi daha uzun içerik alanları için kullanışlıdır.
Vurgulamanın tek tek terimlere uygulandığına dikkat edin. Tüm alanın içeriği için vurgu özelliği yoktur. Bir tümceciği vurgulamak istiyorsanız, tırnak içine alınmış bir sorgu dizesinde eşleşen terimleri (veya tümceciği) sağlamanız gerekir. Bu teknik, bu bölümde daha ayrıntılı olarak açıklanmıştır.
Sorgu isteğinde isabet vurgulama yönergeleri sağlanır. Benzer ve joker karakter arama gibi altyapıda sorgu genişletmeyi tetikleyen sorgular isabet vurgulama için sınırlı desteğe sahiptir.
İsabet vurgulama gereksinimleri
- Alanlar veya olmalıdır
Edm.StringCollection(Edm.String) - Alanlar şu konumda ilişkilendirilmelidir:
searchable
İstekte vurgulama belirtme
Vurgulanan terimleri döndürmek için sorgu isteğine highlight parametresini ekleyin. parametresi, virgülle ayrılmış alan listesine ayarlanır.
Varsayılan olarak, biçimlendirme işareti şeklindedir<em>, ancak ve highlightPostTag parametrelerini kullanarak highlightPreTag etiketi geçersiz kılabilirsiniz. İstemci kodunuz yanıtı işler (örneğin, kalın yazı tipi veya sarı arka plan uygulama).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Varsayılan olarak, Azure AI Search alan başına en fazla beş vurgu döndürür. Bu sayıyı, sonuna bir tamsayı ekleyerek ayarlayabilirsiniz. Örneğin, "highlight": "description-10" açıklama alanındaki eşleşen içerik üzerinde en fazla 10 vurgulanmış terim döndürür.
Vurgulanan sonuçlar
Sorguya vurgulama eklendiğinde yanıt, uygulama kodunuzun bu yapıyı hedeflemesi için her sonuç için bir @search.highlights içerir. "Vurgulama" için belirtilen alanların listesi yanıta eklenir.
Anahtar sözcük aramasında her terim bağımsız olarak taranır. "İlahi gizli diziler" sorgusu, herhangi bir terimi içeren herhangi bir belgedeki eşleşmeleri döndürür.
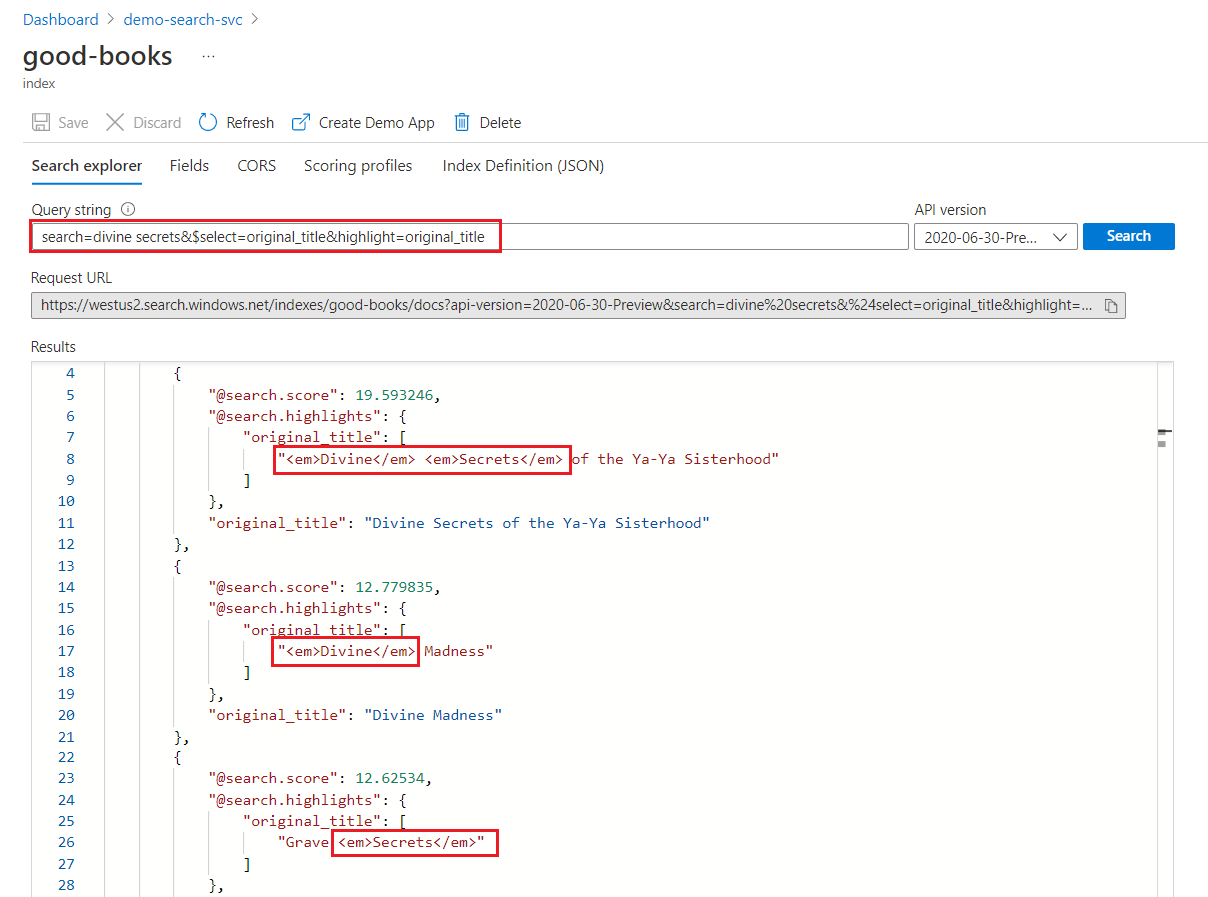
Anahtar sözcük arama vurgulama
