Öğretici: Anlamsal bağlantıyı kullanarak Synthea veri kümesindeki ilişkileri bulma
Bu öğreticide, semantik bağlantı kullanılarak genel Synthea veri kümesindeki ilişkilerin nasıl algı kullanıldığı gösterilmektedir.
Yeni verilerle çalışırken veya mevcut bir veri modeli olmadan çalışırken, ilişkileri otomatik olarak keşfetmek yararlı olabilir. Bu ilişki algılama aşağıdakilere yardımcı olabilir:
- modeli yüksek düzeyde anlamak,
- keşif veri analizi sırasında daha fazla içgörü elde etmek,
- güncelleştirilmiş verileri veya yeni, gelen verileri doğrulama ve
- temiz verileri seçin.
İlişkiler önceden bilinse bile, ilişkiler araması veri modelinin daha iyi anlaşılmasına veya veri kalitesi sorunlarının belirlenmesine yardımcı olabilir.
Bu öğreticide, aralarındaki bağlantıların kolayca takip edebilmesi için yalnızca üç tabloyla denemeler yaptığınız basit bir temel örnekle başlayacaksınız. Daha sonra, daha büyük bir tablo kümesiyle daha karmaşık bir örnek gösterirsiniz.
Bu öğreticide aşağıdakilerin nasıl yapılacağını öğreneceksiniz:
- Semantik bağlantının Python kitaplığının (SemPy) Power BI ile tümleştirmeyi destekleyen ve veri analizini otomatikleştirmeye yardımcı olan bileşenlerini kullanın. Bu bileşenler şunlardır:
- FabricDataFrame - ek anlam bilgileriyle geliştirilmiş pandas benzeri bir yapı.
- Doku çalışma alanından not defterinize anlamsal modeller çekme işlevleri.
- Anlamsal modellerinizdeki ilişkileri bulma ve görselleştirmeyi otomatik hale getiren işlevler.
- Birden çok tablo ve bağımlılık içeren anlam modelleri için ilişki bulma işleminin sorunlarını giderin.
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz bir Microsoft Fabric deneme sürümüne kaydolun.
Synapse Veri Bilimi deneyimine geçmek için giriş sayfanızın sol tarafındaki deneyim değiştiriciyi kullanın.

- Çalışma alanınızı bulmak ve seçmek için sol gezinti bölmesinden Çalışma Alanları'nı seçin. Bu çalışma alanı, geçerli çalışma alanınız olur.
Not defterinde birlikte izleyin
Relationships_detection_tutorial.ipynb not defteri bu öğreticiye eşlik eder.
Bu öğreticide eşlik eden not defterini açmak için, not defterini çalışma alanınıza aktarmak üzere Sisteminizi veri bilimi öğreticilerine hazırlama başlığındaki yönergeleri izleyin.
Bu sayfadaki kodu kopyalayıp yapıştırmayı tercih ederseniz, yeni bir not defteri oluşturabilirsiniz.
Kod çalıştırmaya başlamadan önce not defterine bir göl evi eklediğinizden emin olun.
Not defterini ayarlama
Bu bölümde, gerekli modüller ve verilerle bir not defteri ortamı ayarlarsınız.
Not defterindeki
%pipsatır içi yükleme özelliğini kullanarak PyPI'den yükleyinSemPy:%pip install semantic-linkDaha sonra ihtiyacınız olacak SemPy modüllerinin gerekli içeri aktarmalarını gerçekleştirin:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Çıktı biçimlendirmeye yardımcı olan bir yapılandırma seçeneğini zorlamak için pandas'ı içeri aktar:
import pandas as pd pd.set_option('display.max_colwidth', None)Örnek verileri çekin. Bu öğreticide sentetik tıbbi kayıtların Synthea veri kümesini kullanırsınız (basitlik için küçük sürüm):
download_synthea(which='small')
Synthea tablolarının küçük bir alt kümesindeki ilişkileri algılama
Daha büyük bir kümeden üç tablo seçin:
patientshasta bilgilerini belirtirencounterstıbbi karşılaşmaları olan hastaları belirtir (örneğin, tıbbi randevu, prosedür)providershastalara hangi tıbbi sağlayıcıların katıldığını belirtir
Tablo,
encountersileprovidersarasındakipatientsçoka çok ilişkiyi çözümler ve ilişkilendirilebilir bir varlık olarak tanımlanabilir:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')SemPy'nin
find_relationshipsişlevini kullanarak tablolar arasındaki ilişkileri bulun:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsSemPy'nin işlevini kullanarak DataFrame ilişkilerini grafik olarak görselleştirin
plot_relationship_metadata.plot_relationship_metadata(suggested_relationships)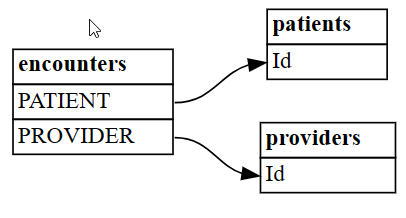
İşlev, çıkıştaki "from" ve "to" tablolarına karşılık gelen ilişki hiyerarşisini sol taraftan sağ tarafa doğru düzenler. Başka bir deyişle, sol taraftaki bağımsız "from" tabloları, sağ taraftaki "to" bağımlılık tablolarına işaret etmek için yabancı anahtarlarını kullanır. Her varlık kutusu, bir ilişkinin "kimden" veya "kime" tarafına katılan sütunları gösterir.
Varsayılan olarak, ilişkiler "m:1" ("1:m" veya "1:1" olarak oluşturulmaz) olarak oluşturulur. "1:1" ilişkileri, eşlenen değerlerin tüm değerlere oranının yalnızca bir veya iki yönde aşılıp aşılmadığını
coverage_thresholdbağlı olarak bir veya iki şekilde oluşturulabilir. Bu öğreticinin ilerleyen bölümlerinde "m:m" ilişkilerinin daha az sık karşılaşılan durumlarını ele alırsınız.

İlişki algılama sorunlarını giderme
Temel örnekte temiz Synthea verilerinde başarılı bir ilişki algılama gösterilmektedir. Uygulamada, veriler nadiren temizdir ve bu da başarılı algılamayı önler. Veriler temiz olmadığında yararlı olabilecek çeşitli teknikler vardır.
Bu öğreticinin bu bölümü, anlam modeli kirli veriler içerdiğinde ilişki algılamayı ele alır.
"Kirli" verileri almak için özgün DataFrame'leri işleyerek başlayın ve kirli verilerin boyutunu yazdırın.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Karşılaştırma için, özgün tabloların boyutlarını yazdırın:
print(len(patients)) print(len(providers))SemPy'nin
find_relationshipsişlevini kullanarak tablolar arasındaki ilişkileri bulun:find_relationships([patients_dirty, providers_dirty, encounters])Kodun çıktısı, "kirli" anlam modelini oluşturmak için daha önce tanıttığınız hatalardan dolayı algılanan bir ilişki olmadığını gösterir.
Doğrulamayı kullanma
Doğrulama, aşağıdakilerden dolayı ilişki algılama hatalarını gidermek için en iyi araçtır:
- Belirli bir ilişkinin neden Yabancı Anahtar kurallarına uymadığı ve bu nedenle algılanamadığına ilişkin net bir şekilde bildirir.
- Yalnızca bildirilen ilişkilere odaklandığı ve arama gerçekleştirmediği için büyük anlamsal modellerle hızlı çalışır.
Doğrulama, tarafından find_relationshipsoluşturulana benzer sütunlara sahip herhangi bir DataFrame kullanabilir. Aşağıdaki kodda suggested_relationships DataFrame yerine öğesine başvurur patients patients_dirty, ancak DataFrame'leri bir sözlükle diğer ad olarak kullanabilirsiniz:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Arama ölçütlerini gevşetme
Daha bulanık senaryolarda arama ölçütlerinizi gevşetmeyi deneyebilirsiniz. Bu yöntem hatalı pozitif olasılığını artırır.
Yardımcı olup olmadığını ayarlayın
include_many_to_many=Trueve değerlendirin:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Sonuçlar, ile ilişkisinin
encounterspatientsalgılandığını gösterir, ancak iki sorun vardır:- İlişki, öğesinden
patientsöğesineencountersgiden bir yönü gösterir ve bu da beklenen ilişkinin tersidir. Bunun nedeni, hastaların satırları eksik olduğundan hepsininpatientsencountersyalnızca kısmen (Coverage FromCoverage To= 0,85)encounterskapsamındapatientsolmasıdır ( 1,0). - Düşük kardinalite
GENDERsütununda, her iki tabloda da ada ve değere göre eşleşen yanlışlıkla bir eşleşme vardır, ancak bu bir "m:1" ilişkisi değildir. Düşük kardinalite veUnique Count TosütunlarıylaUnique Count Fromgösterilir.