Vurgulanan bir alanın içinde biçimlendirme tüm terimlere uygulanır. Örneğin, "Ya-Ya Kardeşliğinin İlahi Sırları" ile yapılan bir eşleşmede, biçimlendirme ardışık olsalar bile her terime ayrı olarak uygulanır.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Tümcecik araması vurgulama
Tüm terim biçimlendirmesi, birden çok terimin çift tırnak içine alındığı bir tümcecik aramasında bile geçerlidir. Aşağıdaki örnek aynı sorgudur, ancak "ilahi gizli diziler" tırnak içine alınmış bir tümcecik olarak gönderilir (bazı REST istemcileri, iç tırnak işaretlerinden ters eğik çizgiyle \"kaçmanızı gerektirir):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Ölçütler artık her iki terime de sahip olduğundan, arama dizininde yalnızca bir eşleşme bulunur. Önceki sorguya verilen yanıt şöyle görünür:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Eski hizmetlerde tümcecik vurgulama
15 Temmuz 2020'ye kadar oluşturulan Arama hizmeti, tümcecik sorguları için farklı bir vurgulama deneyimi uygular.
Aşağıdaki örnekler için tırnak içine alınmış "super bowl" tümceciği içeren bir sorgu dizesi varsayın. Temmuz 2020'ye kadar tümcecikteki terimler vurgulanır:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Temmuz 2020'de oluşturulan arama hizmetleri için yalnızca tam tümcecik sorgusuyla eşleşen tümcecikler içinde @search.highlightsdöndürülür:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Sonraki adımlar
İstemciniz için hızla bir arama sayfası oluşturmak için şu seçenekleri göz önünde bulundurun:
Azure portalında tanıtım uygulaması oluşturma, görüntü varsa arama çubuğu, yönlü gezinti ve küçük resim alanı içeren bir HTML sayfası oluşturur.
ASP.NET Core (MVC) uygulamasına arama ekleme, işlevsel bir istemci oluşturan bir öğretici ve kod örneğidir.
Web uygulamalarına arama ekleme, kullanıcı deneyimi için React JavaScript kitaplıklarını kullanan bir C# öğreticisi ve kod örneğidir. Uygulama Azure Static Web Apps kullanılarak dağıtılır ve sayfalandırma uygular.