- İlişki, öğesinden
Yalnızca "m:1" ilişkilerini aramak için yeniden çalıştırın
find_relationships, ancak daha düşükcoverage_threshold=0.5bir ile :find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Sonuç, ile
encountersprovidersarasındaki ilişkilerin doğru yönünü gösterir. Ancak, öğesindenencounterspatientsilişkisi algılanamaz, çünküpatientsbenzersiz değildir, bu nedenle "m:1" ilişkisinin "Bir" tarafında olamaz.Hem
coverage_threshold=0.5hem deinclude_many_to_many=Truegevşetin:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Artık her iki ilgi ilişkisi de görünür durumdadır, ancak çok daha fazla gürültü vardır:
- Üzerindeki düşük kardinalite eşleşmesi
GENDERmevcut. - Üzerinde daha yüksek bir kardinalite "m:m" eşleşmesi
ORGANIZATIONortaya çıkar ve bu da her iki tablo için de normalleştirilmiş bir sütun olduğunuORGANIZATIONgösterir.
- Üzerindeki düşük kardinalite eşleşmesi
Sütun adlarını eşleştirme
Varsayılan olarak SemPy, veritabanı tasarımcılarının ilgili sütunları genellikle aynı şekilde adlandırmalarından yararlanarak yalnızca ad benzerliğini gösteren özniteliklerle eşleşir. Bu davranış, en sık düşük kardinaliteli tamsayı anahtarlarıyla oluşan sahte ilişkileri önlemeye yardımcı olur. Örneğin, ürün kategorileri ve 1,2,3,...,10 sipariş durumu kodu varsa1,2,3,...,10, yalnızca sütun adlarını hesaba katmadan değer eşlemelerine bakarken birbirleriyle karıştırılırlar. Sahte ilişkiler GUID benzeri anahtarlarla ilgili bir sorun olmamalıdır.
SemPy, sütun adları ile tablo adları arasındaki benzerliğe bakar. Eşleştirme yaklaşık ve büyük/küçük harfe duyarlı değildir. "id", "code", "name", "key", "pk", "fk" gibi en sık karşılaşılan "dekoratör" alt dizelerini yoksayar. Sonuç olarak, en tipik eşleşme durumları şunlardır:
- 'foo' varlığındaki 'column' adlı öznitelik, 'bar' varlığındaki 'column' (aynı zamanda 'COLUMN' veya 'Column') adlı bir öznitelikle eşleşir.
- 'foo' varlığındaki 'column' adlı bir öznitelik, 'bar' içindeki 'column_id' adlı bir öznitelikle eşleşir.
- 'foo' varlığındaki 'bar' adlı bir öznitelik, 'bar' içindeki 'code' adlı bir öznitelikle eşleşir.
Önce sütun adlarını eşleştirerek algılama daha hızlı çalışır.
Sütun adlarını eşleştirin:
- Daha fazla değerlendirme için hangi sütunların
verbose=2seçildiğini anlamak için (verbose=1yalnızca işlenen varlıkları listeler) seçeneğini kullanın. name_similarity_thresholdparametresi sütunların nasıl karşılaştırılmasını belirler. 1 eşiği yalnızca %100 eşleşmeyle ilgilendiğinizi gösterir.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);%100 benzerlikle çalıştırmak adlar arasındaki küçük farkları hesaba bağlayamaz. Örneğinizde, tabloların "s" soneki olan çoğul bir formu vardır ve bu da tam eşleşmeye neden olmaz. Bu, varsayılan
name_similarity_threshold=0.8ile iyi işlenir.- Daha fazla değerlendirme için hangi sütunların
Varsayılan
name_similarity_threshold=0.8ile yeniden çalıştırın:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Çoğul formun
patientskimliğinin artık yürütme süresine çok fazla başka sahte karşılaştırma eklemeden tekilpatientile karşılaştırıldığını görebilirsiniz.Varsayılan
name_similarity_threshold=0ile yeniden çalıştırın:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);0 olarak değiştirmek
name_similarity_thresholddiğer aşırılıktır ve tüm sütunları karşılaştırmak istediğinizi gösterir. Bu nadiren gereklidir ve daha fazla yürütme süresine ve gözden geçirilmesi gereken sahte eşleşmelere neden olur. Ayrıntılı çıktıdaki karşılaştırma sayısını gözlemleyin.
Sorun giderme ipuçlarının özeti
- "m:1" ilişkileri için tam eşleşmeden başlayın (varsayılan
include_many_to_many=Falsevecoverage_threshold=1.0). Bu genellikle istediğiniz şey. - Tabloların daha küçük alt kümelerinde dar bir odak kullanın.
- Veri kalitesi sorunlarını algılamak için doğrulamayı kullanın.
- İlişki için hangi sütunların dikkate alınmadığını anlamak istiyorsanız kullanın
verbose=2. Bu, büyük miktarda çıkışa neden olabilir. - Arama bağımsız değişkenlerinin dengelerine dikkat edin.
include_many_to_many=Trueanalizcoverage_threshold<1.0edilmesi zor olabilecek ve filtrelenmiş olması gereken sahte ilişkiler üretebilir.
Tam Synthea veri kümesindeki ilişkileri algılama
Basit temel örnek, kullanışlı bir öğrenme ve sorun giderme aracıydı. Uygulamada, çok daha fazla tablo içeren tam Synthea veri kümesi gibi anlamsal bir modelden başlayabilirsiniz. Synthea veri kümesinin tamamını aşağıda gösterildiği gibi keşfedin.
Synthea/csv dizinindeki tüm dosyaları okuyun:
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }SemPy
find_relationshipsişlevini kullanarak tablolar arasındaki ilişkileri bulun:suggested_relationships = find_relationships(all_tables) suggested_relationshipsİlişkileri görselleştirme:
plot_relationship_metadata(suggested_relationships)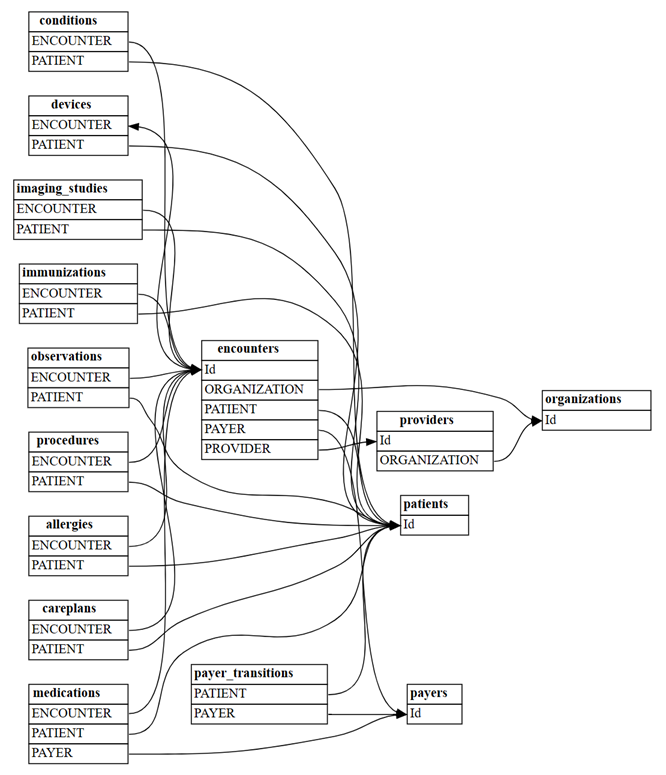
ile
include_many_to_many=Truekaç yeni "m:m" ilişkisi bulunacağını sayar. Bu ilişkiler, daha önce gösterilen "m:1" ilişkilerine ek olarak; bu nedenle, üzerindemultiplicityfiltrelemeniz gerekir:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']İlişki verilerini çeşitli sütunlara göre sıralayarak bunların doğasını daha iyi anlayabilirsiniz. Örneğin, en büyük tabloları tanımlamaya yardımcı olan ve
Row Count Toile çıktıyıRow Count Fromsıralamayı seçebilirsiniz.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)Farklı bir anlamsal modelde, null
Null Count FromveyaCoverage Tosayısına odaklanmak önemli olabilir.Bu analiz, ilişkilerden herhangi birinin geçersiz olup olmadığını ve bunları aday listesinden kaldırmanız gerekip gerekmediğini anlamanıza yardımcı olabilir.

İlgili içerik
Anlamsal bağlantı / SemPy için diğer öğreticilere göz atın: